🎓 レベル:標準 | 重要度:A(必須)
📎 前提:確率過程(マルコフ連鎖・ポアソン過程)(マルコフ性・統計)
要点(BLUF)
- マルコフ決定過程(MDP, Markov Decision Process)は、強化学習が解く問題を数学的に書き下す枠組みです。エージェントが「状態を見て→行動を選び→報酬と次状態を受け取る」ループを、5つ組 で定義します。
- 心臓部はマルコフ性:次に何が起きるかは「いまの状態と行動」だけで決まり、それ以前の履歴には依存しません。だから状態さえ持てば過去を全部覚えなくてよい、という強力な単純化が効きます。
- 目標は、割引累積報酬(リターン) の期待値を最大にする方策 を見つけること。教師あり学習のような「正解ラベル」はなく、報酬という弱い信号だけを頼りに、長期の合計を最大化します。
1. 強化学習とは:報酬で学ぶ枠組み
強化学習(Reinforcement Learning, RL)は、エージェント(agent)が環境(environment)と試行錯誤でやりとりしながら、もらえる報酬の合計を最大化する行動の仕方を学ぶ枠組みです。各時刻でループが回ります。
- エージェントが現在の状態 を観測する
- 行動 を選ぶ
- 環境が報酬 と次状態 を返す
- 2に戻る
flowchart LR
Agent["エージェント"] -->|"行動 a_t"| Env["環境"]
Env -->|"報酬 r_t+1"| Agent
Env -->|"次状態 s_t+1"| Agent
教師あり・教師なしとの違いを押さえておきます。
| 枠組み | 与えられる信号 | 学ぶもの |
|---|---|---|
| 教師あり | 入力ごとの正解ラベル(強い信号) | 入力→出力の写像 |
| 教師なし | ラベルなし、データの構造だけ | 分布・クラスタ・低次元表現 |
| 強化学習 | 報酬(弱い・遅れて来る・選んだ行動の良し悪ししか分からない) | 状態→行動の方策 |
ポイントは2つです。(1) 正解が与えられない:「その状況での最適な行動」は誰も教えてくれず、報酬の良し悪しから自分で推測します。(2) 報酬は遅れて来る(遅延報酬):いま選んだ行動の真価が、何手も先になって初めて分かることがあります(将棋の序盤の一手など)。この「弱くて遅い信号から長期の最適を学ぶ」のが強化学習の難しさであり面白さです。
要するに:強化学習は「正解は教わらないが、行動の結果として報酬がもらえる」状況で、報酬の合計を最大化する行動方針を学ぶ問題です。
2. MDP の構成要素:5つ組
強化学習が扱う「環境」を数学的に書き下したものが MDP です。次の5つで定義します。
- 状態空間 :エージェントが置かれうる状況の集合。。
- 行動空間 :選べる行動の集合。。状態ごとに選べる行動が違うこともあります( と書く)。
- 遷移確率 :状態 で行動 を取ったとき、次状態が になる確率。環境のダイナミクスそのものです。
- 報酬関数 :行動の直後にもらえる即時報酬。 や と書きます。確率的なら 。
- 割引率 :未来の報酬を「いまの価値」に換算するときの割引係数(後述)。
遷移は確率的であることに注意してください。「同じ状態で同じ行動を取っても、次にどこへ行くかは確率的にばらつく」のが一般の MDP です(決定的な環境は が 0/1 になる特殊ケース)。
要するに:MDP は「世界のルール(どう動くと、何がもらえて、次どこへ行くか)」を という5つ組で完全に記述したものです。
3. マルコフ性:過去を忘れてよい理由
MDP の MD(Markov Decision)たるゆえんが**マルコフ性(Markov property)**です。これは
という性質、つまり次状態の分布は「いまの状態と行動」だけで決まり、それ以前の履歴に依存しないことを言います。マルコフ性そのものの定義・確率連鎖としての扱いは統計側の 確率過程(マルコフ連鎖・ポアソン過程) に土台があります。ここではそれを「意思決定つきの確率過程」に拡張している、と捉えてください。
なぜこれが重要かというと、状態 さえ持てば、過去の履歴を全部覚えなくても最適な意思決定ができるからです。記憶すべき情報が「いまの状態」に圧縮され、方策も価値も の関数として書けます。もし次状態が過去の長い履歴に依存するなら、状態の定義を拡張して履歴を畳み込めば(理屈の上では)またマルコフ性を満たせます。
⚠️ 逆に言うと、マルコフ性は「状態が十分な情報を持つように設計されている」という強い前提です。状態の作り方が悪いとこの仮定は壊れます。詳しくは「よくある誤解」で扱います。
要するに:マルコフ性は「いまの状態が、将来を予測するのに必要な情報をすべて含んでいる」という仮定。これのおかげで過去を忘れて、状態だけで意思決定できます。
4. 方策 :状態から行動への写像
エージェントの行動の仕方を表すのが方策(policy) です。状態を入力すると、取るべき行動を返す写像で、確率的にも決定的にも書けます。
- 確率的方策:(状態 で行動 を選ぶ確率)
- 決定的方策:(状態 では必ず行動 )
flowchart LR
S["状態 s"] --> Pi["方策 π"]
Pi -->|"確率 π(a given s)"| A["行動 a"]
確率的方策は「探索(exploration)」のために重要です。常に同じ行動だと、まだ試していないより良い行動を見つけられません。確率的にばらつかせることで、未知の行動も試せます(探索と活用のトレードオフは別ノートで扱います)。
要するに:方策はエージェントの「行動のクセ」。状態を見て、どの行動をどのくらいの確率で取るかを決めるルールです。学習とは、この を良くしていくことに他なりません。
5. リターン :割引累積報酬
強化学習が最大化したいのは、ある時刻以降にもらえる報酬の合計です。これをリターン(return) と呼び、未来の報酬を割引率 で割り引いて足し合わせます。
乗が掛かるので、遠い未来の報酬ほど軽く評価されます( なら10手先は 倍)。
なぜ割り引くのか
割引には数理的・実際的な理由が3つあります。
- 無限和の収束:連続タスク(終わりのない課題)では報酬が無限に足され、 だと合計が発散して「最大化」が定義できません。報酬が有界()なら、 のとき等比級数で
と必ず有限に収まります。これが と半開区間で書く理由です( を含めない)。 2. 近視眼性の調整: が小さいほど「目先の報酬を優先する近視眼的」な行動に、 に近いほど「遠い未来まで見据える遠視的」な行動になります。 は「どれだけ先まで気にするか」を決めるツマミです。 3. 不確実な未来:遠い未来ほど予測が不確かなので、確実な目先の報酬を相対的に重く見るのは合理的です(経済学の割引現在価値と同じ発想)。
要するに:リターンは「これから先にもらえる報酬の割引合計」。割り引くのは、無限和を収束させ、近視眼性を調整し、不確実な未来を割り引くためです。
6. 目標:最適方策
強化学習のゴールは、リターンの期待値を最大にする方策 を見つけることです。リターン は遷移も方策も確率的なので、その期待値を最大化します。状態 から方策 に従ったときの期待リターンを価値関数 と呼びます。
最適方策はすべての状態で価値を同時に最大化する方策です。
「すべての状態で同時に最大化できる方策が本当に存在するのか」は自明ではありませんが、有限 MDP ではそのような決定的な最適方策が必ず存在することが知られています(証明はベルマン最適方程式とともに 価値関数とベルマン方程式 で扱います)。この価値関数とベルマン方程式が、強化学習アルゴリズムすべての土台になります。
要するに:強化学習とは「期待リターンを最大にする方策 を探す最適化問題」。その評価尺度が価値関数 です。
7. エピソード的タスク vs 連続タスク
MDP には終わり方で2タイプあります。
- エピソード的タスク(episodic):明確な終端状態があり、有限ステップで1エピソードが終わってリセットされる(ゲーム1局、迷路を抜ける、など)。終端があるので でもリターンは有限になりえます。
- 連続タスク(continuing):終わりがなく永遠に続く(在庫管理、プラント制御、推薦の継続運用など)。リターンが発散しないよう が事実上必須です。
両者は「終端状態に入ると報酬0で自分自身に留まり続ける(吸収状態)」と見なすことで、 という同じ式に統一して扱えます。
⚠️ よくある誤解・落とし穴
- 報酬・リターン・価値の3つを混同する:報酬 は1ステップの即時の手応え、リターン は実際にたどった1つの軌道での割引合計(実現値・確率変数)、**価値 はその期待値(あらゆる軌道で平均した予測値)**です。報酬は「いまの一口が美味いか」、価値は「この店に通い続けたときの総合満足度の期待」。即時報酬が低くても価値が高い状態はいくらでもあります(将来の大報酬への通り道)。この区別は次ノートの前提です。
- マルコフ性の仮定を無条件に成り立つと思う:マルコフ性は「状態が将来予測に十分な情報を持つ」という状態設計への強い要請です。たとえば速度を知るべき制御で位置だけを状態にすると、次状態は過去の位置履歴に依存してしまい(速度が分からない)、マルコフ性が壊れます。観測が状態を完全に表せない場合は POMDP(部分観測 MDP)という別枠組みになります。状態の作り方そのものが設計の肝です。
- 割引率 を「ただのハイパーパラメータ」と軽く見る: は最大化する目的関数そのものを変えます。 を変えれば最適方策も変わりえます。「無限和を収束させる技術的都合」であると同時に「どれだけ先を見据えるかという問題定義」でもある、という二面性を押さえてください。
- 「遷移は決定的」と思い込む:一般の MDP では同じ でも次状態は確率的にばらつきます。決定的環境は の特殊ケースにすぎません。
対応するシミュレーション
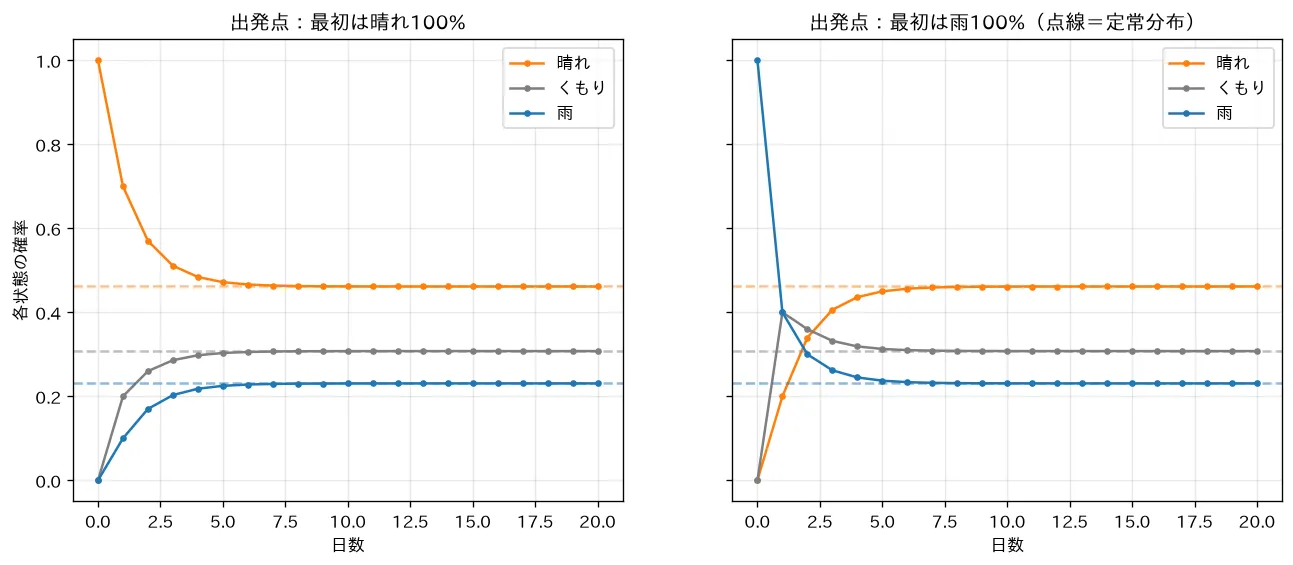
simulations/markov_chain.py:3状態(晴れ・くもり・雨)の遷移行列で、状態分布を と繰り返し更新します。出発点が「晴れ100%」でも「雨100%」でも、十分混ざる連鎖なら同じ定常分布へ収束すること(固有ベクトルから求めた値と一致)を可視化します。MDP はこのマルコフ連鎖に行動と報酬を足したもので、状態のマルコフ性が価値関数・ベルマン方程式(価値関数とベルマン方程式)の土台になります。
関連ノート
- 強化学習 目次
- 価値関数とベルマン方程式(次:価値の再帰的定義と最適性)
- 確率過程(マルコフ連鎖・ポアソン過程)(マルコフ性・状態遷移の数理的土台・統計)
- ニューラルネットワーク 目次(深層強化学習で関数近似器として使う)
- 機械学習テキスト 全体目次