📊 対象級:準1級 ・ 1級 | 重要度:B(標準)
要点(BLUF)
ベイズ推定では、データを観測したあとの分布である事後分布 がすべての答えを持っています。ただ「分布まるごと」では報告しづらいので、1つの値に要約したいことがあります。これが点推定です。要約のしかたは3つあり、どれを選ぶかは「どんな損失関数で間違いを測るか」で決まります。
要するに「損失関数を決めれば、最適な点推定は自動的に1つに決まる」ということです。準1級ではこれらの計算と信用区間、1級ではこの最適性そのもの(ベイズリスクの最小化)を導けるかが問われます。
1. なぜ点推定が要るのか
ベイズ推定の出発点は事後分布です(導出は 事前分布・事後分布・ベイズ更新)。ベイズの定理から
事後分布は「 がどのあたりにありそうか」をすべて語っているので、本来はこれを丸ごと報告するのが理想です。しかし「結局 はいくつなの?」と1つの数字を求められる場面(論文の点推定値、システムへの代入値)では、分布を1点に要約しなければなりません。
ここで問題になるのが「どの1点を選ぶか」です。事後分布が左右対称の山なら平均でも中央値でも頂点でも同じですが、歪んだ分布だと3つはバラバラになります。どれを選ぶべきかは、後で見るように「間違いをどう罰するか(損失関数)」で決まります。
2. 統計的決定理論の枠組み(1級の土台)
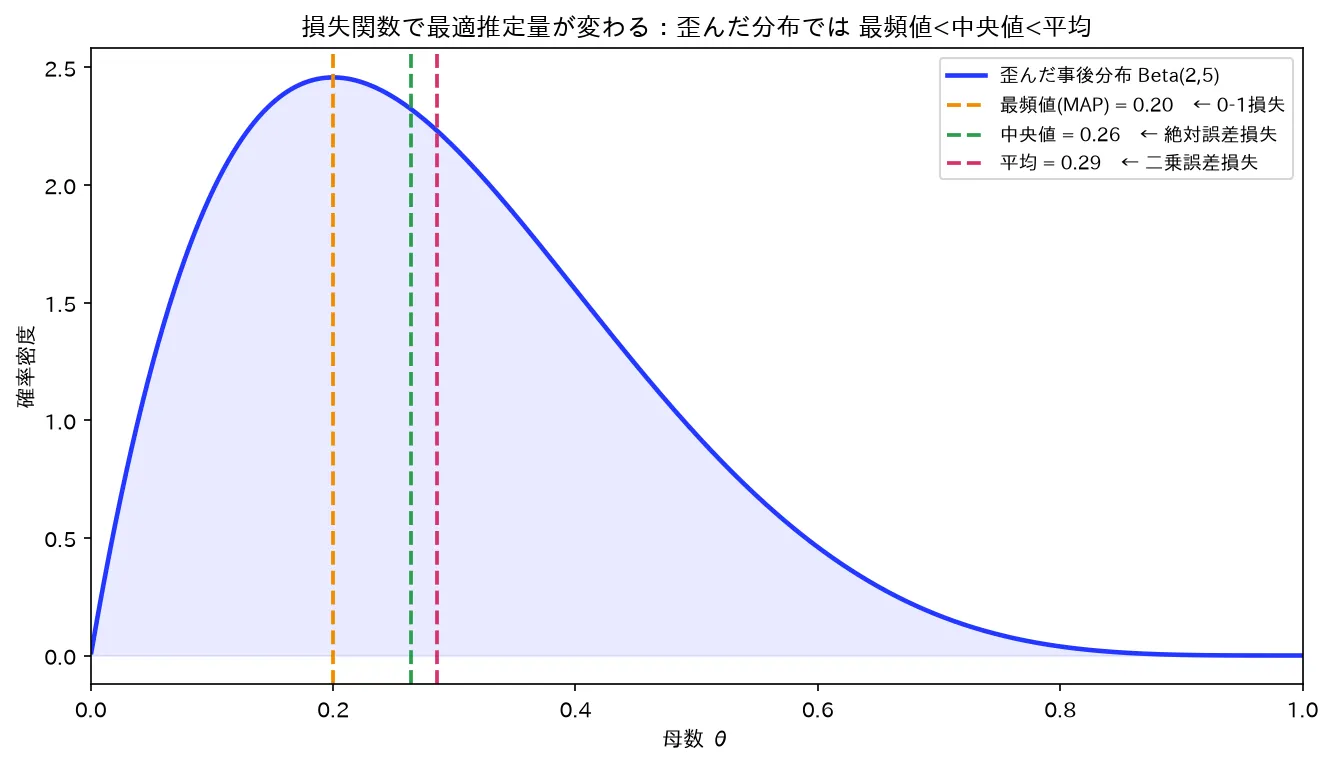
歪んだ事後 Beta(2,5) では 最頻値(0.20)<中央値(0.26)<平均(0.29)。二乗誤差損失→平均、絶対誤差→中央値、0-1損失→最頻値(MAP)。図は simulations/loss_suiteiryo_keijou.py で生成。
3つの点推定が損失関数に対応する仕組みを理解するには、まずベイズリスクと事後リスクを定義します。ここは1級の理論問題で直接問われる部分です。
2.1 損失関数とリスク関数
推定値を (データ から決める推定量)、真の値を とします。損失関数 は「 を と推定したときの罰」です。
これをデータの分布で平均したものがリスク関数(頻度論的リスク)です。
要するに「真の を固定したとき、データのばらつきも込みで平均してどれだけ損するか」です。
2.2 ベイズリスク
リスク関数はまだ の関数なので「どの推定量が一番良いか」を一意に決められません( ごとに勝ち負けが変わる)。そこで事前分布 で平均します。これがベイズリスクです。
ベイズリスクを最小にする推定量 をベイズ推定量と呼びます。要するに「事前の重みも込みで、平均的に一番損が小さい推定方式」です。
2.3 ベイズリスク → 事後リスクへの分解(最重要)
ここがすべての鍵です。ベイズリスクの積分の順序を入れ替えます。
途中で同時分布を ( は の周辺分布)と書き換えました。
中括弧の中が事後リスク(事後期待損失)
です。 なので、各 ごとに事後リスクを最小化すれば、ベイズリスク全体も最小化されることがわかります。
これが核心:ベイズ推定量は「観測した のもとで、事後分布に関する期待損失を最小にする点」を選べばよい。頻度論の積分(データ全体での平均)を考えなくていい——目の前のデータに対する事後分布だけ見ればよい、ということです。これがベイズの実務的なありがたみです。
以降、損失関数 を具体的に入れて、最適な点推定を求めます。
3. 二乗誤差損失 → 事後平均(導出)
二乗誤差損失 を使います。事後リスクは
これを で最小化します。やり方は2通りあり、どちらも同じ結論になります。
方法A:微分してゼロと置く
で微分します(期待値の中の微分は に対してだけ効きます)。
ゼロと置くと
二階微分は なので、これは確かに最小です。
方法B:分散・期待値への分解(こちらが定石)
事後リスクを「 からのズレ」で書き直します。
(交差項は より消えます。)第1項は事後分散で に依存しません。第2項は二乗なので のときちょうどゼロになり最小です。
要するに「二乗で罰すると、最適な要約は事後平均」。これは「データのばらつきを二乗誤差で測れば最良の予測は平均値」という、回帰や条件付き期待値(点推定(推定量の良さ:不偏性・一致性・有効性・十分性) の MSE)でおなじみの事実の、ベイズ版です。慣例として、単に「ベイズ推定量」と言えばこの事後平均を指すことが多いです。
4. 絶対誤差損失 → 事後中央値(導出)
絶対誤差損失 を使います。事後リスクは
これを で微分します。 は で つまり傾き ( に関して)、 で傾き なので、
ゼロと置くと
要するに「絶対値で罰すると、最適な要約は事後中央値」。事後分布を左右半々に割る点です。直観的には「絶対誤差は外れ値(裾の遠い値)を二乗ほど重く罰しない」ので、平均より裾の影響を受けにくい中央値が選ばれる、と理解できます。
5. 0-1損失 → MAP推定(導出)
0-1損失は「ピタリ当たれば損失0、外れたら損失1」です。連続パラメータでは、推定値の周りの微小幅 だけ許す損失
を考え、 の極限を取ります。事後リスクは「許容幅の外にある確率」
これを最小化するには第2項(許容幅内に入る事後確率)を最大化すればよく、 が小さいとき
なので、事後密度 が最大の点を選ぶのが最適です。これが**MAP推定(最大事後確率推定, Maximum A Posteriori)**です。
要するに「外す/外さないの0-1で罰すると、最適な要約は事後分布の山頂(最頻値)」。離散パラメータなら そのもので、事後確率最大のカテゴリを選ぶ、という素直な話になります。
flowchart LR
subgraph 損失関数
L1["二乗誤差<br/>(θ−d)²"]
L2["絶対誤差<br/>|θ−d|"]
L3["0-1損失<br/>1(θ≠d)"]
end
subgraph 最適な点推定
E1["事後平均<br/>E[θ|x]"]
E2["事後中央値<br/>median(θ|x)"]
E3["MAP<br/>argmax π(θ|x)"]
end
L1 == 最小化 ==> E1
L2 == 最小化 ==> E2
L3 == 最小化 ==> E3
6. MAP と MLE の関係
MAP は事後密度の最大化です。事後分布は なので、対数を取って分母( に無関係な周辺尤度)を無視すると
一方、最尤推定(MLE, 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論))は
両者を見比べると、MAP は MLE の目的関数に事前項 を足しただけです。ここから2つの重要な帰結が出ます。
6.1 事前が一様なら MAP = MLE
事前分布が一様 なら は に依存しない定数になり、最大化に効きません。よって
要するに「事前知識が『どの値も平等』なら、MAP は MLE に一致する」。逆に言えば、MAP は「事前という追加情報で MLE を補正したもの」と読めます。
6.2 MAP は「正則化付き MLE」
事前項 は、極端な を罰して推定を引き戻す働きをします。これは機械学習の正則化項と数学的に同じものです。
| 事前分布 | (罰金項) | 対応する正則化 |
|---|---|---|
| ガウス | L2(リッジ) | |
| ラプラス(両側指数) | L1(ラッソ) |
要するに「MLE を最大化する代わりに、事前で重みを掛けて引き戻したのが MAP」。ガウス事前 ⇔ リッジ、ラプラス事前 ⇔ ラッソという対応は準1級〜1級で頻出の論点です(正則化(リッジ・Lasso) と裏表)。
⚠️ MAP は「点」を取るだけなので、事後分布を1点に潰してしまい不確かさ(分散)の情報を捨てます。これがフルベイズ(事後分布を丸ごと使う・事後平均を取る)との違いです。MAP は最適化問題(点を1つ探す)に帰着するため計算が軽い、というのが実務上の利点です。
7. 信用区間(credible interval)
点推定だけでなく、ベイズでは「区間」で不確かさを報告できます。**信用区間(credible interval)**は、事後分布で確率 を占める区間です。
区間の取り方は主に2つあります。
- 等裾区間(equal-tailed):両裾をそれぞれ ずつ切る。事後分布の 分位点と 分位点。計算が素直で準1級ではこちらが中心。
- 最高事後密度区間(HPD, Highest Posterior Density):同じ確率 を含む区間のうち幅が最短になるもの。事後密度がしきい値以上の領域。歪んだ分布で等裾区間とずれる。
信頼区間との解釈の違い(最重要・頻出)
信用区間(ベイズ)と信頼区間(頻度論, 区間推定(母平均・母比率・母分散の信頼区間))は、見た目の「95%区間」が同じでも解釈が決定的に違います。
| 信用区間(ベイズ) | 信頼区間(頻度論) | |
|---|---|---|
| 何が確率変数か | (区間は固定) | 区間の端点( は固定の定数) |
| 「95%」の意味 | この区間に が入る確率が95% | 同じ手続きを繰り返すと95%の区間が真値を覆う |
| 直接言えるか | 言える:「 が にある確率は95%」 | 言えない:個々の区間が真値を含む確率は0か1 |
要するに「信用区間は、誰もが言いたくなる『 がこの区間にある確率が95%』を本当に言える」。頻度論の信頼区間ではこの言い方は誤り(区間ごとに当たり外れが決まっており、確率はあくまで手続きの長期的な被覆率を指す)です。直観に合う解釈ができるのがベイズ信用区間の強みです。
⚠️ 「95%信頼区間 = 真値がそこにある確率95%」は頻度論では誤解です。この直接的解釈ができるのは信用区間(ベイズ)だけ。準1級・1級でこの区別はよく問われます。
8. 引っかけ・頻出論点
- ⚠️ 損失関数で最適な点推定が変わる:二乗→平均、絶対→中央値、0-1→MAP(最頻値)。「ベイズの点推定=事後平均」と覚えていると、絶対誤差損失や0-1損失の問題で間違えます。
- ⚠️ MAP は事後平均と一般に一致しない:事後分布が対称(正規など)なら平均=中央値=最頻値で一致しますが、歪んだ事後(指数・ガンマ・ベータの非対称形など)では3つは乖離します。「MAP=事後平均」は誤り。
- ⚠️ 信用区間 ≠ 信頼区間:解釈が違う(上表)。値が偶然近くても意味が違います。
- ⚠️ 事前が一様でないなら MAP ≠ MLE:事前項が効くので一般には一致しません。一致するのは一様事前(または平坦極限)のときだけ。
- ⚠️ MAP は不確かさを捨てる:点だけ返すので、事後分散・区間の情報は別途(信用区間など)で報告が必要。
試験での問われ方(級ごとの差)
ベイズ法は準1級・1級とも出題範囲ですが、毎回必ず出るわけではありません(出題範囲・配点は改訂されうるため要最新確認)。級で問われる深さが明確に違います。
準1級レベル
ここで問われるのは「計算と区別」。事後分布から事後平均・MAP を実際に計算できるか、信用区間を求められるか、信用区間と信頼区間の解釈の違いを答えられるか。
- 共役事前(共役事前分布)で得た事後分布から、事後平均・MAP を数値で計算する。例:ベータ事後 なら事後平均 、MAP ()。両者がずれることの確認。
- 信用区間の計算(等裾区間)と、信頼区間との解釈の違いを選ばせる。
- MAP と MLE の関係(一様事前で一致、正則化との対応)の定性的理解。
1級レベル
ここで問われるのは「理論と最適性」。損失関数・リスク関数・ベイズリスクを定義し、各損失に対してベイズ推定量が事後平均/中央値/MAP になることを自分で導出できるか。
- ベイズリスク → 事後リスクへの分解(第2節)を書き、二乗誤差損失でベイズ推定量が事後平均になることを導く(論述)。
- 絶対誤差損失で事後中央値になることの導出(微分して )。
- ベイズ推定量の最適性・許容性(admissibility)など決定理論の性質。一般の損失関数 に対する事後リスク最小化の枠組み。
推定量の評価の一般論は 点推定(推定量の良さ:不偏性・一致性・有効性・十分性)、最尤法との接続は 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論)、区間の頻度論側は 区間推定(母平均・母比率・母分散の信頼区間) が前提です。
よくある疑問(Q&A)
Q1. 「ベイズ推定量」と言われたら、事後平均・中央値・MAP のどれを指しますか?
文脈によります。損失関数を指定せずに「ベイズ推定量」と言えば、慣例的に二乗誤差損失に対応する事後平均を指すことが多いです。ただし統計的決定理論の文脈では「ベイズ推定量=指定された損失のもとでベイズリスクを最小にする推定量」という一般的な意味なので、損失が絶対誤差なら中央値、0-1なら MAP がベイズ推定量です。問題文に損失関数の指定があるかを必ず確認してください。
Q2. MAP と事後平均、結局どちらを使えばいいですか?
目的次第です。事後分布が対称ならどちらも同じなので悩む必要はありません。歪んでいる場合、(1) 二乗誤差で評価される・期待値として意味のある量なら事後平均、(2) 計算を軽くしたい・最適化として解きたい(高次元で積分が困難)ならMAP が便利です。ただし MAP は分布の山頂1点なので不確かさを捨てている点に注意。実務のフルベイズでは事後平均+信用区間で報告するのが標準的です。
Q3. MAP が「正則化付き MLE」とはどういう意味ですか?
MAP は です。第1項は MLE の対数尤度、第2項 が「事前」です。ガウス事前を入れると は (マイナスの二乗ペナルティ)になり、これはL2正則化(リッジ)とまったく同じ式です。ラプラス事前なら で**L1正則化(ラッソ)**に対応します。要するに「正則化項は事前分布の対数の符号反転」であり、機械学習の正則化はこっそりベイズをやっている、と読めます。
Q4. 95%信用区間と95%信頼区間は、同じ95%なのに何が違うのですか?
確率の宣言対象が違います。信用区間は「 がこの区間に入る確率が95%」と 自体について確率を述べられます( を確率変数として扱うベイズの立場)。信頼区間は「同じ手続きを無限回繰り返せば95%の区間が真値を覆う」という手続きの性質で、個々の区間が真値を含む確率は0か1( は固定の定数だから)です。多くの人が信頼区間を「真値がここにある確率95%」と誤解しますが、それを正しく言えるのは信用区間だけです。
Q5. 事後分布が左右対称なら、3つの点推定は本当に全部一致しますか?
はい。正規分布のように平均まわりに対称な単峰分布では、平均=中央値=最頻値(山頂)が一致するので、事後平均・事後中央値・MAP はすべて同じ値になります。だから「3つの違い」が問題になるのは非対称な事後分布のときだけです。例えばベータ事後 は左に偏るので、事後平均 と MAP は明確にずれます。試験ではこの非対称ケースが狙われます。
まとめ
- 事後分布 を1点に要約するのが点推定。損失関数で最適な点が決まる:二乗→事後平均、絶対→事後中央値、0-1→MAP。
- 仕組みはベイズリスク = ∫(事後リスク)·m(x)dx の分解。各 で事後リスクを最小化すればよく、二乗誤差損失なら より 。
- MAP は 。事前が一様なら MAP=MLE。事前項は正則化(ガウス⇔L2、ラプラス⇔L1)。MAP は事後を1点に潰し不確かさを捨てる。
- 信用区間は事後で確率 の区間。信頼区間と違い「 がここにある確率95%」と直接言える。
- 引っかけ:損失で点推定が変わる/MAP≠事後平均(歪んだ事後)/信用区間≠信頼区間。準1級は計算、1級は導出・最適性。
関連ノート
- 事前分布・事後分布・ベイズ更新 点推定の出発点となる事後分布の作り方
- 共役事前分布 事後分布が解析的に求まる組み合わせ(事後平均・MAP を計算する土台)
- 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論) MLE。MAP はこれに事前項を足したもの
- 点推定(推定量の良さ:不偏性・一致性・有効性・十分性) 推定量の評価(MSE・不偏性)。事後平均は二乗誤差最小という点推定一般論とつながる
- 区間推定(母平均・母比率・母分散の信頼区間) 頻度論の信頼区間。信用区間との解釈の違いの対比
- ベイズ統計・実験計画(Phase 7 目次) ベイズ統計・実験計画ドメインの全体地図