🎓 レベル:標準 | 重要度:A(必須)
📎 前提:重回帰と多重共線性・汎化と過学習・バイアスバリアンス分解 | 数理:最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論)(統計)・正則化(リッジ・Lasso)(統計)
要点(BLUF)
- 正則化は「係数の大きさにペナルティを足す」ことで、過学習(高バリアンス)を抑えてモデルを安定させる手法です。
- Ridge(L2) は係数を全体的に縮め(0には絶対しない)閉形式解 を持ち、Lasso(L1) は不要な係数をきっちり 0 にして自動で特徴選択します。
- 両者の併用が Elastic Net。 は交差検証で選び、ベイズ的には L2=ガウス事前、L1=ラプラス事前の MAP推定 と解釈できます。
1. なぜ正則化するのか
重回帰と多重共線性 で見たように、特徴量が多い・相関が強いと最小二乗推定 は 係数が暴れて巨大になり、訓練データのノイズまで拾ってしまいます。これは 汎化と過学習・バイアスバリアンス分解 でいう 高バリアンス=過学習の状態です。
正則化のアイデアは単純です。「データへの当てはまり」だけでなく「係数の大きさ」もコストに含める。当てはまりを少し犠牲にしてでも係数を小さく保てば、データが変わっても予測が安定し、バリアンスが下がります。
要するに:「データに合わせろ、ただし係数は欲張るな」という綱引きを、ハイパーパラメータ で調整します。これは「少しのバイアスを足して大きなバリアンスを消す」取引です。
なら通常の最小二乗、 なら係数はすべて 0 に押し潰されます。間のどこかに汎化誤差の谷(U字の底)があります。
2. Ridge(L2正則化)
ペナルティに 係数の二乗和(L2ノルムの二乗)を使います:
これは について微分して 0 と置くと 閉形式(解析解) が得られます:
要するに:OLS の の中身に を足しただけです。この が効きます。 が(多重共線性で)ほぼ特異=逆行列が不安定でも、対角に正の を加えることで必ず正則(可逆)になり、解が安定します。OLS が解けない場面でも Ridge は必ず解ける、これが実務上の大きな利点です。
特徴量を直交化した( の)理想ケースで見ると本質がはっきりします:
つまり Ridge は各係数を 一律の比率 で縮めるだけ。どの係数も小さくはなりますが、ちょうど 0 になることはありません。これが Ridge の限界(=特徴選択はできない)です。
3. Lasso(L1正則化)とスパース性
ペナルティを 係数の絶対値の和(L1ノルム)に変えます:
たった「二乗」を「絶対値」に変えただけですが、結果は劇的に変わります。Lasso は重要でない係数を厳密に 0 にする——つまり自動で特徴選択を行い、スパース(疎)な解を作ります。L1 は微分不可能な「角(キンク)」を に持つため閉形式解はなく、座標降下法などで解きます。
直交化ケースでは Lasso の解は ソフト閾値処理(soft-thresholding) という美しい形になります:
ここで 。
要するに:すべての係数を だけ 0 方向へ引き、引いた結果が負になったら 0 で止める。「OLS の絶対値が 以下の弱い係数は問答無用で 0」になる。これが Lasso がスパースになる仕組みです。Ridge が「比率で縮める」のに対し、Lasso は「一定量だけ引いて 0 で打ち切る」点が決定的に違います。
なぜ角で 0 になるのか(制約領域の幾何)
正則化は「ペナルティ付き最小化」ですが、等価な 制約付き最小化 として描けます——「残差二乗和を最小化せよ、ただし係数の大きさが一定以下」。この制約領域の形が運命を分けます:
- L2(Ridge): = 円(球)。角がなく滑らか。
- L1(Lasso): = 菱形(高次元では超八面体)。軸上に尖った 角がある。
残差二乗和の等高線(楕円)が外側から膨らんで制約領域に最初に触れる点が解です。菱形は角が軸上に飛び出しているため、楕円は高確率でこの角に接します。角では片方の座標がちょうど 0——だから Lasso は 0 を生むのです。円には角がないので、接点が軸上に来る確率は実質ゼロ=Ridge は 0 を作りません。
graph LR
subgraph L2["L2 Ridge:制約は円"]
C(("β2軸 ↑ ─ β1軸 →<br/>円と楕円の接点は<br/>軸を外れる → 0にならない"))
end
subgraph L1["L1 Lasso:制約は菱形"]
D{"β2軸 ↑ ─ β1軸 →<br/>角が軸上にあり<br/>楕円が角に接しやすい → β=0"}
end
図:L1 の菱形は軸上に角を持つため、損失の等高線(楕円)が角に接して片方の係数が 0 になる。L2 の円は滑らかで、接点が軸に乗りにくいので 0 になりにくい。
4. Elastic Net(L1 + L2)
Lasso には弱点があります。強く相関する特徴が群れでいると、Lasso はその中から 1 本だけ気まぐれに残し他を 0 にする(選択が不安定)。また特徴数 がサンプル数 を超えると最大 個までしか選べません。
Elastic Net は L1 と L2 を足し合わせて両者の良いとこ取りをします:
- L1 項がスパース性(特徴選択)を、
- L2 項が安定性と グルーピング効果(相関する特徴をまとめて残す/落とす)を担います。
scikit-learn では と混合比 で書き、 で純 Lasso、 で純 Ridge、間が Elastic Net になります(ライブラリにより記法が違うので要確認)。
要するに:「相関する特徴を群れごと扱いたい、でもスパースさも欲しい」というときの折衷案。高次元・相関の強いデータで Lasso 単体より頑健に効きます。
5. λ の選び方(交差検証)
は学習で決まらない ハイパーパラメータなので、訓練誤差で選んではいけません( が常に最小になる)。標準的には 交差検証で、複数の 候補について検証誤差を測り、最小(または「最小から1標準誤差以内で最もスパースな 」=1-SEルール)を選びます(→ 訓練・検証・テストと交差検証)。
flowchart LR
A["λ候補を多数用意<br/>(対数スケール)"] --> B["各λで交差検証<br/>検証誤差を測定"]
B --> C["検証誤差が最小<br/>のλを採用"]
C --> D["全データで再学習<br/>→ 最終モデル"]
補足:正則化はスケール依存です。係数の大きさを比べる以上、特徴量を標準化してから掛けないと、単位の大きい特徴ほど不当に強くペナルティされます。切片項には通常ペナルティを掛けません。
6. MAP推定としての解釈(ベイズの視点)
正則化は天下りの工夫ではなく、事前分布を置いた最大事後確率(MAP)推定として自然に導けます。誤差をガウスとした線形モデルの対数事後確率は、
最尤推定(最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論))に「事前分布 」が足されるだけ。この事前の形がペナルティの正体です:
- L2(Ridge)=ガウス事前 。 となり、(ノイズ分散 ÷ 事前分散)。事前分散 が小さい=「係数は 0 付近のはず」という強い信念ほど が大きくなります。
- L1(Lasso)=ラプラス事前 。。ラプラス分布は 0 で尖った鋭いピークを持つため、「多くの係数はちょうど 0」という事前信念を表し、スパース性に対応します。
要するに:Ridge は「係数はゼロ近くに緩く集まる」、Lasso は「係数の多くはピッタリ 0」という事前知識を数式に翻訳したもの。正則化=事前分布、ペナルティの強さ =事前の強さ、と読み替えられます(統計側の議論は 正則化(リッジ・Lasso))。
7. 三手法の比較
| Ridge(L2) | Lasso(L1) | Elastic Net | |
|---|---|---|---|
| ペナルティ | 両方 | ||
| 解の形 | 閉形式あり | 閉形式なし(座標降下等) | 閉形式なし |
| 係数を 0 にする | しない | する(スパース) | する |
| 特徴選択 | 不可 | 可 | 可 |
| 相関特徴 | まとめて縮小 | 1本だけ残しがち | 群れで残す |
| 事前分布 | ガウス | ラプラス | 両者の混合 |
| 制約領域 | 円 | 菱形 | 角が丸い菱形 |
使い分けの目安:全特徴を残しつつ安定させたい→Ridge、自動で特徴を絞りたい→Lasso、高次元かつ特徴が相関→Elastic Net。
⚠️ よくある誤解
- 「Ridge も係数を 0 にできる」は誤り。Ridge は 0 へ漸近的に近づけるだけで、厳密な 0 は作りません。0 にして特徴を捨てたいなら L1 が必要です。
- 「正則化すれば必ず精度が上がる」ではない。 が大きすぎると過度に縮めてバイアスが増え、未学習になります。U字の谷を交差検証で探すのが本筋です。
- 標準化を忘れる。特徴のスケールが揃っていないと、ペナルティが単位の大きい特徴に偏ります。掛ける前に標準化が前提です。
- 「Lasso は常に Ridge より良い」ではない。真に効く特徴が多い(密な真値)なら Ridge が勝ち、本当に少数しか効かない(疎な真値)なら Lasso が勝ちやすい、と真の構造に依存します。
- λ を訓練誤差で選ばない。訓練誤差は で最小。必ず検証誤差(交差検証)で選びます。
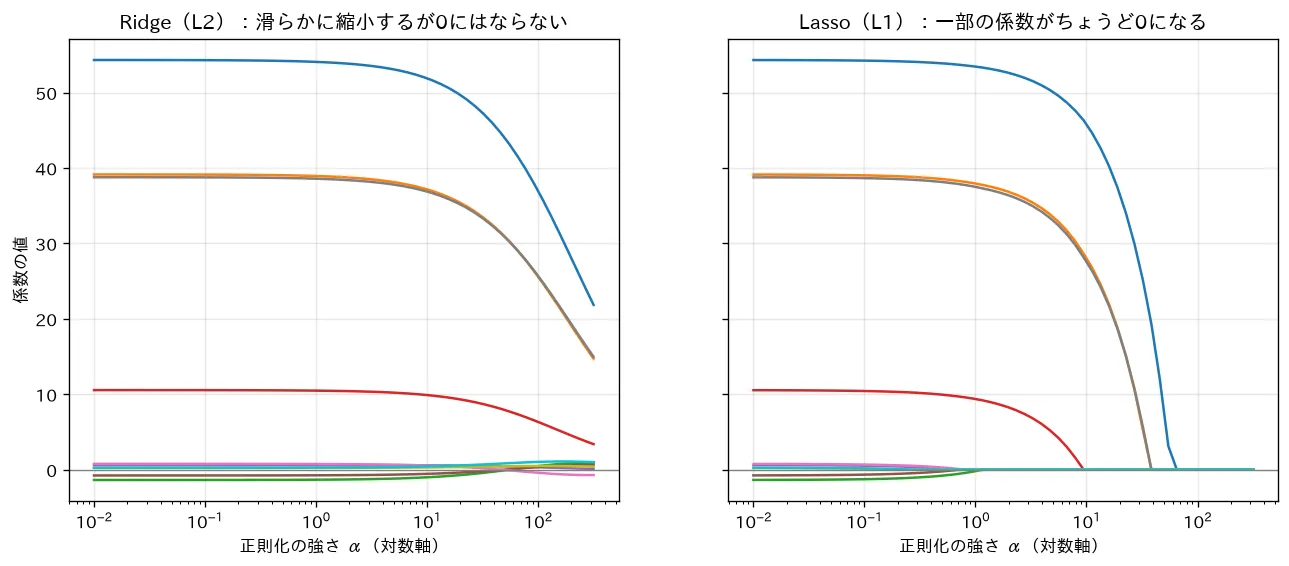
対応するシミュレーション
simulations/regularization_path.py:本当に効く特徴が一部だけの回帰データで、正則化の強さ を対数スケールで振りながら Ridge と Lasso の係数パスを描きます。Ridge は全係数を滑らかに へ縮小する一方、Lasso は無関係な特徴の係数を途中でちょうど にする(スパース=変数選択)ことを可視化します(幾何的な理由は 正則化の理論)。
関連ノート
- 線形回帰(最小二乗法と確率的解釈)
- 重回帰と多重共線性
- 汎化と過学習・バイアスバリアンス分解
- 訓練・検証・テストと交差検証
- 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論)(統計・MAP/最尤の土台)
- 正則化(リッジ・Lasso)(統計・正則化の数理)
- 教師あり学習・回帰 目次
- 機械学習テキスト 全体目次