📊 対象級:準1級 | 重要度:B(標準)
要点(BLUF)
- 正則化とは、最小二乗の損失に罰則項を足して係数を 0 方向へ縮める(縮小推定する)手法。説明変数が多い・多重共線性があるときに最小二乗推定の分散が暴れるのを抑えます。
- **リッジ(L2)**は係数の二乗和を罰し、閉形式解をもちます。これが本ノートの中心結論です。
- Lasso(L1)は係数の絶対値和を罰し、係数をちょうど 0にできる(スパース性)ので変数選択になります。正則化は一般にバイアスを増やして分散を減らす取引で、強さは で調整し、 は交差検証で選びます。
1. なぜ正則化が要るのか(過学習と多重共線性)
最小二乗推定量
は、説明変数が多い・説明変数どうしが強く相関している(多重共線性)とき、極端に不安定になります。理由は にあります。
がほぼ特異(行列式がほぼ 0、=ある列が他の列の線形結合で近似できてしまう)になると、その逆行列 の成分が爆発的に大きくなります。推定量の分散は
なので、 が暴れる = 係数の分散が暴れる、ということです。要するに:データがほんの少し変わるだけで係数が大きく振れ、符号すら反転する。これが過学習(訓練データの偶然のノイズまで拾ってしまい、新しいデータで外す状態)の温床です。
正則化は、損失に「係数を大きくしすぎたら罰金」という項を足し、係数を 0 方向へ引き戻すことでこの不安定さを抑えます。
graph LR
A["説明変数が多い<br/>/多重共線性"] --> B["X^T X がほぼ特異"]
B --> C["(X^T X)^-1 が爆発"]
C --> D["OLS係数の分散が暴れる<br/>=過学習"]
D --> E["罰則項で係数を縮small"]
E --> F["分散が下がり安定"]
2. リッジ回帰(L2 正則化)
2.1 定義
リッジ回帰は、係数の二乗和(L2 ノルムの二乗)を罰則として足した最小化問題です。
ここで 、 は正則化パラメータ(罰則の強さ)です。要するに:「残差を小さくしたい」気持ちと「係数を小さく保ちたい」気持ちを で天秤にかけています。 なら普通の最小二乗、 なら係数は全部 0 へ押しつぶされます。
2.2 閉形式解の導出(省略しない)
目的関数を
と書きます。第1項を展開します。
要するに:ここまでは普通の最小二乗の展開に、末尾の が増えただけです。
で微分して 0 と置きます(ベクトル微分の公式 ( 対称)、 を使う)。
両辺を 2 で割って について整理します。
要するに:最小二乗の正規方程式 の左辺に が足されただけです。両辺に左から をかけて、
を得ます。
2.3 なぜ が多重共線性を救うのか
ここが理論の核心です。任意の行列 に対し は半正定値(固有値がすべて )です。多重共線性があると固有値のいくつかがほぼ 0 になり、これが逆行列を爆発させていました。
を足すと、 のすべての固有値が一律に だけ持ち上がります。 の固有値を とすると、 の固有値は になるからです。よって なら全固有値が となり、 は正定値=必ず可逆になります。要するに:ほぼ 0 だった固有値が 以上に底上げされ、逆行列の爆発が止まる。 がフルランクでなくても(説明変数の数 > データ数でも)リッジは解けます。これが「 で を正則化する」の意味です。
2.4 リッジは係数を縮めるが 0 にはしない
対角化して見ると分かります。 の特異値分解を使うと、リッジは最小二乗の各成分を 倍()に縮める操作になります。要するに:すべての係数を一律に 0 方向へ「比例縮小」しますが、係数が連続的に小さくなるだけで、有限の ではちょうど 0 にはなりません。これが次の Lasso との決定的な違いです。
3. Lasso(L1 正則化)とスパース性
3.1 定義
Lasso(Least Absolute Shrinkage and Selection Operator)は罰則を絶対値和(L1 ノルム)にします。
要するに:罰則を「二乗和」から「絶対値和」に変えただけ。ところがこの違いが、一部の係数をちょうど 0 にする(スパースな解=変数選択)という劇的な効果を生みます。Lasso には閉形式解はなく、座標降下法などで数値的に解きます。
3.2 なぜ L1 だけ角で 0 になるのか(制約領域の幾何)
最小化問題は、ラグランジュ双対により「制約付き最小化」と等価です。
要するに:「係数の入る範囲(制約領域)を決めて、その中で残差を最小化する」という見方です。
- 残差二乗和 の等高線は、最小二乗解 を中心とする楕円です。
- 制約領域は、L2(リッジ)では円()、L1(Lasso)ではひし形()です。
解は「楕円の等高線が制約領域に最初に触れる点」になります。ここで形が効きます。
- **円(リッジ)**は表面がなめらかで角がありません。楕円が触れる点は普通、軸上ではない一般の点になります。だから係数は小さくなっても 0 になりにくい。
- ひし形(Lasso)は座標軸上に尖った角を持ちます。楕円が外側から膨らんで触れるとき、なめらかな辺よりも尖った角に触れる確率が高い。角は軸上にあるので、そこでは片方の座標がちょうど 0になります。
要するに:尖った角=軸上=ある係数が 0、という幾何のため、Lasso は係数を 0 にします。次元 が増えるほどひし形の角(軸・座標部分空間)が増え、いっそう多くの係数が 0 に落ちます。これが「L1 はスパース、L2 はスパースでない」の正体です。
graph TB
subgraph L2["リッジ(L2):制約領域は円"]
R1["角が無くなめらか"] --> R2["楕円は軸外の一般点で接触"]
R2 --> R3["係数は縮むが 0 にならない"]
end
subgraph L1["Lasso(L1):制約領域はひし形"]
S1["座標軸上に尖った角"] --> S2["楕円は角で接触しやすい"]
S2 --> S3["角=軸上=係数がちょうど 0<br/>→ 変数選択"]
end
3.3 もう一段の裏付け:劣微分とソフト閾値
絶対値 は で微分できませんが、劣微分(subgradient)が使えます。説明変数が直交している特別な場合、Lasso の解は最小二乗解 にソフト閾値作用素を当てた形になります。
要するに:絶対値が小さい係数()は問答無用で 0 に潰し、大きい係数も一定量 だけ 0 方向へずらす。L1 罰則の勾配は係数の大きさによらず一定の押し(符号 )なので、最後まで 0 へ押し切れます。
対してリッジ(L2)の罰則の勾配は で、係数が小さくなるほど押す力も弱まる(0 に近づくと 0 に押す力も 0 に消える)。だから 0 ちょうどには到達しない。この勾配の違いが、幾何の「角 vs なめらか」の代数版です。
4. バイアス・バリアンストレードオフ
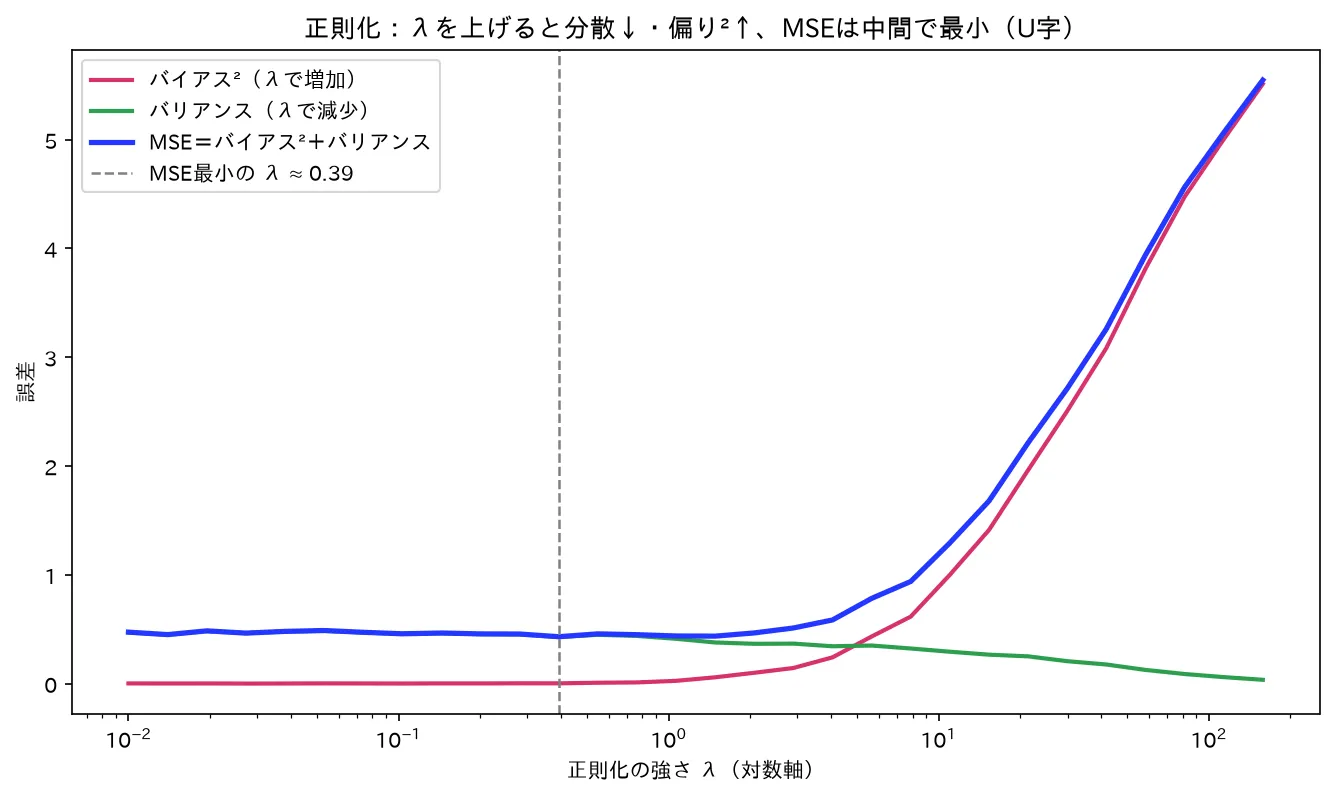
リッジ回帰で λ を上げると分散(緑)は下がるが偏り²(赤)は上がり、MSE(青)は中間の λ で最小(U字)。少し偏らせて分散を抑えると総合誤差が下がるのが正則化。図は simulations/seisokuka_bias_variance.py で生成。
正則化の効果は、推定量の良さを測る**平均二乗誤差(MSE)**の分解で説明できます。推定量の評価(MSE・フィッシャー情報量・クラメール・ラオの不等式) で見たとおり、
と分解されます。
- 最小二乗推定量は(仮定が満たされれば)不偏=バイアス 0 ですが、多重共線性下では分散が巨大で MSE が大きい。
- 正則化は係数を 0 へ引っ張るので、バイアスをわざと持ち込みます( は一般に偏った推定量)。その代わり分散を大きく下げます。
- を上げるほどバイアスは増え分散は減る。MSE はこの和なので、適度な でMSE が最小になる谷ができます。
要するに:正則化は「不偏だが暴れる推定量」を「少し偏るが安定した推定量」に取り替え、トータルの誤差(MSE)を下げる賭けです。下表は を動かしたときの典型的な振る舞いです(数値は概念図としての目安)。
| 係数の縮み | バイアス | 分散 | MSE | 状態 | |
|---|---|---|---|---|---|
| 0(最小二乗) | なし | 小(≈0) | 大 | 大 | 過学習寄り |
| 小 | 少し | 小 | 中 | 中 | 改善 |
| 適度 | 適度 | 中 | 小 | 最小 | ちょうど良い |
| 大 | 強い | 大 | さらに小 | 中〜大 | 過小適合(underfit) |
| 全部 0 | 最大 | ≈0 | 大 | 完全な過小適合 |
graph LR
L0["λ を 0 から増やす"] --> B["バイアス² は単調増加"]
L0 --> V["分散は単調減少"]
B --> M["MSE = バイアス² + 分散<br/>は U 字(谷あり)"]
V --> M
M --> OPT["谷の底の λ が最適<br/>(交差検証で探す)"]
5. の選択と Elastic Net
5.1 交差検証(クロスバリデーション)
はハイパーパラメータで、データから直接は推定できません。標準的には K 分割交差検証で選びます。
- 候補の を複数用意する。
- データを K 個に分け、K−1 個で学習し残り 1 個で予測誤差を測る、を K 通り回して平均する。
- 平均予測誤差が最小(または「最小から 1 標準誤差以内で最も簡素」の 1-SE ルール)の を採用する。
要するに:「未知データでの当たり具合」を擬似的に測り、それが最良になる罰則の強さを選ぶ、ということです。
5.2 Elastic Net(L1 + L2)
L1 と L2 を両方混ぜた罰則が Elastic Net です。
要するに:Lasso の変数選択(スパース性)と、リッジの「相関した変数たちをまとめて拾う安定性」のいいとこ取り。Lasso は強く相関したグループから 1 本だけ拾って他を捨てがちですが、Elastic Net は相関グループをまとめて残せます。準1級では「両者の折衷がある」程度の理解で十分です。
6. 具体例(直観をつかむ)
説明変数 がほとんど同じ情報(相関 0.99)を持ち、真のモデルが だとします。
- 最小二乗: の役割を区別できず、 が や のように大きく符号も不安定に振れる(合計だけ合わせようとして暴れる)。
- リッジ:罰則が両方を縮め、 のように相関ペアへ均等配分して安定。両方とも 0 にはならない。
- Lasso:片方を 0 に落とし、 のように1 本だけ残す(自動変数選択)。
要するに:多重共線性を「縮めて均す」のがリッジ、「片方を捨てて選ぶ」のが Lasso です。
7. 試験での問われ方(準1級)
準1級の出題範囲・ワークブックでは、過学習を抑える手法として「変数増減(ステップワイズ)/縮小推定/次元削減/正則化」が並びで扱われ、その中で L1(Lasso)・L2(リッジ)・Elastic Net が問われます(範囲表は改訂されうるため要最新確認)。
典型的な問われ方は次のとおりです。
- 罰則項の識別:「絶対値和を罰するのはどちらか」「係数を 0 にできるのはどちらか」を選ぶ。L1=Lasso=スパース=変数選択、L2=リッジ=縮小(0 にしない)の対応を即答できること。
- リッジ閉形式解: を書ける/ が逆行列を可逆化する理由を説明できる。
- 幾何の理解:制約領域がひし形(L1)/円(L2)で、Lasso が角で 0 になることを図で説明する問題。
- と当てはまり: を大きくすると係数が縮み、過大にすると過小適合(バイアス過大)になる、という方向の理解。 は交差検証で選ぶ。
- 前処理:罰則は係数のスケールに依存するため、説明変数を標準化してから当てはめる必要がある(後述の引っかけ)。
⚠️ 引っかけ・頻出論点
- リッジは 0 にしない/Lasso は 0 にする:ここを逆に覚えると一発で失点します。リッジは「0 に近づける(連続的に縮める)」、Lasso は「ちょうど 0 にする(変数選択)」。
- の向き: を大きく=罰則を強く=係数を縮める=バイアス増・分散減。大きすぎると過小適合(過学習ではない)。「 大で過学習」は誤り。
- 標準化を忘れる:罰則 や は係数の大きさを直接見るため、変数の単位(スケール)で罰金の効き方が変わります。単位が大きい変数は係数が小さく出て罰を受けにくい。だから説明変数を標準化(平均 0・分散 1)してから正則化するのが原則。切片は普通は罰則に含めません。
- 不偏性を捨てる:正則化推定量は一般に偏っています。「不偏で分散最小(最良線形不偏)」を目指す最小二乗とは設計思想が違い、わざとバイアスを入れて MSE を下げる立場です。
- 多重共線性の処方:相関の強い説明変数群がある回帰では、最小二乗より正則化(特にリッジや Elastic Net)が安定。 が特異に近くても で解ける、が理由。
よくある疑問(Q&A)
Q1. 「正則化=わざとバイアスを入れて分散を下げる」って、不偏性をあえて捨てているということ? A. はい、その理解で正しいです。最小二乗は(仮定下で)最良線形不偏推定量(BLUE)で、不偏性を死守する立場です。一方で正則化は不偏性をあえて手放し、係数を 0 へ縮めることでバイアスを受け入れる代わりに分散を大きく下げます。MSE = バイアス² + 分散 なので、分散の減り幅がバイアスの増え幅を上回れば、トータルの誤差は最小二乗より小さくできます。多重共線性のように分散が暴れている状況では、この取引が割に合います。
Q2. リッジと Lasso、結局どちらを使えばいい? A. 目的で使い分けます。変数を絞り込みたい(解釈したい・不要な変数を落としたい)なら Lasso(係数を 0 にして自動で変数選択)。全変数を残しつつ多重共線性を抑えて安定させたいならリッジ(すべて縮めるが 0 にしない)。相関の強い変数群をまとめて扱いたい、かつスパース性も欲しいなら Elastic Net。試験では「0 にしたい→L1、安定化→L2」の対応だけ押さえれば十分です。
Q3. を大きくしすぎるとどうなる? 過学習が進む? A. 逆です。 を大きくするほど係数は強く 0 へ縮められ、最終的に全係数が 0(=定数モデル)に近づきます。これは過小適合(underfitting)で、データの構造すら表現できなくなる状態です。過学習は が小さすぎる(罰則が弱く最小二乗に近い)ときに起きます。 は「過学習(小さすぎ)」と「過小適合(大きすぎ)」の間の谷を交差検証で探します。
Q4. なぜ正則化の前に説明変数を標準化するの? A. 罰則項が係数の絶対的な大きさを見るからです。例えば身長を「メートル」で測ると係数は大きく、「ミリメートル」で測ると係数は小さく出ます。同じ変数でも単位が変わるだけで罰金の重さが変わってしまい、罰則がスケールに振り回されます。これを避けるため、各説明変数を平均 0・分散 1 に標準化してから当てはめ、全変数が罰則の前で対等になるようにします(正規分布(標準正規・標準化) の標準化と同じ発想で、ここでは罰則の公平化が目的)。なお切片はデータの位置合わせの役割なので、通常は罰則に含めません。
Q5. リッジに閉形式解があるのに、Lasso にはないのはなぜ? A. 目的関数の滑らかさの違いです。リッジの罰則 は について滑らかな二次関数なので、微分して 0 と置けば線形方程式になり、 という閉じた式が出ます。一方 Lasso の罰則 は で尖っていて微分不能です。だから素直に微分して解く方法が使えず、劣微分・座標降下法・最小角回帰(LARS)などで数値的に解きます。皮肉なことに、この「尖り(微分不能点)」こそが係数を 0 にできる源でもあります。
Q6. リッジで を足すと、なぜ必ず逆行列が存在するの? A. は半正定値なので固有値が (最小は 0 もあり得る、これが特異の原因)。 を足すと固有値が一斉に にシフトします。 なら全固有値が で正定値となり、固有値に 0 が無いので逆行列が必ず存在します。だから最小二乗が解けない状況(多重共線性、説明変数の数 > データ数)でもリッジは解けます。これが「 が正則化(regularize)する」という言葉どおりの効果です。
まとめ
- 正則化は損失に罰則を足して係数を 0 方向へ縮める手法で、多重共線性・過学習による最小二乗の分散暴走を抑えます。
- **リッジ(L2)**は係数の二乗和を罰し、閉形式解 を持ちます。 が の固有値を底上げして逆行列を可逆化し、係数を縮めますが 0 にはしません。
- Lasso(L1)は絶対値和を罰し、制約領域がひし形で角(軸上)で接触するため係数をちょうど 0 にし、変数選択になります。
- 正則化はバイアスを増やし分散を減らす取引で、MSE = バイアス² + 分散 の谷を狙います。強さ は交差検証で選び、L1+L2 の折衷が Elastic Net です。
- 実務・試験とも、罰則前の標準化を忘れないこと。
関連ノート
- 推定量の評価(MSE・フィッシャー情報量・クラメール・ラオの不等式) MSE=バイアス²+分散の分解。正則化のトレードオフの土台
- 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論) 推定の一般論(リッジ・Lasso はベイズ事前分布つき推定とも解釈できる)
- 正規分布(標準正規・標準化) 標準化の発想(罰則の公平化の前処理)
- 重回帰分析 正則化が前提とする多変量の線形モデル
- 一般化線形モデル(ロジスティック・ポアソン回帰) 正則化はロジスティック回帰など GLM にも適用できる