🎓 レベル:発展 | 重要度:A(必須)
📎 前提:ブースティングとAdaBoost | 土台:勾配降下法(→ 最適化と学習理論 目次)
要点(BLUF)
- 勾配ブースティングは、前向き段階的加法モデル(forward stagewise additive modeling)を「任意の微分可能な損失」へ一般化したものです。AdaBoost が指数損失に縛られていたのを、二乗誤差・対数損失・Huber 損失など何でも使えるようにしたのが本質です。
- 各ステップでやることはシンプルです。今のモデル に対する損失の「負の勾配」を擬似残差として計算し、それを近似する回帰木 を1本作り、学習率 を掛けて足す。これは「関数空間での勾配降下」そのものです。
- 二乗損失なら擬似残差は普通の残差 に一致します。だから「前の木の残差を次の木が順に学習する」と直観的に説明されます。AdaBoost は「指数損失を選んだときの特殊例」として、この枠組みにすっぽり収まります。
1. ブースティングの一般化:何が問題だったか
ブースティングとAdaBoost で見たように、ブースティングの基本思想は「弱学習器を順番に足し込み、前の誤りを次が補う」加法モデルです。最終予測は
という弱学習器 の重み付き和でした。問題は 「各ステップで と係数をどう決めるか」。AdaBoost はこれを 指数損失 に対する前向き段階的な最小化として解いていました(後述するように、これは数学的に確かめられた事実です)。
ですが指数損失は外れ値・ラベルノイズに弱いという欠点があります。外れた点の が大きくなると損失が指数的に爆発し、その点を補正しようと過剰に引っ張られるからです。
ここで Friedman(2001)が出した答えが「損失を固定せず、微分可能でありさえすれば何でもいい形に書き換えてしまえ」というものです。これが勾配ブースティングです。
graph LR
A["前向き段階的加法モデル<br/>(弱学習器を順に足す枠組み)"] --> B["指数損失で解く<br/>= AdaBoost"]
A --> C["任意の微分可能な損失で解く<br/>= 勾配ブースティング"]
C --> D["二乗誤差<br/>(回帰)"]
C --> E["対数損失<br/>(分類)"]
C --> F["Huber 損失<br/>(外れ値に頑健)"]
要するに:AdaBoost は「ブースティングの一例(指数損失版)」にすぎません。勾配ブースティングは損失の選択を自由にして、回帰・分類・頑健推定まで同じ仕組みで扱える「上位概念」です。
2. 前向き段階的加法モデル(FSAM)
まず土台となる 前向き段階的加法モデル を定式化します。加法モデル 全体を一気に最適化するのは難しいので、1ステップに1つの弱学習器だけを追加し、それを足したときの損失を最小化する、という貪欲な手続きを取ります。
ステップ では、すでに確定した は固定し、新しく足す と係数 だけを動かして
を解きます。そして と更新します。
要するに:「すでに置いた弱学習器には触らず、次の1個だけを最適に足す」。一度足したものを後から調整しない(=前向き/forward)のがポイントです。決定木の貪欲な再帰分割(決定木)と同じ「1手ずつ最善」の精神です。
ここで に指数損失を入れて解くと、ちょうど AdaBoost の重み更新式が出てきます(4-03 で扱った内容)。問題は、一般の ではこの が解析的に解けないことです。そこを勾配で突破します。
3. 関数空間の勾配降下(核心)
ここが勾配ブースティングの心臓部です。「関数 そのものをパラメータとみなして、損失を勾配降下で減らす」と考えます。
なぜ「関数の勾配」なのか
普通の勾配降下は、パラメータ に対して損失 を と更新します(→ 最適化と学習理論 目次)。勾配ブースティングは更新する対象を「パラメータ」ではなく「予測関数 」にします。
訓練データ上での総損失を、各点での予測値 の関数とみなします:
各点の予測値 をひとつの「座標」だと思うと、 を最も速く減らす方向(最急降下方向)は、各座標に関する偏微分にマイナスを付けたものです。これを点 ごとに計算したのが 擬似残差(pseudo-residual) です:
要するに: は「点 の予測値を、損失を減らすにはどっちへどれだけ動かせばいいか」を表す矢印です。 個の点それぞれに矢印が立っていて、これが関数空間での「負の勾配ベクトル」になります。
擬似残差を回帰木で近似する
ただし は訓練点の上でしか定義されていません。未知の に対しては値がない。そこで、この負の勾配ベクトル に一番近い回帰木 を最小二乗でフィットします:
これが「擬似残差を回帰木で近似する」の正体です。回帰木が負の勾配方向を汎化可能な形に補間してくれるので、未知の点にも降下方向を与えられます。
flowchart TB
Start["現在のモデル F_{m-1}"] --> Grad["各点で擬似残差を計算<br/>r_im = - dL/dF(負の勾配)"]
Grad --> Fit["擬似残差を目的変数にして<br/>回帰木 h_m を最小二乗フィット"]
Fit --> Leaf["各葉ごとに最適値を line search<br/>gamma_jm を決める"]
Leaf --> Update["学習率を掛けて足し込む<br/>F_m = F_{m-1} + nu * h_m"]
Update --> Check{"m が M に達した ?"}
Check -->|"No"| Start
Check -->|"Yes"| Done["最終モデル F_M を出力"]
要するに:勾配ブースティングの1反復は「負の勾配を求める → それを回帰木でなぞる → 少しだけ足す」。普通の勾配降下が「勾配を求めて少し動く」のと完全に対応していて、ただ動く対象が関数になっているだけです。
4. 葉ごとの最適値(line search)
回帰木 で**降下の「向き」**は決まりましたが、**どれだけ進むか(歩幅)**はまだです。Friedman の TreeBoost では、ここで木の構造を賢く使います。
回帰木は特徴空間を 個の互いに重ならない葉領域 に分けます。そこで「木が選んだ分割(葉の領域)はそのまま使い、各葉に入れる定数値 だけを、実際の損失 が最小になるように選び直す」ことをします。葉 について
これは葉ごとに独立な1次元の最小化問題(=line search)です。最終的な更新は、各葉領域に最適値 を置いた木を足し込みます:
要するに:木の「形(どこで切るか)」は擬似残差への最小二乗で決め、木の「高さ(葉に入れる値)」は本物の損失 で決め直す、という二段構えです。向きを勾配で決め、歩幅を line search で決める—まさに勾配降下の作法です。
なぜ2段階に分けるのか:擬似残差は「損失の1次近似(線形化)」でしかないので、最小二乗フィットだけだと近似誤差が残ります。葉の値を本物の で取り直すことで、その葉に関する限り損失を厳密に最小化でき、1反復あたりの改善が大きくなります。
二乗損失の場合:擬似残差=普通の残差
二乗損失 で擬似残差を計算してみます。 で微分すると
要するに:二乗損失では擬似残差がそのまま 普通の残差 になります。だから「前の木が外した分(残差)を、次の木が学習して埋める」という直観的な説明が成り立つわけです。さらにこのとき葉の line search の答えも、その葉に落ちた残差の単純平均になります(回帰木の葉が平均を返すのと同じ)。一般の損失では擬似残差は「残差そのもの」ではなく「損失を減らす方向の値」になりますが、二乗損失という特別な場合に限って両者が一致する、と理解するのが正確です。
代表的な損失と擬似残差の対応:
| 損失 | タスク | 擬似残差 | コメント |
|---|---|---|---|
| 二乗誤差 | 回帰 | 普通の残差そのもの | |
| 絶対誤差 | 回帰 | 符号だけ。外れ値に頑健 | |
| Huber 損失 | 回帰 | 中心は残差・外側は符号 | 二乗と絶対の折衷 |
| 対数損失(二項逸脱度) | 分類 | ( は予測確率) | ロジスティック回帰と同じ形 |
| 指数損失 | 分類 | これを使うと AdaBoost |
5. アルゴリズム全体
これまでの部品を1つの手続きにまとめます(Friedman のグラディエント・ツリーブースティング)。
flowchart TB
Init["F_0 = argmin_c Σ L(y_i, c)<br/>定数で初期化"] --> Loop["m = 1 ... M を繰り返す"]
Loop --> S1["(1)擬似残差<br/>r_im = - dL/dF を全点で計算"]
S1 --> S2["(2)r_im に回帰木 h_m を最小二乗フィット<br/>葉領域 R_jm が決まる"]
S2 --> S3["(3)各葉で line search<br/>gamma_jm = argmin_γ Σ L"]
S3 --> S4["(4)更新<br/>F_m = F_{m-1} + nu * Σ gamma_jm * 1[x ∈ R_jm]"]
S4 --> Loop
Loop --> Out["最終モデル F_M"]
ステップを言葉で追うと:
- 初期化:。損失を最小にする定数から始めます(二乗損失なら の平均、対数損失なら対数オッズ)。
- 各 について 擬似残差 を全訓練点で計算。
- 擬似残差を目的変数として 回帰木 を最小二乗フィット(→ 葉領域 が決まる)。
- 各葉で line search して最適値 を求める。
- 学習率 を掛けて足し込む:。
- まで繰り返し、 を最終モデルとする。
要するに:「定数から始めて、残差(負の勾配)を回帰木で順に削る」を 回。分類でも回帰でも使うのは回帰木である点に注意してください(分類でも擬似残差は連続値なので、フィットするのは常に回帰木です)。
6. 正則化:暴走させない3つのつまみ
勾配ブースティングは「訓練損失を順々に削る」仕組みなので、放っておくと訓練データに過剰適合します。これを抑える主要なつまみが3つあります。
(1) 学習率(shrinkage) と木の本数
更新を と、 でわざと縮めて足します。 を小さくすると1本あたりの寄与が小さくなり、過学習しにくくなりますが、同じ訓練損失に到達するのに必要な木の本数 は増えます。
xychart-beta
title "学習率と必要な木の本数のトレードオフ(概念図)"
x-axis "木の本数 M" [100, 500, 1000, 2000, 4000]
y-axis "検証損失" 0 --> 10
line "学習率 大(nu=0.3)" [6, 4, 4.5, 6, 8]
line "学習率 小(nu=0.03)" [9, 5, 3, 2.5, 2.8]
要するに: と は逆向きの関係です。実務では「小さめの (0.01〜0.1 程度)にして、 を大きめに取り、early stopping で止める」のが定石です。経験的には、小さい学習率でゆっくり進むほど汎化が良くなる傾向があります。 は「各ステップで勾配方向にどれだけ進むか」の歩幅そのものなので、これを縮めるのは勾配降下の学習率を下げるのと同じ意味です。
(2) Early stopping(早期終了)
を固定せず、検証データの損失が改善しなくなった時点で打ち切るのが early stopping です。木を足すほど訓練損失は下がり続けますが、ある点を超えると検証損失は上昇に転じます(過学習の始まり)。その直前で止めます。
要するに:「最適な木の本数 」をハイパーパラメータとして探索する代わりに、検証損失をモニタしながら自動で決める方法です。 を小さく取って を大きめに用意し、early stopping に止めどころを任せる、という組み合わせがよく使われます。
(3) 確率的勾配ブースティング(subsample)と木の複雑さ
Friedman は、各反復で訓練データの一部(例:50%)を非復元抽出してサブサンプルし、その上で擬似残差のフィットと line search を行う改良を提案しました。これが 確率的勾配ブースティング(stochastic gradient boosting) です。バギング(バギングとランダムフォレスト)の「行サンプリング」をブースティングに持ち込んだものと言えます。
サブサンプリングには2つの効果があります:
- 正則化:毎回違うデータで木を作るので、特定の点への過剰適合が緩み、汎化が改善します。
- 計算の高速化:1反復あたりに使うデータが減るので速くなります。
加えて、木の深さ(葉の数 ) も重要な正則化のつまみです。勾配ブースティングでは**浅い木(深さ1〜6程度、しばしば「切り株」に近いもの)**を使うのが基本です。
- 深さ (切り株):各特徴の主効果だけを捉える加法モデルに相当。
- 深さ :特徴間の相互作用を表現できる(深さ で 次までの交互作用)。
graph TB
Reg["勾配ブースティングの正則化"]
Reg --> R1["学習率 nu を小さく<br/>(+ 本数 M を増やす)"]
Reg --> R2["early stopping<br/>(検証損失で打ち切り)"]
Reg --> R3["subsample < 1.0<br/>(確率的勾配ブースティング)"]
Reg --> R4["木の深さ・葉数を制限<br/>(弱学習器を浅く保つ)"]
要するに:勾配ブースティングは「弱い木をたくさん」が鉄則です。1本1本を弱く(浅く)保ち、学習率で寄与を縮め、サブサンプルでばらつきを入れ、early stopping で止める—これらを組み合わせて過学習を抑えます。
7. AdaBoost との統一的理解(必ず押さえる)
ここまで来ると、ブースティングとAdaBoost と勾配ブースティングの関係がはっきりします。
AdaBoost は「指数損失 を選んだときの勾配ブースティングの特殊例」です。
これは歴史的には後から発見された事実です。AdaBoost(1995)はもともと「誤分類した点の重みを増やす」という重み更新の手続きとして提案されましたが、後年「指数損失に対する前向き段階的加法モデル」として再解釈できることが示されました(Friedman, Hastie, Tibshirani 2000)。そして Friedman(2001)が「ならば損失を指数損失に限る必要はない」と一般化したのが勾配ブースティングです。
指数損失で擬似残差を計算すると
となり、この がまさに AdaBoost の標本重み に対応します。誤って分類されている( の)点ほど重みが大きくなり、次の弱学習器がそこを重点的に学習する—これが AdaBoost の「誤った点の重みを増やす」操作の正体だったわけです。
graph TB
GB["勾配ブースティング<br/>(任意の微分可能な損失)"]
GB -->|"指数損失 e^(-yF)"| Ada["AdaBoost"]
GB -->|"対数損失"| LogB["ロジスティック・ブースティング<br/>(LogitBoost 系)"]
GB -->|"二乗損失"| L2["L2 ブースティング<br/>(残差を順に学習)"]
Ada -.->|"擬似残差 = 標本重み<br/>y * e^(-yF)"| Note["重み更新は<br/>勾配の特殊な姿"]
要するに:AdaBoost の「重み付け」と勾配ブースティングの「擬似残差」は別物ではなく同じものです。指数損失という特定の損失を選ぶと、勾配(擬似残差)がちょうど標本重みの形になる—それが AdaBoost だった、という統一的な見方ができます。この視点に立つと、損失を対数損失や二乗損失に差し替えるだけで分類・回帰・頑健推定へ自在に展開できることが腑に落ちます。
8. バギング(ランダムフォレスト)との対比
同じ「木のアンサンブル」でも、勾配ブースティングとランダムフォレスト(バギングとランダムフォレスト)は狙いが正反対です。
| 観点 | ランダムフォレスト(バギング) | 勾配ブースティング |
|---|---|---|
| 木の作り方 | 並列・独立に多数育てる | 逐次・前の誤りを次が補う |
| 木の深さ | 深い木(低バイアス・高バリアンス) | 浅い木(高バイアス・低バリアンス) |
| 主に下げるもの | バリアンス(平均化で安定化) | バイアス(残差を順に削る) |
| 過学習 | 木を増やしても基本的に悪化しにくい | 木を増やしすぎると過学習する(要 early stopping) |
| 並列化 | しやすい | 木は逐次依存(ただし1本内の分割探索は並列化可) |
要するに:ランダムフォレストは「深い木を平均してバリアンスを潰す」、勾配ブースティングは「浅い木を積み上げてバイアスを潰す」。前者は木を増やしても安全ですが、後者は増やしすぎると過学習するので止めどころ(early stopping)が要ります。一般に、丁寧にチューニングした勾配ブースティングは表形式データでランダムフォレストを上回る精度を出すことが多い反面、ハイパーパラメータに敏感です。
⚠️ よくある誤解
- 「勾配ブースティングは残差を学習する」だけだと不正確。それが厳密に成り立つのは二乗損失のときだけです。一般には「損失の負の勾配(擬似残差)」を学習しており、残差はその特殊例にすぎません。対数損失や絶対誤差では擬似残差は残差と一致しません。
- 「分類だから分類木を足す」ではない。勾配ブースティングは分類でも回帰木をフィットします。擬似残差は連続値なので、近似する弱学習器は常に回帰木です。
- 「学習率は小さいほど常に良い」わけではない。 を小さくするほど必要な木の本数 が増え、計算コストが膨らみます。 と はトレードオフで、early stopping と組み合わせて決めます。
- 「木を増やせば増やすほど精度が上がる」ではない。ランダムフォレストと違い、勾配ブースティングは木を増やしすぎると過学習します。検証損失が上がり始めたら止めるのが鉄則です。
- 「AdaBoost と勾配ブースティングは別系統の手法」ではない。AdaBoost は勾配ブースティングの**指数損失版(特殊例)**です。重み更新は擬似残差の別の姿で、根は同じ前向き段階的加法モデルです。
- 「擬似残差を回帰木に完璧にフィットさせるべき」ではない。擬似残差は損失の1次近似でしかないので、フィットは近似で十分です。むしろ葉の値を本物の損失で line search し直すこと、弱学習器を浅く保つことの方が重要です。
対応するシミュレーション
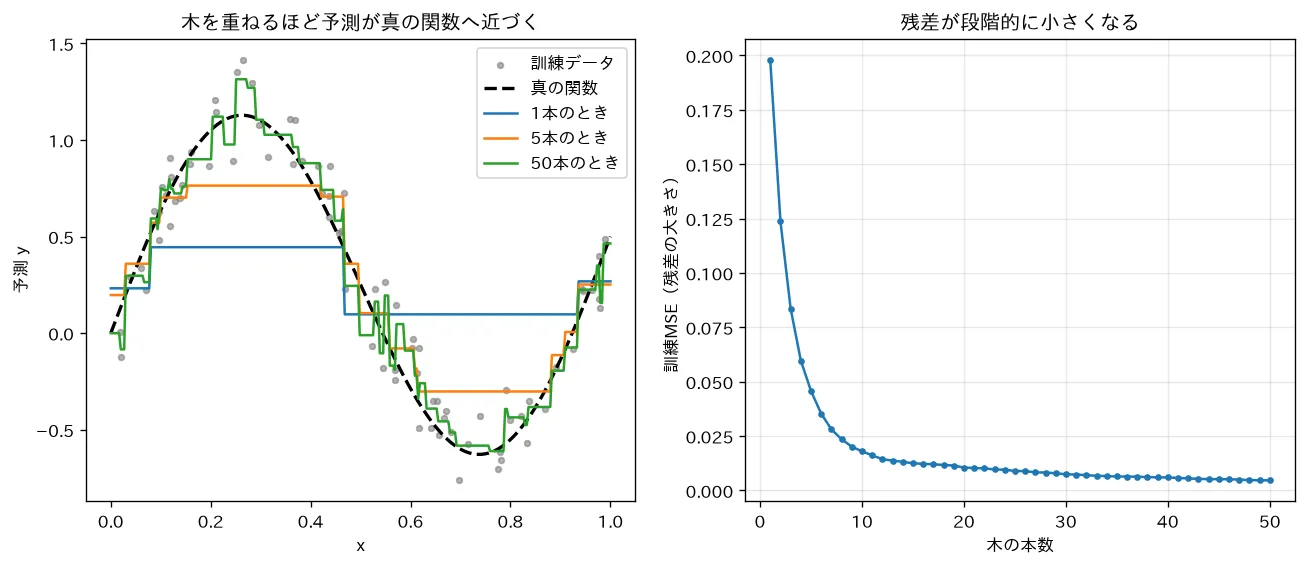
simulations/gradient_boosting_residuals.py:勾配ブースティング(二乗誤差)を自前実装し、いまの予測の残差に小さな木を当てはめて少しずつ足す様子を可視化します。木1本ではざっくりした階段でも、本数を重ねると残差が小さくなり予測が真の関数へ近づくこと(訓練MSE 0.20→0.005)を示します。二乗誤差では残差が損失の負の勾配=関数空間の勾配降下です。バギング(バギングとランダムフォレスト)が並列に分散を下げるのと対照的に、ブースティングは逐次にバイアスを下げます。
関連ノート
- アンサンブル学習 目次
- ブースティングとAdaBoost(指数損失版の特殊例。本ノートの直接の前提)
- XGBoostとLightGBM(勾配ブースティングを2次近似・正則化・高速化で実装したもの)
- バギングとランダムフォレスト(並列・バリアンス削減との対比)
- 決定木(弱学習器としての回帰木)
- 最適化と学習理論 目次(勾配降下法という土台)
- 機械学習テキスト 全体目次