🎓 レベル:基礎 | 重要度:A(必須)
📎 前提:訓練・検証・テストと交差検証(リーク防止)
要点(BLUF)
- 特徴量エンジニアリングは、生データをモデルが学べる形に整える工程です。数値のスケーリング・カテゴリのエンコーディング・欠損値処理・新しい特徴量の生成が柱で、ここの質がモデルの上限を決めます(Garbage In, Garbage Out)。
- スケーリングが要るかは手法しだいです。距離ベース(k近傍・SVM)と勾配ベース(線形回帰・ニューラルネット)・PCAはスケールに敏感ですが、木系(決定木・ランダムフォレスト)はスケール不変で不要です。
- 最重要は データリークの防止。前処理の統計(平均・分散・エンコード表)は訓練データだけで学習し、検証/テストにはその基準を適用するだけにします(fit on train, transform on test)。
1. なぜ前処理が重要か — Garbage In, Garbage Out
機械学習のモデルは、与えられた特徴量に書かれている情報以上のことは学べません。どんなに高性能なアルゴリズムでも、入力が荒れていれば出力も荒れます。これを Garbage In, Garbage Out(ゴミを入れればゴミが出る) と言います。
実務では、モデル選びやハイパラ調整よりも、前処理と特徴量設計に時間の大半を使うのが普通です。理由はシンプルで、
- モデルが学べる情報の上限は、特徴量がどれだけ「学習に適した形」になっているかで決まる
- 良い特徴量があれば単純なモデルでも十分な性能が出るが、悪い特徴量だと複雑なモデルでも頭打ちになる
からです。前処理は地味ですが、性能への効きが一番大きい工程だと考えてください。
flowchart LR RAW["生データ"] --> CLEAN["欠損値処理"] CLEAN --> SCALE["数値スケーリング"] SCALE --> ENC["カテゴリのエンコーディング"] ENC --> FEAT["特徴量生成・選択"] FEAT --> MODEL["モデル学習"]
要するに:モデルの性能はデータの質で頭打ちになるので、前処理は「あとからやる雑用」ではなく性能の主役級の工程です。
2. 数値のスケーリング — 標準化と正規化
数値特徴量は、スケール(値の桁・範囲)がバラバラなことが多いです。たとえば年齢(0〜100)と年収(0〜数百万)を一緒に使うと、距離や勾配の計算で桁の大きい特徴量だけが効いてしまう。これを揃えるのがスケーリングです。
標準化(z-score)
平均0・標準偏差1に揃えます。
ここで は特徴量の平均、 は標準偏差です。
要するに:「平均から標準偏差いくつ分ずれているか」に変換します。外れ値があっても極端には潰れにくく、最もよく使う既定の選択です。
正規化(min-max)
最小0・最大1の範囲に押し込めます。
要するに:値を に直線で詰め込みます。範囲が決まっていて扱いやすい一方、外れ値に弱い(1個の極端な値が を引っ張ると、他がすべて狭い範囲に押し潰される)。
なぜスケーリングが要るのか — 手法ごとの理由
スケーリングの要否は、アルゴリズムが特徴量をどう使うかで決まります。
| 手法のタイプ | 例 | スケーリング | 理由 |
|---|---|---|---|
| 距離ベース | k近傍・SVM・k-means | 必要 | ユークリッド距離が桁の大きい特徴量に支配される |
| 勾配ベース | 線形回帰(最小二乗法と確率的解釈)・ロジスティック回帰・ニューラルネット | 必要 | スケールが違うと損失曲面が歪み、勾配降下の収束が遅くなる/正則化が不公平になる |
| 分散ベース | 主成分分析と次元削減(PCA) | 必要 | 分散最大の方向を探すため、分散の大きい特徴量(=桁の大きい特徴量)に主成分が引っ張られる |
| 木系 | 決定木・ランダムフォレスト・勾配ブースティング | 不要 | 分割は「しきい値で大小を分ける」だけ。単調変換しても順序が変わらず分割点も変わらない |
木系がスケール不変なのは本質的です。決定木は「 か否か」のように順序(大小)だけを見ます。標準化や正規化は単調増加変換なので順序を保存し、対応するしきい値に直されるだけで分割は同じになります。だから木系に標準化をかけても性能は変わりません(無駄ではないが不要)。
要するに:距離・勾配・分散を使う手法はスケールに敏感なので揃える。木系は大小だけ見るので不要。
3. カテゴリのエンコーディング
モデルは数値しか扱えないので、「赤・青・緑」のようなカテゴリ変数を数値に変換します。代表的な3つを使い分けます。
One-hot エンコーディング
各カテゴリを 0/1 の列に展開します。「色」が3種類なら 色_赤・色_青・色_緑 の3列にして、該当する列だけ1にします。
- 利点:カテゴリ間に順序を持ち込まない(色に大小はない、を正しく表現できる)
- 欠点:次元が増える。カテゴリ数(カーディナリティ)が高いと列が爆発し、スパース(ほぼ0)な巨大行列になる
ラベルエンコーディング
カテゴリを整数に対応させます(赤→0、青→1、緑→2)。1列で済みますが、勝手に順序・距離が生まれる(緑が赤の2倍、という誤った大小関係)。
順序が本当に意味を持つ順序尺度(小・中・大→0・1・2)には適切ですが、順序のない名義尺度に線形モデルで使うのは危険です。一方、木系では大小を分割に使うだけなので、ラベルエンコーディングでも害が少なく、列が増えない利点が活きます。
ターゲットエンコーディング
各カテゴリを、そのカテゴリにおける目的変数の平均で置き換えます。たとえば「都市」を「その都市での平均購入額」に変換します。1列で高カーディナリティをさばける強力な手法ですが、目的変数を使うためデータリークと過学習のリスクが高い(詳細は第6節)。
flowchart TD
CAT["カテゴリ変数"] --> Q1{"順序がある?"}
Q1 -->|"はい(小中大など)"| LBL["ラベルエンコーディング"]
Q1 -->|"いいえ"| Q2{"カーディナリティは?"}
Q2 -->|"低い"| OH["One-hot エンコーディング"]
Q2 -->|"高い"| TGT["ターゲットエンコーディング(リーク注意)"]
要するに:順序ありはラベル、順序なしで種類が少なければone-hot、種類が多すぎてone-hotが爆発するならターゲット(ただしリーク対策必須)。
4. 欠損値処理
現実のデータには欠損(NaN)がつきものです。多くのモデルは欠損があると学習できないので、対処します。
削除か、補完か
- 行を削除:欠損のある行を捨てる。欠損がごく一部かつランダムなら手軽ですが、欠損が多いと貴重なデータを大量に失います。
- 列を削除:欠損が大半を占める列を捨てる。その特徴量がほぼ使えないとき。
- 補完(imputation):欠損を何かで埋める。最も一般的。
補完の方法
| 方法 | 内容 | 向き |
|---|---|---|
| 平均補完 | その列の平均で埋める | 分布が左右対称なとき |
| 中央値補完 | その列の中央値で埋める | 歪んだ分布・外れ値があるとき(中央値は外れ値に強い) |
| 最頻値補完 | 最も多いカテゴリで埋める | カテゴリ変数 |
| モデルベース | k近傍・回帰・ランダムフォレストで欠損値を予測して埋める | 特徴量間に相関があり、精度を上げたいとき |
単純補完(平均など)は手軽ですが、分散を縮める(同じ値を多数入れるので分布が痩せる)という副作用があります。モデルベース補完は他の特徴量との関係を使うので精度は上がりますが、計算が重くなります。
欠損の仕組み — MCAR / MAR / MNAR
なぜ欠損したかで、適切な対処が変わります。
- MCAR(Missing Completely At Random):完全にランダムに欠損。欠損が他の何にも依存しない。削除や平均補完でも偏りが出にくい。
- MAR(Missing At Random):欠損が他の観測されている変数に依存(例:若い人ほど年収を書かない=年齢で説明できる)。年齢など観測変数を使ったモデルベース補完が有効。
- MNAR(Missing Not At Random):欠損が欠損した値そのものに依存(例:高所得者ほど年収を書かない)。最も厄介で、単純補完は偏りを生む。「欠損だった」という情報自体を特徴量にする等の工夫が要る。
要するに:歪んだデータは中央値、相関があるならモデルベース。そして「なぜ欠けたか(MCAR/MAR/MNAR)」で偏りの出方が変わるので、欠損のパターンも調べます。
5. 特徴量生成・選択
既存の特徴量から、より学習に効く新しい特徴量を作る/削るのが特徴量エンジニアリングの花形です。
特徴量生成
- ドメイン知識:分野の知見で意味のある量を作る(例:身長と体重→BMI、日時→曜日・時間帯・祝日フラグ)。モデルが自力では気づきにくい関係を人が与えます。
- 交互作用特徴量:特徴量の積など、組み合わせの効果を明示的に作る(例:
面積 × 立地スコア)。線形モデルは特徴量同士の掛け合わせを自力で表現できないので、人が作ると効きます。 - 集約特徴量:グループごとの統計量(ユーザーごとの平均購入額、過去7日の合計など)。
特徴量選択・次元削減
特徴量が多すぎると、ノイズの混入・過学習・計算コストの増大を招きます。減らす方向の工夫も重要です。
- 特徴量選択:相関や重要度で効かない特徴量を捨てる。
- 次元削減:主成分分析と次元削減(PCA)で、情報を保ちつつ少数の合成軸にまとめる。
要するに:人の知識で効く特徴量を足し、効かない・冗長な特徴量を減らす。両方向のチューニングが効きます。
6. ⚠️ データリーク — 最重要の落とし穴
前処理で最も致命的なミスが データリーク(data leakage) です。前処理の基準(平均・分散・エンコード表など)を全データで計算してしまうと、テストの情報が訓練側に漏れ、開発中だけ優秀で本番で崩れるモデルになります(訓練・検証・テストと交差検証)。
鉄則:fit on train, transform on test
前処理には2つの段階があります。
- fit(基準を学ぶ):標準化なら平均 ・標準偏差 を計算する。補完なら埋める値(平均・中央値)を決める。エンコードなら対応表を作る。
- transform(基準を当てる):学んだ基準でデータを変換する。
ここで守るべきは、fit は訓練データだけで行い、検証/テストには transform を当てるだけにすることです。
flowchart TD ALL["全データ"] --> SPLIT["分割を先に行う"] SPLIT --> TR["訓練データ"] SPLIT --> TE["テストデータ"] TR --> FIT["fit:平均・分散・エンコード表を学ぶ(訓練だけ)"] FIT --> TTR["transform:訓練を変換"] FIT --> TTE["transform:テストを変換(訓練の基準を当てる)"] TTR --> MODEL["モデル学習"] TTE --> EVAL["最終評価"]
テストの平均や分散を使ってしまうと、「未知のはずのテストを少し覗いてから訓練した」ことになり、評価が楽観的に出ます。本番で来るデータの平均・分散は事前にわからないので、訓練で決めた基準をそのまま当てるのが現実に即した正しいやり方です。
交差検証では各 fold 内で前処理する
k分割交差検証でも同じ原則が効きます。前処理を分割前に1回やってしまうと、各 fold の検証データの情報が前処理の基準に混じり、リークします。正しくは、**各 fold の中で「訓練側だけで fit → 検証側に transform」**を毎回やり直します(訓練・検証・テストと交差検証)。前処理+モデルをパイプラインにまとめ、それを交差検証にかけると、この順序が自動で守られて安全です。
ターゲットエンコーディングは特にリークしやすい
第3節のターゲットエンコーディングは目的変数の平均を使うので、自分の行の目的変数を使ってその行の特徴量を作ると、答えを覗いていることになります。対策は、
- 全データで平均を取らず、訓練データだけで対応表を作る
- さらに out-of-fold(自分の fold を除いた平均) で計算し、自分の行の目的変数を使わない
- カテゴリの件数が少ないと平均が不安定なので、全体平均とのブレンド(スムージング) で過学習を抑える
要するに:前処理の「基準を学ぶ(fit)」は必ず訓練データだけで。テストや他 fold の情報を一滴も混ぜないことが、本番で崩れないモデルの条件です。
7. まとめ
- 前処理はモデル性能の上限を決める主役級の工程(Garbage In, Garbage Out)。
- スケーリング:距離・勾配・分散ベースは必要、木系は不要。既定は標準化、外れ値が怖いときは中央値系の発想で。
- エンコーディング:順序ありはラベル、順序なし低カーディナリティはone-hot、高カーディナリティはターゲット(リーク対策必須)。
- 欠損値:歪みには中央値、相関にはモデルベース。MCAR/MAR/MNAR で偏りの出方が違う。
- リーク防止が最重要:fit on train, transform on test。交差検証は fold 内で前処理。
対応するシミュレーション
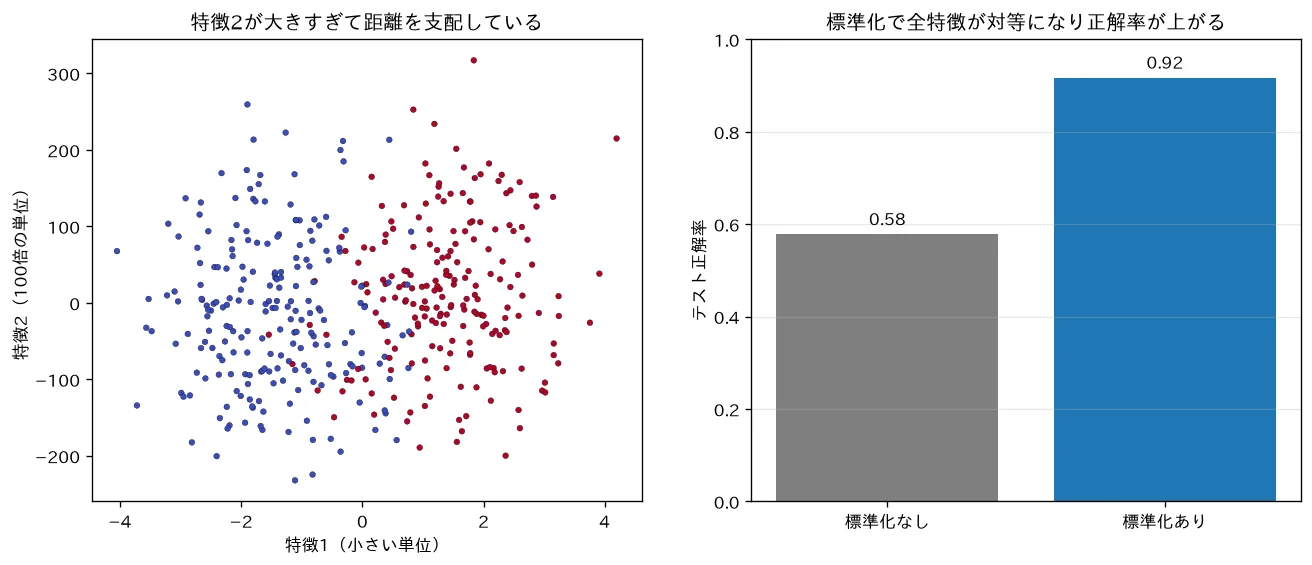
simulations/feature_scaling.py:クラスを強く分ける特徴1と、無関係だが単位が100倍大きい特徴2を持つデータで k近傍法を比べます。標準化なしだと距離が大きい単位のノイズ特徴2に支配されて正解率が当てずっぽうに近づき(0.58)、標準化すると本当に効く特徴1が距離に効いて正解率が上がる(0.92)ことを可視化します。あわせて、標準化の平均・分散は訓練データだけで決めテストには適用するだけ(データリーク防止)という実装上の鉄則を示します。
関連ノート
- 実践・MLOps 目次 — このドメインの目次
- 不均衡データの扱い — 偏ったラベル分布への対処
- 訓練・検証・テストと交差検証 — リーク防止と評価設計の土台
- 線形回帰(最小二乗法と確率的解釈) — スケーリングが効く勾配ベース手法
- 主成分分析と次元削減 — スケール依存の次元削減・特徴量圧縮
- 決定木 — スケール不変な木系手法
- 機械学習テキスト 全体目次 — 全ドメインのハブ