🎓 レベル:標準 | 重要度:B(標準)
📎 前提:k-meansクラスタリング | 数理:クラスター分析(統計)
要点(BLUF)
- 階層的クラスタリングは、クラスタ数 を事前に決めず、データを「入れ子になった階層(クラスタの中にクラスタ)」として構成する手法です。結果は デンドログラム(樹形図) として丸ごと得られ、後から好きな高さで切ってクラスタ数を選べます。
- 主流は 凝集型(bottom-up):各点を1個のクラスタとして始め、最も近いクラスタ対を1つずつ併合していきます。クラスタ間距離の測り方が 連結法(linkage) で、単連結・完全連結・群平均・ウォード法が代表です。連結法を変えると樹形の癖が変わります。
- を決めなくてよく決定的(毎回同じ結果)で解釈しやすい一方、素朴な実装は時間 ・メモリ と重く、大規模データには向きません。ここが k-meansクラスタリング との一番の使い分けです。
1. 階層的クラスタリングとは
k-meansクラスタリング は「クラスタ数 を先に決めて、点を 個のグループに分割する(フラットなクラスタリング)」手法でした。階層的クラスタリングはこれと発想が違い、1個の階層構造を作って、分割の仕方を全部いっぺんに表現します。
イメージは生物の分類です。「個体 → 種 → 属 → 科 → …」と、小さいまとまりが入れ子で大きいまとまりになっていく。階層的クラスタリングはまさにこの入れ子(hierarchy)をデータから作ります。出力は1つの木で、
- どの点とどの点が近いか(木のどこで合流するか)
- どのくらいの粒度で見ればいくつのクラスタになるか(木をどの高さで切るか)
を同時に表します。 を決め打ちせず、後から木を眺めて決められるのが最大の特徴です。
要するに:「 を当てに行く」のではなく「クラスタの入れ子構造そのものを作る」のが階層的クラスタリングです。
2. 凝集型と分割型
階層を作る方向に2通りあります。
| 方式 | 方向 | 手順 |
|---|---|---|
| 凝集型(agglomerative) | ボトムアップ | 各点を1クラスタとして開始 → 最も近い2クラスタを併合 → 1個になるまで繰り返す |
| 分割型(divisive) | トップダウン | 全点を1クラスタとして開始 → 最も不均質なクラスタを2分割 → 各点が1個になるまで繰り返す |
flowchart TB
subgraph AGG["凝集型 (bottom-up)"]
direction TB
A1["n個の点 = n個のクラスタ"] -->|"最も近い対を併合"| A2["n-1 個"]
A2 -->|"併合"| A3["n-2 個"]
A3 -->|"…"| A4["最後は1個 (全体)"]
end
subgraph DIV["分割型 (top-down)"]
direction TB
D1["全点 = 1個のクラスタ"] -->|"最も不均質な所で2分割"| D2["2個"]
D2 -->|"分割"| D3["…"]
D3 -->|"分割"| D4["n個 (各点が単独)"]
end
実務でほぼ常に使うのは 凝集型 です。分割型は「あるクラスタをどこで2つに割るか」の候補が指数的( 通り)にあり、素朴にやると組合せ爆発します(近似手法に DIANA があります)。以降は凝集型を中心に説明します。
要するに:下から積むのが凝集型、上から割るのが分割型。実用上は凝集型が標準です。
3. 距離行列と連結法(linkage)
凝集型の各ステップでやることは1つ、「最も近い2クラスタを選んで併合する」だけです。問題は「クラスタとクラスタの近さ」をどう定義するか。点と点の距離 (ふつうユークリッド距離)は決まっていても、複数点を含むクラスタ と の距離は一意ではありません。この定義が 連結法(linkage criterion) です。
代表的な4つを挙げます。クラスタ 、点 とします。
単連結(single linkage / 最短距離法)
2クラスタのいちばん近い点どうしの距離で測ります。「橋が1本架かれば近い」と判定するため、点が数珠つなぎに連なる細長いクラスタを作りやすい。これを 鎖効果(chaining effect) と呼びます。非球状のクラスタを拾える長所でもあり、ノイズで関係ないクラスタが繋がる短所でもあります。
完全連結(complete linkage / 最長距離法)
いちばん遠い点どうしの距離で測ります。全ペアが近くないと併合されないので、コンパクトで径の揃った(球状寄りの)クラスタを作りやすい。外れ値の影響を受けやすい点に注意。
群平均(average linkage / UPGMA)
全ペア距離の平均で測ります。単連結(min)と完全連結(max)の中間で、両者の極端さを和らげた穏当な選択です。
ウォード法(Ward’s method)
ここだけ「距離の min/max/平均」ではなく分散基準で測ります。ウォード法は「併合によってクラスタ内平方和(within-cluster sum of squares, ESS)がどれだけ増えるか」が最小になる対を選びます。
クラスタ の内部平方和を、重心 として
と定義します(k-meansクラスタリング の目的関数と同じ「重心からの二乗距離の和」です)。クラスタ と を併合したときの ESS の増分は、重心 、サイズ を使ってきれいに書けます。
ウォード法はこの が最小の対を毎ステップ併合します。
要するに:ウォード法は「併合してもクラスタがあまり広がらない(ばらつきの増加が小さい)対」から順にくっつけます。重心間距離をサイズで重みづけした量を最小化する、-means と親戚の基準です。サイズの揃った球状クラスタを作りやすく、実務でまず試す既定の連結法としてよく使われます。
連結法ごとの樹形の癖(まとめ)
graph LR
L["連結法の選択"] --> S["単連結 (min)"]
L --> C["完全連結 (max)"]
L --> A["群平均 (mean)"]
L --> W["ウォード法 (ESS増分)"]
S --> Sc["細長い・鎖効果 / 非球状も拾うがノイズに弱い"]
C --> Cc["コンパクト・球状寄り / 外れ値に敏感"]
A --> Ac["min と max の中間でバランス型"]
W --> Wc["サイズの揃った球状 / k-means と親戚・既定で多用"]
| 連結法 | クラスタ間距離 | 作りやすい形 | 弱点 |
|---|---|---|---|
| 単連結 | 最近点間 | 細長い・非球状 | 鎖効果でノイズに弱い |
| 完全連結 | 最遠点間 | コンパクト・球状寄り | 外れ値に敏感 |
| 群平均 | 全ペア平均 | 中庸 | 強い癖はないが万能でもない |
| ウォード法 | サイズの揃った球状 | 非球状・サイズ不均衡に弱い |
4. Lance–Williams の更新式(連結法を一本化する)
連結法ごとに「クラスタ間距離をどう測るか」を別々に定義しましたが、実はほとんどの連結法は1本の漸化式に統一できます。これが Lance–Williams の更新式(Lance & Williams, 1967)です。
いま と を併合して新クラスタ を作ったとします。残りのクラスタ に対する新しい距離 を、併合前にわかっている3つの距離 だけから計算できる、というのが要点です。
係数 を選ぶだけで、連結法を切り替えられます( は各クラスタのサイズ)。
| 連結法 | ||||
|---|---|---|---|---|
| 単連結 | ||||
| 完全連結 | ||||
| 群平均(UPGMA) | ||||
| 重心法(UPGMC) | ||||
| ウォード法 |
( なら になり、確かに単連結=最小、 なら =完全連結になります。ウォード法・重心法では距離は二乗ユークリッド距離を入れて使います。)
要するに:連結法は「距離をどう測るか」をバラバラに実装する必要はなく、4つの係数を差し替えるだけで統一的に計算できます。距離を毎回ゼロから測り直さず、併合のたびに行を1本の式で更新できるので実装も速くなります。⚠️ ただし重心法・メディアン法は が単調に増えない(あとで併合した方が距離が小さくなる=デンドログラムの逆転 / inversion が起きうる)ので、樹形図が読みにくくなることがあります。単・完全・群平均・ウォードは逆転しません。
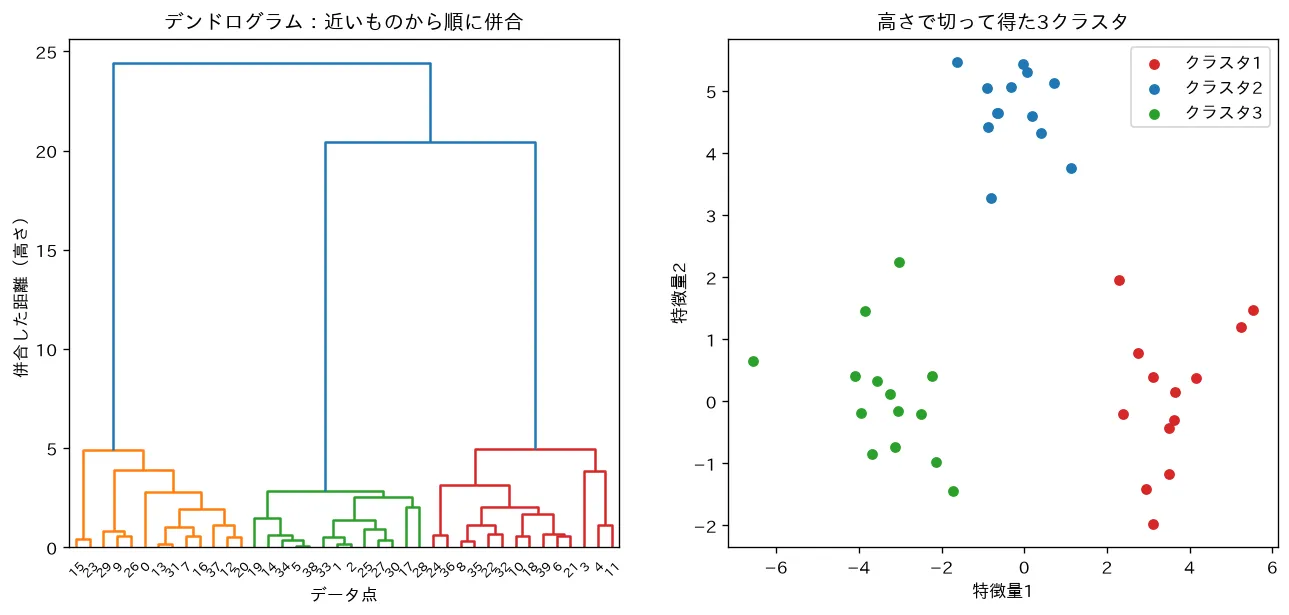
5. デンドログラム(樹形図)の読み方
凝集型の併合の履歴をそのまま描いた図が デンドログラム です。
- 葉(一番下) が個々のデータ点
- 2つを併合するたびに、両者を横棒でつなぐ
- その横棒の高さ=併合したときのクラスタ間距離(連結法で測った値)
つまり「低い位置で合流する点どうしは近い、高い位置でしか合流しない点どうしは遠い」と読みます。
graph TD
R["高さ大: 全体が1つに (遠い者どうしの最後の合流)"]
R --- G1["中くらいの高さで合流"]
R --- G2["中くらいの高さで合流"]
G1 --- p1["点1"]
G1 --- p2["点2"]
G2 --- p3["点3"]
G2 --- p4["点4"]
高さで「切る」とクラスタ数が決まる
デンドログラムをある高さで水平に切断すると、切った線が横切る縦線の本数だけクラスタができます。低く切れば細かく多数のクラスタ、高く切れば粗く少数のクラスタ。ここで を後から選べるのが階層的クラスタリングの強みです。
切る高さの目安として、「併合のたびに高さがどれだけ飛ぶか」を見て、大きくジャンプする直前で切る方法がよく使われます(高さの差が大きい=そこで離れたものを無理にくっつけ始めた、という合図。-means のエルボー法に似た発想です)。
要するに:デンドログラムは「いつ・どのくらいの距離で併合したか」の全履歴で、横に切る高さを変えるだけで任意の のクラスタリングが取り出せます。
6. 計算量と大規模データでの限界
凝集型の素朴な実装のコストは、
- メモリ:全点対の距離をしまう距離行列で
- 時間:各ステップで「最も近い対」を距離行列から探し、併合で行を更新する。これを 回繰り返すと素朴には
優先度付きキューや最近傍チェーン(nearest-neighbor chain)を使うと一般に まで、単連結に限れば最小全域木との対応から SLINK(Sibson 1973)で時間 ・メモリ の最適アルゴリズムが知られています。
それでも本質は最低でも (全点対を一度は見る)です。 が数十万を超えると距離行列 のメモリだけで破綻するため、階層的クラスタリングは中小規模(おおむね数千〜数万点)向きと理解してください。大規模なら -means や 混合ガウスモデルとEM、あるいはミニバッチ・近似手法が現実的です。
7. k-means との比較
| 観点 | 階層的クラスタリング | k-meansクラスタリング |
|---|---|---|
| の事前指定 | 不要(後から木を切って選ぶ) | 必要(先に決める) |
| 出力 | 階層(デンドログラム)丸ごと | フラットな 分割のみ |
| 再現性 | 決定的(同じ入力=同じ結果) | 初期値依存でランダム(毎回変わりうる) |
| クラスタ形状 | 連結法しだい(単連結なら非球状も可) | 基本は球状・等方を仮定 |
| 計算量 | 重い(〜、メモリ ) | 軽い(反復あたり 、大規模向き) |
| 解釈性 | 高い(木で関係が一望できる) | 中(重心と割り当てのみ) |
graph TB
Q["どちらを使う?"] --> Q1{"k を事前に決められる?"}
Q1 -->|"決めにくい / 階層構造を見たい"| H["階層的クラスタリング"]
Q1 -->|"k は見当がつく"| Q2{"データは大規模?"}
Q2 -->|"大規模 (数十万〜)"| K["k-means (軽い)"]
Q2 -->|"中小規模で形が非球状 / 樹形を見たい"| H
Q2 -->|"中小規模で球状でよい"| K
要するに:「 を決めずに構造を見たい・解釈したい・再現性が欲しい・データが中小規模」なら階層的。「 の見当がついて大規模で速さが欲しい」なら -means。両者は対立ではなく、まず階層的で構造と の当たりをつけ、本番の分割は -means で回すといった併用も定番です。
⚠️ よくある誤解・落とし穴
- 「階層的だから を決めなくてよい=楽」ではない。木は得られますが、結局どの高さで切るか(=いくつのクラスタにするか)の判断は残ります。 を決める問題が「切る高さを決める問題」に姿を変えただけです。
- 連結法の選択は結果を大きく左右する。同じデータでも単連結とウォード法でまるで違う樹形になります。「とりあえずデフォルト」で済ませず、目的(球状を期待するか/細長い構造を拾いたいか)に合わせて選ぶこと。迷ったらウォード法か群平均が無難です。
- 距離尺度とスケーリングに敏感。ユークリッド距離を使うなら -means 同様、特徴量の標準化はほぼ必須です(k-meansクラスタリング と同じ注意)。ウォード法は二乗ユークリッド距離前提なので、距離尺度を勝手に取り替えると意味が崩れます。
- 一度併合したら戻せない(貪欲・局所最適)。凝集型は各ステップでその場の最近対を選ぶ貪欲法で、全体最適は保証しません。途中の併合ミスは後段に引きずられます。
- 大規模データに素朴に適用しない。 のメモリで簡単に破綻します。数万点を超えたら手法選定を見直してください。
- デンドログラムの「横軸の並び順」に意味を読みすぎない。葉の左右の並びは描画の都合で入れ替え可能で、近さを表すのは”合流する高さ”だけです。
対応するシミュレーション
simulations/hierarchical_dendrogram.py:3つの塊データにウォード法の凝集型クラスタリングをかけ、併合の履歴を**デンドログラム(樹形図)**として描きます。低い高さで結ばれる点ほど似ていること、k-means と違い事前にクラスタ数を決めず、デンドログラムを好きな高さで横に切るだけで任意の数のクラスタが得られることを可視化します。連結法しだいで結果が変わる点にも触れます(k-meansクラスタリング と使い分け)。
関連ノート
- 教師なし学習 目次
- k-meansクラスタリング( を決め打ちするフラットな対比手法。前提)
- 混合ガウスモデルとEM(確率モデルで「柔らかく」クラスタリングする発展)
- クラスター分析(統計:クラスター分析の数理的土台。連結法・デンドログラムの原典)
- 多次元尺度構成法(MDS)(統計:距離行列から布置を作る。距離ベースという発想が共通)
- 機械学習テキスト 全体目次