🎓 レベル:発展 | 重要度:B(標準)
📎 前提:汎化と過学習・バイアスバリアンス分解・学習問題の定式化(仮説・損失・経験リスク)(経験リスク最小化) | 数理:大数の法則(弱法則・強法則)(統計)
要点(BLUF)
- 訓練誤差(経験リスク)を最小にしただけで未知データに当たる保証は、本来どこにもありません。それでも当たるのは「仮説集合がそこまで複雑でない」からです。
- 汎化誤差は 「経験誤差 + 複雑さ/データ数の項」 で上から押さえられます。複雑さは有限なら 、無限なら VC次元 で測ります。
- この「高い確率で・近似的に正しい」を枠組みにしたのが PAC学習。ただし深層学習はこの古典理論では説明しきれず、未解決です。
1. 問い:経験リスク最小化はなぜ汎化するのか
学習器が本当に下げたいのは未知データでの平均誤差、すなわち期待リスク です(学習問題の定式化(仮説・損失・経験リスク))。しかし分布 は不明なので、手元のデータで測った経験リスク を代わりに最小化します。これが**経験リスク最小化(ERM)**です。
問題は、 を最小にした が も小さいとは限らないこと。両者の差
が大きければ、訓練でいくら当たっても未知データでは外します。これが過学習の正体です(汎化と過学習・バイアスバリアンス分解では同じことを「バリアンスが大きい状態」として見ました)。汎化理論の目的は、この差を仮説集合の複雑さとデータ数で上から押さえることです。
要するに:訓練誤差と未知誤差の「ズレ」を、理論的に保証つきで小さくしたい。
2. 一歩目:1つの仮説なら Hoeffding 不等式
まず仮説 を1つに固定します。損失を とすると、 は独立な確率変数 の平均で、その期待値が です。すると Hoeffding 不等式がそのまま使えます:
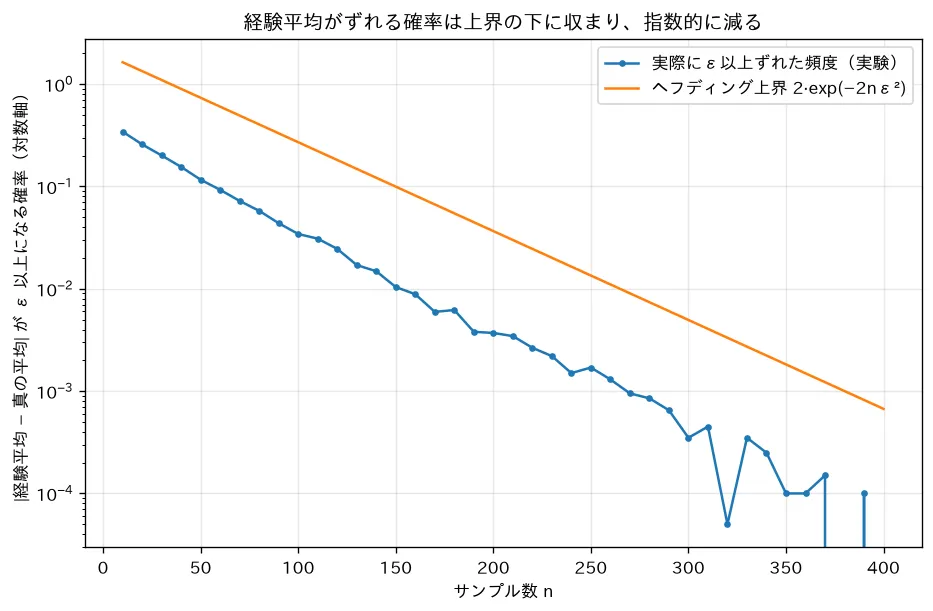
要するに:サンプル平均(経験リスク)は、真の平均(期待リスク)から指数関数的にしか外れない。データ を増やせば、ズレが を超える確率はあっという間に 0 に近づきます。これは統計の 大数の法則(経験平均が真の平均に収束)を、有限の で定量化した集中不等式にあたります。
ただしこれは「先に を決めてからデータを見た」場合の話です。ERM は逆で、データを見てから一番当たる を選びます。選んだ後の には Hoeffding をそのまま当てられません(選択そのものがデータに依存して都合よく偏るため)。ここが核心の落とし穴です。
3. 二歩目:有限仮説集合は union bound で
仮説集合 が有限( 個)だとします。ERM が選ぶ がどれになるか事前にはわからないので、「どれか1つでも大きく外れる」確率を押さえます。各仮説が外れる事象の和集合を取り、union bound(和集合上界) を使うと:
右辺を と置いて について解くと、確率 以上ですべての について同時に成り立つ評価が得られます:
要するに:未知誤差 ≤ 訓練誤差 + 複雑さの罰。罰の項を読むと、
- (仮説集合の複雑さ)が小さいほど小さい
- データ数 が多いほど小さい( で減る)
- 確信度を上げる( を小さくする)と少しだけ増える
これが汎化理論の雛形です。ERM が「全部の仮説について同時に訓練誤差≒未知誤差」を保証できれば、訓練で一番良かった も未知データで悪くない、と言えます(一様収束の考え方)。
4. 三歩目:無限の仮説集合をどう数えるか — VC次元
困るのは のとき。線形分類器は係数が連続なので仮説は無限個あり、 が発散して上の式が無意味になります。
突破口は「 個の点の上では、無限個の仮説も結局は有限通りのラベル付けしか作れない」という観察です。 点に対して が実現できる二値ラベル付けのパターン数を成長関数 と呼びます(上限は )。これが実質的な「有効な仮説数」で、union bound の をこれで置き換えます。
成長関数を1つの整数で要約するのが VC次元(Vapnik–Chervonenkis dimension) です:
VC次元 = が shatter(粉砕) できる点の最大数。 shatter とは、その 点の すべての ラベル付け( 通り)を の中の仮説で実現できること。
代表例:2次元平面の線形分類器の VC次元は 3。一般に 次元の線形分類器(バイアス込み)は 。
- 一般の位置にある 3点は、 通りの ラベルすべてを直線で分離できます → shatter 可能。
- 4点は、対角どうしを同じクラスにする XOR 的なラベル付けを直線で分けられない → shatter 不可能。だから 。
要するに:VC次元は「この仮説集合がどれだけ自由にラベルを付け替えられるか」という表現力の上限。大きいほど複雑(=過学習しやすい)。
Sauer の補題:表現力は有限なら多項式で頭打ち
VC次元が有限なら、成長関数は爆発しません。Sauer の補題:
要するに: では (指数)で何でも表現できるが、 を超えると一転して の多項式( オーダー)でしか増えない。指数 が多項式 に化けるこの「相転移」こそが、無限仮説でも一様収束が効く理由です。
5. VC汎化バウンド:複雑さ/データ数のトレードオフ
union bound の を に置き換え、Sauer の補題で多項式評価すると、無限仮説集合でも確率 以上で次が成り立ちます(係数は文献で差がありますが形が本質):
ざっくり覚えるなら
要するに:未知誤差 ≤ 訓練誤差 +(複雑さ ÷ データ数)の平方根。読み方は1つ — 複雑さ とデータ数 の綱引きです。
- が大きい(柔らかいモデル)→ 訓練誤差は下げやすいが罰の項が膨らむ
- が大きい → 罰の項が縮み、複雑なモデルでも安全に使える
- 良い汎化は 、すなわち「データ数に対してモデルが複雑すぎない」とき
これは 汎化と過学習・バイアスバリアンス分解 のバイアスバリアンスを確率保証つきで定式化したものです。 を上げると訓練誤差(≒バイアス起因のズレ)は減り、罰の項(≒バリアンス起因のズレ)は増える。両者の和を最小化する「ちょうどよい複雑さ」を選ぶ、という同じ綱引きが見えます。正則化はこの (実効的な複雑さ)を陰に小さくする操作と読めます(正則化の理論)。
graph TD
A["1つの仮説:Hoeffding不等式"] --> B["有限の仮説集合 H<br/>union bound で |H| 個へ拡張"]
B --> C["バウンド:経験誤差 + √( ln|H| ÷ n )"]
C --> D["無限の仮説集合<br/>|H| = ∞ で破綻"]
D --> E["成長関数 → VC次元<br/>Sauer の補題で多項式に"]
E --> F["VC汎化バウンド<br/>R ≤ R̂ + O( √( d_VC ÷ n ) )"]
F --> G["読み方:複雑さ d_VC と データ数 n の綱引き"]
graph LR
subgraph トレードオフ["複雑さ と データ数 のトレードオフ"]
P["複雑さ d_VC が大きい<br/>= 柔らかいモデル<br/>→ 訓練誤差↓ だが 罰の項↑"]
Q["データ数 n が大きい<br/>→ 罰の項 √( d_VC ÷ n )↓"]
R["良い汎化の条件<br/>d_VC ≪ n<br/>= データに対しモデルが複雑すぎない"]
P --> R
Q --> R
end
6. PAC学習:高い確率で・近似的に正しい
ここまでの「確率 以上で、誤差が 以下」という言い回しを枠組みにしたのが PAC学習(Probably Approximately Correct、Valiant 1984) です。
仮説集合 が PAC学習可能 とは、任意の精度 ・確信度 に対し、ある十分なサンプル数 を集めれば、**確率 以上(=Probably)で誤差 以下(=Approximately Correct)**の仮説を、どんな分布 でも返せること。
ここで必要な を**標本複雑度(sample complexity)**と呼びます。VCバウンドを逆に解くと、おおよそ
要するに:欲しい精度・確信度を達成するのに必要なデータ数は、VC次元に比例する。複雑なモデルほど多くのデータを要求します。
設定は2種類あります。
- 実現可能(realizable):真の概念が の中にある(訓練誤差 0 を達成できる)。このとき必要データは とさらに少なくて済む。
- アグノスティック(agnostic):真の概念が にある保証はなく、ノイズもある。最良の仮説 に対し を目指す現実的な設定。必要データは 。
そして統計的学習理論の基本定理:
が(アグノスティックに)PAC学習可能 ⇔ VC次元が有限。
要するに:「学習できるか」は VC次元が有限かどうかで決まる。VC次元こそが学習可能性の本質的な尺度です。
7. データ依存の複雑さ:Rademacher 複雑度
VC次元は「最悪の分布」を想定した分布によらない指標で、しばしば過大評価になります。これをデータに合わせて精緻化したのが Rademacher 複雑度 です。
を等確率のランダム符号(Rademacher変数=でたらめなラベル)として、
要するに:この仮説集合は、でたらめなラベル(ノイズ)にどれだけ当てはめられるか。表現力が高いほどノイズにもフィットでき、値が大きくなります。これを使った汎化バウンドは
VC次元との違いは、Rademacher 複雑度が実データから測れて(data-dependent)、しばしばVCバウンドより緊密なこと。「ノイズへの当てはまり度が、汎化ギャップの上界そのもの」という直観が美しく、深層学習の解析でも主役の1つです。
8. ⚠️ 深層学習はこの古典理論で説明しきれない(要最新確認・未解決)
ここまでの結論は「複雑すぎる( の)モデルは汎化しない」でした。ところが深層ニューラルネットはこれを真っ向から破ります。
- 現代の巨大ネットワークはパラメータ数が訓練データ数をはるかに超える(過剰パラメータ)。VC次元はパラメータ数とともに巨大化するので、古典バウンドは「汎化しない」と予言します。
- 実際にはそうした網がランダムラベルすら完全に暗記できる(=Rademacher複雑度も実質最大)にもかかわらず、本物のラベルではよく汎化します(Zhang et al. 2017 の有名な実験)。worst-case の VC/Rademacher バウンドは**空虚(vacuous)**になり、説明力を失います。
- さらに 二重降下(double descent):モデルを複雑にすると、古典的には U字(過学習で悪化)のはずが、訓練データを完全に当てはめる点(補間閾値)を超えてさらに複雑にすると、テスト誤差が再び下がるという非単調な振る舞いが観測されます。古典理論には無い現象です。
なぜ過剰パラメータでも汎化するのか。有力な仮説は 暗黙のバイアス(implicit bias) — SGD が無数にある「訓練誤差 0 の解」の中から、たまたま単純で滑らかな(ノルムの小さい)解を選ぶ傾向がある、という見方です。つまり実効的な複雑さは見かけのパラメータ数よりずっと小さい、と。
ただしこれは決着していません。「古典VC理論でも正しく VC次元を見積もれば二重降下まで説明できる」とする反論(2022〜2023)もあり、PAC-Bayes など別枠組みで空虚でないバウンドを作る試みも進行中です。
⚠️ 要最新確認・未解決:深層学習の汎化は2026年現在も活発な研究領域で、定説は固まっていません。本ノートの古典理論(VC・Rademacher・PAC)は枠組みと直観としては正しく重要ですが、過剰パラメータの深層モデルにそのまま適用して「汎化する/しない」を断定してはいけません。
要するに:古典理論は「複雑さ vs データ数」という見方の土台として必須。ただし深層の謎には、暗黙のバイアスなど追加の説明が要る。
9. まとめ
- ERM が汎化する理由は「仮説集合がそこまで複雑でないから」。これを保証つきで述べるのが汎化理論です。
- 道筋:Hoeffding(1仮説)→ union bound(有限 )→ VC次元・Sauer(無限 )→ VCバウンド。結論は 、すなわち複雑さとデータ数の綱引き。
- PAC学習がこの「高確率・近似正しさ」を枠組み化し、学習可能性 ⇔ VC次元有限という基本定理に至ります。Rademacher 複雑度はそのデータ依存版。
- 深層学習はこの古典理論の射程外。過剰パラメータでの汎化と二重降下は未解決で、暗黙のバイアスなどが鍵と見られています(要最新確認)。
対応するシミュレーション
simulations/hoeffding_bound.py:コイン投げの経験平均が真の平均から 以上ずれる頻度を、サンプル数 を変えて実測し、ヘフディング上界 と比べます。実測値がつねに上界の下に収まり指数的に減ること(分布の中身を知らずに精度を保証できる)を可視化します。これが「訓練誤差から真の誤差を確率的に保証する」汎化バウンドの土台で、仮説が多いほど union bound や VC 次元で補正が要ります。
関連ノート
- 最適化と学習理論 目次
- 汎化と過学習・バイアスバリアンス分解 — 同じ綱引きを期待値分解で見たノート
- 学習問題の定式化(仮説・損失・経験リスク) — 期待リスク・経験リスク・ERMの定義
- 正則化の理論 — 実効的な複雑さを下げる操作としての正則化
- 大数の法則(弱法則・強法則)(統計)— Hoeffding 不等式の定性版にあたる大数の法則
- 標準化(z得点)・偏差値・チェビシェフの不等式 ── 標準化≠正規化/偏差値に上限なし/どんな分布でも成り立つ歯止め(統計)— 最も基本的な集中不等式
- 機械学習テキスト 全体目次