🎓 レベル:標準 | 重要度:B(標準)
📎 前提:勾配ブースティング
要点(BLUF)
- XGBoost も LightGBM も、中身は 勾配ブースティング そのものです。「浅い木を順に足して前の木の誤りを補正する」という骨格は同じで、両者はそれを高速化・正則化・実装上の工夫で磨き上げたものだと捉えてください。
- XGBoost の核は2点。(1) 損失を2次のテイラー近似(勾配 ・ヘシアン )で評価し、葉の重みの最適値と分割の利得を閉じた式で求める。(2) 木の複雑さ(葉の数・葉重みのL2)を目的関数に明示的に足す=構造リスク最小化を内蔵する。
- LightGBM の核は速さ。連続特徴をヒストグラム(ビン)に離散化して分割探索を軽くし、leaf-wise(最も得する葉から伸ばす)成長で同じ精度に少ない木で到達します。さらに GOSS・EFB でサンプルと特徴を間引きます。
- ⚠️ 実装の既定値・APIは頻繁に変わります。本ノートは廃れにくい原理に絞ります。学習率・木の本数・正則化の既定値や引数名は必ず最新の公式ドキュメントで確認してください(要最新確認)。
0. 位置づけ:勾配ブースティングの「実務標準」
まず全体像です。決定木(決定木)を束ねるアンサンブルには2つの大きな流派があります。木を並列に作って平均するバギング系(バギングとランダムフォレスト)と、木を逐次に作って誤りを補正するブースティング系(勾配ブースティング)。XGBoost と LightGBM はどちらも後者、勾配ブースティング(GBDT)の高性能な実装です。
graph TB
GBDT["勾配ブースティング GBDT"]
GBDT --> XGB["XGBoost:2次近似+明示的正則化"]
GBDT --> LGB["LightGBM:ヒストグラム+leaf-wise"]
GBDT --> CAT["CatBoost:順序付きブースティング"]
XGB --> Note1["原理は同じ。違いは速度・正則化・実装の工夫"]
LGB --> Note1
CAT --> Note1
要するに:これらは別物の新アルゴリズムではなく、「同じ勾配ブースティングを、現実のデータと計算資源で速く・過学習しにくく回すための実装」です。だから両者を理解する近道は、まず 勾配ブースティング の「残差(より正確には負の勾配)に木を当てて足す」流れを思い出すことです。
そして実務的な結論を先に言うと、表形式(テーブル)データでは、いまだに RF と GBDT 系(XGBoost / LightGBM / CatBoost)が定番です。画像や言語は深層学習が圧倒しますが、行と列でできた構造化データに対しては、これらの勾配ブースティング実装が手早く高精度を出すことが多く、Kaggle などの表データコンペでも頻出します。
1. XGBoost:2次のテイラー近似
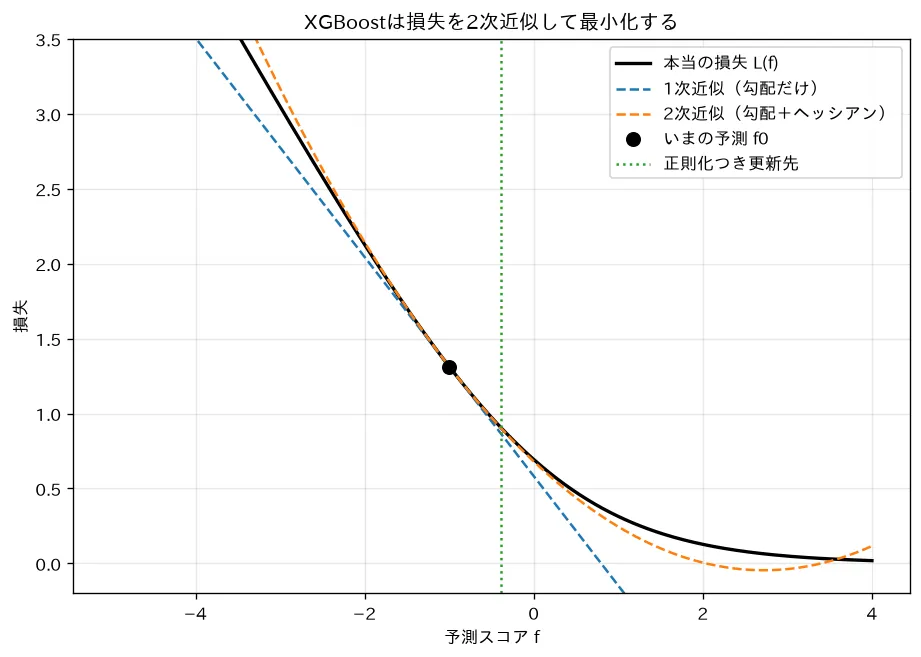
勾配ブースティングは「現在のモデル に、新しい木 を1本足して損失を下げる」ことを繰り返します。 本目を足すときに最小化したい目的関数は、 個のサンプルについて
です。 は損失(二乗誤差や対数損失)、 は前ステップまでの予測、 は木の複雑さへの罰則(次節)。素の勾配ブースティングは の1次の勾配だけを使って木を当てますが、XGBoost はここで2次までテイラー展開します。 を小さな増分とみなして のまわりで展開すると
ここで と は、損失を「前ステップの予測値」で微分した1次・2次の係数です:
は勾配(残差の向き)、 はヘシアン(損失の曲がり具合=そのサンプルをどれだけ自信を持って動かせるか) です。先頭の は に依存しない定数なので、最適化では落とせます。
要するに:素のブースティングは坂の「傾き」だけ見て進みますが、XGBoost は「傾き 」に加えて「曲がり具合 」も見ます。曲率がわかると、ニュートン法のように一発で最適な踏み込み幅が決まる——これが次の閉じた式に効いてきます。
graph LR
L["損失 ℓ"] --> G["1次:勾配 g_i(残差の向き)"]
L --> H["2次:ヘシアン h_i(曲率)"]
G --> Opt["葉重みの最適値と分割利得を"]
H --> Opt
Opt --> Closed["閉じた式で計算(探索が速い・正確)"]
2. 葉重みの最適値と分割利得(閉じた式)
ここが XGBoost の一番おいしい部分です。木 は「サンプルを 個の葉に振り分け、葉 に落ちたら一定値 を返す」関数です。葉ごとにサンプルをまとめ、その葉に入るサンプルの勾配・ヘシアンを合計して 、 と置きます。さらに複雑さの罰則を (次節で説明)とすると、目的関数は葉ごとの和に整理できて
これは各 について下に凸な2次関数です。 で微分してゼロと置けば、葉 の最適な重みが一発で求まります:
要するに:葉の予測値は「勾配の合計をヘシアンの合計(+正則化 )で割って符号を反転したもの」。残差を で正規化した加重平均のような量で、 は分母を膨らませて重みを0方向へ縮める安全装置です。これを目的関数に代入し戻すと、その木構造での最小損失が
になります。 が小さい(負に大きい)ほど良い木構造です。これを木構造のスコア(質の点数) と呼びます。
ここから分割の利得(Gain) が自然に出ます。あるノードを左 ・右 に分けるかどうかは、「分けた後のスコアが分ける前よりどれだけ良くなるか」で決めます。スコアの差を取ると
第1項が左の子のスコア、第2項が右の子、第3項が分ける前(親)のスコア。これがこの分割で損失をどれだけ減らせるかで、決定木の情報利得(決定木)に当たる量です。XGBoost は全特徴・全しきい値の候補について Gain を計算し、最大の分割を選びます。
要するに:XGBoost は不純度(ジニ・エントロピー)ではなく、損失の2次近似から導いた ベースの利得で分割を選ぶ。損失そのものを直接最小化する分割を、閉じた式で評価できるのが強みです。
剪定は利得の閾値で行う
Gain の式の末尾 が効きます。Gain がマイナス(つまり利得が を下回る)なら、その分割はしない。 は「葉を1枚増やすために最低限必要な利得」で、 を上げるほど枝が増えにくくなります。これは決定木のコスト複雑度剪定(決定木 の )と同じ発想を、利得の閾値という形で組み込んだものです。
3. 正則化=構造リスク最小化を目的関数に内蔵
XGBoost の名前 “eXtreme” の中身の半分はこの明示的な正則化です。素の勾配ブースティングは「損失を下げる」ことしか目的関数に書いていませんが、XGBoost は木の複雑さへの罰則 を目的関数そのものに足します:
- :葉の数 への罰金。葉が増える(木が複雑になる)ほどコストが上がる。前節の Gain の がこれに対応し、利得の小さい分割を止めます。
- :葉重みのL2正則化。重み が大きくなりすぎないよう縮める。 の分母に が入っていたのは、まさにこの罰則の効果です。
graph TB
Obj["XGBoost の目的関数"]
Obj --> Loss["損失項 Σ ℓ(経験リスク:データへの当てはまり)"]
Obj --> Reg["正則化項 Ω(複雑さへの罰則)"]
Reg --> R1["γT:葉の数を抑える"]
Reg --> R2["½λ Σ w_j^2:葉重みのL2"]
Loss --> SRM["構造リスク最小化"]
Reg --> SRM
SRM --> Goal["当てはまりと単純さのバランスを最適化"]
要するに:「損失(当てはまり)」と「複雑さの罰則」を同じ式の中で同時に最小化する。これは統計学習でいう構造リスク最小化(経験リスク+複雑さペナルティ)そのもので、線形モデルのリッジ回帰がやっていることを木のアンサンブルに持ち込んだ形です。素の勾配ブースティングが「学習率を下げて木を浅くする」といった外付けの工夫で過学習を抑えるのに対し、XGBoost は罰則を目的関数に内蔵しているのが思想的な違いです。
4. XGBoost のその他の実装上の工夫
数理の核は1〜3節で尽きています。残りは「現実のデータと計算資源で速く回す」ための工夫で、原理だけ押さえます。
| 工夫 | 何をするか | 狙い |
|---|---|---|
| 近似分割探索(approximate) | 連続特徴を分位点(ヘシアン重みつき)で区切った候補だけで分割を探す | 全しきい値を試さず高速化・分散化 |
| sparsity-aware(既定方向) | 欠損や0が多い特徴で、欠損サンプルを左右どちらへ送るか(既定方向)をデータから学習 | 欠損値を補完せず扱える・スパースに強い |
| 列サブサンプリング(colsample) | 木やノードごとに特徴の一部だけ使う | 過学習抑制+計算削減(RF由来) |
| 縮小(shrinkage / eta) | 新しい木の寄与を学習率 で縮めて足す | 各木の影響を弱め、後の木に余地を残す |
少しだけ補足します。
近似分割探索:厳密法は1特徴のすべての値をしきい値候補にしますが、データが巨大だと重い。そこで特徴値をヘシアン で重み付けした分位点で数十個のビンに区切り、その境界だけを候補にします。なぜヘシアンで重み付けするかというと、2次近似の目的関数で各サンプルの「重み」が だからです( の項)。
sparsity-aware(既定方向の学習):欠損値を平均で埋めたりせず、各ノードに「欠損したサンプルはこっちへ行く」という既定方向(default direction)を持たせ、その向きを利得が最大になるように学習します。欠損・0・one-hot後のスパースな列を、補完なしでそのまま扱えるのが利点です。
要するに:XGBoost の数理的な肝は「2次近似+明示的正則化」で、それ以外(近似探索・既定方向・列サンプリング・縮小)は速度と頑健さのための上乗せです。
5. LightGBM:速さに全振りした GBDT
LightGBM も勾配ブースティングですが、設計思想は「大規模データで速く・省メモリに」。違いは主に分割探索の方法と木の伸ばし方、そしてサンプル・特徴の間引きの3点です。
ヒストグラムベース分割
XGBoost の近似法と同じ発想をさらに徹底します。学習の最初に、各連続特徴を固定数のビン(例:255個)に離散化してしまいます。あとは分割探索のたびに、サンプルを「どのビンに入るか」で振り分け、ビンごとの勾配・ヘシアンの合計を集計(ヒストグラムを作る)して、ビン境界だけを分割候補にします。
flowchart LR
A["連続特徴の値"] --> B["最初に固定数のビンへ離散化"]
B --> C["分割探索のたびにビン単位で g,h を集計"]
C --> D["ビン境界だけを分割候補に"]
D --> E["候補が少ない → 探索が高速・省メモリ"]
要するに:候補をビン境界に限ることで、しきい値を試す回数が一気に減ります(特徴値の個数ではなくビン数で決まる)。さらに「親のヒストグラムから片方の子を引けばもう片方が出る(histogram subtraction)」ので、子の集計コストも半減します。連続値をビンに丸める分の精度低下はごくわずかで、速度メリットが圧倒的です。
leaf-wise(best-first)成長 vs level-wise
木の伸ばし方が XGBoost(既定は level-wise 寄り)と LightGBM(leaf-wise)で違います。
graph TB
subgraph LW["level-wise(深さ優先で全葉を展開)"]
direction TB
A1["同じ深さの葉を全部分割してから次の階へ"]
A2["木が左右対称・バランス型に育つ"]
end
subgraph BF["leaf-wise / best-first(LightGBM)"]
direction TB
B1["今いる葉の中で利得が最大の1枚だけ分割"]
B2["得する所だけ深く伸びる → 非対称な木"]
end
- level-wise:建物を1フロアずつ完成させるイメージ。同じ深さの葉をすべて分割してから次の深さへ進むので、バランスの取れた木になります。
- leaf-wise(best-first):いま存在する葉のうち、分割したときの利得が一番大きい1枚だけを選んで伸ばします。全体の損失を一番減らす方向へ貪欲に進むので、同じ葉数なら level-wise より損失を速く下げられることが多いです。
要するに:leaf-wise は「一番得する所だけ深掘りする」ので効率は良いが、特定の枝だけ深く育って過学習しやすい。だから LightGBM では num_leaves(葉の最大数)や max_depth で深さ・葉数を縛るのが定石です。XGBoost のバランス型より速く強くなりやすい一方、暴れやすさを抑える正則化がより重要になります。
GOSS と EFB(間引きの工夫)
LightGBM 論文の名前 “Light”(軽い)を支える2つの間引きです。狙いだけ押さえます。
- GOSS(Gradient-based One-Side Sampling):勾配 が小さいサンプルは「すでによく学習できている」ので、勾配の大きいサンプルは全部残し、小さいサンプルは一部だけランダムに残す(残した分は重みで補正)。情報量の多いサンプルに計算を集中させてサンプル数を減らす狙いです。
- EFB(Exclusive Feature Bundling):one-hotエンコード後の列のように、同時に非ゼロになることがほぼない(排他的な)特徴を1本の列に束ねる。意味的に衝突しないので情報をほぼ落とさず、特徴数(=ヒストグラム作成コスト)を減らす狙いです。
要するに:GOSS は「行(サンプル)を賢く間引く」、EFB は「列(特徴)を賢く束ねる」。どちらも情報をなるべく保ったまま計算量を落とす工夫で、これがヒストグラム分割と組み合わさって大規模データでの速さを生みます。
6. CatBoost:順序付きブースティングでリークを断つ
3つ目の主要実装が CatBoost です。こちらの売りはカテゴリ特徴の扱いと、ターゲットリーク(prediction shift)の回避。要点だけ。
カテゴリ変数を「そのカテゴリの目標値の平均」で数値化するターゲットエンコーディングは強力ですが、自分の正解ラベルを使って自分の特徴を作ってしまうため、訓練データに過剰適合します(リーク)。同じことが勾配ブースティングの残差計算でも起き、訓練時の残差が「そのサンプル自身を含むモデル」から計算されるとバイアス(prediction shift)が乗ります。
CatBoost はこれを順序付きブースティング(ordered boosting) で断ちます。データに人工的な順序(ランダムな並べ替え)を入れ、各サンプルの統計量や残差を自分より前のサンプルだけから計算する。
要するに:「未来(自分の正解)を使わずに、過去だけで特徴と残差を作る」。時系列の予測でうっかり未来を覗かないのと同じ発想を全データに課し、リークによる楽観バイアスを取り除く——これが CatBoost の中心思想です。カテゴリの多いデータで真価を発揮します。
7. 表データの2大巨頭:RF vs GBDT 系
最後に実務的な対比です。表形式データで最初に試すべきは、ほぼ常にランダムフォレスト(バギングとランダムフォレスト)か GBDT 系のどちらかです。
| 観点 | ランダムフォレスト(バギング) | XGBoost / LightGBM(ブースティング) |
|---|---|---|
| 木の作り方 | 並列・独立(脱相関させて平均) | 逐次・依存(前の木の誤りを補正) |
| 主に下げる誤差 | バリアンス(汎化と過学習・バイアスバリアンス分解) | バイアス |
| 木の深さ | 深い木(低バイアス・高バリアンスを平均で抑える) | 浅い木を多数 |
| 過学習 | しにくい(木を増やしても安定) | しやすい(木を増やすと過学習。早期終了・正則化が要る) |
| チューニング | 軽い(既定でそこそこ強い) | 重い(学習率・木数・深さ・正則化の調整で伸びる) |
| 典型的な到達精度 | 安定して良い | 上限はこちらが高いことが多い |
要するに:まず手早く頑健な基準を作るなら RF、チューニングを厭わず最高精度を狙うなら GBDT 系。どちらも決定木(決定木)という同じ部品を、平均で安定させるか・逐次で補正するかの違いで、表データでは依然としてこの2系統が王道です。
⚠️ よくある誤解
- 「XGBoost / LightGBM は勾配ブースティングとは別物の新手法」ではない。骨格は 勾配ブースティング そのもの。違いは2次近似・明示的正則化・ヒストグラム分割・leaf-wise といった実装上の工夫であって、原理は共通です。
- 「2次のテイラー近似だから常に高精度」ではない。曲率 を使うと分割評価が正確で収束が速くなりますが、最終精度は正則化・学習率・木数のチューニング次第。近似の次数が高いこと自体が精度を保証するわけではありません。
- 「LightGBM は速いから常に優れている」わけではない。leaf-wise は過学習しやすく、データが小さいと XGBoost や RF の方が安定することもあります。速さ=精度ではありません。
- 「ヒストグラム分割で精度が大きく落ちる」わけではない。連続値をビンに丸めますが、ビンを十分に取れば精度低下はごくわずかで、速度メリットの方が大きいのが普通です(XGBoost も近似法・ヒストグラム法を備えています)。
- 「正則化の既定値や引数名を覚えれば足りる」ではない。・・学習率・木数・
num_leavesなどの既定値やAPIはバージョンで変わります。本ノートの式(原理)は変わりませんが、具体値は必ず最新の公式ドキュメントで確認してください(要最新確認)。 - 「欠損値は前処理で埋めないと使えない」ではない。XGBoost の sparsity-aware は欠損を補完せず、既定方向をデータから学習して扱えます。むやみな平均補完が逆効果になることもあります。
対応するシミュレーション
simulations/xgboost_taylor.py:XGBoost が損失をいまの予測の周りで2次のテイラー展開して近似し、その2次関数を最小化する様子を可視化します。1次近似(勾配だけ)より2次近似(勾配+ヘッシアン)が本当の損失にぴったり寄り添うこと、葉の最適値 が正則化 で縮むこと(明示的正則化)を示します。LightGBM のヒストグラム分割・leaf-wise にも触れます(土台は 勾配ブースティング)。
関連ノート
- アンサンブル学習 目次
- 勾配ブースティング(XGBoost / LightGBM の原理的な土台)
- バギングとランダムフォレスト(表データの2大巨頭の対比:並列の平均 vs 逐次の補正)
- 決定木(共通の部品。分割利得・剪定の発想)
- 汎化と過学習・バイアスバリアンス分解(正則化と過学習の意味)
- 機械学習テキスト 全体目次