🎓 レベル:標準 | 重要度:B(標準)
📎 前提:線形回帰(最小二乗法と確率的解釈)・汎化と過学習・バイアスバリアンス分解 | 数理:単回帰分析(統計)
要点(BLUF)
- 入力 をあらかじめ決めた基底関数 で変換し、 と書くと、データに対しては曲線(非線形)なのにパラメータ については線形なモデルになります。
- だから最小二乗法(線形回帰(最小二乗法と確率的解釈))がそのまま使えます。多項式・ガウス・スプラインなど、基底関数を選ぶだけで表現力を変えられます。
- 次数(基底の数)を上げると表現力は増えますが過学習に向かいます(汎化と過学習・バイアスバリアンス分解)。正則化(正則化(Ridge・Lasso・Elastic Net))と併用すれば高次でも安定します。
1. 基底関数とは
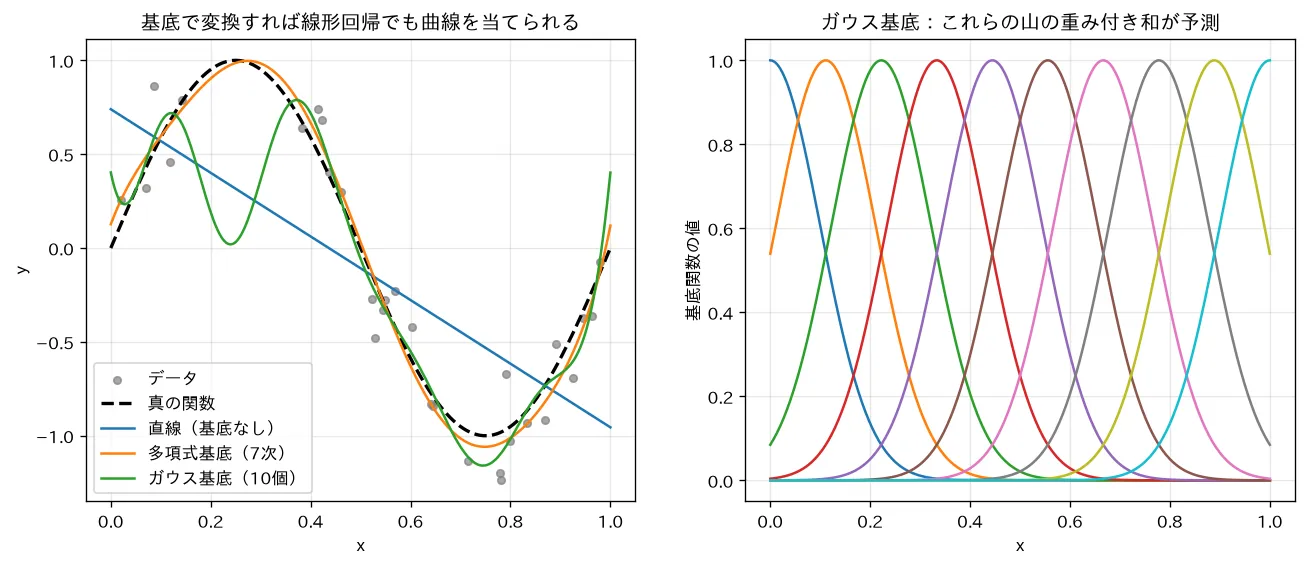
線形回帰は のように入力 に直接比例する直線しか引けません。これを非線形に拡張する素直な方法が、入力をいったん別の特徴量に変換してから直線を引くことです。
入力 を 個の関数で写した値 を新しい特徴量とみなし、それらの線形結合で予測します。
ここで (定数項=バイアス)と置くのが慣例です。 を基底関数(basis function)、このモデルを線形基底関数モデルと呼びます。
要するに:「生の 」ではなく「 を加工した特徴量 」に対して直線(超平面)を当てるだけ。加工で曲げる、当てはめは線形のまま、という分業です。
flowchart LR X["入力 x"] --> P["基底変換 φ(x) = [φ0, φ1, ..., φM-1]"] P --> L["線形結合 Σ wj φj(x)"] L --> Y["予測 y(x, w)"]
この発想の利点は、「曲げる責任」を基底に、「重みづけの責任」を学習に分けられることです。どんな曲線族を表現したいか(多項式か、山型か、区間ごとか)は基底の選択で決まり、その中でデータに最も合う1本を選ぶのは線形回帰の最小二乗が担います。基底を差し替えるだけで、同じ学習エンジンのまま表現する関数の性格を変えられます。
2. 代表的な基底関数
多項式基底
とすると、
これが多項式回帰です。次数 が表現力のつまみで、 を上げるほど複雑な曲線を描けます。
要するに:多項式回帰は「基底に を選んだ線形基底関数モデル」の特別な場合にすぎません。
⚠️ 多項式基底は**大域的(global)**です。1つの が定義域全体に効くため、ある一点を合わせようとすると遠くの形まで動き、高次では端で激しく振動します(後述)。
ガウス基底(RBF)
中心 ・幅 の山型の関数を並べます。
各基底は中心付近だけに反応する**局所的(local)**な関数です。中心をデータの範囲に均等に配置し、その重ね合わせで曲線を作ります。
要するに:山をいくつも置いて高さ を調整し、足し合わせて任意の形になじませるイメージです。局所的なので、ある領域の調整が遠くを壊しにくいのが多項式との違いです。
幅 は滑らかさのつまみです。 を小さくすると各山が鋭くなり細かい変化を表せますが過学習しやすく、 を大きくすると山がなだらかになり全体がぼやけます。中心 の数と が、多項式でいう「次数」に相当する複雑さのコントロールになります。
区分多項式・スプライン
定義域をいくつかの区間(区切り点をノットと呼ぶ)に分け、区間ごとに低次の多項式を当て、ノットでなめらかに(値・1階・2階微分が連続するように)つなぎます。これがスプラインです。代表は各区間を3次多項式にした3次スプライン。
要するに:全域を1本の高次多項式で無理に通すのをやめ、「局所ごとに低次多項式を貼り合わせる」ことで、低い次数のまま柔軟さと安定性を両立させます。これも -スプラインなどの基底関数で表せば線形基底関数モデルの一種です。
ノットの数と位置が複雑さのつまみです。ノットを増やすほど局所的な変化を表せますが、増やしすぎれば過学習します。端の外側を直線に固定した自然3次スプラインは、データの少ない境界付近で曲線が暴れるのを防ぐ実務的な工夫としてよく使われます。
graph TD BF["基底関数モデル<br/>y = Σ wj φj(x)"] --> POLY["多項式基底<br/>φj = x^j(大域的)"] BF --> GAUSS["ガウス基底 RBF<br/>山型(局所的)"] BF --> SPL["スプライン<br/>区間ごと低次多項式を接続"]
3種類の性格を整理すると次のとおりです。
| 基底 | 形 | 効き方 | 強み | 弱み |
|---|---|---|---|---|
| 多項式 | 単項式 | 大域的 | 単純・解釈しやすい | 高次で振動・悪条件 |
| ガウス(RBF) | 山型 | 局所的 | なめらか・局所調整が安定 | 中心・幅の設定が必要 |
| スプライン | 区間ごとの低次多項式 | 局所的 | 低次のまま柔軟・端が安定 | ノット位置・数の設計が必要 |
局所的な基底(ガウス・スプライン)は「ある領域をいじっても遠くが壊れにくい」ため、同じ柔軟さでもバリアンスを抑えやすいのが実務上の利点です。
3. なぜ最小二乗がそのまま使えるのか
基底関数 がどれだけ非線形でも、それは事前に計算できる固定の値です。学習で動かすのは重み だけ。モデルが について線形()である限り、線形回帰とまったく同じ計算になります。
データ に対し、 成分が の計画行列 を作ると、
という、線形回帰の正規方程式とまったく同じ閉形式解が得られます( が に置き換わっただけ)。
要するに:「線形」とは入力に対してではなくパラメータに対して線形という意味。だから非線形な曲線でも、解き方は線形回帰の使い回しでよいのです(数理の土台は 単回帰分析 統計)。
具体例:3点を2次多項式で
、 なら計画行列は
各行が1つのデータ点、各列が1つの基底です。あとは に通すだけで、2次曲線の係数 が一発で求まります。基底を に増やせば列が1本増えるだけで、手続きは何も変わりません。
4. 次数と過学習
次数 (=基底の数)を上げると仮説集合が広がり、訓練データへの当てはまりは良くなりますが、ノイズまで拾って過学習します。これは 汎化と過学習・バイアスバリアンス分解 のバイアス-バリアンスのトレードオフそのものです。
- 低次( 小):表現力不足で真の関係を捉えきれない=高バイアス・低バリアンス(未学習)
- 高次( 大):訓練点を通すが暴れる=低バイアス・高バリアンス(過学習)
極端に言えば、データ点が 個あるとき次数 の多項式は全点をぴったり通せて訓練誤差をゼロにできます(補間)。しかしそれは真の関係ではなくノイズまで暗記しただけで、未知データでの誤差はむしろ悪化します。訓練誤差がいくらでも下がってしまうからこそ、評価は検証誤差で行う必要があるのです。
xychart-beta
title "多項式の次数と当てはまり"
x-axis ["1次", "3次", "5次", "9次", "15次"]
y-axis "誤差" 0 --> 100
line [70, 30, 15, 8, 3]
line [72, 35, 30, 55, 92]
上の線が訓練誤差(次数とともに単調減少)、下から立ち上がる線が検証誤差(高次でU字に増加)。谷が「ちょうどよい次数」。検証誤差で次数を選ぶのが鉄則です(バイアスバリアンスの実証)。
高次多項式の落とし穴:ルンゲ現象
多項式基底にはもう一つ、過学習とは別の数値的な弱点があります。次数を上げると計画行列 が悪条件(ill-conditioned)になり、係数 がわずかなデータの違いで桁違いに変動します。その結果、たとえ訓練点をすべて通っていても、点と点の間(とくに定義域の端)で曲線が大きく振動します。これをルンゲ現象と呼びます。
- 原因:単項式 は互いによく似た形(高次でほぼ平坦→急上昇)になり、列同士が相関する。これが をほぼ特異にし、逆行列が数値的に不安定になる。
- 対策:(1) 局所的な基底(スプライン・ガウス)に替える、(2) 正則化で係数の暴れを抑える、(3) 等間隔でなく端を密にした点を使う、など。
要するに:高次多項式は「データを通すこと」はできても「データの間を素直に補間すること」が苦手。表現力の高さがそのまま不安定さにつながるため、局所基底や正則化で抑えるのが定石です。
5. 正則化との併用で高次でも安定
「次数を下げる」以外に、高次のまま重みを抑える手もあります。L2正則化(Ridge)を入れた最小二乗は、
となり、 を足すぶん の悪条件がやわらぎ、係数が暴れにくくなります(数値的にも安定)。
要するに:基底の数(次数)と正則化の強さ は、どちらも複雑さを調整するつまみ。高次の基底で表現力を確保しつつ でバリアンスを抑える、という組み合わせが実務的です(詳細は 正則化(Ridge・Lasso・Elastic Net))。
スパース性が欲しい場合は L1 正則化(Lasso)を使うと、不要な高次の基底の重みがちょうど 0 になり、「実質的に使う基底を選ぶ」効果も得られます。
6. 使いどころと基底の選び方
- 基底の種類:素直な多項式は低次(〜3次程度)までなら解釈もしやすく十分。柔軟さが要るなら局所的なガウス基底やスプラインに切り替えるのが定石です。
- 基底の数(複雑さ)の決め方:訓練誤差ではなく検証誤差で選びます。次数 ・ガウスの幅 ・ノット数などはハイパーパラメータなので、検証データ(または交差検証)で誤差の谷を探します(バイアスバリアンスの実証)。
- 正則化とセットで考える:高次でも を効かせれば暴れません。「基底数を絞る」か「多めの基底+正則化」かは、データ量・滑らかさの事前知識で選びます。
固定基底の限界と、その先
ここまでの基底はすべて人が事前に決め打ちしたものでした。これは入力が1次元なら問題になりませんが、入力の次元が増えると基底の数が爆発的に必要になります(次元の呪い)。たとえば 次元入力で全次数 までの多項式項を並べると、項数はおよそ のオーダーになり、現実的でなくなります。
この限界を超える発想が「基底そのものをデータから学習する」ことです。ニューラルネットワークは、隠れ層が に相当する基底を学習で形作り、その線形結合で出力する——いわば「基底が固定でなく可変な線形基底関数モデル」と見ることができます。固定基底モデルは、その意味で深層学習へ続く出発点でもあります。
要するに:基底関数モデルは「特徴量をどう作るか」と「どう重みづけるか」を分けた最初の一歩。後者を線形回帰に任せ、前者を学習で獲得する方向に進めたのがニューラルネットワークです。
まとめ
基底関数モデルは、入力 を に写すことで、線形回帰の枠組みのまま非線形な関係を表現する仕組みです。多項式・ガウス・スプラインなど基底を選ぶだけで表現力を変えられ、パラメータについては線形なので最小二乗がそのまま使えます。表現力を上げれば過学習に向かうので、検証誤差で複雑さを選び、正則化を併用して安定させる——これが基底関数モデルを使いこなす勘所です。
⚠️ よくある誤解
- 「多項式回帰は非線形モデルだから線形回帰とは別物」ではありません。パラメータ については線形なので、解法も理論も線形回帰の枠組みのままです。「非線形なのは入力に対して」だけ。
- 次数を上げるほど良い、ではありません。訓練誤差は単調に下がりますが、見るべきは検証誤差。高次は過学習・悪条件・振動を招きます。
- 基底の数は事前に決め打ちします(学習で増減しない)。中心・幅・ノット位置などはハイパーパラメータで、検証誤差で選びます。学習で動かすのは重み だけ、という分担を混同しないこと。
- ガウス基底とカーネル法は別物。ここでは基底を明示的に並べて特徴量を作ります。基底を陰に無限次元で扱うのがカーネル法で、出発点の発想は共通でも仕組みが違います。
- 「特徴量を増やせば必ず良くなる」ではありません。基底を増やすことは複雑さを上げることと同義で、バリアンス増・悪条件・計算コストを伴います。増やすなら正則化とセットで、が原則です。
対応するシミュレーション
simulations/polynomial_basis.py:sin 波のデータに、(1) そのまま(直線)、(2) 多項式基底 、(3) ガウス基底で線形回帰を当てて比べます。直線は曲線に追従できないが、入力を基底で“変換”してから線形回帰すると x について非線形な曲線を当てられること=「線形回帰の“線形”は重みについての線形で、入力についてではない」ことを可視化します。基底を増やすと過学習するので正則化(正則化(Ridge・Lasso・Elastic Net))と組み合わせます。