🎓 レベル:基礎 | 重要度:A(必須)
📎 前提:学習問題の定式化(仮説・損失・経験リスク) | 数理:単回帰分析(統計)・最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論)(統計)
要点(BLUF)
- 線形回帰は「入力の線形結合で出力を予測するモデル を、二乗誤差が最小になるように当てはめる」教師あり回帰の最も基本的な手法です。
- 二乗損失を最小化すると 正規方程式 が出て、解は 。これは幾何的には「 を列空間 へ直交射影する」操作です。
- 誤差を と仮定すると、最小二乗解=最尤推定(MLE) になります。二乗損失は「ガウス誤差を仮定したときの負の対数尤度」だったわけです。
1. モデルの定式化
個のデータ を考えます。各 は 次元の特徴ベクトルです。線形回帰は、出力を特徴の線形結合で予測します:
これを行列でまとめます。切片 を吸収するため各行の先頭に 1 を足した 設計行列(design matrix) を使うと、
要するに:予測値 は「 の各列を で重み付けして足したもの」。 はモデルで説明しきれないズレ(誤差項)です。
⚠️ 「線形」とはパラメータ について線形という意味です。 や を特徴に入れても、 について線形なら線形回帰のままです(曲線も当てはめられる)。
2. 最小二乗法と正規方程式
良い とは、予測の二乗誤差の合計(残差平方和, RSS)を最小にするものとします:
これを で微分して 0 と置きます。 を展開すると
勾配を取ると(ベクトル微分の公式 、 は対称):
これを整理すると 正規方程式(normal equation) が得られます:
要するに:損失は の凸な二次関数なので、勾配が 0 になる一点が唯一の最小値。 が正則(=列が一次独立)なら逆行列で一発で解けます。反復計算は不要で、これが線形回帰の大きな利点です。
が正則であるためには の列がフルランク(一次独立)である必要があります。列同士が強く相関すると逆行列が不安定になる——これが多重共線性の問題で、次のノート 重回帰と多重共線性 で扱います。
3. 幾何的意味:列空間への直交射影
正規方程式を と書き直すと、図形的な意味がはっきりします。
- 予測ベクトル は、 の列ベクトルの線形結合なので、必ず列空間 ( の列が張る部分空間)の中にあります。
- 残差ベクトル は、 より のすべての列と直交します。つまり 。
graph TB
Y["観測ベクトル y"] -->|"直交射影"| YH["予測 ŷ = Xβ̂(列空間内)"]
Y -->|"残差 e = y − ŷ"| E["e は列空間と直交"]
YH -->|"残差はここに直交"| E
SUB["列空間 col(X)(X の列が張る平面)"] --- YH
これは「 を列空間に下ろした足(最短距離の点)が である」という、最短距離=垂線の足の話そのものです。残差 が列空間と直交していなければ、まだ列空間の方向に動かして誤差を減らせる余地があるので、最小ではありません。直交していること自体が最小性の条件になっています。
予測を作る写像 の行列
は ハット行列(射影行列) と呼ばれ、(射影なので二度かけても同じ)、(対称)という直交射影の性質を満たします。
要するに:最小二乗法は「観測 から、モデルで表現できる空間 に向かって垂線を下ろす」操作です。代数(正規方程式)と幾何(直交射影)は同じ事実の two views です。
4. 確率的解釈:最小二乗=ガウス誤差の最尤推定
ここまでは「二乗誤差を最小にする」という最適化の話でした。実はこの二乗損失には確率モデルの裏付けがあります。
誤差を独立同分布のガウスノイズと仮定します:
つまり「各 は、真の直線上の値 を中心とした、分散 の正規分布から出る」と考えます。1 点の尤度(確率密度)は
独立性より全データの尤度は積になり、対数を取ると(対数尤度):
に関係するのは最後の項だけです。 を について最大化することは、符号が逆なので
を最小化することと完全に一致します。これは §2 の最小二乗の損失そのものです。
flowchart LR
A["誤差を N(0, σ²) と仮定"] --> B["尤度 ∏ p(yi | xi)"]
B --> C["対数尤度 ℓ(β)"]
C -->|"β に依存する項だけ残す"| D["最大化 ⇔ Σ(yi − xiᵀβ)² の最小化"]
D --> E["最小二乗解 β̂ = (XᵀX)⁻¹Xᵀy"]
要するに:最小二乗法は天下りの「便利な損失」ではなく、「誤差が正規分布する」という確率モデルの最尤推定です(→ 統計の 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論))。だから二乗損失が外れ値に弱いのも、正規分布が裾の薄い分布だから、と理解できます(裾の厚いラプラス分布を仮定すると絶対値損失=中央値回帰になる)。
補足: を最尤推定すると (残差の平均二乗)。ただしこれは下方バイアスを持ち、不偏推定では で割ります(→ 統計 残差分析・回帰診断)。
5. 前提(古典的線形回帰モデルの仮定)
最小二乗推定量 が「良い推定量」であるための古典的仮定は次の通りです。
| 仮定 | 内容 | 破れると |
|---|---|---|
| 線形性 | (パラメータについて線形) | バイアス(系統的なズレ) |
| 独立性 | 各標本の誤差が独立(無相関) | 標準誤差が過小評価 |
| 等分散性 | で一定(homoscedasticity) | 推定の効率が落ちる |
| 正規性 | 小標本で検定・区間が不正確 |
ここで効いてくるのが ガウス・マルコフの定理 です:誤差が「平均0・等分散・無相関」(正規性は不要)であれば、最小二乗推定量は 線形不偏推定量の中で最小分散 = BLUE(Best Linear Unbiased Estimator) になります。正規性まで仮定すると、線形に限らずすべての不偏推定量の中で最小分散となり、§4 の最尤推定の最適性とつながります。
要するに:正規性は「点推定 の最適性」には不要(等分散・無相関で十分にBLUE)。正規性が効くのは検定・信頼区間などの推測統計の場面です。
⚠️ よくある誤解
- 「線形回帰は直線しか引けない」は誤り。線形なのはパラメータ についてであり、 などを特徴に入れれば曲線も当てられます(多項式回帰も線形回帰の一種)。
- 正規方程式の逆行列は実務では直接計算しない。 は数値的に不安定になりやすく、実装は QR 分解や SVD で解くのが標準です(解は同じ)。
- 正規性は推定そのものには必須でない。ガウス・マルコフより、等分散・無相関なら正規性なしで BLUE。正規性が要るのは 検定・信頼区間など。
- 最小二乗=最尤、は誤差がガウスのときだけ。誤差分布を変えれば損失も変わります(ラプラス→絶対値損失)。二乗損失が外れ値に弱いのはガウスの裾の薄さの裏返し。
- が特異だと解が一意に決まらない。列が一次従属(完全な多重共線性)だと逆行列が存在せず、解が無数に出ます(→ 正則化で対処、正則化(Ridge・Lasso・Elastic Net))。
対応するシミュレーション
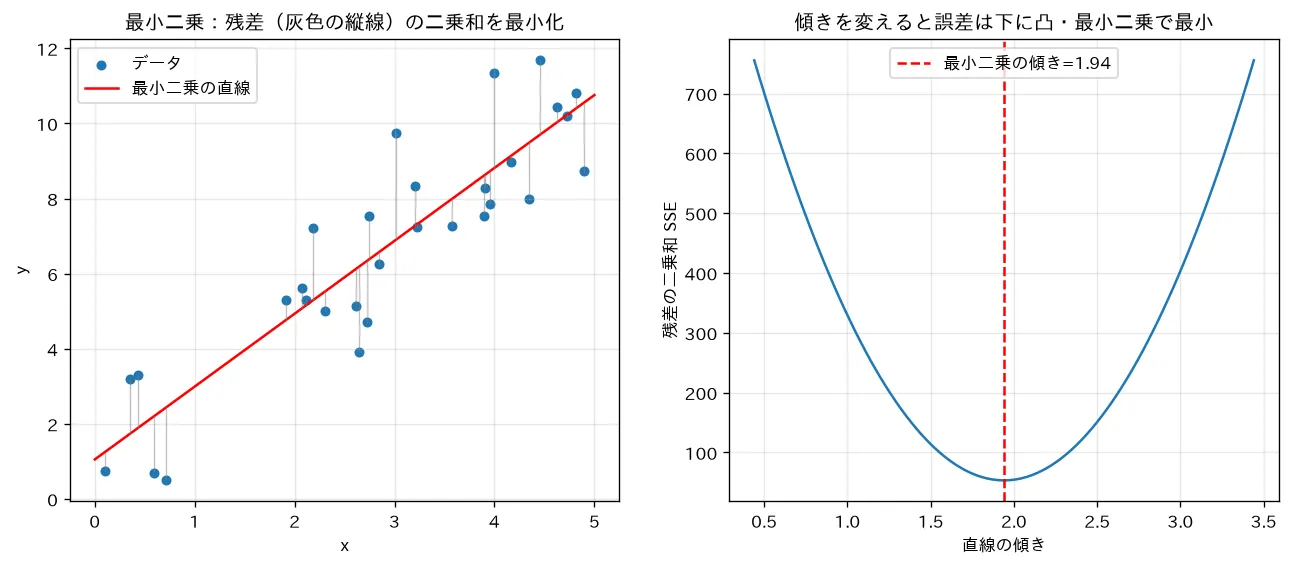
simulations/linear_regression_ols.py:直線っぽいデータに最小二乗法を正規方程式 で一発で当てはめ、各点の残差(予測と実測の縦のズレ)を可視化します。傾きを変えると残差の二乗和(SSE)が下に凸の放物線を描き、最小二乗の傾きでちょうど底になる=他のどの傾きより誤差が小さいことを示します。なぜ二乗かは誤差が正規分布のときの最尤推定に対応します(統計サイト参照)。
関連ノート
- 教師あり学習・回帰 目次
- 学習問題の定式化(仮説・損失・経験リスク)(二乗損失と経験リスク最小化の枠組み)
- 汎化と過学習・バイアスバリアンス分解(線形モデルは低バリアンス・高バイアス側)
- 評価指標(回帰)(RMSE・決定係数 R² など)
- 重回帰と多重共線性( の不安定性)
- 正則化(Ridge・Lasso・Elastic Net)(特異・過学習への対処)
- 単回帰分析(統計・1変数版の土台)
- 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論)(統計・最尤推定の一般論)
- 残差分析・回帰診断(統計・仮定のチェック)
- 機械学習テキスト 全体目次