🎓 レベル:標準 | 重要度:B(標準)
要点(BLUF)
- 判別分析は「各クラスのデータが多変量正規分布から出ている」と仮定し、ベイズの定理で事後確率が最大のクラスに割り当てる分類手法です。
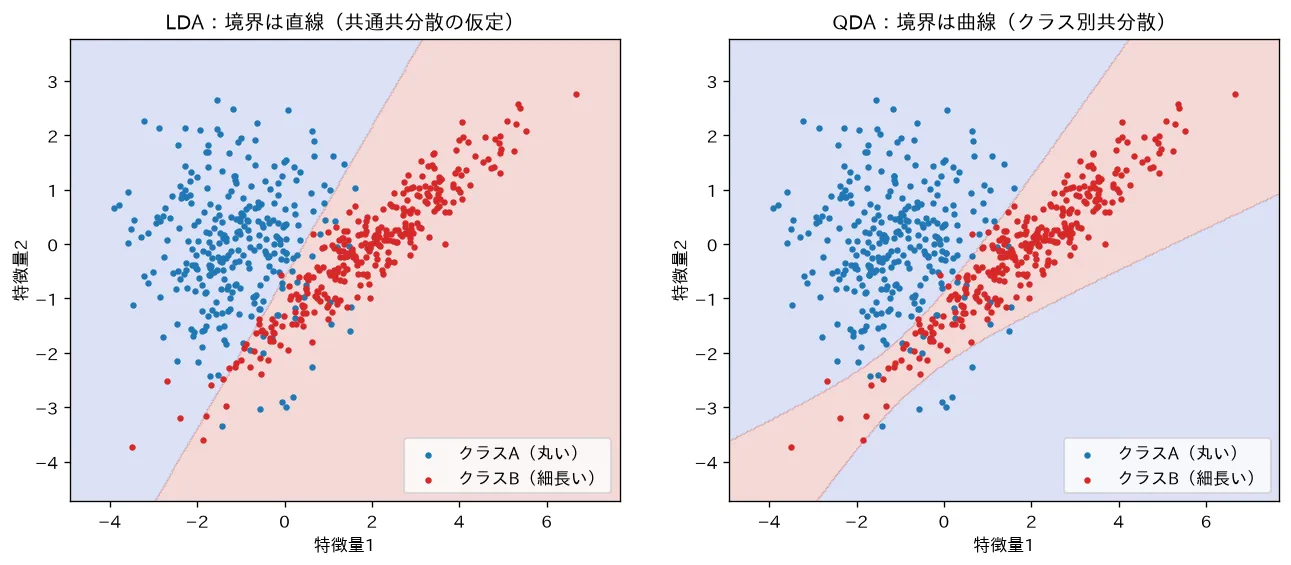
- 各クラスの共分散行列が共通だと判別関数の二次項が打ち消し合い、決定境界は直線(超平面)になります=LDA。共分散がクラスごとに違うと二次項が残り、境界は曲線(二次曲面)になります=QDA。
- 判別の中身は「点 が各クラスの中心からどれだけ離れているか」を測るマハラノビス距離+クラスの出やすさ(事前確率)の比較です。
1. ベイズ判別の考え方
分類のゴールは、入力 を見て最も「ありそうな」クラスを選ぶことです。ありそうさを確率で表したものが事後確率 で、これが最大のクラスを選べば誤分類確率が最小になります。これをベイズ判別(ベイズ最適分類器) と呼びます。
事後確率はベイズの定理で次のように分解できます(→ 統計 ベイズの定理):
ここで はクラス の事前確率(全体に占める割合)、 は「クラス の中で がどのくらい出やすいか」を表すクラス条件付き分布です。
要するに:分母はどのクラスでも共通なので、比較に効くのは分子 だけ。「そのクラスらしさ(条件付き分布)×そのクラスの出やすさ(事前確率)」が最大のクラスを選ぶ、というのがベイズ判別です。
問題は をどうモデル化するか。ここで多変量正規分布を仮定するのが判別分析です。
2. 各クラスを多変量正規と仮定する
クラス のデータが、平均 ・共分散行列 の 次元多変量正規分布に従うと仮定します:
要するに:各クラスは「中心 のまわりに、 という形(広がり・傾き)の楕円状に散らばっている」と見なす、ということです。指数の中の は、後で出てくるマハラノビス距離の二乗そのものです。
flowchart LR
A["入力 x"] --> B["各クラスの正規分布で<br/>P(x | y=k) を評価"]
B --> C["事前確率 πk を掛ける"]
C --> D["判別関数 δk(x) を比較"]
D --> E["最大の k に割り当て"]
3. 判別関数の導出:なぜ log を取るか
事後確率を直接比べてもよいのですが、指数関数が邪魔なので対数を取ります。対数は単調増加なので、 を最大化することは元の量を最大化することと同じです。分母(共通項)と だけの定数項を捨てて、クラス に依存する部分だけ残したものを判別関数(discriminant function) と呼びます:
そして が最大のクラスに を割り当てます。
要するに:判別関数は「マハラノビス距離が近いほど大きく(第2項)、分布が広すぎないほど大きく(第1項のペナルティ)、もともと出やすいクラスほど大きい(第3項)」というスコアです。これを各クラスで計算して一番大きいものを選ぶだけ。
4. 共分散が共通 → 線形になる(LDA)
ここからが核心です。まず がすべてのクラスで等しい()と仮定します。マハラノビス距離の二乗を展開すると:
このうち①の はクラス に依存しません。 が共通なので も共通。クラス比較では共通項は無視できるので、判別関数は
となり、 について一次式(線形) になります。これが LDA(Linear Discriminant Analysis) です。
要するに:二次の項 が全クラスで同じだから打ち消し合い、 の一次項だけが残る。だから境界が直線になるのです。
決定境界(クラス と の引き分けライン)は で、これは
という の一次方程式=超平面(直線) になります。
graph LR
LDA["LDA:Σk = Σ(共通)"] -->|"x²項が消える"| LIN["決定境界:直線(超平面)"]
QDA["QDA:Σk がクラスごと"] -->|"x²項が残る"| QUAD["決定境界:曲線(二次曲面)"]
5. 共分散が異なる → 二次になる(QDA)
次に がクラスごとに違う一般の場合に戻ります。すると判別関数の中の二次項 がクラスごとに違うため、もう打ち消し合いません。また も残ります。判別関数は
と について二次式になります。これが QDA(Quadratic Discriminant Analysis) です。決定境界 も二次方程式になり、曲線(放物線・楕円・双曲線などの二次曲面) を描けます。
要するに:LDA は「全クラスの楕円の形と向きが同じ」という強い制約で境界を直線に固定したもの。QDA はその制約を外して各クラスに自前の楕円を許した結果、境界が曲がれるようになったものです。
💡 LDA は QDA の特殊ケース( を全部同じに縛ったもの)です。QDA はクラスごとに ( 行列)を推定するためパラメータが多く、次元 が大きい・データが少ないと共分散の推定が不安定になり過学習しやすくなります。LDA は共分散を1つに共有する分パラメータが少なく頑健です(バイアス-バリアンスのトレードオフ、→ 評価指標(分類)とROC・AUC の文脈)。
6. マハラノビス距離との関係
判別関数の主役 は、 と中心 のマハラノビス距離の二乗 です。これは「分布の広がりで割り引いたユークリッド距離」と読めます:
ふつうのユークリッド距離は全方向を平等に測りますが、マハラノビス距離は を挟むことで「データがよく散らばる方向は近め、あまり散らばらない方向は遠め」に補正します。
要するに:判別分析は「マハラノビス距離が最も近いクラスに割り当てる(+事前確率で微調整)」分類器です。事前確率が全クラス等しく( 共通)共分散も共通(LDA)なら、判別は純粋に「マハラノビス距離が最も近いクラスを選ぶ」だけに帰着します。これは「データを白色化(球状化)してから、最も近い中心をユークリッド距離で選ぶ」のと等価です。
⚙️ 白色化(whitening):変換 をかけると共分散が単位行列になり、マハラノビス距離はその空間での普通のユークリッド距離に一致します。LDA は「空間を球状に直してから最近傍中心を選ぶ」と理解できます。
7. ロジスティック回帰との違い(生成 vs 識別)
LDA とロジスティック回帰は、決定境界がどちらも線形で見かけはそっくりです。2クラス LDA の事後確率を整理すると
となり、ロジスティック回帰とまったく同じシグモイド形になります。違いはパラメータの決め方です。
| LDA / QDA(生成モデル) | ロジスティック回帰(識別モデル) | |
|---|---|---|
| モデル化する対象 | 同時分布 ( を正規と仮定) | 条件付き分布 を直接 |
| 学習で最大化するもの | 同時尤度( を推定) | 条件付き尤度( を直接最尤) |
| 仮定 | クラスが多変量正規という強い仮定 | 仮定が少なく頑健 |
| 当たれば | 仮定が正しければ効率よく少データでも安定 | 仮定が崩れても比較的ロバスト |
要するに:LDA は「データの生成過程(各クラスの正規分布)を丸ごとモデル化してから、ベイズで境界を逆算する」生成的アプローチ。ロジスティック回帰は「境界そのものを直接学ぶ」識別的アプローチです。正規仮定が妥当ならLDAが効率的、そうでなければロジスティック回帰が無難、というのが実務の目安です(→ ロジスティック回帰)。
graph TB
G["生成モデル:P(x, y) を丸ごとモデル化"] --> GA["LDA / QDA<br/>(各クラスを正規分布で仮定)"]
GA --> GB["ベイズの定理で<br/>P(y | x) を逆算"]
D["識別モデル:P(y | x) を直接モデル化"] --> DA["ロジスティック回帰<br/>(境界を直接学習)"]
GB --> R["どちらも線形境界に到達<br/>(推定法が違う)"]
DA --> R
⚠️ よくある誤解
- 「LDA は次元削減の手法」だけだと思うのは半分だけ正解。同じ名前で「クラス間分散/クラス内分散を最大化する軸へ射影する」フィッシャーの線形判別(次元削減)も LDA と呼ばれます。実は両者は等価で、本ノートの「正規仮定+共通共分散のベイズ判別」と同じ軸に行き着きます(→ 統計 判別分析、関連して 主成分分析(PCA) とは目的が違う点に注意:PCAは分散最大、LDAはクラス分離最大)。
- 「QDA は LDA の上位互換」ではない。QDA は表現力が高い分パラメータ(クラスごとの共分散)が多く、データが少ない・次元が高いと共分散推定が不安定で過学習します。データが潤沢で境界が明らかに曲がっているときだけ QDA が有利です。
- 「線形境界=特徴も線形でしか効かない」ではない。 などの特徴を足せば LDA でも曲がった境界を作れます。LDA/QDA の「線形/二次」は元の特徴空間での境界の形の話です。
- 正規仮定は必須に見えて、外れても意外と動く。境界が線形でうまく分かれるデータなら、正規分布から多少ズレても LDA は実用的に機能します。ただし強く非正規・外れ値が多いと崩れます。
- クラスの事前確率 を無視しない。不均衡データでは の項が境界を多数派クラス側へずらします。これは正しい挙動ですが、少数派を重視したいなら を調整する必要があります。
対応するシミュレーション
simulations/lda_qda.py:クラスごとに広がり方(共分散)が違う2クラスデータで LDA と QDA の決定境界を並べて描きます。共通共分散を仮定する LDA は境界が直線になるのに対し、クラス別共分散の QDA は境界が曲線になり、細長いクラスの形に沿ってより自然に分けられること(訓練正解率も QDA が高い)を可視化します。
関連ノート
- 教師あり学習・分類 目次
- ロジスティック回帰(同じ線形境界だが識別モデル・直接学習)
- k近傍法(k-NN)(距離に基づく分類・こちらは分布を仮定しない)
- 評価指標(分類)とROC・AUC(分類器の性能評価)
- 判別分析(統計・判別分析の土台、フィッシャーの線形判別)
- 主成分分析(PCA)(統計・PCAとの目的の違い:分散最大 vs クラス分離最大)
- ベイズの定理(統計・事後確率の分解)
- 機械学習テキスト 全体目次