🎓 レベル:発展 | 重要度:A(必須)
📎 前提:ロジスティック回帰・正則化(Ridge・Lasso・Elastic Net)・汎化と過学習・バイアスバリアンス分解 | 数理:SVM・非線形回帰・プロビット分析(統計)
要点(BLUF)
- SVM は「2クラスを分ける直線(超平面)」のうち、境界から最も近いデータ点までの距離(マージン)が最大になるものを選ぶ分類器です。境界をどちらのクラスからもなるべく遠ざけることで、未知データに頑健な=汎化しやすい境界を狙います。
- 解くべき問題は s.t. という凸2次計画。これを双対問題に直すと、境界を決めるのは境界ギリギリにいる一部の点(サポートベクター)だけだと分かります。
- 双対問題ではデータが内積でしか現れないため、その内積をカーネル関数 に置き換えるだけで、高次元へ実際に写像せずに非線形な境界を引けます(カーネルトリック)。
1. マージン最大化という発想
ロジスティック回帰 は確率 をシグモイドでモデル化し、交差エントロピーを最小化して境界を引きました。SVM は発想が違います。確率を一切モデル化せず、純粋に幾何学的な余白だけを基準にします。
2クラスが直線(一般には超平面)で分けられるとき、分け方は無数にあります。どれも訓練データは完璧に分けますが、境界が片方のクラスにギリギリ寄っていると、新しい点がわずかにズレただけで誤分類されます。
graph LR
subgraph BAD["境界が偏っている(マージン小)"]
B1["境界が片側に寄る<br/>→ 少しのズレで誤分類<br/>→ 汎化に弱い"]
end
subgraph GOOD["マージン最大(SVM)"]
G1["両クラスから等距離で最遠<br/>→ ズレに頑健<br/>→ 汎化に強い"]
end
BAD --> GOOD
SVM の主張:分けられる超平面のうち、両クラスの最近接点との余白(マージン)が最大のものが最も安全。これは「分けられる中で最も保守的な境界を選ぶ」という構造的リスク最小化の考え方に対応します。
要するに:きれいに分けるだけでなく、境界を両クラスから最大限に遠ざける。これが SVM の核心です。
2. マージンを数式にする
分離超平面を と書きます( は境界に直交する法線ベクトル、 は切片)。クラスラベルは を使います(ロジスティック回帰の ではなく にするのが SVM の流儀で、後で式が一本にまとまります)。
点 から超平面までの距離は、線形代数の公式で
です( が単位法線だから、超平面の式に点を代入して法線の長さで割ると距離になります)。
ここで を定数倍しても表す超平面は同じ( も同じ平面)なので、このスケールの自由度を使い、両クラスの最近接点でちょうど になるように目盛りを決めます。すると最近接点から境界までの距離は左右とも になり、マージン全幅は
要するに:境界から最も近い点までの余白(の両側合計)は 。法線 が短いほどマージンが広い、という関係です。(この導出の詳細は統計側 SVM・非線形回帰・プロビット分析 に同じ式があります。)
3. ハードマージン SVM の最適化問題
マージン を最大化することは、分母 を最小化することと同じ。さらに の最小化は の最小化と同値( なので単調)です。微分を楽にするため係数 を付けて目的関数を とします。
制約は「すべての点を正しく分類し、かつマージンの外側に置く」こと。正例()は 、負例()は 。 を掛けると一本にまとまり、
要するに:マージン最大化を「目的=法線を短く、制約=全点を正しく の外に置く」と書き直したもの。目的関数は2乗ノルムで凸、制約は線形なので、これは凸2次計画問題です。局所最適に捕まる心配がなく、大域最適が一意に求まります(多峰になりうる尤度最大化との大きな違い)。
この を小さく保つ部分は、正則化(Ridge・Lasso・Elastic Net) の L2 ペナルティ(Ridge)とまったく同じ形です。後で見るように、SVM はこの正則化の視点でも読み解けます。
4. ラグランジュ双対とサポートベクター
制約付き最適化なのでラグランジュ未定乗数法で解きます。各制約に乗数 を当てると、
で偏微分して0と置く(停留条件)と、
要するに:最適な法線 は、データ点 を で重みづけた和です。これを に代入すると が消え、 だけの双対問題になります。
要するに:「 を探す問題」を「乗数 を探す問題」に置き換えました。ここで重要なのは、データが という内積の形でしか現れないこと。これが後でカーネルを効かせる鍵になります。
サポートベクター(境界を決めるのは一部の点だけ)
最適解では相補性条件(KKT条件の一つ)
が成り立ちます。「」と「制約の余り」の積がゼロ、つまりどちらかが必ず0です。ここから点が2種類に分かれます。
- マージンの外側の点():括弧が正なので 。 の和に一切寄与しない。
- マージン境界ちょうどの点(): になりうる。これがサポートベクター。
したがって
要するに:境界を決めるのは、境界ギリギリにいる少数のサポートベクターだけ。遠くの点は何個あっても境界に影響しません。サポートベクター以外を削除して再学習しても、得られる境界はまったく同じです。これは「全データの平均・分散で境界を動かす」判別分析やロジスティック回帰と根本的に違う、SVM の際立った特徴です。
flowchart TD
A["全データ点"] --> B{"KKT相補性条件<br/>αᵢ・(制約の余り)= 0"}
B -->|"マージン外側<br/>余りが正"| C["αᵢ = 0<br/>境界に寄与しない"]
B -->|"マージン境界上<br/>余りが0"| D["αᵢ > 0<br/>サポートベクター"]
D --> E["w = Σ αᵢ yᵢ xᵢ<br/>(サポートベクターだけで決まる)"]
5. ソフトマージン(スラック変数とハイパーパラメータ C)
現実のデータは完全には分離できない(クラスが少し混じる、外れ値がある)のが普通です。そのままハードマージンを課すと、たった1点の外れ値のために境界が大きく歪んだり、そもそも解が存在しなかったりします。
そこでスラック変数 を導入し、「制約をどれだけ破ったか」を許す代わりに、破った総量にペナルティ を課します。
要するに:マージンの内側へ だけ食い込むのを許すが、その総量に料金 を払わせる。 なら正しくマージン外、 ならマージン内だが正しい側、 なら誤分類です。
C の役割(マージンの広さと誤分類のトレードオフ)
は「制約違反をどれだけ嫌うか」を決めるつまみです。
- が大きい:違反に重いペナルティ。多少マージンを狭めても全点を正しく分けようとする → ハードマージンに近づき、過学習しやすい。
- が小さい:違反に寛容。多少の誤分類を許してでもマージンを広く・境界を滑らかに → 汎化重視だが学習誤差は増える。
これは 汎化と過学習・バイアスバリアンス分解 のバイアス・バリアンスの綱引きそのもの。 は交差検証で選ぶハイパーパラメータです。
ヒンジ損失との等価性(正則化としての SVM)
制約を最良に埋める を代入すると、ソフトマージン SVM は
の形に書けます。要するに:SVM は「ヒンジ損失 + L2 正則化」の最小化と等価です。ヒンジ損失は「マージン内に入ったら線形に罰し、十分外なら罰しない」損失で、 は 正則化(Ridge・Lasso・Elastic Net) の Ridge とまったく同じ罰則項です。ここで が小さいほど罰則が強い= は正則化の強さの逆数に当たる点に注意してください。
ロジスティック回帰(交差エントロピー損失+正則化)と SVM(ヒンジ損失+正則化)は、「損失関数だけが違う、同じ正則化付き線形分類器の兄弟」と見ることができます。
6. カーネルトリック(非線形分離)
線形では分けられないデータも、高次元の特徴空間に写像 すれば線形分離できることがあります(例:同心円状の2クラスは の軸を足せばある半径で平面分離できる)。しかし を陽に計算するのは高次元では重く、無限次元では不可能です。ここで4節の双対問題を思い出すと、データは内積 の形でしか現れませんでした。写像後も必要なのは内積 だけ。そこでこの内積をカーネル関数
で丸ごと置き換えます。要するに:高次元へ飛ばした後の内積を、元の空間の関数 一発で計算する。写像 自体は作らない。これがカーネルトリックです。
flowchart LR
A["元の空間<br/>線形分離できない"] --> B["内積を K(x, x')に置換<br/>(φ は陽に計算しない)"]
B --> C["高次元の特徴空間で<br/>暗黙に線形分離"]
C --> D["元の空間では<br/>非線形な境界"]
双対問題と判別式は、 を に差し替えるだけです。
代表的なカーネル
- 多項式カーネル : 次までの多項式的な特徴の相互作用に対応します。次数 を上げるほど複雑な境界を表現できますが、過学習しやすくなります。
- ガウス(RBF)カーネル :無限次元の特徴空間に対応し、非常に柔軟な境界を引けます。 は「近さの効く範囲」を決め、 が大きいほど各点の影響が局所的になり(境界が点に貼りつき)過学習しやすい、小さいほど滑らかになります。最も汎用的でまず試される定番です。
要するに:カーネルは「内積の差し替え」であって、特徴ベクトルを実際に作るわけではありません。RBF は無限次元の に対応しますが、計算は元空間の関数1発で済みます。なお、 が本当にある の内積として書けるには、 が**正定値(Mercer 条件)**を満たす必要がある、という理論的な前提だけ覚えておけば十分です。
RBF SVM では (正則化)と (カーネル幅)の2つを同時に交差検証で調整します。両方が複雑さを上げる向きに効くので、グリッドサーチで一緒に探すのが定石です(→ 汎化と過学習・バイアスバリアンス分解 の複雑さ調整)。
⚠️ よくある誤解
- 「マージン最大化なのに最小化問題なのはおかしい」ではない。マージンは で、分子は定数。最大化したいので分母 を最小化し、結果として目的関数は (最小化)になります。符号と分母の向きを混同しがちです。
- 「SVM は全データで境界を決める」は誤り。境界を決めるのはサポートベクター()だけ。マージン外の点()は何個消しても境界は不変です。「全データの重心で動く」のは判別分析の話です。
- 「カーネルで高次元ベクトルを実際に作っている」は誤り。作るのは内積 だけ。RBF は無限次元 に対応しますが、計算は元空間の関数1発で、次元の高さは計算量に響きません。
- C の向きを逆に覚えがち。 大 → 違反に厳しい → ハードマージン寄り → 過学習しやすい。 小 → 違反に寛容 → マージン広く滑らか。 は正則化の強さの逆数に近い役割なので、「 が大きいほど正則化が強い」と思うと逆になります。
- 「SVM は確率を出す」は半分誤り。素の SVM の出力は符号(どちら側か)だけで、確率は出しません。確率が欲しい場合はプラットスケーリング等で後付けします。確率モデルが本体なのはロジスティック回帰の方です。
- 標準化を忘れる・ を大きくしすぎる。RBF も多項式も内積・距離に依存するため、標準化が前提です。また が大きすぎる RBF は訓練点に貼りつく過学習境界になり、・ を調整しないと線形 SVM に負けます。
対応するシミュレーション
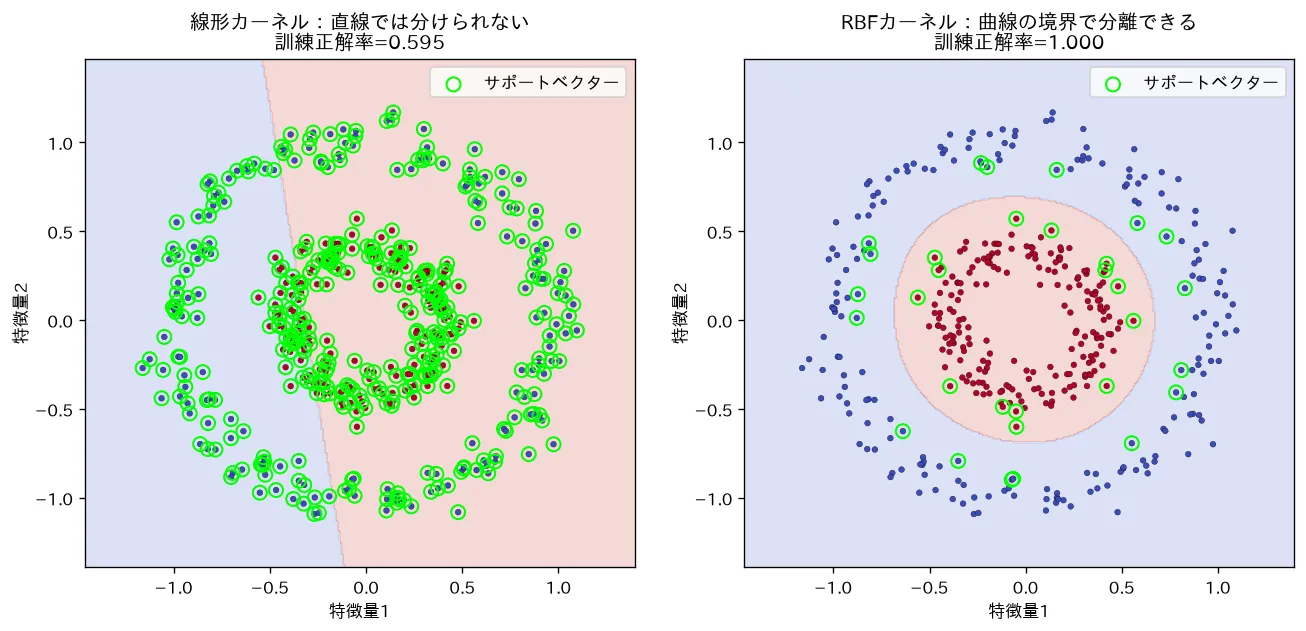
simulations/svm_kernel.py:同心円状(線形分離できない)データで 線形カーネルと RBFカーネルの SVM を比較します。線形カーネルは直線でしか分けられず正解率0.5付近で失敗するのに対し、RBFカーネルはカーネルトリックで曲線の境界を引いて分離できることを可視化し、境界を支えるサポートベクターを強調表示します。
関連ノート
- ロジスティック回帰 同じ線形分類器だが、確率(交差エントロピー)でなく幾何マージン(ヒンジ損失)で境界を引く兄弟。損失関数だけが違う
- 正則化(Ridge・Lasso・Elastic Net) ソフトマージン SVM は「ヒンジ損失+L2正則化」と等価。 は Ridge と同じ罰則
- 汎化と過学習・バイアスバリアンス分解 ・ の調整はバイアス・バリアンスの綱引き。交差検証で複雑さの谷を探す
- SVM・非線形回帰・プロビット分析(統計) マージン導出・双対・KKT・カーネルの数理が統計側にある対応ノート
- 教師あり学習・分類 目次
- 機械学習テキスト 全体目次