🎓 レベル:標準 | 重要度:B(標準)
要点(BLUF)
- 汎化と過学習・バイアスバリアンス分解で導いた「総誤差 = ノイズ + バイアス² + バリアンス」を、多項式回帰の次数を変えながら数値実験で実際に確かめます。
- やり方はシンプルです。真の関数にノイズを足して訓練セットを何百本も作り、各セットで学習し、テスト点ごとに「予測の平均のズレ(バイアス²)」と「予測のばらつき(バリアンス)」を測ります。
- 次数を上げるとバイアス²は下がり、バリアンスは上がり、総誤差はU字を描く——理論どおりの結果が、計算からそのまま出てきます。
1. なぜ実験するのか
汎化と過学習・バイアスバリアンス分解の分解式は、固定した点 における期待二乗誤差を次のように分けたものでした。
要するに:消せないノイズ に、「平均的にどれだけズレるか(バイアス²)」と「データ次第でどれだけ暴れるか(バリアンス)」を足したものが誤差です。
ここで は「訓練データ を取り替えたときの予測の平均」です。式の中に期待値 が入っているのがポイントで、これは1本の訓練データだけでは計算できません。訓練データを何度も取り替えて初めて意味を持つ量です。
そこで発想を逆にします。期待値を解析的に計算する代わりに、訓練データを実際に何百本も作って平均で近似する(モンテカルロ近似)。こうすればバイアス²もバリアンスも電卓のように数えられます。これが本ノートの実験です。
2. 実験のセットアップ
題材は多項式回帰と基底関数で扱った多項式回帰です。設定をひとつ決めておきます。
- 真の関数 :たとえば のような滑らかな曲線(次数では完全には表せない関数を選ぶのがコツ)。
- ノイズ :平均0・分散 の正規ノイズ。観測は 。
- モデル:次数 の多項式回帰。この が「モデルの複雑さ」のつまみです。
- テスト点: を区間に等間隔でたくさん並べた固定の点群。ここで誤差を測ります。
真の関数 と をこちらで決めてデータを作るのが実験の肝です。現実のデータでは も も未知でバイアスとバリアンスは直接測れませんが、シミュレーションなら正解を知っているので分解が数値で検証できます。
3. 手順(モンテカルロ分解)
各次数 について、次を実行します。
- 訓練セットを 本生成する。(例:)について、毎回新しいノイズを引いて から訓練データ を作る。
- 各 で次数 の多項式を学習し、予測器 を得る。
- テスト点ごとに 本の予測を集める。テスト点 に対し、 という 個の予測値が並ぶ。
- 平均予測を出す:。
- 点ごとにバイアス²とバリアンスを計算する:
- バイアス² (平均予測が真の値からどれだけズレているか)
- バリアンス (予測が平均のまわりでどれだけ散らばるか)
- テスト点全体で平均する:手順5の2つの量を全テスト点で平均し、その次数 の代表値とする。
- 総誤差を組み立てる: バイアス² バリアンス。これが分解式の右辺で、実測の期待二乗誤差とほぼ一致するはずです。
flowchart TD G["真の関数 g(x) と ノイズ分散 σ²"] --> GEN["訓練セットを B 本生成<br/>y = g(x) + ε"] GEN --> FIT["各セットで次数 d を学習<br/>予測器 f_b を得る"] FIT --> COL["テスト点ごとに B 本の予測を集める"] COL --> MEAN["平均予測 f̄(x) を計算"] MEAN --> BIAS["バイアス² = ( f̄ − g )²"] MEAN --> VAR["バリアンス = 予測の散らばり"] BIAS --> SUM["総誤差 = σ² + バイアス² + バリアンス"] VAR --> SUM SUM --> REP["次数 d を変えて繰り返す"]
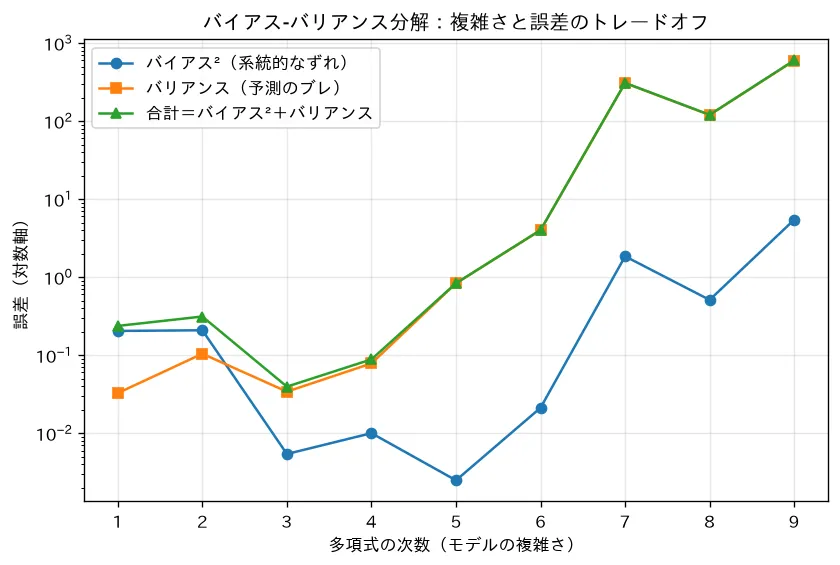
4. 結果として何が見えるか
次数 を横軸に、3つの量を並べると次の挙動が出ます。
- バイアス²は右下がり:次数を上げると多項式の表現力が増し、平均予測 が真の関数 に近づくため、ズレ(バイアス²)は単調に減ります。
- バリアンスは右上がり:次数が高いほどモデルはノイズに敏感になり、訓練セットを取り替えるたびに予測が大きく暴れます。
- 総誤差はU字:両者の和(+一定のノイズ )は、低次数では高バイアスで、高次数では高バリアンスで大きくなり、中間に谷ができます。
xychart-beta
title "次数を上げたときの誤差分解"
x-axis ["1次", "3次", "5次", "9次", "15次"]
y-axis "誤差" 0 --> 100
line [78, 30, 14, 8, 5]
line [4, 10, 20, 45, 82]
line [92, 50, 44, 63, 97]
上から:バイアス²(右下がり)/バリアンス(右上がり)/総誤差(U字)。総誤差の谷が、この問題での「ちょうどよい次数」です。
谷の位置は真の関数の複雑さとノイズの大きさで決まります。ノイズ を大きくするとバリアンスの立ち上がりが早まり、谷は低い次数側に動きます。逆にデータ点を増やすとバリアンスが全体的に下がり、谷は浅く・右に動きます(バイアスはデータ量では下がらない点に注意。詳しくは汎化と過学習・バイアスバリアンス分解)。
5. 検証データとの対応
実務では真の関数 を知らないので、上の分解は直接は測れません。その代わりに使うのが検証データでの誤差です(訓練・検証・テストと交差検証)。検証誤差は「ノイズ + バイアス² + バリアンス」をまとめて推定した量なので、検証誤差が最小になる次数を選べば、結果的にU字の谷を選んでいることになります。
この実験は「検証誤差の谷の正体が、バイアス²とバリアンスのせめぎ合いである」ことを、正解を知っている人工データで裏側から確認する作業だと言えます。複雑さの抑え込み(正則化)でバリアンスを下げる手段は正則化(Ridge・Lasso・Elastic Net)を参照してください。
対応するシミュレーション
simulations/bias_variance.py:上の手順をそのまま実装します。真の関数 にノイズを足して訓練セットを多数生成し、次数を変えて多項式回帰を学習。テスト点ごとにバイアス²・バリアンスを数値分解し、次数対誤差のグラフ(対数軸)でU字を再現します。高次でも数値的に安定させるため、当てはめは入力を に正規化する numpy.polynomial.Polynomial.fit を使っています。
⚠️ よくある誤解
- バイアスとバリアンスは「1本のデータ」では測れない。両者とも訓練データを取り替えたときの期待値で定義される量です。だから多数の訓練セットを作る実験が必要になります。1本のモデルの当てはまりを見ても分解はできません。
- 「総誤差=バイアス²+バリアンス」ではない。ノイズ が必ず残ります。どんなに次数を最適化しても総誤差は を下回れません(既約誤差)。
- U字の谷=正解の次数、とは限らない。谷の次数はノイズ量・データ量・テスト点の取り方で動きます。実験はあくまで「与えた設定での」最適点を示すもので、普遍の正解次数があるわけではありません。
- 高次数で必ず破綻するわけでもない。正則化を強くかけると高次数でもバリアンスを抑えられ、U字が平らになります。次数とバリアンスは「正則化なしなら」連動する、という条件付きの話です。