🎓 レベル:標準 | 重要度:A(必須)
📎 前提:次元の呪い | 数理:主成分分析(PCA)(統計, 固有値分解の数理)・分散共分散行列・相関行列(統計)
要点(BLUF)
- 主成分分析(PCA)は、データの分散が最大になる直交方向(主成分)を順に見つけ、その上位 本へ射影して 次元を 次元へ落とす線形の次元削減手法です。教師なし(ラベルを使わない)。
- 中身は1つの最適化です。「射影後の分散を最大化する」と「射影で失う情報=再構成誤差を最小化する」は同じ問題で、解はどちらも共分散行列の固有ベクトル(実装上は SVD の特異ベクトル)になります。固有値が各主成分の分散です。
- 強力ですが仮定は明確です。**「分散が大きい=情報が多い」「構造は線形」**を前提にしているので、スケールに敏感(→標準化)で、クラス分離が目的なら別物(→主成分分析(PCA) の判別分析や教師あり手法)。非線形構造には カーネルPCAと多様体学習 へ進みます。
1. 次元削減とは・なぜ要るのか
次元削減は、 個の特徴量を、情報をなるべく保ったまま少数の 個に圧縮する操作です。動機は主に4つあります。
- 次元の呪い対策:次元の呪い の通り、高次元では点がスカスカになり距離が意味を失い、必要なサンプル数が指数的に増えます。次元を下げると密度が回復します。
- 可視化:2〜3次元に落とせば人間が目で見られます。クラスタや外れ値の当たりを付けるのに有効です。
- ノイズ除去・圧縮:本質的な変動(信号)を残し、小さな変動(ノイズ)を捨てます。
- 多重共線性の緩和:相関の強い特徴量を直交方向にまとめ直すので、重回帰と多重共線性 のような不安定さを避けられます(主成分回帰)。
PCA はこのうち線形・教師なし・分散基準の代表選手です。「線形」とは、新しい軸が元の特徴量の一次結合(足し算と定数倍だけ)で書けるという意味です。
要するに:たくさんの軸を、情報の損が一番少ない少数の軸に取り替える。PCA はその軸を「分散が大きい順」に選びます。
2. データの中心化と共分散行列
PCA の前処理は**中心化(centering)**です。各特徴量から平均を引き、各列の平均を 0 にします。 個・ 次元のデータを行に並べた行列を (既に中心化済み)とすると、共分散行列は
です。 の対角成分が各特徴量の分散、非対角成分が特徴量間の共分散。 は対称・半正定値なので、固有値はすべて実数かつ非負、固有ベクトルは直交に取れます——これが後で効きます。
中心化が必須なのは、 が「原点まわりの二次モーメント」であって、平均を引かないと分散ではなくなるからです。平均を引いて初めて が共分散になります。
要するに:まず平均を引いて原点を重心に合わせ、特徴量どうしの「一緒に動く度合い」を にまとめます。
3. 定式化(その1):分散最大化
第1主成分 は「この向きに射影したとき、射影点の分散が最大になる単位ベクトル」です。データ点 を方向 ()に射影したスカラーは 。中心化済みなのでその分散は
よって第1主成分は次の制約付き最大化の解です。
ラグランジュ未定乗数法 → 固有値問題
制約 をラグランジュ乗数 で組み込みます。
で微分して 0 と置くと( は対称なので )、
つまり は** の固有ベクトル**、 はその固有値でなければなりません。さらにこの での目的関数値は
なので、射影後の分散はちょうど固有値 に等しい。分散を最大にしたいので、選ぶべきは最大固有値 に対応する固有ベクトルです。これが第1主成分 で、その分散は 。
第2主成分は「 と直交する」制約を追加して同じ最大化を解くと、2番目に大きい固有値 の固有ベクトルになります。以下同様で、主成分 = 固有値の大きい順に並べた固有ベクトル、各主成分の分散 = その固有値です。固有値分解そのものの数理(対称行列の固有値が実数になる理由など)は 主成分分析(PCA)(統計)に譲ります。
要するに:分散最大化を真面目に解くと、自動的に「共分散行列の固有ベクトルを固有値の大きい順に取れ」という答えが出ます。固有値がそのまま「その軸が説明する分散の量」です。
4. 定式化(その2):再構成誤差最小化、そして双対性
PCA にはもう1つの顔があります。「上位 本の軸だけで元データを近似したとき、近似の誤差(再構成誤差)を最小にする部分空間を選べ」という見方です。実はこれが3節と同じ問題であることを示します。これが PCA の双対性(duality)です。
正規直交な 本の方向を列に持つ ()を取ります。点 をこの部分空間に射影して戻した再構成は 。最小化したいのは平均二乗の再構成誤差
トレースによる分解
は射影行列で 、かつ が成り立ちます(直交射影なのでピタゴラスの定理そのもの)。これを代入し、 を使うと
第1項 は に依らない全分散の定数です。したがって
右辺は「射影後の分散の合計を最大化せよ」——まさに3節の多次元版です。**全分散 = 射影後に残る分散 + 失う分散(再構成誤差)**という恒等式なので、片方を最大化すれば自動的にもう片方が最小化されます。
graph LR
Total["全分散 tr(S) = Σλ (一定)"] --> Keep["残す分散 = tr(W^T S W) (最大化したい)"]
Total --> Lost["失う分散 = 再構成誤差 J(W) (最小化したい)"]
Keep -. "和は常に一定なので一方を上げれば他方が下がる(双対)" .- Lost
要するに:「一番よく説明する向き」を選ぶのと「一番情報を捨てない向き」を選ぶのは、同じコインの裏表です。全分散が一定だから、残す分散を最大化=失う分散を最小化、になります。
5. SVD:実装ではこちらを使う
理論は共分散行列 の固有値分解ですが、実装では を作らずに を直接 SVD します。中心化済み の特異値分解は
で、 は直交、 は対角に特異値 を並べたものです。ここで
これは の固有値分解そのものです。つまり
- の列(右特異ベクトル)=主成分( の固有ベクトルと一致)
- 固有値 (特異値の二乗を で割ったもの)
- 射影後の座標(主成分得点)は で一気に得られる
なぜ を経由しないか。 を作ると条件数が二乗されて数値的に不安定になり、メモリも 必要です。SVD は から直接、より安定に同じ答えを出します。scikit-learn の PCA も内部は SVD です。
要するに:PCA = 共分散行列の固有値分解、ですが計算は SVD で代用するのが定番。 が主成分、特異値の二乗 が分散です。
6. 寄与率と次元の選び方
主成分 が説明する分散は 、全分散は 。そこで
と定義します。寄与率は「その軸が全情報の何割を担うか」。 の選び方の定番は2つです。
- 累積寄与率のしきい値:累積で 90% や 95% を超える最小の を採る(圧縮・前処理向き)。
- スクリープロット(scree plot):固有値 を大きい順に並べた折れ線を描き、「肘(elbow)」——傾きが急に緩むところ——で切る。肘より右は「なだらかな砂利(scree)=ノイズ」とみなす発想です。
flowchart LR
A["データ X"] --> B["中心化(列平均を引く)"]
B --> C["SVD:X = U Σ Vᵀ(または S = X^T X / n の固有値分解)"]
C --> D["固有値 λ を降順に並べる"]
D --> E["寄与率・累積寄与率を計算"]
E --> F["スクリープロットの肘 or 累積寄与率しきい値で k を決定"]
F --> G["上位 k 本へ射影:得点 = X·V_k"]
注意点として、スクリープロットの肘は主観的です。曲線が滑らかだと肘がはっきりせず、複数の肘が見えることもあります。下流タスク(分類・回帰)がある場合は、累積寄与率より交差検証で を選ぶほうが堅実です。
要するに:固有値の大きさ=その軸の重要度。累積で十分な割合を確保できる最小の 、または折れ線の肘で次元を決めます。
7. 白色化(whitening)
主成分得点を、各軸が分散1・互いに無相関になるよう正規化する操作を**白色化(whitening / sphering)**と呼びます。第 主成分の得点を で割るだけです。これで共分散行列が単位行列になり、データが等方的(どの向きも同じ広がり)になります。
なぜ要るか。下流のモデルが各方向を対等に扱ってほしいとき(例:距離ベースの手法、一部のニューラルネット入力)に効きます。ただし小さい固有値で割るとノイズを増幅しやすいので、 が極端に小さい軸を切ってから行うのが安全です。
8. ML文脈での使いどころと限界
使いどころ
- 前処理:高次元・相関の強い特徴量を圧縮してから学習器に渡す。学習が速く・安定になります。
- 可視化:上位2〜3主成分でデータを散布図に。クラスタ・外れ値の探索的分析(EDA)の定番。
- ノイズ除去:小さい固有値の軸を捨てて再構成すると、信号を残してノイズを落とせます(画像のデノイズ等)。
- 多重共線性対策:相関のかたまりを直交主成分にまとめ、それを説明変数に使う(主成分回帰)。重回帰と多重共線性 の不安定さを回避できます。
限界(前提が崩れると効かない)
- 線形しか捉えない:主成分は元特徴量の一次結合。曲がった構造(らせん・円環など)は1枚の平面に潰せません。→ 非線形版の カーネルPCAと多様体学習 へ。
- 「分散が大きい=重要」とは限らない:分散はあくまで「広がり」。タスクにとって重要な情報が小さい分散に潜むこともあります。
- 教師なしなのでクラス分離を狙わない:PCA はラベルを一切見ません。分類が目的なら、クラス間分散を最大化する**判別分析(LDA)**のほうが分離に直結します(PCA は全体の広がり、LDA はクラスの分かれ方を見る)。判別分析の数理は 主成分分析(PCA)(統計)周辺を参照。
要するに:PCA は「線形・分散基準・教師なし」の枠の中で最強クラスですが、その枠の外(非線形・クラス分離・小分散に潜む情報)には届きません。目的に合うかを毎回確認します。
⚠️ よくある誤解・落とし穴
- スケールに極端に敏感:単位の大きい特徴量(例:年収 vs 年齢)が分散で勝ってしまい、主成分がそれに引っ張られます。**単位がバラバラなら標準化(各列を標準偏差で割る)**してから PCA を。標準化済み PCA は実質「相関行列の固有値分解」です(分散共分散行列・相関行列)。
- 主成分は解釈しづらい:主成分は全特徴量の混ぜ合わせなので「第1主成分=○○」と一言で言いにくいことが多い。負荷量(loading=固有ベクトルの成分)で寄与の大きい元特徴量を読むのが定石ですが、過度な意味づけは禁物です。
- 分散最大 ≠ クラス分離:可視化して2クラスが重なって見えても、それは「全体の広がりで切った断面が悪いだけ」かもしれません。分類前提なら LDA や教師あり次元削減を検討。
- 中心化を忘れる:平均を引かないと が共分散にならず、第1主成分が「平均方向」を拾ってしまいます。実装ライブラリは通常自動で中心化しますが、自前実装では明示的に。
- 固有値の符号・順序:固有ベクトルは符号が一意に決まりません( と はどちらも主成分)。可視化の向きが実行ごとに反転しても、それは誤りではありません。
対応するシミュレーション
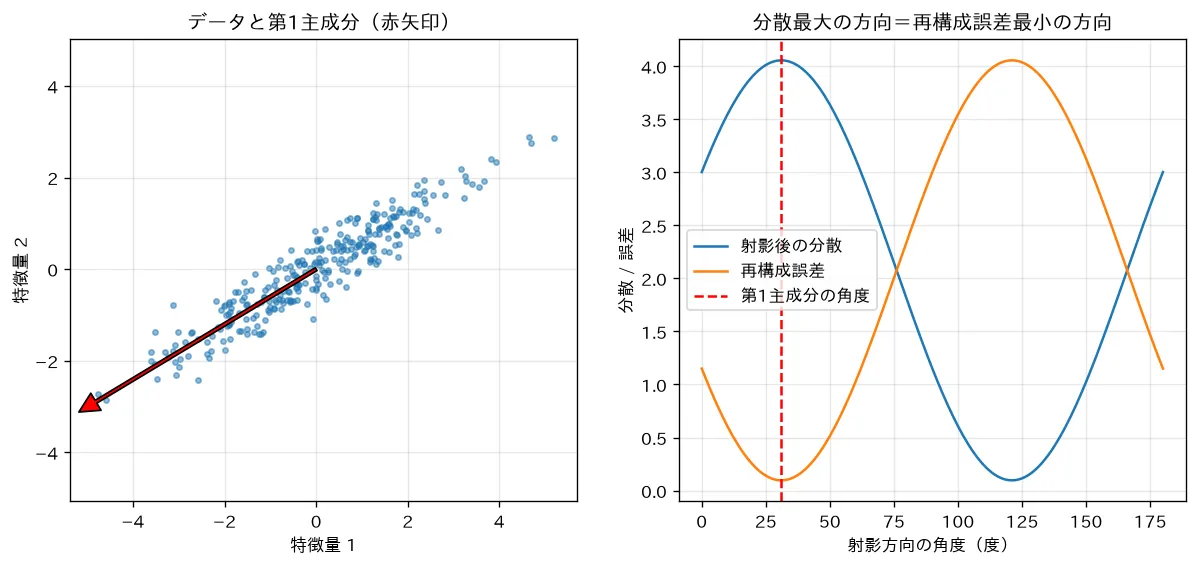
simulations/pca_variance.py:相関のある2次元データで、射影方向を 〜 まで回しながら射影後の分散と再構成誤差を測ります。分散が最大になる角度と再構成誤差が最小になる角度がぴったり一致し、それが共分散行列の第1固有ベクトルの方向に一致することを数値・グラフで確認できます(「全分散=射影分散+再構成誤差」というトレース恒等式の実証)。
関連ノート
- 同ドメイン:教師なし学習 目次・カーネルPCAと多様体学習(PCA の非線形・多様体への一般化)
- 前提・周辺:次元の呪い(なぜ次元を下げたいのか)・重回帰と多重共線性(主成分回帰で対策する文脈)
- 数理の土台(統計サイト):主成分分析(PCA)(固有値分解・判別分析の数理)・分散共分散行列・相関行列(共分散行列と相関行列、標準化との関係)
- 全体地図:機械学習テキスト 全体目次
Sources(DeepResearch で横断した主な情報源):
- CSC411 Lecture 12: Principal Component Analysis (U. Toronto)
- Principal Component Analysis and Dimensionality Reduction (CMU 10-701)
- Lecture Notes on Principal Component Analysis (Laurenz Wiskott)
- PCA Part 1: The Different Formulations (Towards Data Science)
- Relationship between PCA and SVD (Medium)
- Importance of Feature Scaling (scikit-learn)
- LDA vs PCA for dimensionality reduction (Sebastian Raschka)