← 機械学習テキスト 一覧
🎓 レベル:標準 | 重要度:A(必須)
📎 前提:マルコフ決定過程
要点(BLUF)
- 価値関数は「ある状態(または行動)から先、方策 π に従ったときに得られる将来報酬の期待値」。良さを1つの数で測る道具です。
- ベルマン方程式は、その価値を「今の報酬 + 割引した次状態の価値」へ再帰的に分解した関係式。これがあるおかげで価値を逐次計算で求められます。
- 最適価値を満たす V∗ はベルマン作用素の不動点で、作用素が γ-収縮なので価値反復・方策反復で必ず収束します。
1. なぜ価値関数が要るのか
マルコフ決定過程 で、強化学習の目的は累積報酬(リターン)の期待値を最大化することだと定義しました。リターンは
Gt=Rt+1+γRt+2+γ2Rt+3+⋯=k=0∑∞γkRt+k+1
でした(γ∈[0,1) は割引率)。しかし Gt は将来の確率的な報酬の無限和なので、これ自体は直接最大化できません。そこで「期待値を取って状態(や行動)の関数にしてしまえば扱える」という発想が価値関数です。
2. 状態価値関数 Vπ と行動価値関数 Qπ
状態価値関数は、状態 s から方策 π に従ったときのリターンの期待値です。
Vπ(s)=Eπ[Gt∣St=s]
要するに:「この状態にいると、これから平均でどれくらい得するか」を表す数。
行動価値関数(Q関数)は、状態 s で行動 a を取ってから方策 π に従ったときのリターンの期待値です。
Qπ(s,a)=Eπ[Gt∣St=s,At=a]
要するに:「この状態でこの行動を選ぶと、これから平均でどれくらい得するか」。V は状態だけ、Q は状態と行動の組で評価する点が違います。
両者の関係は、最初の1手を方策に従って選ぶ期待を取れば V になる、というものです。
Vπ(s)=a∑π(a∣s)Qπ(s,a)
逆に Q は「即時報酬 + 割引した次状態の V」で書けます(次節で導きます)。
Qπ(s,a)=s′∑P(s′∣s,a)[R(s,a,s′)+γVπ(s′)]
3. ベルマン期待方程式(導出)
価値関数の威力は、リターンの再帰構造から来ます。定義の和を1つ前と1つ後に分けると
Gt=Rt+1+γ(Rt+2+γRt+3+⋯)=Rt+1+γGt+1
要するに:リターン=「次にもらう報酬」+「割引した、その先のリターン」。
これを Vπ の定義に代入します。期待の線形性から
Vπ(s)=Eπ[Rt+1+γGt+1∣St=s]=Eπ[Rt+1∣St=s]+γEπ[Gt+1∣St=s]
ここで第2項に注目します。Gt+1 は時刻 t+1 以降の量なので、いったん次状態 St+1=s′ で条件付ければ、マルコフ性により「s′ から先のリターンの期待」= Vπ(s′) にまとまります(全期待値の法則)。状態遷移の確率を明示的に展開すると、ベルマン期待方程式が得られます。
Vπ(s)=a∑π(a∣s)s′∑P(s′∣s,a)[R(s,a,s′)+γVπ(s′)]
要するに:Vπ(s) は「自分でできる関数評価」だけで閉じている。無限和を消して、次状態の同じ関数 Vπ で書き直したのがミソです。
Qπ についても同様に、Qπ(s,a) を1手分展開してから次状態で方策に従うと
Qπ(s,a)=s′∑P(s′∣s,a)[R(s,a,s′)+γa′∑π(a′∣s′)Qπ(s′,a′)]
となります。V 版と Q 版は、Vπ(s′)=∑a′π(a′∣s′)Qπ(s′,a′) を通して互いに変換できます。
バックアップ図(期待の取り方)
ベルマン方程式は「状態 → 行動 → 次状態」と1段先まで木を展開し、確率で重み付けして価値を**戻す(バックアップ)**操作として読めます。
graph TD
S["状態 s : Vπ(s)"]
A1["行動 a1"]
A2["行動 a2"]
S1["次状態 s' : Vπ(s')"]
S2["次状態 s'' : Vπ(s'')"]
S3["次状態 s''' : Vπ(s''')"]
S -- "π(a1|s)" --> A1
S -- "π(a2|s)" --> A2
A1 -- "P(s'|s,a1) → R + γVπ(s')" --> S1
A1 -- "P(s''|s,a1) → R + γVπ(s'')" --> S2
A2 -- "P(s'''|s,a2) → R + γVπ(s''')" --> S3
上向きに「即時報酬+割引した次状態価値」を期待で集約すると Vπ(s) になる、という図です。∑ はこの集約(行動について方策で、次状態について遷移確率で)を表します。
4. ベルマン最適方程式
価値関数には半順序を入れられます。すべての状態で Vπ′(s)≥Vπ(s) なら「π′ は π 以上」と定めます。有限MDPでは、この順序で最大の価値を達成する方策が必ず存在し、それを最適方策 π∗、その価値を最適価値と呼びます。
V∗(s)=πmaxVπ(s),Q∗(s,a)=πmaxQπ(s,a)
最適価値が満たす再帰は、ベルマン期待方程式で「方策に従って行動を平均する」代わりに「最良の行動を選ぶ」に置き換えたものです。
V∗(s)=amaxs′∑P(s′∣s,a)[R(s,a,s′)+γV∗(s′)]
Q∗ についても同様に、次状態では最良の行動を取るので
Q∗(s,a)=s′∑P(s′∣s,a)[R(s,a,s′)+γa′maxQ∗(s′,a′)]
要するに:期待方程式の ∑aπ(a∣s) が maxa に変わっただけ。これが「最適とはこういう関係を満たす」という定義不要の自己整合条件です。
V∗ と Q∗ の関係、最適方策の取り出し
両者は次で結ばれます。
V∗(s)=amaxQ∗(s,a),Q∗(s,a)=s′∑P(s′∣s,a)[R(s,a,s′)+γV∗(s′)]
最適方策は Q∗ に関して貪欲(greedy)に取れば得られます。
π∗(s)=argamaxQ∗(s,a)
要するに:Q∗ さえ分かれば、各状態で最大の Q∗ を与える行動を選ぶだけで最適に動ける。これが Q学習が Q∗ を直接狙う理由です(Q学習とSARSA)。なお V∗ から方策を取り出すには P,R(遷移モデル)が要りますが、Q∗ からならモデル不要なのが実務上の大きな違いです。
5. 動的計画法(モデルあり)
遷移 P と報酬 R が既知なら、ベルマン方程式を計算手続きに変えて最適価値を求められます。これが**動的計画法(DP)**です。
ベルマン作用素
価値関数を入力に取り、ベルマン更新を1回適用して新しい価値関数を返す写像をベルマン作用素と呼びます。最適版(ベルマン最適作用素)T は
(TV)(s)=amaxs′∑P(s′∣s,a)[R(s,a,s′)+γV(s′)]
です。ベルマン最適方程式は TV∗=V∗、つまり V∗ は T の不動点だと言い換えられます。
価値反復(value iteration)
T をひたすら適用します。
Vk+1=TVk(k=0,1,2,…)
収束したら(∥Vk+1−Vk∥ が十分小さくなったら)貪欲方策を取り出します。
flowchart TD
INIT["V を任意に初期化"] --> UPD["全状態を更新 : V(s) ← max_a Σ P・(R + γV(s'))"]
UPD --> CONV{"変化が ε 未満か"}
CONV -- "いいえ" --> UPD
CONV -- "はい" --> POL["貪欲方策を抽出 : π(s) = argmax_a Q(s,a)"]
POL --> END["最適方策 π*"]
方策反復(policy iteration)
「評価」と「改善」を交互に繰り返します。
- 方策評価:固定した π のベルマン期待方程式を解いて Vπ を求める(線形方程式 Vπ=Rπ+γPπVπ を直接解くか、期待作用素を反復)。
- 方策改善:得た Vπ に貪欲な新方策 π′(s)=argmaxa∑s′P(s′∣s,a)[R+γVπ(s′)] を作る。
- 方策が変わらなくなったら終了。
flowchart TD
INIT["方策 π を初期化"] --> EVAL["方策評価 : Vπ を Σ で求める"]
EVAL --> IMPR["方策改善 : π'(s) = argmax_a Q(s,a)"]
IMPR --> STABLE{"π が変化したか"}
STABLE -- "はい" --> EVAL
STABLE -- "いいえ" --> END["最適方策 π*"]
方策改善定理により各改善ステップで Vπ′≥Vπ(成分ごと)が保証され、有限MDPでは決定的方策が有限個しかないので有限回で停止して最適に到達します。価値反復は「評価を1回だけにした方策反復」とも見なせます。
なぜ収束するか:γ-収縮とバナッハの不動点定理
DP が必ず最適価値に行き着く核心は、T が最大値ノルムで γ-収縮写像だという事実です。任意の2つの価値関数 V,W に対し
∥TV−TW∥∞≤γ∥V−W∥∞,∥U∥∞=smax∣U(s)∣
が成り立ちます(0≤γ<1)。
証明の要点。各状態 s について、a∗=argmaxa(TV 側で最大を取る行動)とすると、TW はその a∗ でも最大以下なので
(TV)(s)−(TW)(s)≤γs′∑P(s′∣s,a∗)[V(s′)−W(s′)]≤γs′∑P(s′∣s,a∗)∥V−W∥∞=γ∥V−W∥∞
を得ます(途中で R が打ち消し、確率の和が1)。V,W を入れ替えれば逆向きの不等式も成り立つので、両辺の絶対値・maxs を取って収縮が言えます。
要するに:max も「即時報酬の差はゼロ、残るのは次状態価値の差が γ 倍に縮む」という構造を壊さない。だから1回 T を当てるたびに、真の解 V∗ との距離が必ず γ 倍以下になります。
収縮写像なのでバナッハの不動点定理から、不動点 V∗ は一意に存在し、任意の初期値から
∥Vk−V∗∥∞≤γk∥V0−V∗∥∞
と幾何級数的(指数的)に収束します。γ が1に近いほど縮みが緩く、収束が遅くなります。
⚠️ よくある誤解・落とし穴
- V と Q を混同する。V は状態だけの良さ、Q は「状態でこの行動を取る」良さ。制御(行動選択)には Q が直接効くので、モデルなしで最適方策を取り出すなら Q∗ が要ります。
- DP は遷移モデルが要る。価値反復・方策反復は P,R が既知である前提のプランニング手法です。P,R を知らない実問題では使えず、サンプルから学ぶ TD法(Q学習とSARSA)に移ります。
- ベルマン方程式は「定義」ではない。Vπ,V∗ の定義はあくまで期待リターンです。ベルマン方程式は、その定義から導かれて成り立つ自己整合の関係式であり、価値が満たすべき条件として後から効いてきます。
- 最適方程式の max は線形でない。期待方程式 Vπ は Vπ について線形(だから連立一次方程式で一発で解ける)ですが、最適方程式は max のせいで非線形になり、一般に反復で解きます。
- γ=1 では収縮が保証されない。γ<1 が収縮・一意不動点・収束の根拠です。γ=1(割引なし)はエピソードが必ず終わる等の追加条件が要ります。
対応するシミュレーション
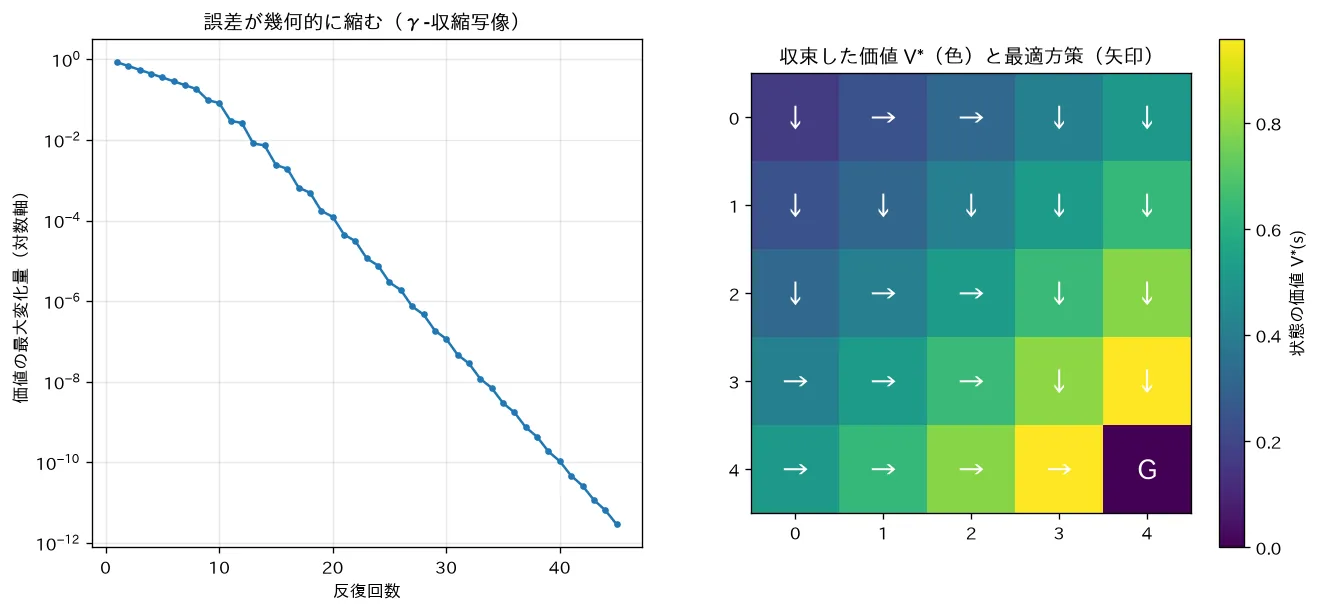
simulations/value_iteration.py:遷移と報酬が分かっている(やや確率的な)グリッドワールドで、ベルマン最適方程式 V(s)=maxa∑s′P(s′∣s,a)[r+γV(s′)] を右辺→左辺の代入として繰り返します。価値が一意の最適値 V∗ に収束し、その誤差が毎回 γ 倍以下に縮む(対数軸で直線=幾何的収束=γ-収縮写像)ことを可視化します。得られる最適方策は Q学習(Q学習とSARSA)と一致し、違いは「モデルあり動的計画法」か「経験から学ぶモデルなし」かです。
関連ノート