🎓 レベル:発展 | 重要度:A(必須)
📎 前提:正則化(Ridge・Lasso・Elastic Net)(実践) | 数理:ベイズ推定・MAP推定(統計, MAP)
要点(BLUF)
- 正則化は見かけ上ばらばらな道具に見えますが、「複雑さ(係数の大きさ)にペナルティを課す=事前知識を入れる」という一つの理論でL1・L2・早期終了がすべて説明できます。
- 中心になる等価性は 正則化 = MAP推定。負の対数事後確率を分解すると「損失=負の対数尤度」「正則化項=負の対数事前」になり、L2はガウス事前、L1はラプラス事前から自然に出ます。
- L1がスパースになるのは制約領域(ボール)の角が軸上にある幾何のため。早期終了は係数が育ちきる前に止めることで、近似的にL2と同じ縮小をかけます。
このノートは「なぜ効くか」の理論に集中します。Ridge/Lassoの解の形・soft-thresholding・λの選び方・Elastic Netといった実践は 正則化(Ridge・Lasso・Elastic Net) にあります。
1. 動機:正則化はバリアンスを下げる取引
正則化が解こうとしている問題は、汎化と過学習・バイアスバリアンス分解 の言葉では明快です。特徴量が多い・相関が強いと、当てはめだけを追う推定量(最小二乗・最尤)は係数が暴れて巨大化し、訓練データのノイズまで再現してしまう——これが**高バリアンス(過学習)**です。
正則化は「係数を小さく保て」という圧力を足すことで、少しのバイアスと引き換えに大きなバリアンスを消す取引をします。汎化誤差 バイアス バリアンス ノイズ という分解で、第2項を削るために第1項をわずかに増やす、という最適化です。
要するに: は「データへの忠実さ」と「モデルの単純さ」を天秤にかけるダイヤルです。 なら無正則化(高バリアンス側)、 なら (高バイアス側)。汎化誤差はこの間でU字を描き、底が最適な強さです。
2. 正則化 = 制約付き最適化(ラグランジュ双対)
ペナルティ付き最小化は、制約付き最小化と表裏一体です。これが幾何の議論の出発点になります。
なぜ等価か(導出):右の制約付き問題のラグランジアンは です。最適解では KKT 条件が成り立ち、 について停留する条件は
となります。これは左のペナルティ付き問題 の停留条件とまったく同じ式です。 は に依存しない定数なので最小化に影響しません。よってある に対応するラグランジュ乗数 が必ず存在し、両問題は同じ解を与えます。
要するに: と制約半径 は一対一で対応し、 を上げることは制約 を縮める(許される係数の大きさを絞る)ことに等しい。。だから「ペナルティを強める=係数が動ける箱を小さくする」と読み替えられます。この「箱の形」が次節の主役です。
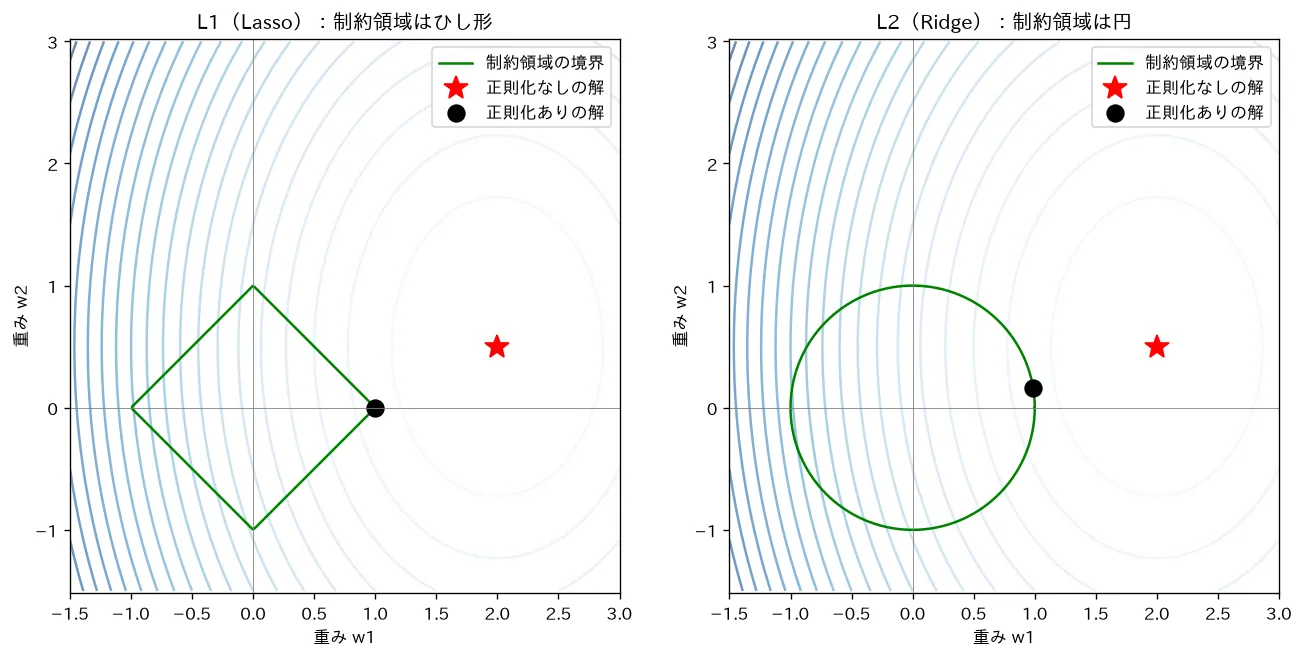
3. L1とL2の幾何:なぜLassoだけスパースになるか
制約版で見ると、 が動ける領域(制約領域)の形がノルムごとに違います:
- L2(Ridge): = 球(2次元なら円)。表面はどこも滑らかで角がない。
- L1(Lasso): = 超八面体(2次元なら菱形、ボール)。軸上に尖った角を持つ。
解は「損失 の等高線(最小二乗なら楕円)が、外側から膨らんで制約領域に最初に触れる点」です。ここで形が運命を分けます。
graph TB
subgraph L2["L2 Ridge:制約は球(円)"]
A["損失の等高線(楕円)が<br/>滑らかな円周に接する"] --> B["接点は軸を外れた一般の点<br/>→ どの係数も非ゼロ(縮むだけ)"]
end
subgraph L1["L1 Lasso:制約は菱形(ℓ1ボール)"]
C["菱形の角が<br/>軸上に飛び出している"] --> D["楕円は高確率で角に接する<br/>→ 角では片方の座標が厳密に0"]
D --> E["スパース解(自動で特徴選択)"]
end
図:L1の菱形は軸上に角を持つため、損失の等高線が角に接して片方の係数が厳密に0になる(スパース化)。L2の円は滑らかで、接点が軸にちょうど乗る確率は実質ゼロなので、Ridgeは縮めはしても0は作らない。
もう一段の理由(劣勾配で見る):1変数で ( は無正則化解)に L1 を足した を考えます。 は で微分できず、劣勾配が の幅を持ちます。 が最小になる条件は 、すなわち のとき。
要するに:L1は原点で「 の死角」を持つので、無正則化解が 以下の弱い係数は問答無用で0に吸い込まれます。L2のペナルティ は原点で勾配が0なので、この死角がなく0を作る力がありません。幾何(角)と劣勾配(死角)は同じことを別の言葉で言っています。
4. MAP推定との等価性(このノートの中心)
正則化は天下りの工夫ではなく、事前分布を置いた最大事後確率(MAP)推定そのものです。ベイズの一般論(尤度・事前・事後・ベイズ更新)は統計側 ベイズ推定・MAP推定・事前分布・事後分布・ベイズ更新 に譲り、ここでは「正則化項がどこから出るか」の導出だけを示します。
4.1 負の対数事後の分解
ベイズの定理 の両辺の対数をとり、 を掛けます。 は に依存しない定数なので落とせます:
MAP推定は左辺の最小化(事後確率の最大化)です。最尤推定(事前なし)に が足されるだけ。この事前の形がペナルティの正体です。回帰で誤差を等分散ガウス とすると、第1項は
となり、おなじみの二乗誤差が出ます(→ 線形回帰(最小二乗法と確率的解釈) の確率的解釈)。残りは事前 を何にするか、です。
4.2 L2 ⇔ ガウス事前
各係数に平均0・分散 のガウス事前 を置きます:
これを 4.1 の損失に足すと、。両辺を 倍で整理すると、まさに Ridge の目的関数で、正則化強度は
要するに:ガウス事前の対数は 、つまりL2そのもの。 は「ノイズ分散 ÷ 事前分散」で、事前分散 が小さい(=「係数は0付近のはず」という強い信念)ほど が大きく、強く縮みます。
4.3 L1 ⇔ ラプラス事前
各係数に平均0・スケール のラプラス事前 を置きます:
これを足すと Lasso の目的関数になり、強度は (定数倍の取り方で 等と書く流儀もあります)。
要するに:ラプラス事前の対数は 、つまりL1そのもの。ラプラス分布は0で尖った鋭いピークを持ち、ガウスより0近傍に確率が集中します。これが「多くの係数はちょうど0」という事前信念を表し、3節のスパース性に対応します。
graph LR
G["ガウス事前 N(0,τ²)<br/>なだらかな山"] -->|"−log で"| GL["L2 ペナルティ<br/>Σθ²(滑らか・縮小)"]
L["ラプラス事前 Laplace(0,b)<br/>0で尖る"] -->|"−log で"| LL["L1 ペナルティ<br/>Σ|θ|(角・スパース化)"]
図:事前分布の「形」がペナルティの「形」を決める。0で尖るラプラスは0を強く好み、なだらかなガウスは0付近に緩く集めるだけ。
4.4 注意:MAP は事後の「点」にすぎない
MAP は事後分布の最頻値(モード)を1点取るだけで、フルベイズ(事後全体で平均・不確実性を扱う)ではありません。とくにL1では、事後の平均はスパースになりませんが、モードはスパースになります(だからLassoの点推定は0を作る)。この区別は統計側 ベイズ推定・MAP推定 で扱います。
5. 早期終了(early stopping)は近似的にL2
明示的なペナルティを足さなくても、勾配降下を途中で止めるだけで正則化と同じ効果が得られます。「係数が大きく育つ前に学習を打ち切る=大きさを制限する」という直観を、二次近似で定量化できます。
最適点 のまわりで損失を二次近似します(ヘッセ行列 ):
は対称半正定値なので、固有値分解 で固有ベクトル方向ごとに独立な1次元問題に分解できます。各方向 (固有値 )で、 から学習率 の勾配降下を ステップ回すと、その方向の成分は
へ向かいます( なら で無正則化解 に収束)。一方、同じ問題のL2正則化(強度 )の解は方向ごとに
と同じ係数 を縮める形になります。2つの縮小係数 と を等しいと置き、 かつ で対数展開 を使って解くと、両者が一致する条件は
要するに:反復回数 が正則化強度の逆数として効きます。早く止める( 小)=強いL2( 大)、長く回す( 大)=弱いL2( 小)。学習軌道は、固有値の大きい(曲率が急=重要な)方向から先に伸び、固有値の小さい方向は最後まで小さいまま——だから途中で止めると、L2が小さい固有値方向を強く縮めるのと同じことになります。
厳密な等価は「線形モデル+二次損失+方向ごとに を調整」という条件下の話で、一般の非凸な深層学習では近似にすぎません。それでも early stopping が最も使われる正則化である理由(計算が只・ハイパラ1個)を、この理論が裏づけます。
6. まとめ:一つの視点に統一する
L1・L2・早期終了は別々の道具に見えて、「複雑さ(=事前知識)による制御」という一本の理論で繋がります。
graph TB
R["正則化<br/>min L(θ) + λΩ(θ)"]
R --> C["制約付き最適化<br/>min L s.t. Ω(θ)≤t(ラグランジュ)"]
R --> M["MAP推定<br/>−log p(θ|D)=損失+負の対数事前"]
M --> ML2["L2 ⇔ ガウス事前 N(0,τ²)"]
M --> ML1["L1 ⇔ ラプラス事前 Laplace(0,b)"]
R --> E["早期終了<br/>τステップで打ち切り ≈ L2(α≈1/(τε))"]
C --> G["幾何:球は縮小・菱形の角はスパース化"]
style R fill:#e3f2fd
style M fill:#fff3e0
- 制約の視点: は係数が動ける箱の大きさ を決める。箱の形(球か菱形か)がスパース性を決める。
- ベイズの視点:正則化=事前分布、=事前の強さ。事前の形(ガウスかラプラスか)がL2/L1を決める。
- 最適化の視点:早期終了は学習軌道を途中で止めることで、追加のペナルティなしに同じ縮小を実現する。
どの視点も「当てはめだけを追わず、係数の複雑さに事前知識で制約をかける」という同じ思想の現れです。汎化がなぜ改善するかの一般論は 汎化理論 へ繋がります。
⚠️ よくある誤解
- 「L1が常に最良のスパース化」ではない。L1は凸緩和(本当に最小化したい =非ゼロ個数の代理)で、強相関の特徴では1本だけ気まぐれに残すなど、必ずしも真にスパースな正解を選びません。真の構造が密ならL2が勝ちます。
- ()は理論式で決めない。 は解釈の式であって、実際は を知らないので交差検証で選びます(→ 訓練・検証・テストと交差検証)。早期終了の も検証誤差の最小点で止めます。
- 標準化が前提。MAPで全係数に同じ事前分散 を置く=特徴のスケールが揃っている前提です。スケールがバラバラだと、単位の大きい特徴ほど不当に強く(または弱く)ペナルティされます。切片には通常ペナルティを掛けません(無情報事前に相当)。
- 「MAP=フルベイズ」ではない。MAPは事後のモードを1点取るだけ。不確実性の定量化や予測分布が欲しいならフルベイズが必要です(4.4/ベイズ推定・MAP推定)。
- 「早期終了は厳密にL2」ではない。等価は線形+二次近似下の近似。非凸な深層学習では「近い挙動」にとどまり、初期値・学習率・軌道に依存します。
対応するシミュレーション
simulations/l1_l2_geometry.py:損失の等高線(楕円)が制約領域に最初に触れる点が解になる、という見方で L1(ひし形)と L2(円)の制約領域を可視化します。L1 の解は軸上の角に当たって片方の係数がちょうど になる(スパース)一方、L2 の解は両方とも にはならないことを、数値解(L1: /L2: )とグラフで確認できます。
関連ノート
- 最適化と学習理論 目次
- 正則化(Ridge・Lasso・Elastic Net)(実践:解の形・soft-thresholding・λ選択)
- 汎化と過学習・バイアスバリアンス分解
- 汎化理論
- 線形回帰(最小二乗法と確率的解釈)
- 訓練・検証・テストと交差検証
- ベイズ推定・MAP推定(統計・MAP/最尤の土台)
- 事前分布・事後分布・ベイズ更新(統計・ベイズの一般論)
- 機械学習テキスト 全体目次