🎓 レベル:発展 | 重要度:B(標準)
📎 前提:主成分分析と次元削減 | 関連:サポートベクターマシン(SVM)(カーネルトリック)
要点(BLUF)
- **線形PCAは「直線(超平面)でしか圧縮できない」**ので、スイスロールのように曲がった構造を持つデータをほどけません。非線形次元削減は、この「曲がり」を扱うための道具です。
- カーネルPCAは、データをカーネルで高次元の特徴空間へ写してからPCAをする手法。実体はグラム行列(カーネル行列)の固有値分解で、写像を明示的に計算せず内積だけで済ませるカーネルトリック(サポートベクターマシン(SVM)と同じ着想)が肝です。
- t-SNE・UMAPは「近傍関係の確率」を高次元と低次元で合わせる可視化専用の手法。距離やクラスタの大きさを保存する保証はないので、絵を読みすぎないのが最重要の注意点です。
1. なぜ線形PCAでは足りないのか
主成分分析と次元削減のPCAは、データを直線(多次元なら超平面)に射影して分散最大の方向を取り出す手法でした。これは「データがおおむね平らな低次元部分空間に乗っている」ときは完璧に効きます。
問題は、現実の高次元データがしばしば曲がった面の上に乗っていることです。教科書的な例が**スイスロール(Swiss roll)**です。3次元空間の中で2次元の紙をくるくる巻いた形をしていて、「本当は2次元」なのに、ユークリッド距離で測ると巻きの内側と外側が近くに見えてしまいます。
graph LR
A["スイスロール<br/>3次元に巻かれた2次元の面"] -->|"線形PCA: 平面に潰す"| B["巻きが重なって<br/>近傍がぐちゃぐちゃ"]
A -->|"非線形次元削減: ほどく"| C["きれいな2次元<br/>近傍関係が保たれる"]
線形PCAでこれを2次元に落とすと、面を「巻いたまま真上から潰す」ことになり、本来遠い点(巻きの何周も先)と近い点(すぐ隣)が混ざります。ユークリッド距離という直線の物差しが、曲がった面の上では正しい近さを測れない——これが線形手法の限界の本質です。
要するに:PCAは「平らな構造」専用。曲がった構造をほどくには、直線以外の物差しが要ります。
2. 多様体仮説(manifold hypothesis)
非線形次元削減すべてに共通する前提が多様体仮説です。
高次元データは、見かけの次元(ピクセル数・特徴数)よりずっと低次元な多様体(manifold)の近傍に集中して乗っている。
多様体とは、ざっくり言えば「局所的には平らな(ユークリッド的な)、曲がった面・曲線」のこと。地球の表面(2次元の球面)が3次元空間に埋め込まれているのと同じイメージです。たとえば「同じ顔をいろんな角度・照明で撮った画像」は、ピクセル数としては数万次元でも、実質的に動かしているパラメータは「角度・照明」など数個。だからデータは数万次元空間の中の数次元の多様体に張り付いている、と考えます。
この仮説が効く理由は次元の呪いと表裏です。高次元空間はスカスカで何でもできそうに見えますが、意味のあるデータはごく薄い低次元の層にしか存在しない。だから「その層(多様体)の中での近さ」さえ復元できれば、低次元で十分に表現できる、というわけです。
非線形次元削減の手法はどれも「多様体に沿った近さ(測地距離・近傍グラフ・近傍確率)を保つように低次元へ落とす」という方針を共有しています。違いはその「近さ」をどう定義するかです。
3. カーネルPCA
着想:特徴空間でPCAをする
カーネルPCAの発想はシンプルです。「曲がった構造は、いったん高次元の特徴空間 に写してから見れば、平らに見えるかもしれない。ならそこで普通のPCAをやろう」。SVMで非線形分離をやったのとまったく同じ着想です(サポートベクターマシン(SVM))。
問題は、特徴空間が高次元(無限次元のこともある)なので を明示的に計算したくないこと。ここでカーネルトリックが効きます。
数理:グラム行列の固有値分解
特徴空間での共分散行列を固有値分解したいのですが、PCAの主成分は「データ点の線形結合」で書けることを使うと、計算を内積だけに落とせます。カーネル関数 を成分に持つ のグラム行列(カーネル行列) を作ると、解くべきは次の固有値問題になります:
ここで は の固有ベクトル、 はデータ数です。特徴空間での第 主成分 は という形で表され、新しい点 をこの成分へ射影した値は
と、やはりカーネル評価だけで計算できます。 は一度も出てきません。
要するに:カーネルPCAは「共分散行列ではなく のカーネル行列を固有値分解するPCA」です。 を計算せず、点と点のカーネル値だけで非線形な主成分が取り出せます。
中心化の扱い(一言)
普通のPCAはデータを平均0に中心化してから行います。カーネルPCAでも特徴空間で中心化する必要がありますが、 を直接触れないので、カーネル行列 の側で中心化します。中心化済みの行列 は
で得られます( は全要素が の 行列)。これも入力空間の量だけで計算できる点がカーネルトリックの恩恵です。この中心化を忘れると主成分がずれるので、実装上の定番の落とし穴です。
カーネルPCAの位置づけ
カーネルPCAは「成分(軸)を取り出せる」のが強みです。線形PCAの素直な非線形拡張なので、新しい点の射影(out-of-sample)も上の式で計算でき、前処理として下流のモデルに渡せます。一方で、カーネルとそのパラメータ(RBFカーネルの幅など)の選び方に結果が強く依存し、 行列を扱うのでデータが大きいと重い、という弱点があります。
4. t-SNE:近傍の確率を合わせる
着想
t-SNE(t-distributed Stochastic Neighbor Embedding) は、可視化(2〜3次元)に特化した手法です。発想は「点の座標そのものではなく、点どうしの近さの“確率”を、高次元と低次元で一致させよう」というもの。
高次元側:近傍を確率で表す
高次元では、点 から見て点 が「近傍である確率」を、 を中心としたガウシアンで定義します:
近いほど確率が高く、遠いほど指数的に小さくなります。これを左右対称にした同時確率 を使います(対称化することで孤立点の扱いが安定します)。
perplexity:実効的な近傍数
各点の幅 は唯一のハイパーパラメータ**perplexity(パープレキシティ)**から決まります。perplexity は確率分布 のシャノンエントロピー を使って
と定義され、直観的には「各点が実効的に何個の近傍を持つとみなすか」を表します。perplexity を決めると、各点でその値になるよう を二分探索で合わせます。典型値は 5〜50 です。
要するに:perplexity は「近傍を何個ぶん見るか」のつまみ。小さいと細かい局所、大きいと大域寄りになります。
crowding problem と t分布
低次元側の近さ には、ガウシアンではなく自由度1のスチューデントt分布を使います:
なぜt分布か。これが混雑問題(crowding problem)への対処です。高次元で「どれも適度に離れている」点を低次元(2次元)に詰め込むと、置き場所が足りずに全部が中心に潰れて団子になる——これが crowding です。t分布はガウシアンより裾が重いので、低次元で点を少し遠くに置いても確率が極端に小さくならない。結果、団子化を避けてクラスタが適度にほどけます。
学習:KLダイバージェンス最小化
あとは高次元の分布 と低次元の分布 を近づけるだけ。「分布間の近さ」の尺度としてKLダイバージェンスを使い、低次元座標 について最小化します:
KLは非対称で、「 が大きい(高次元で近い)のに が小さい(低次元で遠い)」ペアを強く罰します。つまり局所的な近さの保存を優先し、勾配降下で座標を動かして団子をほどいていきます。逆に「高次元で遠いのに低次元で近い」ことへのペナルティは弱いので、大域的な配置はあまり守られない——これが後述の誤読注意の根っこです。
5. UMAP:位相的な着想で速く
UMAP(Uniform Manifold Approximation and Projection) は、t-SNEと似た見た目の埋め込みを作りますが、位相幾何(topology)とグラフの理論に着想を得た手法です。
ざっくりした流れは、(1) 各点の周りに近傍を取ってファジィな近傍グラフ(fuzzy simplicial set)を組み、データ多様体の位相構造を近似する。(2) 低次元側でも同じグラフを組み、両者のクロスエントロピーを最小化して座標を最適化する。t-SNEの「近傍確率を合わせる」を、確率というよりグラフの辺の重みの一致として定式化したものと捉えると見通しが良いです。
実務上よく言われる UMAP の特徴(要最新確認:この領域は速く動くため、最新版の挙動・既定値は公式ドキュメントで確認してください):
- 速い:近傍探索を近似することで計算量がおおむね 程度に収まり、t-SNE の に比べて大規模データで圧倒的に速い、とされます。
- 大域構造をやや保ちやすいとよく言われます。ただしここは要注意で、「同じ初期化を使えば UMAP が t-SNE より大域構造を良く保つわけではない」という指摘もあります(=見えていた差の一部は初期化の違いによる、という主張)。UMAP だから大域距離が信頼できる、とは思わないでください。
- ハイパーパラメータは主に
n_neighbors(局所か大域か。t-SNE の perplexity に相当)とmin_dist(低次元で点をどれだけ詰めるか=クラスタの締まり具合)。
要するに:UMAP は「t-SNE を高速化し、グラフ理論で定式化し直した近縁手法」。速さは本物ですが、大域構造の優位性は条件つきで、過信は禁物です。
6. ⚠️ t-SNE / UMAP の誤読(最重要)
可視化結果は論文や報告で最も誤読される図のひとつです。以下は守ってください。
- クラスタの大きさに意味はない。t-SNE は密なクラスタを広げ、疎なクラスタを縮める性質があり、大きさを均す。「このクラスタは大きいから重要/ばらつきが大きい」とは読めません。
- クラスタ間の距離に意味はない(ことが多い)。よく離れた2つのクラスタの間隔は、高次元での実際の距離をほとんど反映しません。「Aクラスタは C より B に近い」と図から結論しないでください。
- ハイパーパラメータとシードに強く依存する。perplexity(や
n_neighbors)を変えると見た目が劇的に変わる。単一の perplexity を信じず、複数の値で見るのが鉄則です。乱数シードでも配置が変わるので、再現性のためにシードを固定します。 - ノイズがクラスタに見える。完全にランダムなデータでも、低 perplexity では「それらしい塊」が現れます。塊が見えた=構造がある、ではありません。
- 形が歪む。直線状の構造がわずかに外側へ反るなど、t-SNE は密な領域を拡大するため形が変形します。
- 距離保存ではない・可視化専用。t-SNE / UMAP の出力座標は「下流のモデルの入力特徴」として使うものではありません(距離の意味が保証されないため)。あくまで人間が眺めて当たりをつけるための絵です。
検証のコツ:見えたクラスタは、元の高次元空間で k-means や DBSCAN を回す・別手法(UMAP↔t-SNE)でも同じ塊が出るか確認する、など図の外で裏取りしてから主張しましょう。
7. 使い分けと他手法との関係
graph TD
PCA["線形PCA<br/>平らな構造・成分が解釈可能"] -->|"カーネルで非線形化"| KPCA["カーネルPCA<br/>成分を取り出せる / 射影可能"]
PCA -->|"距離を保つ線形埋め込み"| MDS["古典的MDS<br/>距離から座標 / 統計側"]
MANI["多様体仮説<br/>低次元の曲がった面に乗る"] --> KPCA
MANI --> TSNE["t-SNE<br/>近傍確率のKL最小化 / 可視化専用"]
MANI --> UMAP["UMAP<br/>位相グラフ / 高速 / 可視化専用"]
TSNE -.->|"距離・大きさは読まない"| WARN["⚠ 絵を読みすぎない"]
UMAP -.-> WARN
- 成分(軸)が欲しい・前処理に使いたい・新しい点を射影したい → カーネルPCA(あるいは線形PCA)。
- とにかく全体を眺めて当たりをつけたい(探索的可視化) → t-SNE / UMAP。大規模なら UMAP が速い。ただし出力は座標として使わない。
- 点間の距離そのものを保ったまま低次元に置きたい → 多次元尺度構成法(MDS)。「距離行列から座標を復元する」古典手法で、数理的土台は統計側にあります(多次元尺度構成法(MDS))。古典的MDS(計量MDS)は、実は中心化した距離行列の固有値分解で、線形PCAと数理的に双対の関係にあります。Isomap は「ユークリッド距離の代わりに多様体に沿った測地距離を使う MDS」と理解すると、ここまでの手法が一本の線でつながります。
まとめ
- 線形PCAは平らな構造専用。曲がった構造(スイスロール等)は多様体仮説に基づく非線形手法でほどく。
- カーネルPCA=特徴空間でのPCA=グラム行列の固有値分解。 を計算しないカーネルトリックが肝で、成分を取り出せて射影もできる。中心化はカーネル行列側で行う。
- t-SNE=高次元の近傍確率 と低次元の (自由度1のt分布でcrowding 対策)のKL最小化。perplexity は実効近傍数のつまみ。
- UMAP=位相グラフ+クロスエントロピーで t-SNE を高速化した近縁手法(要最新確認)。大域構造の優位は条件つき。
- t-SNE / UMAP は可視化専用。クラスタの大きさ・距離・形を読みすぎない。複数ハイパラ・固定シードで、図の外で裏取りする。
対応するシミュレーション
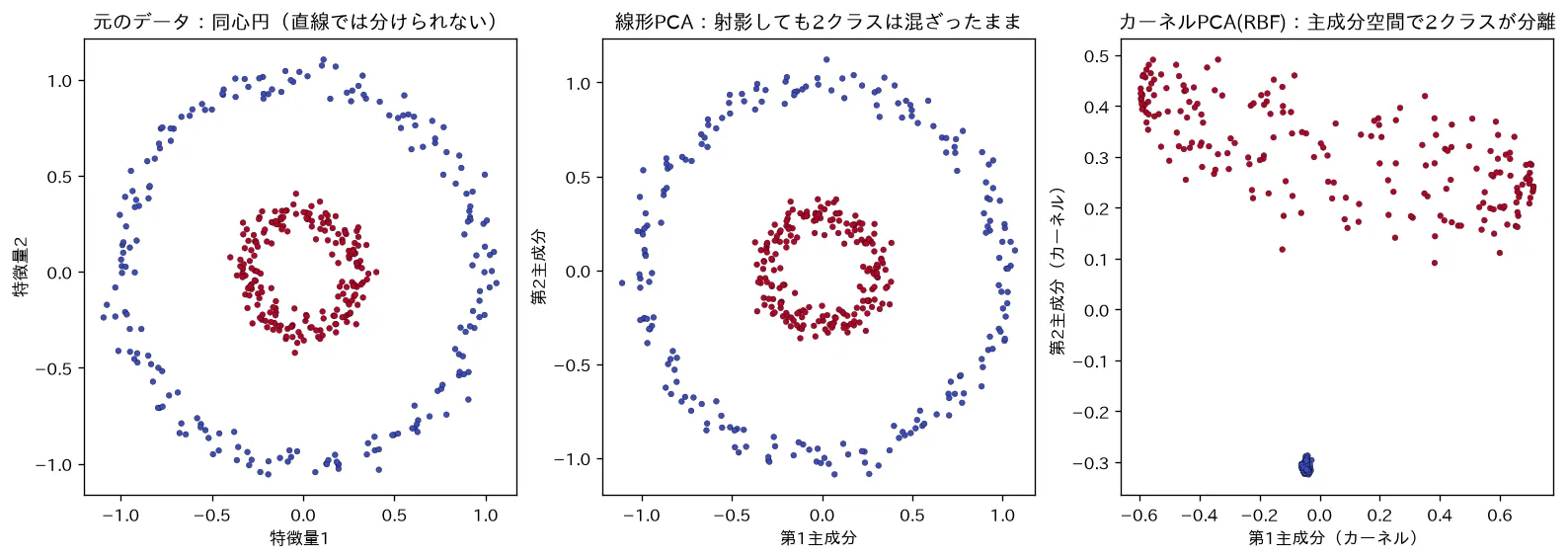
simulations/kernel_pca.py:同心円状(線形分離できない)データに線形PCAとカーネルPCA(RBF)をかけて比べます。線形PCAは射影しても内側・外側の円が混ざったままなのに対し、カーネルPCAは高次元へ写してから主成分をとるため、主成分空間で2クラスが直線で分けられる形に展開されることを可視化します。SVMのカーネル(サポートベクターマシン(SVM))と同じ発想です。
関連ノート
- 教師なし学習 目次
- 主成分分析と次元削減(線形の土台)
- サポートベクターマシン(SVM)(カーネルトリックの兄弟)
- 多次元尺度構成法(MDS)(統計・距離保存の埋め込み)
- 次元の呪い(多様体仮説の背景)
- 機械学習テキスト 全体目次