🎓 レベル:標準 | 重要度:A(必須)
📎 前提:価値関数とベルマン方程式
要点(BLUF)
- TD学習=環境モデル(遷移確率 ・報酬 )を知らずに、経験のサンプルだけから価値を更新する。鍵はブートストラップ:今の推定値で今の推定値を直す。
- **SARSA(方策オン)**は「実際にとった次の行動 」で更新し、**Q学習(方策オフ)**は「次状態で最善な行動 」で更新する。この一文字の違いが両者を分ける。
- 価値を当てにする(活用)だけでは局所最適に陥るので、たまにわざと外す(探索)。その実装が ε-greedy。
1. なぜモデルフリーか
価値関数とベルマン方程式では、遷移確率 と報酬 が既知である前提で、ベルマン方程式を解いて価値を求めました(動的計画法)。
しかし現実の多くの問題では、 も も事前にはわかりません。ロボットが床を蹴ったとき次にどこへ転ぶか、ゲームでこの手を指したとき相手がどう応じるか、その確率分布を式で持っていることはまずありません。
そこで発想を変えます。確率分布を知らなくても、実際に動いてみればサンプルは手に入る。状態 で行動 をとったら、報酬 が返り、次状態 に遷移した――この一回一回の経験 を積み上げて、価値関数を直接推定する。これが**モデルフリー(model-free)**の強化学習です。
要するに:期待値を計算する代わりに、サンプルで近似する。確率分布の数式を持たずに、経験の積み重ねで価値を学ぶ。
2. TD学習とブートストラップ
TD誤差
状態価値 を例にとります。ベルマン方程式は でした。期待値 は分布を知らないと計算できませんが、1回の経験 は という1サンプルを与えてくれます。
このサンプルと現在の推定 のズレを **TD誤差(temporal-difference error)**と呼びます:
そして をこの誤差の方向へ少しだけ動かします( は学習率):
要するに:TD誤差は「予想より良かった/悪かった」の差分。良ければ価値を上げ、悪ければ下げる。 なら が過小評価だった合図です。
ブートストラップとは
TDターゲット の中に、まだ確定していない推定値 が入っている点に注目してください。確定した実測値ではなく、自分の推定で自分の推定を更新している。これを**ブートストラップ(bootstrapping)**と呼びます。
最初は もデタラメですが、すべての状態が互いを少しずつ正しい方向へ引っ張り合い、反復のうちに全体が真の価値へ収束していきます。
TD vs モンテカルロ
ブートストラップの有無が、TDと**モンテカルロ法(MC)**を分けます。
| モンテカルロ(MC) | TD学習 | |
|---|---|---|
| ターゲット | エピソード終了までの実収益 | 1ステップ先の推定 |
| ブートストラップ | しない | する |
| 更新タイミング | エピソード終了後 | 1ステップごと(オンライン) |
| バイアス | なし(不偏) | あり(推定値を使うため) |
| 分散 | 大きい(多数の確率事象の積み重ね) | 小さい |
要するに:MCは最後まで待って実際の収益で更新するので不偏だが分散が大きい。TDは1歩先の推定で即更新するのでバイアスは入るが分散が小さく、エピソードが終わらない問題でも学べる。バイアス‐バリアンスのトレードオフです。
flowchart LR
A["状態 s で行動 a"] --> B["報酬 R と次状態 s' を観測"]
B --> C["TDターゲット = R + γ × 次の価値推定"]
C --> D["TD誤差 δ = ターゲット − 現在の推定"]
D --> E["価値を α×δ だけ更新"]
E --> A
3. SARSA(方策オン制御)
状態価値 だけでは、モデルがないと「どの行動が良いか」を選べません(行動を比較するには遷移先の分布が要る)。そこで行動価値 を学びます。 さえあれば、各状態で が最大の行動を選ぶだけで方策が決まります。
SARSAの更新則は次の通りです:
ここで は、現在の方策(例:ε-greedy)に従って次状態 で実際に選んだ行動です。更新に使う5つの量
の頭文字を並べて **SARSA(State–Action–Reward–State–Action)**と名づけられました。
要するに:SARSAは「次に本当にとる行動 の価値」でブートストラップする。だから自分が今まさに従っている方策の価値を学ぶ。これが**方策オン(on-policy)**の意味です。学習対象の方策と、行動を決める方策が同一。
4. Q学習(方策オフ制御)
Q学習の更新則はSARSAとほぼ同じ形ですが、 の代わりに次状態での最大値を使います:
は「次状態 で最も価値の高い行動をとったと仮定した値」です。実際に次にどの行動をとるか(探索でわざと外すかもしれない)とは無関係に、常に貪欲(greedy)な行動を基準にターゲットを作る点がSARSAと決定的に違います。
このため Q学習は2つの方策を区別します:
- 行動方策(behavior policy):実際に環境を動かして経験を集める方策(探索を含む ε-greedy)
- 学習方策(target policy):学ぼうとしている方策(貪欲な最適方策)
両者が別物なので **方策オフ(off-policy)**と呼びます。Q学習の更新則は最適行動価値 に対するベルマン最適方程式 をサンプルで近似したものなので、探索しながら(行動方策が何であれ)最適方策の価値 を学べます。
graph TB
subgraph SARSA["SARSA(方策オン)"]
S1["TDターゲット = R + γ × Q ( s' , a' )"]
S2["a' は実際にとる次の行動"]
S1 --- S2
end
subgraph QL["Q学習(方策オフ)"]
Q1["TDターゲット = R + γ × max_a' Q ( s' , a' )"]
Q2["貪欲な行動を仮定(実際の a' は無関係)"]
Q1 --- Q2
end
5. SARSA と Q学習の違い:崖歩き
両者の性格差が最もきれいに出るのが **崖歩き(cliff walking)**という格子世界です。スタートからゴールまで歩き、各ステップで 、崖に落ちると でスタートに戻されます。崖のすぐ縁を通る経路が最短ですが、探索(ε-greedy)で時々ヨコに外れると崖に落ちます。
- Q学習:ターゲットが なので、探索で落ちるリスクを無視して最適経路(崖の縁)を学ぶ。学習した方策としては最短だが、学習中は ε による事故落下が多く、エピソード収益は荒れがち。
- SARSA:ターゲットが「実際にとる の価値」なので、縁の状態は“探索で落ちる危険”込みで低く評価される。結果として崖から少し離れた安全で長い経路を学ぶ。学習中の収益はQ学習より安定して良いことが多い。
要するに:Q学習は「探索が消えた後の最適方策」の価値を学ぶので攻める。SARSAは「今まさに探索している自分」の価値を学ぶので安全側に倒れる。なお に減衰させれば、両者とも同じ最適方策に近づきます。
6. 探索と活用(ε-greedy)
価値推定が手に入っても、常に「今いちばん良さそうな行動」だけを選ぶ(純粋な活用 exploitation)と、まだ試していない本当に良い行動を永遠に発見できません。一度たまたま低く評価された行動は二度と選ばれず、推定が更新されないまま局所最適に固定されます。
そこで**探索(exploration)**を混ぜます。最も基本的なのが ε-greedy:
- が大きい:よく探索する。学習初期に有効。
- が小さい:活用優先。十分学んだ後はこちら。
実務では を徐々に減衰させ、初めは探索、後半は活用へと移すのが定石です。
要するに:探索=「未知を試す投資」、活用=「既知の最善で稼ぐ」。この探索と活用のトレードオフは強化学習の根本問題で、ε-greedy はその最小限の解決策です。
7. 収束条件
Q学習・SARSAが真の価値(Q学習なら )へ収束するための代表的な条件は次の2つです(Watkins & Dayan 1992 ほか、確率近似理論に基づく)。
- 全状態行動対を無限回訪問:どの も訪れ続ける(探索を絶やさない= を保つことが効く)。一度も試さない手の価値は学べません。
- 学習率の減衰(ロビンス・モンロー条件):
前者は「更新を止めない(どこへでも動ける)」、後者は「ノイズを平均化して落ち着かせる」を意味します。 のような減衰がこれを満たします。
要するに:「全部の手を試し続ける」+「学習率を適切に小さくしていく」が揃えば、サンプルだけからでも価値は真値に収束します。
⚠️ よくある誤解・落とし穴
- オン方策とオフ方策を取り違える:「SARSA=オン、Q学習=オフ」。見分け方は更新ターゲットだけ―― を使えばオフ方策(Q学習)、実際の を使えばオン方策(SARSA)。アルゴリズム名ではなく更新式で判断する。
- TD誤差の符号:。順番を逆にして「現在 − ターゲット」とすると更新の向きが反転し、価値が発散します。ターゲット − 現在が正しい。
- 探索を切ると学習が壊れる: にすると未訪問の が永久に更新されず、収束条件「全状態行動対を無限回訪問」が破れます。学習中は探索を残すこと。
- Q学習の を「実際に次にとる行動」と勘違いする: はあくまで仮定の貪欲行動。次に実際とる行動は ε-greedy で別個に決まる(だからオフ方策)。
- 学習率を減衰させずに固定する:定数 だと収束条件 を満たさず、真値の周りで振動し続けます(実務では近似として許容されることもありますが、理論上の収束は保証されません)。
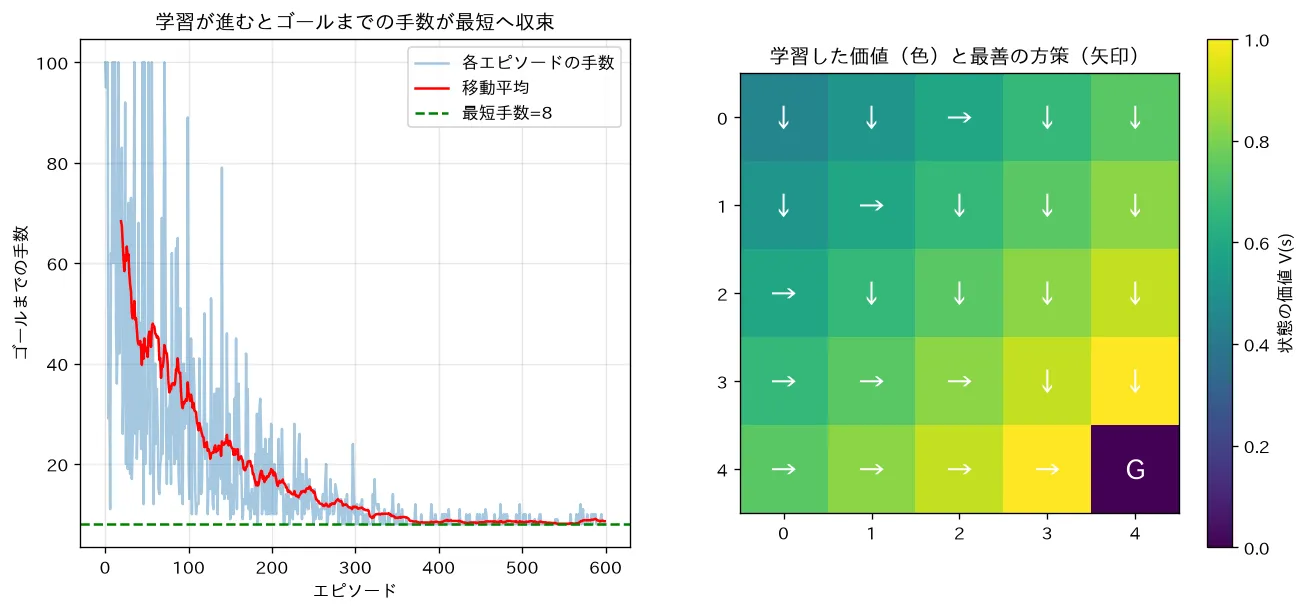
対応するシミュレーション
simulations/q_learning_gridworld.py:5×5のグリッドワールド(左上→右下ゴール)で Q学習を自前実装します。ε-greedy で探索しながら TD誤差 で Q値を更新すると、ゴールまでの手数が最短(8手)へ収束し、各マスの価値(ゴール側ほど高い)と最善の方策(全矢印がゴールへ向かう)を報酬モデルだけから学べることを可視化します。max を使う方策オフ学習で、SARSA は実際にとった を使う点が違います。