📊 対象級:準1級 | 重要度:A(頻出)
要点(BLUF)
多くの変数を持つデータを、情報(分散)をできるだけ失わずに少数の合成変数(主成分)へ要約する手法です。準1級では「分散最大化がなぜ固有値問題になるか」「寄与率・累積寄与率を計算・解釈できるか」「主成分得点とは何か」「相関行列ベースと共分散行列ベースをいつ使い分けるか」が問われます。すべての出発点はこの一行に集約されます。
要するに「データの共分散行列 の固有ベクトルが主成分の方向、固有値 がその方向の分散」ということです。あとは固有値を大きい順に並べるだけで、主成分が第1・第2…と決まります。
1. 問題設定:分散を最も多く説明する方向を探す
個の変数を持つ確率ベクトル があり、その共分散行列を とします(実データでは標本共分散行列 を使います)。 は の対称・半正定値行列です。
やりたいのは、変数たちの線形結合
を作り、この合成変数 の分散ができるだけ大きくなる方向 を探すことです。なぜ分散最大かというと、分散が大きい方向こそ「観測がよくばらついている=個体差の情報を多く含む」方向だからです。逆に分散がほぼ0の方向は、どの個体もほぼ同じ値で、捨てても情報をほとんど失いません。
graph LR A["元の p 変数<br/>(相関あり・冗長)"] --> B["線形結合 Z = aᵀX"] B --> C["分散 Var(Z) を最大化"] C --> D["第1主成分<br/>(最も情報が多い軸)"] D --> E["直交方向で繰り返し<br/>→ 第2・第3…主成分"]
要するに「相関して冗長な 個の変数を、互いに無相関で分散の大きい順に並んだ少数の新しい軸へ置き換える」のが主成分分析です。これは次元削減(dimension reduction)の代表的手法であり、教師なし学習です(目的変数 を使わない)。
分散を と で表す
の分散は、共分散行列を使って次のように書けます。
なぜこうなるか。 一般に確率ベクトル を行列 で線形変換すると共分散行列は に変換されます(線形変換と分散の関係は 確率変数の変換・モーメント母関数・積率 が下地)。いま は 行列なので、、 を代入すると (スカラー)になります。
要するに「合成変数の分散は、係数ベクトル を共分散行列 で挟んだ二次形式」だということです。
2. 第1主成分の完全導出(ラグランジュ未定乗数法・省略しない)
2.1 制約がないと発散する
をただ最大化しようとすると、 をいくらでも長くすれば分散もいくらでも大きくなってしまい( で分散は4倍)、最大値が存在しません。意味があるのは「向き」だけで「長さ」ではないので、長さを固定します。
つまり問題は「 という制約の下で を最大化する」という制約付き最適化になります。
2.2 ラグランジュ関数を作る
等式制約付き最大化なので、ラグランジュ未定乗数法を使います。乗数を として、
要するに「最大化したい本体 から、制約 に乗数 を掛けて引いた」関数です。制約を満たす停留点で の勾配がゼロになります。
2.3 で微分してゼロと置く
ここで使う二次形式のベクトル微分の公式は、重回帰の最小二乗解(重回帰分析)と同じ道具です。
これらを使って を で微分しゼロと置きます。
両辺を2で割って整理すると、
これが導出の核心です。 「分散を制約付きで最大化せよ」という最適化問題が、純粋な線形代数の問題、すなわち「共分散行列 の固有値方程式を解け」に化けました。つまり停留点の候補 は の固有ベクトル、 はその固有値でなければなりません。
2.4 どの固有ベクトルを選ぶか — 固有値=分散
固有ベクトルは 個あります(対称行列なので互いに直交する固有ベクトルが 本取れる。下記 2.5)。そのうちどれが「分散最大の方向」かを決めます。固有値方程式 を満たす単位ベクトル ()に対し、達成される分散は
つまり、その方向で得られる分散はちょうど固有値 そのものです。 ラグランジュ乗数 が、たまたま固有値であると同時に「最大化したかった分散の値」になっている、という美しい一致がここで効きます。
したがって分散を最大にするには、最大の固有値 に対応する固有ベクトル を選べばよい。これが**第1主成分(first principal component)**の方向で、第1主成分の分散は です。
要するに「固有値を大きい順に と並べたとき、 の固有ベクトルが一番情報の多い軸」ということです。半正定値性から固有値はすべて になります(分散だから負はあり得ない、と整合)。
2.5 固有ベクトルの直交性(共分散行列が対称だから)
は実対称行列なので、線形代数のスペクトル定理により次が保証されます。
- 固有値はすべて実数(半正定値なので )。
- 異なる固有値に属する固有ベクトルは互いに直交する。重複固有値があっても、直交する固有ベクトルを取り直せる。
結果として、 を正規直交固有ベクトル で対角化できます。
この固有値分解(スペクトル分解)こそが、主成分分析の計算そのものです。共分散行列・相関行列の性質は 分散共分散行列・相関行列 にまとめています。
3. 第2主成分以降:直交制約の下での最大化
第2主成分は「第1主成分と無相関(直交)という条件の下で、次に分散が大きい方向」です。なぜ直交を課すかというと、第1主成分とかぶった情報(同じ方向の分散)をもう一度数えても無駄だからです。新しい軸には「第1主成分が拾い残した分散」だけを担当させます。
定式化は、制約を1本増やしたラグランジュ最適化です。 を第1主成分方向として、
ラグランジュ関数に直交制約の項を足して同様に微分すると、解は「残りの固有ベクトルのうち2番目に大きい固有値 の固有ベクトル 」になります。第2主成分の分散は です。
これを繰り返すと、第 主成分は 番目に大きい固有値 の固有ベクトル 、その分散は となります。
graph TD L1["第1主成分 = 最大固有値 λ₁ の固有ベクトル v₁<br/>(分散最大の方向)"] L2["第2主成分 = 2番目 λ₂ の固有ベクトル v₂<br/>(v₁ と直交し、次に分散大)"] L3["第3主成分 = 3番目 λ₃ の固有ベクトル v₃<br/>(v₁,v₂ と直交)"] L1 --> L2 --> L3 L2 -. v₁⊥v₂ .- L1 L3 -. v₂⊥v₃ .- L2
主成分どうしは無相関です。理由:固有ベクトルが直交()なので、2つの主成分 , の共分散は
要するに「主成分は互いに無相関な新しい座標軸になっている」ということです。相関して重複していた元の変数を、重複のない軸へ組み替えたわけです。
4. 寄与率・累積寄与率:何成分残すか
4.1 総分散は固有値の和
各主成分の分散は固有値 でした。データ全体のばらつきの総量(総分散)は、固有値の総和に等しくなります。
ここでトレース(対角和)の循環性 と を使いました。 は元の各変数の分散の合計です。
要するに「主成分に組み替えても総分散(情報の総量)は保存される。それを各固有値が分け合っているだけ」ということです。
4.2 寄与率と累積寄与率
第 主成分が総分散のうちどれだけを説明するかが**寄与率(proportion of variance / contribution ratio)**です。
最初の 個の主成分までの寄与率を足したものが**累積寄与率(cumulative proportion)**です。
要するに「第 主成分までで、元の情報の何パーセントを保持できているか」を表します。(全部使えば100%)。
4.3 成分数を決める基準(要最新確認)
何個の主成分を残すかの代表的な目安は次の通りです。いずれも絶対の基準ではなく、最終的には分析目的に応じた判断が必要です(数値基準は文献により幅があり、要最新確認)。
| 基準 | 内容 | 注意 |
|---|---|---|
| 累積寄与率 | 累積寄与率が**70〜80%**を超える まで残す | 分かりやすいが、変数が多いと残す数が増えがち |
| カイザー基準(固有値1以上) | 固有値 の主成分を残す(相関行列ベースのとき) | 相関行列では各変数の分散が1なので「元の変数1個分以上の情報がある成分」の意。共分散行列ベースには直接使えない |
| スクリープロット | 固有値を大きい順にプロットし、傾きが急に緩む「肘(elbow)」の手前まで残す | 視覚的判断で主観が入る |
⚠️ カイザー基準「固有値1以上」は相関行列ベース(後述)でこそ意味を持ちます。共分散行列ベースでは各変数の分散が1ではないので、この基準をそのまま当てはめてはいけません。準1級の引っかけポイントです。
5. 主成分得点:各観測を新しい軸へ射影する
固有ベクトル は「軸の向き(重み)」を与えるだけです。個々の観測を新しい軸の上の座標に直したものが**主成分得点(principal component score)**です。
観測 ( 番目の個体)を中心化(平均を引く)してから第 主成分方向へ射影します。
要するに「データ雲を主成分軸で回転させたときの、各点の新しい座標」が主成分得点です。第1主成分得点 が大きい個体ほど「第1主成分が表す特徴を強く持つ」と読みます。
- 中心化が必要な理由:分散は平均からのばらつきなので、原点を平均に移してから射影しないと「軸の向き」と「平均位置」が混ざります。実務では平均を引いた中心化データに対して固有ベクトルを掛けます。
- 主成分得点の分散:第 主成分得点の(標本)分散は固有値 に一致します(2.4・3節の帰結)。
関連して、各元変数と各主成分の相関係数を**主成分負荷量(factor loading)**と呼び、主成分の「解釈」(その軸が何を表すか)に使います。負荷量は固有ベクトルの成分に固有値の平方根を掛けたものとして計算されます。
6. 分散共分散行列ベース vs 相関行列ベース
ここまで (共分散行列)で説明しましたが、実は「共分散行列を使うか、相関行列を使うか」で結果が変わります。これは準1級の頻出論点です。
6.1 何が違うか
- 共分散行列ベース:元データそのものの共分散行列 (標本では )を固有値分解する。
- 相関行列ベース:各変数を標準化(平均0・分散1に変換)してから共分散行列を取る。標準化データの共分散行列は相関行列 に一致する。つまり相関行列ベースの主成分分析=標準化してから共分散行列ベースで分析、と同じです。
6.2 なぜ単位が問題になるか
共分散行列ベースは、各変数の分散の絶対値にそのまま影響されます。たとえば「身長(cm)」と「体重(kg)」を混ぜたとき、たまたま単位の取り方で分散が大きい変数(cmをmmに変えれば分散は100万倍)が第1主成分をほぼ独占してしまいます。これは「情報量」ではなく単なる「単位の都合」です。
そこで、変数の単位や分散のスケールが大きく異なるときは標準化して相関行列ベースにします。標準化すれば全変数の分散が1にそろい、単位に依存せず「変数間の相関構造」だけを見て主成分を決められます。
| 共分散行列ベース | 相関行列ベース(標準化) | |
|---|---|---|
| 入力 | 共分散行列 | 相関行列 |
| 各変数の重み | 分散の大きい変数が支配的 | 全変数を平等に扱う |
| 使う場面 | 変数が同じ単位・同程度の分散(例:同一テストの各科目得点) | 変数の単位・スケールがバラバラ(例:身長cmと年収円) |
| 固有値の総和 | (変数の個数) | |
| カイザー基準 | そのまま使えない | 「固有値1以上」が使える |
⚠️ どちらを使うかで固有値も主成分も変わります。「相関行列ベースでは固有値の和が変数の個数 に等しい」(各変数の分散が1だから)という性質は、寄与率の計算でそのまま効きます。迷ったら、単位が異なるなら相関行列ベース、と覚えます。
実データへの相関・共分散の基礎は 分散共分散行列・相関行列、相関係数そのものの記述統計的な扱いは 2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変 を参照してください。
7. 幾何的な意味:データ雲の長軸
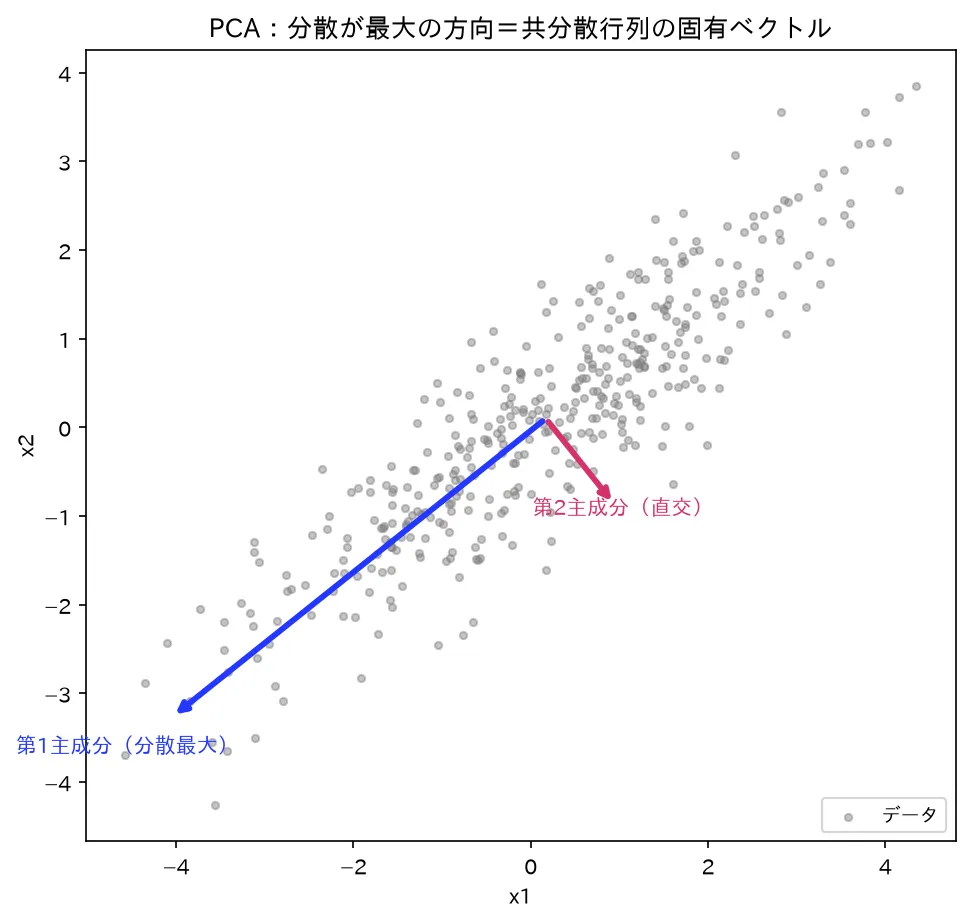
相関データの第1主成分(青矢印)=分散が最大の方向=共分散行列の最大固有ベクトル。第2主成分(赤)は直交。矢印の長さは √固有値。図は simulations/pca_bunsan_saidai.py で生成。
2変数の正規分布のように、データ雲が楕円形に広がっている状況を考えます。
- 第1主成分の方向=楕円の長軸:最もデータが伸びている(分散が大きい)方向。
- 第2主成分の方向=楕円の短軸:長軸と直交し、次に伸びている方向。
- 固有値 は各軸方向の「広がりの大きさ(分散)」に対応し、楕円の半径の二乗のようなイメージです。
要するに「主成分分析は、座標軸をデータ雲の自然な向き(長軸・短軸)に回転させる操作」です。元のデカルト座標 ではなく、データに沿った新しい直交座標 で個体を表し直しているわけです。回転後の軸が無相関になるのは、楕円の主軸を取れば軸間の相関(楕円の傾き)が消えるからです。
graph LR A["元の座標 (X₁, X₂)<br/>傾いた楕円のデータ雲"] -->|"主成分軸へ回転"| B["新座標 (Z₁, Z₂)<br/>Z₁=長軸, Z₂=短軸<br/>互いに無相関"]
8. PCAの手順フロー
flowchart TD
S["データ行列(n×p)を用意"] --> C{"変数の単位・分散は<br/>大きく異なるか?"}
C -- "はい(異なる)" --> R["標準化 → 相関行列 R を計算"]
C -- "いいえ(同程度)" --> V["共分散行列 Σ を計算"]
R --> E["固有値分解<br/>固有値 λ と固有ベクトル v を求める"]
V --> E
E --> O["固有値を大きい順に並べ替え<br/>λ₁ ≥ λ₂ ≥ … ≥ λ_p"]
O --> P["寄与率 cₖ = λₖ / Σλ を計算<br/>累積寄与率で残す成分数 m を決定"]
P --> Z["主成分得点 zᵢₖ = vₖᵀ(xᵢ − x̄) を計算<br/>各観測を主成分軸へ射影"]
Z --> I["主成分(負荷量)を解釈"]
9. 試験での問われ方(準1級)
主成分分析は多変量解析の中でも頻出です。準1級では次の角度で問われます。
- 導出:分散最大化を制約 の下でラグランジュ未定乗数法で解き、固有値方程式 を導く。固有値が分散に一致する理由。
- 寄与率・累積寄与率の計算:固有値が与えられ、第 主成分の寄与率や、累積寄与率が一定値を超える成分数を求める。固有値の和=総分散(相関行列なら )。
- 主成分得点の計算:固有ベクトルと中心化データが与えられ、特定の個体の主成分得点を計算する。
- 相関行列 vs 共分散行列:どちらを使うべきか、単位の異なるデータでの選択。標準化の要否。
- 主成分の解釈:固有ベクトル(重み)や主成分負荷量の符号から、各主成分が何を表すかを読む。
- 因子分析との区別:生成方向(因果の向き)の違い。因子分析は 因子分析 で扱います。
固有値分解・対称行列の対角化という線形代数の道具が前提です。確率変数の線形変換と分散の関係は 確率変数の変換・モーメント母関数・積率、共分散・相関行列の性質は 分散共分散行列・相関行列 を先に押さえてください。
よくある疑問(Q&A)
Q1. 主成分分析と因子分析は何が違うのですか?同じ「次元削減」では?
生成の向き(因果の方向)が逆です。主成分分析は「観測変数 → 主成分」、つまり観測した変数を合成して主成分を作ります(主成分は観測変数の線形結合で、結果側)。一方、因子分析は「共通因子 → 観測変数」、つまり背後に潜む共通因子が原因となって観測変数が生じる、というモデルです。要するにPCAは観測を要約する道具、因子分析は観測の背後にある潜在要因を推定する道具です。多くの統計ソフトで因子分析のオプションにPCAが混じっているため取り違えが起きやすい、というのもよくある誤りです。詳しくは 因子分析 で対比します。
Q2. 主成分の符号(固有ベクトルの向き)が、ソフトや実行ごとに反転するのですが?
正常です。符号は数学的に決まりません(符号の不定性)。 が単位固有ベクトルなら も を満たし、長さも1なので等しく正当な解です。どちらを返すかは計算ライブラリの実装次第なので、符号が反転しても結果は同値です。解釈するときは「全成分の符号をまとめて反転しても意味は変わらない」点に注意します(第1主成分得点の大小関係は符号反転で逆になるが、軸の意味は同じ)。要するに「向きは決まるが、正負どちら向きかは決まらない」ということです。
Q3. データは必ず標準化(相関行列ベース)すべきですか?
いいえ、変数の単位・分散がどうかで決めます。単位やスケールが大きく異なる(例:身長cmと年収円)なら標準化して相関行列ベースにします。標準化しないと、たまたま分散の大きい変数が第1主成分を独占し、それは「情報量」ではなく「単位の都合」です。一方、すべて同じ単位・同程度の分散(例:同一テストの各科目得点で、得点差そのものを重視したい)なら共分散行列ベースが自然です。「とりあえず標準化」が常に正解ではありません。
Q4. 寄与率が高い第1主成分は、必ず予測や分類に役立つ軸ですか?
必ずしも役立つとは限りません。PCAは教師なしで、目的変数 を一切見ずに「分散が大きい方向」を選びます。分散が大きいことと、 を予測・分類するのに有用なことは別問題です。クラスを分ける情報がたまたま分散の小さい方向(捨てた成分)に入っていれば、第1主成分はむしろ分類に効きません。要するに「分散最大 ≠ 予測・分類に最適」です。予測のための次元削減なら、目的変数を使う手法(部分最小二乗回帰など)の方が適することがあります。
Q5. 主成分は必ず意味のある概念(「総合学力」など)として解釈できますか?
保証されません。主成分はあくまで「分散最大という数学的条件」で機械的に決まる軸であり、人間にとって解釈可能な意味を持つとは限りません。固有ベクトルの符号と大きさ(や主成分負荷量)を見て「この軸はおおむね全変数が同方向=総合的な大きさ」「この軸は一部が正・一部が負=対比」のように事後的に解釈を試みますが、きれいに解釈できないこともあります。解釈しやすさを重視するなら、回転を許す因子分析(因子分析)の方が向く場合があります。
まとめ
- 主成分分析は、線形結合 の分散 を の下で最大化する手法。ラグランジュ未定乗数法で微分してゼロと置くと固有値方程式 に帰着する。
- 最大固有値 の固有ベクトルが第1主成分方向、その分散が 。第2主成分以降は直交制約の下で次に大きい固有値の固有ベクトル。主成分どうしは無相関。
- 固有値の和=総分散 。寄与率 、累積寄与率で残す成分数を決める(70〜80%・カイザー基準・スクリープロット。基準は要最新確認)。
- 主成分得点 は、各観測を主成分軸へ射影した座標。
- 変数の単位・分散が大きく異なるなら標準化して相関行列ベース。同程度なら共分散行列ベース。相関行列ベースでは固有値の和が でカイザー基準が使える。
- 注意:教師なし・分散最大であって予測/分類に最適とは限らない/主成分の解釈は保証されない/符号は不定/因子分析とは生成方向が逆。
関連ノート
- 分散共分散行列・相関行列 PCAの入力。固有値分解する対象である共分散行列・相関行列の性質
- 因子分析 PCAと混同されやすい手法。生成方向(因果の向き)が逆
- 確率変数の変換・モーメント母関数・積率 線形変換 の根拠
- 2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変 相関係数の記述統計的な基礎
- 重回帰分析 二次形式のベクトル微分など、最適化の道具を共有する
- 多変量解析(Phase 6 目次) 多変量解析ドメインの全体像