📊 対象級:準1級 | 重要度:A(頻出)
要点(BLUF)
ベイズ統計は、推定したいパラメータ を「固定の定数」ではなく 確率変数 とみなします。データを見る前の信念(事前分布 )を、観測データ が持つ情報(尤度 )で更新し、見た後の信念(事後分布 )を得ます。この一連の更新がすべて次の一行に集約されます。
要するに「事後分布 ∝ 尤度 × 事前分布」。分母の積分は に依存しないただの正規化定数なので、形を知りたいだけなら掛け算だけで済む、ということです。
1. ベイズの枠組み:パラメータを確率変数とみなす
ベイズ推測の出発点は、頻度論との世界観の違いです。
- 頻度論(最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論)):パラメータ は 固定された未知の定数。確率変数なのは観測データの方。「真の は1つの値で、ただ我々が知らないだけ」と考えます。
- ベイズ:パラメータ を 確率変数 とみなす。 に対する我々の知識・信念の度合いを確率分布で表現します。
要するに「 にも分布を考えてよい」と一歩踏み込むのがベイズです。これにより「パラメータがこの範囲にある確率」を直接語れるようになります(後述の信用区間)。
ベイズ推測で登場する4つの要素を整理します。
| 記号 | 名称 | 意味 | 何の関数か |
|---|---|---|---|
| 事前分布(prior) | データを見る 前 の への信念 | ||
| 尤度(likelihood) | を固定したときデータ の出やすさ | ( は観測されて固定) | |
| 事後分布(posterior) | データを見た 後 の への信念 | ||
| 周辺尤度/エビデンス(marginal likelihood) | データ が出る確率( を周辺化)=正規化定数 | 定数( を含まない) |
⚠️ 尤度 は の関数 として読みます。 はすでに観測された定数です。「 の確率分布」ではなく「 をいろいろ動かしたときデータがどれだけ尤もらしいか」を表す関数なので、 について積分しても1にはなりません(これは後述の頻出の引っかけです)。
2. 事後 ∝ 尤度 × 事前:連続版ベイズの定理の導出
この比例関係は、ベイズの定理 の連続版です。離散の和を積分に置き換えるだけで導けます。
2.1 離散版(出発点)
事象に対するベイズの定理は次の形でした。 を仮説(パラメータの候補)、 をデータとすると、
分母は 全確率の公式 で 、つまり「データ が出る確率」をすべての仮説について足し上げたものです。
要するに「分母はデータが出る確率(正規化のための合計)」です。
2.2 連続版(パラメータが連続値)
パラメータ が連続値をとるとき、離散の確率 は密度 に、合計 は積分 に置き換わります。
分母の積分変数を と書いたのは、左辺・分子の と区別するためです。分母は を含まない ただの数(正規化定数)になります。
2.3 なぜ「∝(比例)」でよいのか
事後分布は の確率密度なので、全区間で積分すると1になる必要があります。分母はその「1にするための割り算」をしているだけです。したがって の関数としての形 だけを見れば、分母を無視して
と書けます。後で「積分して1」になるよう定数を決め直せばよいからです。
要するに「事後分布の“形”は尤度×事前で決まり、定数は後で帳尻を合わせる」。実際のベイズ計算では、まず を について整理して「見覚えのある分布の形」を見つけ、正規化定数は分布の公式から復元する、という手順を踏みます。次のベータ‐二項がまさにその実例です。
⚠️ 比例「∝」は 正規化定数(分母の積分)を省略している ことを忘れないこと。 と等号で書くのは誤りです。
3. ベイズ更新:事後が次の事前になる
データを 一度に 使っても 順番に 使っても、最終的な事後分布は同じになります。これが 逐次更新(sequential updating) です。
データ を順に観測する場合を考えます。まず で更新すると、
次に、この事後分布 を 新しい事前分布 として で更新すると、
( が のもとで独立なら 。)
最右辺は「 を まとめて一度に 使った結果」と完全に一致します。掛け算の順序は結果を変えないので、 を先に使っても を先に使っても事後分布は同じです。
要するに「昨日の事後が今日の事前。データが届くたびに信念を上書きでき、その順番は結果に影響しない」ということです。
flowchart LR P0["事前分布 π(θ)"] -->|"× 尤度(x₁)"| Po1["事後分布 π(θ given x₁)"] Po1 -->|"次の事前として再利用"| Pr2["事前分布 π(θ given x₁)"] Pr2 -->|"× 尤度(x₂)"| Po2["事後分布 π(θ given x₁,x₂)"] Po2 -.->|"データが増えるたび繰り返す"| Next["…"]
4. 具体例:ベータ‐二項モデル(コイン投げの 推定)
ベイズ更新が「パラメータの足し算」になる最重要例です。準1級で計算問題として頻出します。
4.1 設定
コインの表が出る確率 ()を推定します。 は確率の値なので、 上の分布で表すのが自然です。そこで事前分布に ベータ分布 を選びます(ベータ分布の性質は 指数分布・ガンマ分布・ベータ分布 を参照)。
回投げて 回表が出たとします。表の回数は二項分布に従うので、尤度は
( は を含まない定数なので、 の関数としては比例で落とせます。)
4.2 事後分布の導出(掛けるだけ)
「事後 ∝ 尤度 × 事前」に代入します。
最後の式は、パラメータが と の ベータ分布の形そのもの です。よって正規化定数を復元すれば、
要するに「ベータ事前にデータを入れると、また同じベータ分布が出てくる」。これが 共役事前分布 でいう「共役」の意味で、事後分布が事前分布と同じ分布族にとどまるおかげで計算が足し算だけで済みます。
4.3 更新の中身を読む
更新規則は驚くほど単純です。
事前パラメータ は「仮想的に観測済みの表 回・裏 回」と解釈できます(疑似カウント, pseudo-count)。これに実データの表 回・裏 回を足し込む、というのがベイズ更新の正体です。
事後分布の平均(点推定の一例。詳しくは ベイズ推定・MAP推定)は、ベータ分布の期待値公式から
4.4 事前の効きとデータ量の関係
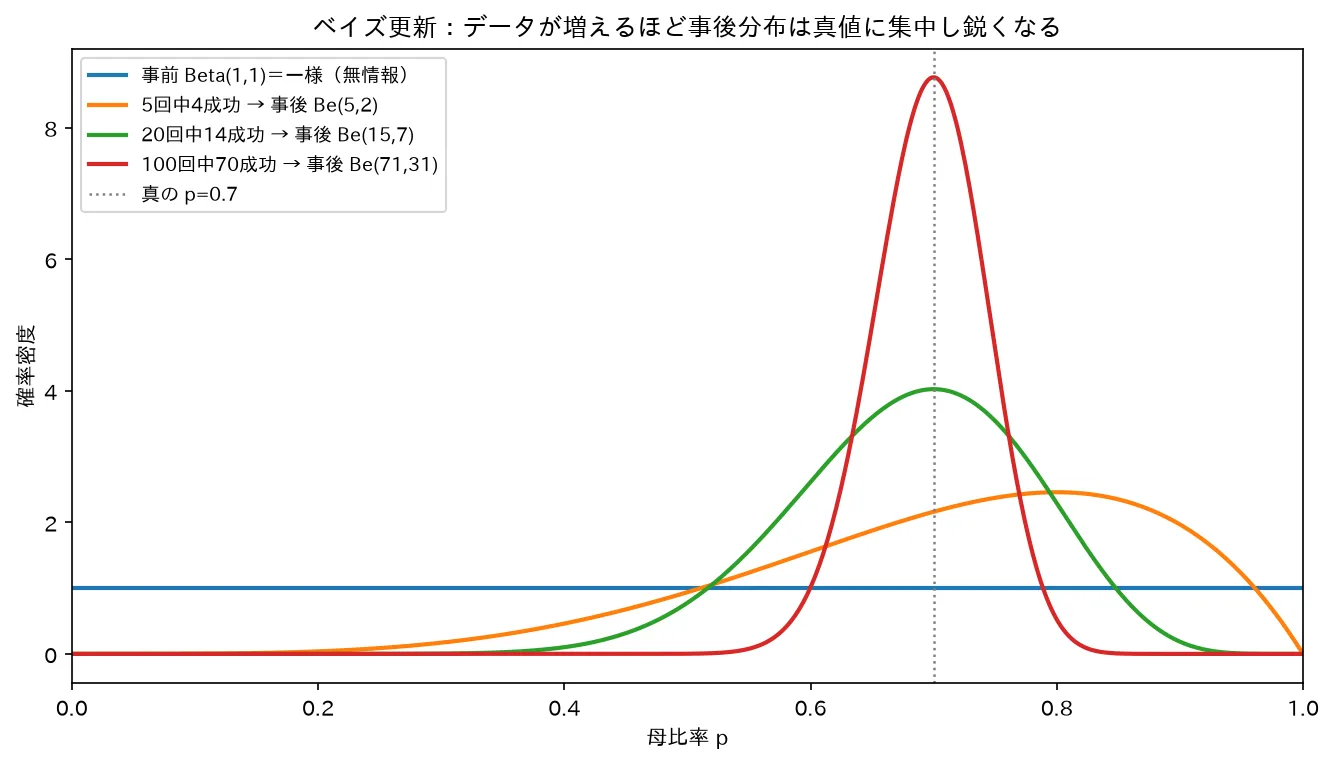
事前 Beta(1,1)=一様から、5回・20回・100回とデータが増えるほど事後分布は真値 0.7 に鋭く集中。データが多いと事前の影響は薄れる。図は simulations/bayes_kosin_beta_keijou.py で生成。
上の事後平均を、データだけの推定値 と事前平均 の 加重平均 に書き換えると、両者の綱引きが見えます。
- が 小さい(データが少ない):重み が小さく、事前平均 が強く効く。
- が 大きい(データが多い): となり、データの推定値 がほぼ支配する。事前の影響は薄れる。
要するに「データが少ないうちは事前分布の見立てが効くが、データが増えるほど事前は薄まり、尤度(データ)が事後を決める」。これがベイズ更新の本質的な振る舞いで、 では頻度論の最尤推定と一致していきます。
| 観測データ量 | 事後平均の支配項 | 事前の影響 |
|---|---|---|
| 小(データわずか) | 事前平均 | 大きい |
| 中 | 事前とデータの加重平均 | 中程度 |
| 大() | データ (=最尤推定) | ほぼ消える |
5. 頻度論との対比(世界観の違い)
同じ「未知パラメータの推定」でも、頻度論とベイズでは語り方が根本から異なります。
graph TB
subgraph 頻度論
F1["θ は固定の定数"] --> F2["データが確率変数"]
F2 --> F3["p値・信頼区間で語る"]
F3 --> F4["『この手続きを繰り返すと<br/>95%が真値を含む』"]
end
subgraph ベイズ
B1["θ は確率変数"] --> B2["データは観測されて固定"]
B2 --> B3["事後分布で語る"]
B3 --> B4["『θ がこの区間にある確率が95%』<br/>(信用区間)"]
end
| 観点 | 頻度論 | ベイズ |
|---|---|---|
| パラメータ | 固定の未知定数 | 確率変数 |
| データ | 確率変数(繰り返し可能な試行の結果) | 観測されて固定 |
| 推定の道具 | 点推定・値・信頼区間 | 事後分布(点推定はその要約) |
| 区間の意味 | 信頼区間:手続きの被覆確率(推定量の評価(MSE・フィッシャー情報量・クラメール・ラオの不等式) 系の発想) | 信用区間:パラメータがその区間にある確率そのもの |
| 事前知識 | 原則使わない | 事前分布として明示的に組み込む |
⚠️ 信頼区間と信用区間は別物。頻度論の95%信頼区間は「真値がこの区間にある確率が95%」とは 言えない(真値は定数なので、ある特定の区間に入るか入らないかは0か1)。「同じ手続きを繰り返すと95%の区間が真値を含む」が正しい解釈です。一方ベイズの信用区間は「 がこの区間にある確率が95%」と直接言えます。この違いは準1級で論述・選択どちらでも問われます。
数値計算では、事後分布が解析的に求まらないことが多く、その場合はマルコフ連鎖モンテカルロ法(MCMC、ギブスサンプリングやメトロポリス・ヘイスティングス法など)で事後分布からサンプリングして近似します。MCMCは本ノートの範囲を超えるため別途扱いますが、「共役でないときの事後計算の主力手段」とだけ押さえておいてください。
6. ⚠️ 引っかけポイント・頻出論点
- 尤度は の関数。 を「 の確率分布」と読むのは誤り。 は観測済みの定数で、 を動かす関数として見る。だから について積分しても1にならない。
- 事後 ∝ 尤度 × 事前 の「∝」は正規化定数を省略。等号で と書くのは間違い。分母の周辺尤度 で割って初めて等号になる。
- 事前分布の選び方には主観が入る。「同じデータでも事前が違えば事後が違う」のは事実で、ベイズの弱点として批判されることもある。一方、データが増えれば事前の影響は薄れる(§4.4)。
- 無情報事前 vs 主観事前。事前知識がないときは 無情報事前分布(一様分布、ジェフリーズ事前分布など。ベータでいえば =一様)を使う。過去データや専門知識があるときは 主観事前(情報事前) を使う。どちらが正しいという話ではなく、目的と前提知識による使い分け。
- 周辺尤度(エビデンス)は を含まない定数。これはパラメータ推定では正規化定数にすぎないが、モデル比較(ベイズファクター)では主役になる、という二面性に注意。
- 共役は計算上の便宜。共役事前分布だと事後が同じ分布族になり計算が楽(共役事前分布)。ただし「共役でなければベイズができない」わけではなく、その場合はMCMC等で数値的に解く。
7. 試験での問われ方(準1級)
ベイズは準1級で 頻出(重要度A) の分野です。次の角度で問われます。
- 事後 ∝ 尤度 × 事前 の適用:与えられた事前分布と尤度(データ)から事後分布を求める。ベータ‐二項、ガンマ‐ポアソン、正規‐正規が典型(共役の組は 共役事前分布)。
- ベータ‐二項の更新計算: + 成功 / → を計算し、事後平均 などを求める。実際に2021年6月の準1級論述問題でベイズ法と事後分布が出題されている(年度・出題形式は要最新確認)。
- 頻度論との違い:信頼区間と信用区間の解釈の違い、 を定数とみるか確率変数とみるか。
- 点推定への要約:事後分布から事後平均・事後中央値・MAP推定(事後確率最大)を求める(ベイズ推定・MAP推定)。
頻度論側の推定(最尤法)との対比が論点になるので、最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論) とセットで理解しておくこと。
よくある疑問(Q&A)
Q1. 頻度論とベイズ、結局どこが違うのですか?
一番の違いは パラメータ を確率変数とみなすかどうか です。頻度論は を「真の値は1つだが未知の定数」とみなし、確率変数なのはデータの方だと考えます。だから「この手続きを無限に繰り返したら95%が真値を含む」という信頼区間の言い方になります。ベイズは 自体に分布(信念)を考えるので、「 がこの区間にある確率は95%」と直接言えます。要するに「確率を“長期頻度”とみるか“信念の度合い”とみるか」の世界観の違いです。
Q2. 事前分布を勝手に決めてよいのですか?恣意的では?
主観が入るのは事実で、これはベイズへの典型的な批判です。ただし2つの逃げ道があります。(1) 事前知識がないなら 無情報事前分布(一様分布やジェフリーズ事前分布)を使い、できるだけ事前の影響を小さくする。(2) §4.4で見たように、データが増えれば事前の影響は自然に薄まり、事後分布はデータ(尤度)に支配されていく。さらに実務では複数の事前分布で結果がどれだけ変わるかを調べる 感度分析 を行います。「主観が入る=デタラメ」ではなく、前提を明示して検証する枠組みだと理解してください。
Q3. 「事後 ∝ 尤度 × 事前」の比例記号は、なぜ等号ではないのですか?
右辺 は、 について積分しても1になりません。確率密度になるには「全体で積分して1」が必要なので、分母の正規化定数 で割らねばなりません。比例「∝」はこの割り算を 省略している 印です。実用上は、右辺を整理して見覚えのある分布の形(例:ベータ分布)を見つければ、正規化定数はその分布の公式から自動的に決まるので、わざわざ積分を計算しなくて済みます。だから「形だけなら ∝ で十分」なのです。
Q4. 尤度 は確率分布ではないのですか?
を変数とみれば確率分布ですが、ベイズで使うときは の関数 として読みます。データ はすでに観測されて固定されているので、「 をいろいろ動かしたとき、そのデータがどれだけ尤もらしいか」を表す関数です。 について足し上げても(積分しても)1にはなりません。「尤度=データの確率」と混同するのが頻出の誤りです。最尤法(最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論))でも尤度を の関数として最大化したのと同じ見方です。
Q5. データを1個ずつ入れるのと、全部まとめて入れるので、答えは変わりますか?
変わりません。これが逐次更新(§3)のポイントです。前のデータで得た事後分布を次の事前分布として使えば、データを1個ずつ順に入れても、全部まとめて一度に入れても、最終的な事後分布は完全に一致します。掛け算 の順序は結果を変えないからです。要するに「昨日の事後が今日の事前」で、データの到着順序に依存しない、ということです。
Q6. 共役でない事前分布を使うとどうなりますか?
事後分布が「見覚えのある分布の形」にならず、解析的に書けないことが多くなります。その場合は MCMC(マルコフ連鎖モンテカルロ法)などで事後分布から大量にサンプリングし、ヒストグラムや平均で事後分布を近似します。つまり共役(共役事前分布)は「計算が楽になる便宜」であって必須条件ではありません。準1級の手計算問題では共役の組が出されますが、実務では非共役+数値計算が普通だと押さえておけば十分です。
まとめ
- ベイズは を 確率変数 とみなし、事前分布 をデータの尤度 で更新して事後分布 を得る枠組み。
- 中核の式は 。分母は を含まない正規化定数(周辺尤度)。「∝」は正規化定数の省略。
- 離散版ベイズの定理の和を積分に置き換えれば連続版が導ける。
- 逐次更新:昨日の事後が今日の事前。データの順序に依存せず、まとめても1個ずつでも同じ事後になる。
- ベータ‐二項: + 成功 / → 。更新は表・裏の回数の足し算。事後平均 。
- データが増えるほど事前の影響は薄れ、尤度(データ)が事後を支配する。 で最尤推定に近づく。
- 頻度論( は定数・信頼区間)とベイズ( は確率変数・信用区間)は世界観が異なる。信頼区間と信用区間の解釈の違いは頻出。
関連ノート
- ベイズの定理 本ノートの式の離散版。連続版はここの和を積分にしたもの
- 指数分布・ガンマ分布・ベータ分布 ベータ分布の性質。ベータ‐二項の事前分布
- 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論) 頻度論側の推定。尤度を の関数とみる点は共通
- 共役事前分布 事後が事前と同じ分布族になる組み合わせ(ベータ‐二項など)
- ベイズ推定・MAP推定 事後分布を点推定に要約する(事後平均・MAP)
- ベイズ統計・実験計画(Phase 7 目次) ベイズ統計・実験計画ドメインの全体像