🎓 レベル:基礎 | 重要度:A(必須)
📎 前提:学習問題の定式化(仮説・損失・経験リスク)・線形回帰(最小二乗法と確率的解釈) | 評価:評価指標(分類)とROC・AUC | 数理:最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論)(統計)・一般化線形モデル(ロジスティック・ポアソン回帰)(統計)
要点(BLUF)
- ロジスティック回帰は「線形結合 をシグモイドで 〜 に押し込め、クラス1に属する確率 を出力する」確率を出す線形分類器です。回帰という名前ですが、やることは分類です。
- 学習は 交差エントロピー損失 の最小化で行います。これは「ラベルがベルヌーイ分布に従う」という仮定のもとでの最尤推定そのものです(二乗誤差は使いません)。
- 線形回帰と違って解析解はなく、勾配降下で解きます。ただし損失は凸なので最小値は一つだけ。決定境界( の面)は について線形になります。
1. なぜ線形回帰をそのまま分類に使えないのか
ラベルが の二値分類で、線形回帰 をそのまま当てはめると2つの問題が起きます。
- 出力が確率にならない: は から まで動くので、 や のような「確率でない値」が平気で出ます。
- 二乗誤差が分類に向かない: ラベルに直線を当てると、極端な を持つ正しく分類済みの点が直線を引っ張り、決定境界がずれます。外れ値に弱いのです。
欲しいのは「 という の値を、確率 に変換する関数」です。それが次のシグモイドです。
flowchart LR
X["特徴 x"] --> Z["線形結合 z = xᵀβ(範囲は −∞〜+∞)"]
Z --> S["シグモイド σ(z)"]
S --> P["確率 p = P(y=1 | x)(範囲は 0〜1)"]
P --> D["p ≥ 0.5 ならクラス1, さもなくばクラス0"]
2. シグモイドと対数オッズの線形性
クラス1の確率を、線形結合 を**シグモイド関数(ロジスティック関数)**に通して定義します:
シグモイドは で 、 で 、 で を取る S 字曲線です。これで の入力が必ず に収まります。
要するに:線形回帰の出力を「確率の蛇口」に通して 〜 に絞っただけです。
このモデルの正体は、対数オッズ(log-odds, ロジット)が について線形という点にあります。シグモイドを逆に解くと、
が出ます(導出: より 、両辺の対数を取ると )。ここで はオッズ(起こる確率と起こらない確率の比)です。
要するに:ロジスティック回帰は「確率そのもの」ではなく「対数オッズ」を線形モデルで予測しています。だから係数 は「 が1増えると対数オッズが 増える=オッズが 倍になる」と解釈できます。これは統計の一般化線形モデル(ロジスティック・ポアソン回帰)で言う「リンク関数がロジット、誤差分布がベルヌーイの GLM」です。
graph LR
A["対数オッズ log(p/(1−p))<br>= xᵀβ(線形)"] -->|"シグモイドで変換"| B["確率 p(非線形・S字)"]
B -->|"ロジットで逆変換"| A
3. 交差エントロピー損失=ベルヌーイ分布の最尤推定(導出)
損失をどう決めるか。ここが核心です。各ラベル が確率 のベルヌーイ分布から出ると考えます:
これは「 なら 、 なら 」をひとつの式に畳んだものです(指数 と のどちらかが必ず1で、もう一方は0になり片方が消える)。
データが独立なら全体の尤度は積になり、対数を取ると和になります(対数尤度):
最尤推定は を最大化することですが、最適化では最小化に揃えるのが慣習なので、符号を反転した負の対数尤度を損失とします。これが**交差エントロピー損失(バイナリ・クロスエントロピー / ログ損失)**です:
要するに:交差エントロピーは天下りの損失ではなく、「ラベルはベルヌーイ分布に従う」という確率モデルの最尤推定そのものです。線形回帰で「二乗誤差=ガウス誤差の最尤」だったのと完全に同じ筋立てで、誤差分布がガウスからベルヌーイに変わっただけです(→ 線形回帰(最小二乗法と確率的解釈)・最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論))。
なぜ二乗誤差ではなく交差エントロピーか。1点だけ理由を挙げると、シグモイド出力に二乗誤差を掛けると損失が非凸になり、勾配も飽和域( が0や1に近い所)で消えて学習が止まります。交差エントロピーなら凸性が保たれ、勾配も後述のきれいな形になります。
4. 勾配降下で解く(解析解がない理由と勾配の形)
線形回帰は正規方程式 で一発で解けました。ロジスティック回帰はそうはいきません。損失 を で微分して0と置いても、 が について非線形なため、 について閉じた形に解けない(解析解が存在しない)のです。そこで勾配降下法で反復的に最小化します。
勾配を計算すると、驚くほどきれいな形になります。シグモイドの微分 を使って連鎖律を回すと、
になります( は各 を並べたベクトル)。
要するに:勾配は「予測確率と正解ラベルの差(残差) 特徴量」の和です。これは線形回帰の勾配 とまったく同じ形で、シグモイドの非線形さも対数も指数も消えています。これは交差エントロピーとシグモイドの相性が良い証拠です。
更新式は学習率 を使って
を収束するまで繰り返すだけです(→ 最適化の詳細は勾配降下のノートで)。
flowchart TB
A["βを初期化"] --> B["各点の確率 p = σ(Xβ) を計算"]
B --> C["勾配 ∇L = Xᵀ(p − y) を計算"]
C --> D["β ← β − η·∇L で更新"]
D --> E{"収束したか?"}
E -->|"No"| B
E -->|"Yes"| F["学習終了"]
損失 は について凸(ヘッセ行列 が半正定値)なので、局所最適に捕まる心配はなく、勾配降下は唯一の大域最小に向かいます。実務ではより速い準ニュートン法(L-BFGS)やニュートン法(IRLS)も使われます。
5. 決定境界が線形になる
予測クラスは「 ならクラス1」で決めます。 となるのは のとき、つまり境界は
という方程式で表されます。これは について**線形(超平面)**です。
要するに:ロジスティック回帰の決定境界は必ず直線(2次元)/平面(高次元)になります。確率の出力は S 字に曲がっていても、クラスの切れ目はまっすぐです。だから本質的に線形分離可能に近いデータ向きで、複雑な境界が要るなら特徴量を非線形変換する(多項式特徴・基底関数 → 多項式回帰と基底関数)か、別の手法(判別分析(LDA・QDA) の QDA、SVM のカーネル等)に移ります。正則化(正則化(Ridge・Lasso・Elastic Net))を入れて過学習を抑えるのも回帰と同じ要領です。
6. 多クラスへの拡張:ソフトマックス回帰
クラスが3つ以上 あるときは、クラスごとに重み を持たせ、ソフトマックス関数で確率に変換します:
ソフトマックスは「各クラスのスコア を指数で正にしてから、合計が1になるよう正規化する」操作で、シグモイドの多クラス版です( にすると2クラスのシグモイドに一致します)。
損失はカテゴリカル交差エントロピー(正解クラスの対数確率の負和)で、勾配はやはり
という「予測確率 正解(ワンホット)」の形になります。
要するに:二値のシグモイド+ベルヌーイ最尤を、多値のソフトマックス+カテゴリカル分布の最尤に置き換えただけで、構造は同一です。この「最後の層がソフトマックス+交差エントロピー」という形は、そのままニューラルネットワークの分類出力層に受け継がれます。
⚠️ よくある誤解
- 「回帰」だから連続値を予測すると思う:名前は回帰ですが出力はクラス確率で、用途は分類です。名前は「対数オッズを線形回帰している」ことに由来します。
- 損失に二乗誤差を使ってしまう:シグモイド+二乗誤差は非凸かつ勾配が飽和して学習が進みません。**交差エントロピー(=ベルヌーイ最尤)**を使うのが正解です。
- 解析解があると思う:線形回帰の正規方程式に相当する閉じた解は存在しません。 が について非線形だからで、必ず反復最適化(勾配降下・IRLS等)が要ります。
- 決定境界が曲がると思う:出力確率は S 字ですが、クラスの境界 は線形です。曲げたければ特徴量を非線形変換するか別手法へ。
- 完全分離(perfect separation)で係数が発散する:データが線形完全分離可能だと、尤度を上げ続けるために となり推定が収束しません。正則化(L2 など)を入れて抑えるのが定石です。
- 多クラスは「シグモイドを各クラスに独立適用」ではない:相互排他な多クラスは各確率の合計を1にする必要があり、ソフトマックスを使います(独立シグモイドはマルチラベル=1サンプルが複数クラスに属せる設定向け)。
対応するシミュレーション
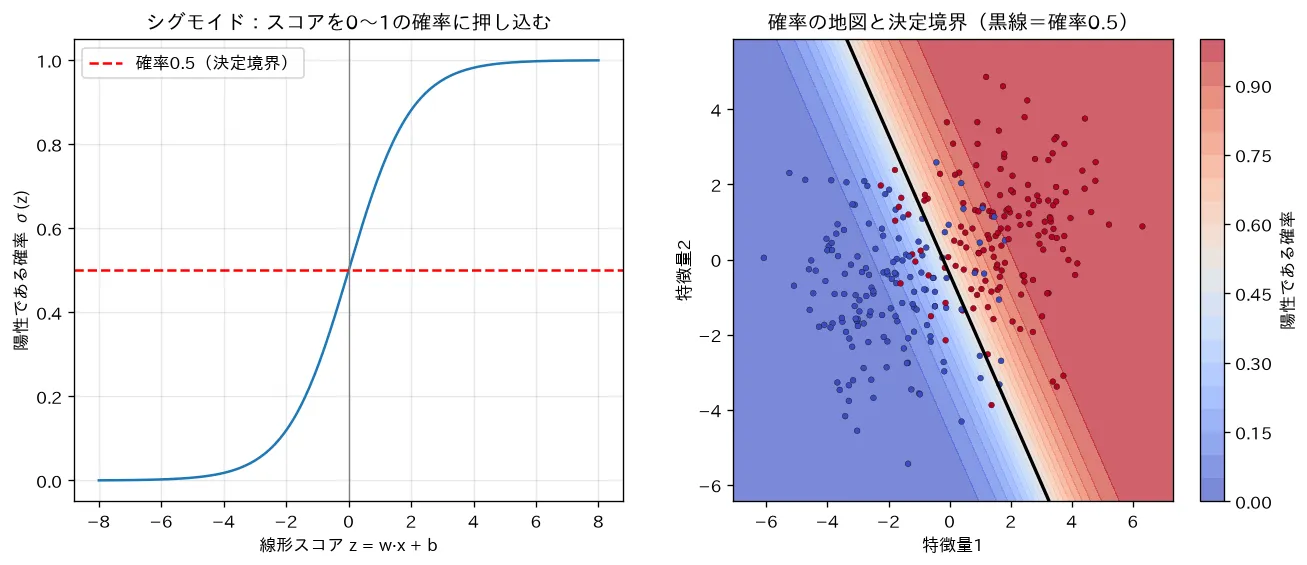
simulations/logistic_regression.py:2クラスデータにロジスティック回帰を当て、(1) シグモイド関数が線形スコア を 〜 の確率に押し込む様子、(2) 確率の地図(ヒートマップ)と決定境界(確率0.5の線)を可視化します。境界の近くほど確率が0.5に近く確信度が低いこと、出力が確率なのでしきい値を動かせること(評価指標(分類)とROC・AUC)が見て取れます。
関連ノート
- 教師あり学習・分類 目次
- 学習問題の定式化(仮説・損失・経験リスク)(損失最小化・経験リスクの枠組み)
- 線形回帰(最小二乗法と確率的解釈)(線形結合・最尤としての損失という同じ筋立て)
- 正則化(Ridge・Lasso・Elastic Net)(完全分離・過学習への対処)
- 多項式回帰と基底関数(非線形な境界が要るときの特徴変換)
- 判別分析(LDA・QDA)(線形/二次の決定境界・生成モデルとの対比)
- 評価指標(分類)とROC・AUC(確率出力の閾値・性能評価)
- 一般化線形モデル(ロジスティック・ポアソン回帰)(統計・ロジットリンクのGLMとしての位置づけ)
- 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論)(統計・最尤推定の一般論)
- 機械学習テキスト 全体目次