🎓 レベル:標準 | 重要度:A(必須)
要点(BLUF)
- ブースティングは「弱い学習器を1つずつ順番に足していき、前の学習器が間違えたサンプルに次の学習器を集中させる」アンサンブルです。木をたくさん独立に育てて平均するバギングとランダムフォレスト(並列・バリアンスを下げる)とは正反対の発想で、ブースティングは主にバイアスを下げます。
- 代表が AdaBoost。各ラウンドで重み付き誤り率 を計算し、その弱学習器の発言権 を決め、誤分類したサンプルの重みを増やして次に渡します。最終予測は という重み付き多数決です。
- AdaBoost の正体は「加法モデル+指数損失 の前向き段階的(forward stagewise)最適化」。 の式も重み更新も、この最小化からそのまま導けます。一方で指数損失が誤分類を激しく罰するため、ノイズや外れ値に弱いのが弱点です。
1. ブースティングの考え方
ブースティングは、単体では精度の低い弱学習器(weak learner) を逐次的に足して、強い予測器を組み立てる枠組みです。「弱学習器」とは、ランダムよりほんの少しマシ(誤り率が 0.5 をわずかに下回る)程度の単純なモデルで、典型は decision stump(深さ1の決定木=特徴1つのしきい値で2分割するだけの木)です。
ポイントは足し方です。前の学習器が間違えたサンプルを「重要なサンプル」として重みを大きくし、次の学習器がそこに注目するよう仕向けます。これを繰り返すと、各弱学習器が前の弱点を順に埋めていきます。
flowchart LR
D0["訓練データ(全サンプル等重み)"] --> H1["弱学習器 h1 を学習"]
H1 --> R1["誤分類したサンプルの重みを増やす"]
R1 --> H2["重み付きデータで弱学習器 h2 を学習"]
H2 --> R2["まだ間違うサンプルの重みをさらに増やす"]
R2 --> H3["弱学習器 h3 を学習"]
H3 --> Dots["..."]
Dots --> Final["重み付き多数決で最終予測 H"]
要するに:ブースティングは「間違えたところを次で重点的に直す」を反復する逐次プロセスです。一発で完璧を狙わず、弱い手を順に積んで全体を強くします。
バギングとの対比
同じアンサンブルでも、バギング(ランダムフォレスト)とブースティングは設計思想が逆です。
graph TB
Ens["アンサンブル"]
Ens --> Bag["バギング(並列・独立)"]
Ens --> Boost["ブースティング(逐次・依存)"]
Bag --> B1["強い学習器(深い木)を多数"]
Bag --> B2["互いに独立に学習し平均/多数決"]
Bag --> B3["主にバリアンスを下げる"]
Boost --> O1["弱い学習器(浅い木)を多数"]
Boost --> O2["前の誤りを見て次を学習(依存)"]
Boost --> O3["主にバイアスを下げる"]
| 観点 | バギング(ランダムフォレスト) | ブースティング(AdaBoost等) |
|---|---|---|
| 学習器の作り方 | 並列・独立(順序は無関係) | 逐次・依存(前の結果を使う) |
| 部品の強さ | 強い学習器(深い木)でよい | 弱い学習器(stump など) |
| データの扱い | ブートストラップ標本(行を再抽出) | 全データを使い重みを変える |
| 主な効果 | バリアンスを下げる | バイアスを下げる |
| 並列化 | しやすい | しにくい(順番に作るため) |
要するに:バギングは「ばらつく学習器を平均してならす」、ブースティングは「ヘタな学習器を順に足し合わせて賢くする」。狙う誤差成分(バリアンス vs バイアス)が違います。詳しくはアンサンブルの原理のバイアス・バリアンス分解を参照してください。
2. AdaBoost のアルゴリズム(離散AdaBoost, 2クラス)
最も基本的な離散 AdaBoost(discrete AdaBoost)を、2クラス分類 で書き下します。弱学習器 も を返すものとします。
入力:訓練データ 、ラウンド数 。
ステップ0(初期化):すべてのサンプルに等しい重みを与える。
各ラウンド で:
-
弱学習器の学習:現在の重み のもとで、重み付き誤りが最小になる弱学習器 を学習する。
-
重み付き誤り率の計算:
は中身が真なら1・偽なら0を返す指示関数です。要するに:「重みで測った間違い率」。重い(重要な)サンプルを間違えるほど が大きくなります。
- 発言権(係数)の計算:
要するに:その弱学習器が最終投票でどれだけ強く意見を言えるかの重み。誤り率が低いほど大きくなります(後述)。
- サンプル重みの更新:
要するに:正解したサンプル()は 倍で軽く、間違えたサンプル()は 倍で重くなります。次のラウンドは重くなったサンプル=今回の失敗に注目します。
出力(最終識別器):
要するに:各弱学習器の予測 を発言権 で重み付けして足し合わせ、符号でクラスを決める「重み付き多数決」です。
flowchart TB
Init["重み初期化 w_i = 1/N"] --> Train["重み付きデータで h_m を学習"]
Train --> Err["重み付き誤り率 eps_m を計算"]
Err --> Alpha["発言権 alpha_m = 0.5 ln((1-eps_m)/eps_m)"]
Alpha --> Update["重み更新:誤分類サンプルを重く・正解を軽く → 正規化"]
Update --> Check{"m < M ?"}
Check -->|"Yes"| Train
Check -->|"No"| Out["最終識別器 H(x) = sign(Σ alpha_m h_m(x))"]
と重み更新の意味
の形を、誤り率 を動かして眺めると意味がはっきりします。
| 誤り率 | 解釈 | |
|---|---|---|
| (ほぼ完璧) | 強い発言権。最終投票を大きく左右 | |
| (当てずっぽう) | 発言権ゼロ。投票に寄与しない | |
| (逆張りで当たる) | 符号を反転して採用(予測を逆にすれば有用) |
要するに:「よく当てる弱学習器ほど大きな発言権を持つ」という直感が、 の式にそのまま入っています。 で になるのは、ランダムと同じ学習器は足しても無意味だから理にかなっています。
重み更新の方は、(正解なら 、誤りなら )が指数の符号を決めます。 のとき、誤分類サンプルは 倍に膨らみ、次のラウンドで「無視できない重要サンプル」に格上げされます。これが「前が間違えたところを次で直す」の実装です。
3. 数理的正体:指数損失の前向き段階的最適化
ここが理論の核心です。AdaBoost のアルゴリズムは天下りではなく、「指数損失で測った加法モデルを、項を1つずつ貪欲に最適化する」という1つの最適化問題から完全に導けます。 の式も重み更新も、この導出の副産物として自然に出てきます。
加法モデルと前向き段階的最適化
作りたいのは弱学習器の重み付き和、すなわち加法モデル(additive model):
全パラメータ を一度に最適化するのは困難なので、前向き段階的(forward stagewise) に解きます。つまり、これまでに作った は固定したまま、新しい項 だけを最適化して足す。1項ずつ貪欲に積み上げる方針です(決定木の貪欲な分割と同じ思想)。
損失には指数損失(exponential loss) を使います:
要するに: と の符号が一致(正しく分類)すれば で損失は小さく、外せば で損失が急激に大きくなる、滑らかな代理損失(surrogate loss)です(0-1損失の連続な上界)。
ラウンド の最小化問題
ラウンド で解くのは、 を固定して新しい項を足したときの指数損失の最小化です:
指数を分解します():
ここで と置くと、これは には依存しない定数(過去の積み上げで決まっている量)です。サンプル重みの正体はこれで、「今までのモデルがそのサンプルをどれだけ間違えているか」を表します。よって:
弱学習器 の決定 → 重み付き誤り最小化
、 なので、 は正解なら ・誤りなら の2値しか取りません。和を正解組と誤り組に分けます:
これを「誤り項」でまとめると(恒等式 を使う):
を固定して を選ぶとき、第2項は に依存しない定数で、第1項の係数 は正です。したがってこの損失を最小化する は、重み付き誤分類 を最小にする弱学習器にほかなりません。これがアルゴリズムのステップ1「重み付き誤りが最小の弱学習器を学習」の正体です。
係数 の決定 → あの式が出てくる
を固定し、重み付き誤り率 を使うと、最小化対象( で割って正規化)は
これを で微分して 0 と置きます:
両辺に を掛けて整理すると:
要するに:アルゴリズムで天下りに見えた は、「指数損失をその項について最小化する係数」を解いた閉形式の最適解です。係数の もこの微分から自然に出ます。
重み更新もここから出る
新しい項を足した後、次ラウンドの重みは定義上
これはアルゴリズムのステップ4そのものです(正規化は全体を定数倍するだけで や の選択に影響しないため、計算の都合で挟みます)。
graph LR
A["加法モデル f = Σ alpha_m h_m"] --> B["指数損失 L = exp(-y f)"]
B --> C["前向き段階的に1項ずつ最小化"]
C --> D["h_m → 重み付き誤り最小化"]
C --> E["alpha_m = 0.5 ln((1-eps)/eps)"]
C --> F["重み更新 w <- w exp(-alpha y h)"]
D --> G["= AdaBoost のアルゴリズム"]
E --> G
F --> G
要するに:AdaBoost =「指数損失を最小化する加法モデルを貪欲に組む手続き」。この見方が重要なのは、損失を別の関数に取り替えれば一般のブースティングになるからです。指数損失を一般の微分可能な損失に置き換え、勾配方向に弱学習器を足す一般化が勾配ブースティングで、AdaBoost はその特殊ケース(損失=指数損失)に位置づけられます。
4. 性質:過学習しにくさとノイズへの弱さ
なぜ過学習しにくいと言われるのか
AdaBoost はラウンドを増やしても、しばしば訓練誤差が0になった後でもテスト誤差が下がり続けることが経験的に知られています。直感的には、ラウンドを重ねるほど「正しく分類できる余裕の大きさ(マージン)」が広がるためで、マージン理論による説明が与えられています(訓練誤差0でも、判別の確信度 を押し上げ続ける)。
xychart-beta
title "ブースティングのラウンド数と誤差(概念図)"
x-axis "弱学習器の数 m" [10, 50, 100, 200, 400]
y-axis "誤差" 0 --> 0.5
line [0.30, 0.12, 0.05, 0.02, 0.01]
line [0.35, 0.22, 0.18, 0.16, 0.15]
上の線が訓練誤差、下の線がテスト誤差のイメージです。訓練誤差が0付近に達した後もテスト誤差がしばらく改善する(あるいは悪化しにくい)のがブースティングの特徴的な挙動です。要するに:単純な「足し算を増やすほど過学習」という直感が、ブースティングではそのまま当てはまりません。
指数損失の代償:ノイズ・外れ値に弱い
一方で、AdaBoost の最大の弱点はノイズと外れ値への脆さで、これは指数損失 の形から直接来ます。誤分類されたサンプル()の損失は に対して指数的に増大します。
xychart-beta
title "マージン y·f に対する損失(指数損失 vs 0-1損失)"
x-axis "マージン y·f" [-2, -1, 0, 1, 2]
y-axis "損失" 0 --> 8
line [7.39, 2.72, 1.0, 0.37, 0.14]
line [1, 1, 1, 0, 0]
ラベルが間違っているサンプルや真の外れ値は「いつまでも誤分類される」ので、重み更新のたびに 倍され、重みが指数的に膨れ上がります。すると後続の弱学習器がその少数の汚れたサンプルに引っ張られ、全体の性能が崩れます。要するに:指数損失は「外しているサンプルを激しく罰する」ため、罰すべきでないノイズまで全力で追いかけてしまうのです。
これを緩和する方向が、誤分類への罰がより穏やかな損失(対数損失・Huber 損失など)を使う一般のブースティングで、ここでも勾配ブースティングへの動機になります。
⚠️ よくある誤解
- 「ブースティングはバギングの一種」ではない。両方アンサンブルですが、バギングは並列・独立でバリアンスを下げ、ブースティングは逐次・依存でバイアスを下げる、逆方向の手法です(バギングとランダムフォレスト)。
- 「AdaBoost はデータをリサンプリングしている」とは限らない。ブートストラップで行を引き直すバギングと違い、標準の AdaBoost は全データを使い、サンプルの重みを変えるだけです(重みに比例した再抽出で実装することもありますが、本質は重み付き学習です)。
- 「 は天下りの定数」ではない。 は、指数損失をその項について最小化した閉形式の最適解です。 も微分から出ます。
- 「弱学習器は強いほど良い」ではない。ブースティングは弱学習器(stump・浅い木)を前提にします。1本を強くしすぎると各ラウンドが過学習し、逐次補正の利点が失われます。バリアンスの高い強学習器を束ねるのはバギング側の発想です。
- 「過学習しにくいから無敵」ではない。訓練誤差0後もテスト誤差が下がる挙動はクリーンなデータでの話。ノイズや誤ラベルが混じると指数損失のせいで急速に劣化します。AdaBoost は前処理でのラベルの正しさ・外れ値処理に敏感です。
- 「sign の中の和は確率」ではない。 は確率ではなくスコア(符号がクラス、絶対値が確信度=マージンの目安)。確率が欲しければロジスティック版(LogitBoost)や勾配ブースティングの対数損失版を使います。
対応するシミュレーション
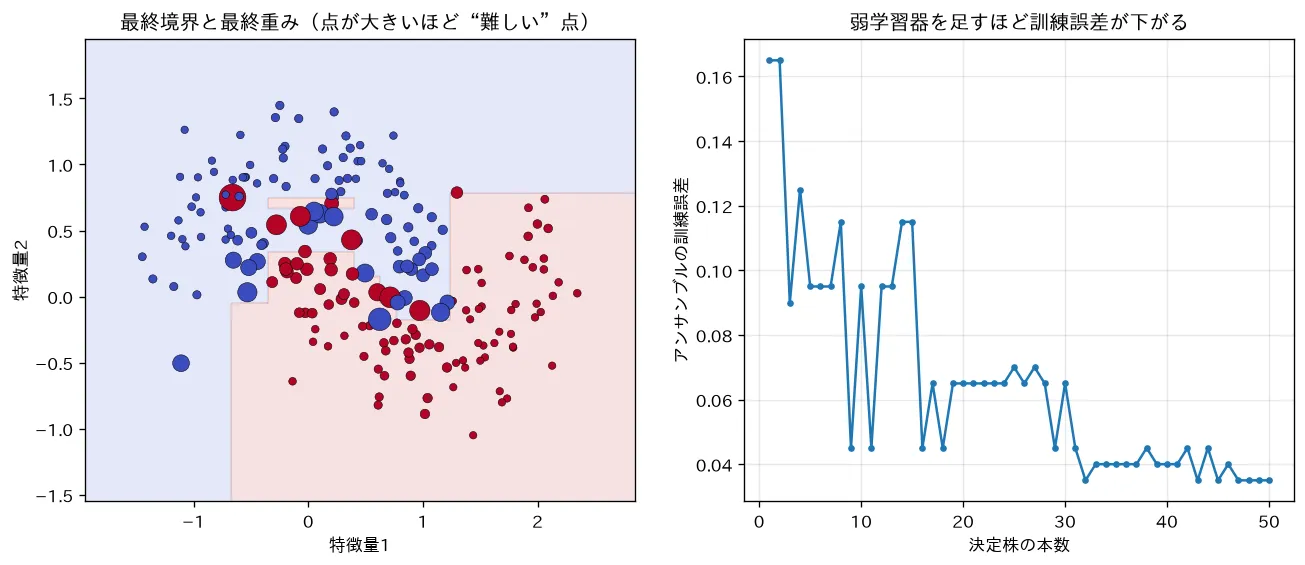
simulations/adaboost_stages.py:AdaBoost(離散版)を自前実装し、決定株(深さ1の木)を1本ずつ足していきます。前の株が間違えた点の重みを増やして次の株に注目させる逐次的な再重み付けの結果、アンサンブルの訓練誤差が下がること、最後まで重みが大きい“難しい”点が境界付近に集中することを可視化します(点の大きさ=最終重み)。指数損失の逐次最小化として導かれます。
関連ノート
- アンサンブル学習 目次
- アンサンブルの原理(バイアス・バリアンス分解とアンサンブルの効き方)
- バギングとランダムフォレスト(並列・独立でバリアンスを下げる対照的手法)
- 勾配ブースティング(指数損失を一般の損失に拡張した一般化。AdaBoost はその特殊ケース)
- 決定木(弱学習器となる decision stump の母体)
- 機械学習テキスト 全体目次