🎓 レベル:標準 | 重要度:A(必須)
📎 前提:線形回帰(最小二乗法と確率的解釈) | 数理:重回帰分析(統計)・残差分析・回帰診断(統計)
要点(BLUF)
- 重回帰は説明変数を複数にした線形回帰で、各係数(偏回帰係数)は「他の変数を固定したまま、その変数を1だけ動かしたときの効果」を表します。
- 多重共線性は説明変数どうしが強く相関する状態で、 がほぼ特異になり逆行列が暴れるため、係数推定の分散が膨らみ、符号反転や不安定化を招きます。
- 診断は相関行列・VIF・条件数で行い、対処は変数を削る・主成分回帰・正則化。本ノートは 正則化(Ridge・Lasso・Elastic Net) への橋渡しです。
1. 重回帰モデルと偏回帰係数
説明変数が 個あるとき、線形回帰モデルは次のように書けます。
個のデータをまとめて、定数項の列(全部 1)を加えた計画行列 を使うと、最小二乗解は一行で表せます(導出は統計の 重回帰分析 にあります)。
要するに:単回帰の「傾き」を多次元に拡張しただけで、解の形は逆行列をひとつ挟むだけです。
偏回帰係数の意味
係数 は 偏回帰係数(partial regression coefficient) と呼ばれ、
他のすべての説明変数を固定したまま、 を1単位だけ増やしたときの の変化量
を意味します。「他を止めて1つだけ動かす」がポイントです。単回帰の傾きと値が違うのはこのためで、単回帰では「他の変数経由の間接効果」も混ざって現れるのに対し、重回帰の偏回帰係数は他変数の影響を取り除いた正味の効果を測ります。
flowchart LR X1["x1(広告費)"] --> Y["y(売上)"] X2["x2(店舗数)"] --> Y X3["x3(気温)"] --> Y Y -. "各矢印の強さが偏回帰係数 βj(他を固定した正味の効果)" .-> NOTE["係数の解釈"]
2. 多重共線性とは
多重共線性(multicollinearity) は、説明変数どうしが強く相関している状態を指します。極端な場合、ある変数が他の変数の線形結合でほぼ表せてしまう(例:「身長」と「座高」、「気温(℃)」と「気温(℉)」)。
なぜ係数が不安定になるのか
鍵は の逆行列です。説明変数が強く相関すると の列がほぼ平行になり、 はほぼ特異(行列式がほぼ 0) になります。すると逆行列 の成分が爆発的に大きくなります。
係数推定量の分散・共分散は次の形をしています。
要するに: が暴れる = 係数の分散が膨らむ。データを少し変えただけで係数が大きく揺れ、ときに符号が逆転します。「広告費を増やすほど売上が下がる」といった直観に反する係数が出たら、まず共線性を疑います。
重要なのは、予測そのものは必ずしも悪化しないことです。共線性が壊すのは「個々の係数の解釈」であって、 全体の当てはまりではありません。係数は依然として不偏ですが、分散が大きく信頼できなくなります。
graph TD A["説明変数どうしが強く相関"] --> B["X の列がほぼ平行"] B --> C["X^T X がほぼ特異(行列式 ≒ 0)"] C --> D["逆行列 (X^T X)^-1 の成分が爆発"] D --> E["係数の分散が増大"] E --> F["符号反転・不安定・解釈不能"] E --> G["予測自体は壊れにくい"]
3. 診断:相関行列・VIF・条件数
(1) 相関行列
最も手軽なのは説明変数の相関行列を見ること。 程度の強い相関ペアがあれば共線性の候補です。ただし2変数ずつしか見られないのが弱点で、「3変数の和でほぼ表せる」ような多変数間の共線性は見逃します。
(2) VIF(分散拡大係数)
その弱点を補うのが VIF(Variance Inflation Factor, 分散拡大係数) です。変数 を残りの全説明変数で回帰したときの決定係数を とすると、
要するに: が他の変数たちでどれだけ説明できてしまうか()が大きいほど VIF が跳ね上がる。「他で説明しきれる = 共線性が強い」という直観そのままの指標です。(無相関)なら VIF=1、 なら VIF。
名前のとおり、VIF は係数 の分散が、共線性のない理想状態の何倍に膨らんでいるかを表します。
目安(情報源で幅があります):
| VIF の値 | 解釈 |
|---|---|
| 1 | 共線性なし |
| 1〜5 | おおむね許容 |
| 5〜10 | 注意(5超で係数の推定が不安定との指摘) |
| 10 超 | 深刻な共線性。対処が必要 |
(3) 条件数
VIF は変数ごとの指標ですが、条件数(condition number) はモデル全体の共線性を1つの数で測ります。(または )の最大特異値と最小特異値の比で定義されます。
最小特異値が 0 に近い = ほぼ特異 = 比が巨大、という関係です。目安として条件数が 10〜30 を超えると共線性あり、100 を超えると深刻とされます(しきい値は要最新確認)。
要するに:相関行列で当たりをつけ、VIF で犯人の変数を特定し、条件数でモデル全体の重症度を測る、という三段構えです。
flowchart TD
S["重回帰を当てはめた"] --> C["相関行列<br/>強い相関ペアを探す"]
C --> V["VIF を計算<br/>VIFj = 1 / (1 - Rj^2)"]
V --> K["条件数を計算<br/>全体の重症度"]
K --> J{"共線性あり?"}
J -- "なし" --> OK["そのまま解釈してよい"]
J -- "あり" --> FIX["対処へ(第4節)"]
4. 対処:削る・まとめる・縮める
共線性が見つかったときの代表的な対処は次の通りです。
- 変数を削る/選択する:強く相関するペアの一方を落とす、あるいはステップワイズなどで変数選択する。最も素直ですが、落とした変数の情報は失われます。
- 変数をまとめる(主成分回帰):主成分分析(PCA)(統計)で説明変数を互いに直交する主成分に変換し、それを使って回帰します。直交化により定義上 が安定し、共線性が消えます。代償として軸の解釈性が落ちます。
- 中心化・標準化:交互作用項や多項式項( など)を入れると人工的な共線性が生じやすく、変数を平均0に中心化するだけで緩和できることがあります。
- 正則化で縮める: に小さな対角項を足して逆行列を安定させる Ridge 回帰、不要な係数を0にする Lasso が代表格です。共線性を「消す」のではなく、係数を縮めて分散を抑える発想です。
最後の正則化が、次のノート 正則化(Ridge・Lasso・Elastic Net) の主題です。Ridge は推定式が となり、対角に足した がほぼ特異な行列を確実に正則化する——共線性対策がそのまま正則化の動機になっている、という流れで読み進めてください。
graph TD P["多重共線性"] --> A["削る:変数選択"] P --> B["まとめる:主成分回帰(直交化)"] P --> C["中心化・標準化"] P --> D["縮める:Ridge / Lasso(正則化)"] D --> N["次ノート:正則化へ"]
⚠️ よくある誤解
- 「共線性があると予測がダメになる」は誤り。壊れるのは個々の係数の解釈・安定性で、予測精度( の当てはまり)はしばしば保たれます。目的が「予測」なら共線性を放置してもよい場面があります。
- VIF が高い = その変数が重要、ではない。VIF は他変数との重複度を測るだけで、 との関係の強さとは無関係です。
- 相関行列だけでは不十分。2変数ペアの相関が全部小さくても、多変数の組み合わせで共線性が生じることがあります(VIF・条件数で補う)。
- 係数の符号が直観と逆 = 必ず共線性、とも限らない。交絡や真に負の効果のこともあります。VIF で切り分けてから判断します。
- 完全な共線性(ある変数が他の完全な線形結合)では が真に特異になり、逆行列が存在せず最小二乗解が一意に定まりません(ダミー変数の入れすぎ=ダミー変数トラップが典型)。
対応するシミュレーション
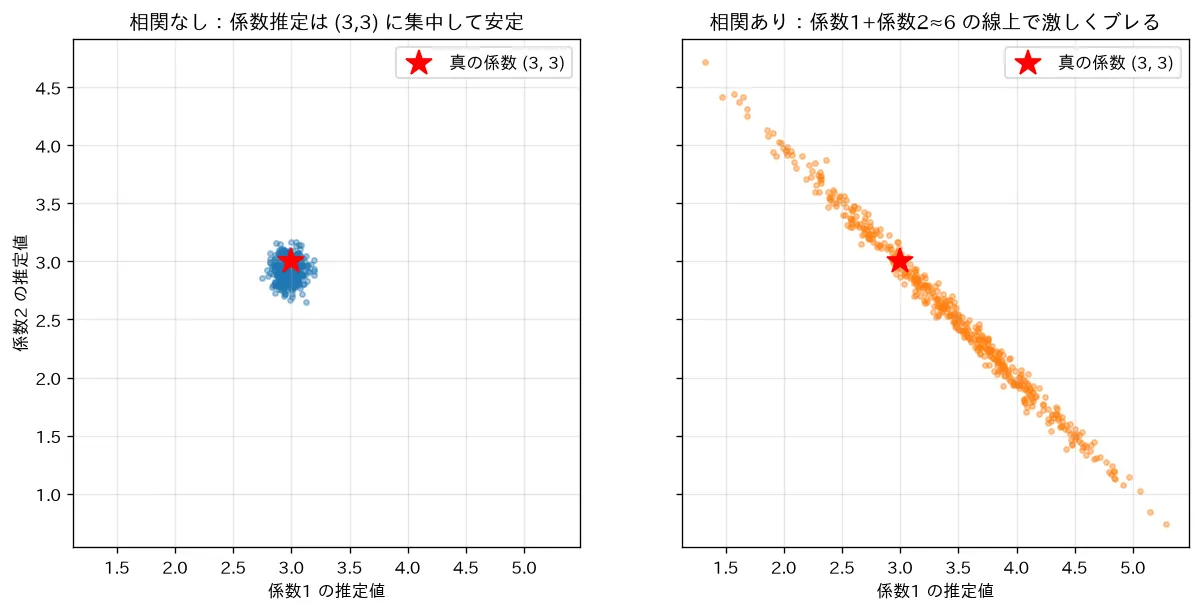
simulations/multicollinearity.py:2つの特徴がほぼ同じ(相関 、VIF98)データと、無相関なデータで、ブートストラップで何度も線形回帰を当てはめ、係数の推定がどれだけブレるかを比べます。相関が強いと係数が「係数1+係数2≈一定」の直線上で激しく振れ、予測は安定なのに個々の係数の解釈ができなくなる多重共線性を可視化します。対策は正則化(正則化(Ridge・Lasso・Elastic Net))。
関連ノート
- 線形回帰(最小二乗法と確率的解釈)(最小二乗・確率的解釈)
- 正則化(Ridge・Lasso・Elastic Net)(共線性対策としての正則化)
- 汎化と過学習・バイアスバリアンス分解(係数の分散=バリアンス増大)
- 重回帰分析(統計・最小二乗の行列導出と変数選択)
- 残差分析・回帰診断(統計・回帰の前提チェック)
- 主成分分析(PCA)(統計・主成分回帰の土台)
- 教師あり学習・回帰 目次
- 機械学習テキスト 全体目次