🎓 レベル:発展 | 重要度:B(標準)
要点(BLUF)
- Actor-Critic は、行動を決めるActor(方策 ) を、状態の良さを評価するCritic(価値 ) が採点する仕組み。Criticで優位関数 を推定し、方策勾配法(REINFORCE)の高分散を下げる。
- 深層強化学習は、価値・方策をニューラルネットで関数近似して高次元状態(画像など)を扱えるようにしたもの。代表がDQN(価値ベース)とPPO(方策ベース)。
- DQNとPPOの肝はどちらも安定化技術。DQNは経験再生+ターゲットネットワーク、PPOは更新幅のクリッピングで「壊さずに学ぶ」。
1. Actor-Critic:価値ベースと方策ベースの融合
Q学習とSARSA(価値ベース)と方策勾配法(方策ベース)は、これまで別系統の手法として扱ってきました。Actor-Critic はこの2つを1つのループに統合します。
| 役割 | 中身 | 何をするか |
|---|---|---|
| Actor(俳優) | 方策 | 行動を選ぶ。方策勾配で更新される |
| Critic(批評家) | 価値 | 行動の結果を採点する。TD学習で更新される |
要するに、Actorが動き、Criticが「今のは平均よりよかった/悪かった」と評価し、その評価を使ってActorを直す——という分業です。
なぜCriticが要るのか:REINFORCEの高分散問題
方策勾配法の素朴な勾配(REINFORCE)は、軌跡全体の収益 で方策を重み付けします。
ここで は1エピソードを最後まで回して得るモンテカルロ収益なので、運の要素が丸ごと乗り、分散が非常に大きいのが弱点でした。学習が遅く不安定になります。
そこでベースライン を引きます。ベースラインが行動 に依存しなければ、勾配の期待値(バイアス)は変えずに分散だけ下げられる——これは方策勾配法で示した性質です。最も自然なベースラインが状態価値 であり、その差し引きが優位関数(Advantage) です。
優位関数:その行動は「平均よりどれだけ良いか」
- :状態 で行動 をとった後の期待収益
- :その状態で方策に従ったときの平均
要するに は「この行動は、その場の平均的な行動と比べてどれだけ得か」を表す相対評価です。 なら平均より良い行動なので確率を上げ、 なら下げる。絶対値の収益 ではなく相対値 を使うことで、状態ごとの収益水準のばらつきがキャンセルされ、分散が下がります。優位を使った勾配は:
TD誤差が優位関数の推定になる
も も真の値は未知です。ところがTD誤差(Q学習とSARSAで出た1ステップの予測誤差)が、優位関数の手軽な推定量になります。
真の のもとでは なので、 は優位関数の不偏推定です。つまり Critic が さえ持っていれば、 を別途学ぶ必要なく、TD誤差ひとつで「Criticの自己評価更新」と「Actorの優位による更新」を同時にまかなえます。これが Advantage Actor-Critic(A2C) の中核です。
- Criticの更新: を小さくする方向に を回帰()
- Actorの更新:
flowchart LR
S["状態 s"] --> Actor["Actor(方策 πθ)"]
Actor -->|"行動 a を選ぶ"| Env["環境"]
Env -->|"報酬 r ・ 次状態 s'"| Critic["Critic(価値 Vw)"]
Critic -->|"TD誤差 δ=優位の推定"| Update["更新シグナル"]
Update -->|"δ で方策を補正"| Actor
Update -->|"δ を小さくするよう回帰"| Critic
補足:TD誤差を1ステップで打ち切ると分散は小さいがバイアスが乗り、Nステップ/モンテカルロ寄りにすると不偏だが分散が増えます。このバイアス-バリアンスのつまみを で連続的に調整するのが GAE(Generalized Advantage Estimation) で、PPOの標準装備です。バイアス-バリアンスの考え方自体は教師あり学習と同じ枠組みです。
2. 深層強化学習:価値・方策を関数近似する
ここまでの ・・ は、状態が少なければ表(テーブル)で持てました。しかし状態が画像のように高次元になるとテーブルは破綻します(Q学習とSARSAの関数近似の必要性)。
深層強化学習(Deep RL) は、この ・・ をニューラルネットで近似するアプローチの総称です。画像入力なら畳み込みニューラルネットワークを、系列入力なら系列モデルを特徴抽出器に使います。Actor-Critic はこの関数近似と相性がよく、深層RLの土台になっています。
ただし「テーブルなら収束が保証されたQ学習」をニューラルネットに載せた途端に発散しやすくなる——この不安定性の克服が、以降の DQN・PPO の主題です。
3. DQN:Q学習 + 深層ニューラルネット
DQN(Deep Q-Network) は、Q学習とSARSAのQ学習の をニューラルネット で置き換えたものです。Atariのゲーム画面(生ピクセル)を入力に、人間並みのスコアを出して深層RLブームの火付け役になりました。画面入力の特徴抽出には畳み込みニューラルネットワークを使います。
学習則はQ学習と同じく、ベルマン最適方程式の右辺を目標値(ターゲット) として二乗誤差を最小化します。
なぜ素朴に載せると壊れるのか
ナイーブにこれをやると発散します。原因は2つ:
- サンプルの相関:環境を順番に進めると、連続する は強く相関します。相関したデータで勾配を回すと、直近の状況に過剰適応して学習が偏る(i.i.d.前提が崩れる)。
- 目標が動く(moving target):上式の目標 は 自身を含みます。 を更新すると予測値も目標値も同時に動き、自分の影を追いかけるフィードバックループになって振動・発散します。
2つの安定化技術
| 技術 | 何を解決するか | 仕組み |
|---|---|---|
| 経験再生(experience replay) | サンプルの相関 | 経験 を大きなバッファに貯め、そこからランダムにミニバッチを取り出して学習。時間順を崩し、相関を断つ。データを使い回せるのでサンプル効率も上がる |
| ターゲットネットワーク | 目標が動く問題 | 目標計算用に別のネット を用意し、その重み は普段は固定。数千ステップごとにだけ をコピーする。目標を一定期間凍結することで、追いかけっこを止め発散を防ぐ |
上の損失で目標側を (ターゲットネット)にしているのがその表れです。この2つがDQNの本質で、ネット構造そのものより「いかに学習を壊さないか」の工夫が効いています。問題意識は重み初期化と正規化——深層ネットの学習を発散させずに安定させる——と通じます。
派生(要最新確認):過大評価を抑える Double DQN、重要な経験を優先的に再生する Prioritized Experience Replay、状態価値と優位を分けて推定する Dueling Network などが標準的な改良です。
4. 方策勾配の改良:TRPO と PPO
方策勾配法や A2C には、もう1つの不安定性があります。1回の更新で方策を変えすぎると壊れる問題です。
教師あり学習ならデータは固定ですが、強化学習では方策が変わると集まるデータ自体が変わる。更新が大きすぎて方策が悪い方向に飛ぶと、そこから取れるデータも悪くなり、二度と立て直せないことがあります。そこで「信頼できる範囲でだけ更新する」という発想が出てきます。
TRPO:KL制約付きの信頼領域
TRPO(Trust Region Policy Optimization) は、更新前後の方策の差をKLダイバージェンスで測り、一定以下に抑える制約のもとで代理目的を最大化します。
ここで は重要度比(新旧方策で同じデータを使い回すための補正)。要するに「優位 が正の行動の確率を上げたいが、方策を前から大きく動かしすぎるな」 という制約付き最適化です。理論的には単調改善が保証される一方、二次の制約を解くため計算が重く実装も複雑です。
PPO:比のクリッピングで一次法に簡略化
PPO(Proximal Policy Optimization) は、TRPOの「動かしすぎない」をはるかに簡単に実現した手法で、現在の実務の定番です。制約を陽に解く代わりに、重要度比 をクリッピングして目的関数に組み込みます。
- :新旧方策の確率比。1から離れるほど「変えた」
- :クリップ幅。よく (要最新確認、タスク依存)
要するに、比 が を超えて方策を動かそうとしても、目的関数の改善が頭打ちになるよう天井を付ける——という仕掛けです。 と組み合わせることで、優位が正でも負でも「行きすぎ」に報酬を与えません。これでTRPO並みの安定性を、ただの一次の勾配上昇(標準的なAdam等)で得られます。PPOは中身としては Actor-Critic(優位はGAEで推定)であり、本ノートの流れの集大成です。
flowchart TB
PG["方策勾配(REINFORCE)"] -->|"分散を下げる:優位 A=Q−V"| AC["Actor-Critic(A2C)"]
AC -->|"更新しすぎを防ぐ"| TRPO["TRPO(KL制約の信頼領域)"]
TRPO -->|"制約を比のクリッピングで簡略化"| PPO["PPO(実務の定番)"]
5. RLHF への橋渡し
PPO の応用先として今いちばん重要なのが RLHF(Reinforcement Learning from Human Feedback)——大規模言語モデルを人間の選好に合わせる手続きです(大規模言語モデル 目次のアラインメント)。典型的には3段構成です:
- SFT(教師ありファインチューニング):人手のお手本で土台モデルを整える
- 報酬モデルの学習:人間が「どちらの応答が好ましいか」をランク付けし、それを再現するスカラー報酬 を学習する
- PPOで方策最適化:言語モデルを方策とみなし、報酬モデルのスコアを報酬として PPO で更新。元モデルから離れすぎないようKLペナルティを足す
ここでの対応関係を掴むのがポイントです:
| 強化学習の概念 | RLHFでの中身 |
|---|---|
| 方策(Actor) | 言語モデル(次トークンの分布を出す) |
| 行動 | トークンを1つ出力する |
| 報酬 | 人間の選好を学んだ報酬モデルのスコア |
| 安定化 | PPOのクリッピング + 元モデルとのKLペナルティ |
要するに、人間の好みを報酬という形に変換し、それを最大化する方策をPPOで探す——というのがRLHFです。本ノートのActor-Critic・PPOが、そのまま現代のLLMアラインメントの基盤になっています(詳細は大規模言語モデル 目次)。
⚠️ 要最新確認:RLHFは進展が速く、PPOの代替としてDPO(Direct Preference Optimization) など報酬モデルやRLループを簡略化する手法が広く使われています。最新の主流手法は必ず確認してください。
⚠️ よくある誤解・落とし穴
- 要最新確認(最重要):深層RLは進展が非常に速く、再現性の問題もよく指摘されます。同じアルゴリズムでも実装の細部・乱数シード・ハイパーパラメータで結果が大きく変わることが知られています。本ノートは廃れにくい原理(優位関数・経験再生・ターゲットネット・クリッピング)を中心にしており、具体的なSOTAや数値は要確認です。
- 「DQNは価値ベース、PPOは方策ベース」の取り違え:DQNは を学んで間接的に方策を決める価値ベース。PPOは方策 を直接更新する方策ベース(Actor-Critic)。系統が違います。
- 安定化技術の役割を混同しない:経験再生は「サンプルの相関」を断つもの、ターゲットネットは「目標の移動」を止めるもので、狙う問題が別です。PPOのクリッピングは「方策の更新幅」を抑えるもので、これらとも目的が違います。
- 優位関数 ≠ 報酬: は「平均と比べた相対的な良さ」であって、報酬そのものでも収益そのものでもありません。相対化することで分散を下げているのが本質です。
- TD誤差の符号に注意: が優位の推定になるのは Critic が正確なときの話。Criticが未熟なうちは推定にバイアスが乗ります(だからActorとCriticを交互に育てる)。
まとめ
- Actor-Critic はActor(方策)をCritic(価値)が採点する分業で、優位関数 (実装上はTD誤差)を使ってREINFORCEの高分散を下げる、価値ベースと方策ベースの融合です。
- 深層強化学習は ・・ をニューラルネットで近似して高次元状態を扱うもの。代表が価値ベースのDQNと方策ベースのPPO。
- どちらも本質は安定化:DQN=経験再生+ターゲットネットワーク、PPO=更新幅のクリッピング。PPOはRLHFで言語モデルのアラインメントにそのまま使われています。
- 深層RLは動きが速く再現性も難しい領域。原理を押さえ、最新スペックは都度確認するのが正解です。
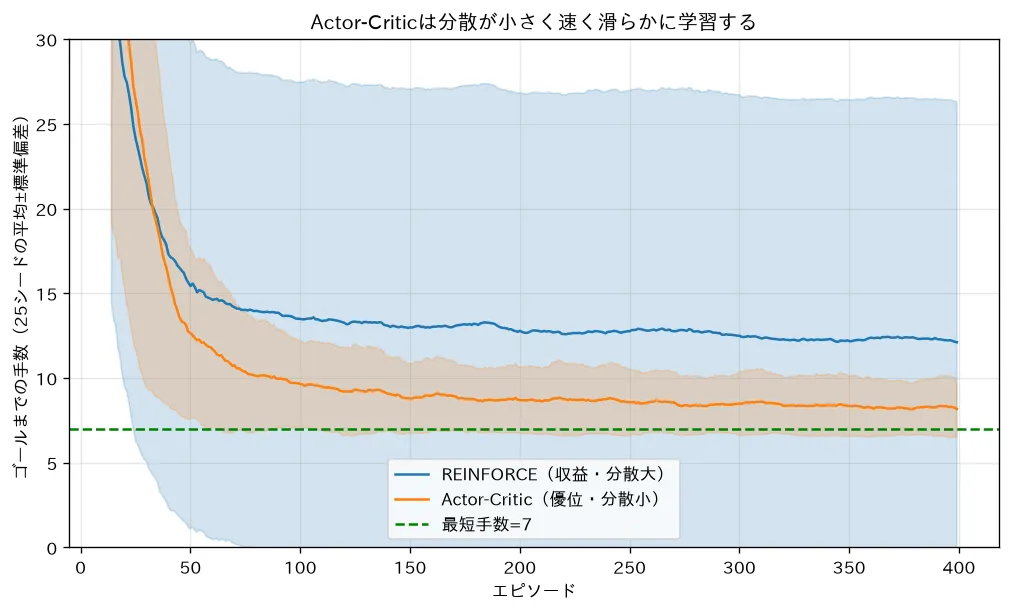
対応するシミュレーション
simulations/actor_critic.py:報酬にノイズを乗せた廊下MDPで、REINFORCE(モンテカルロ収益で更新)とActor-Critic(批評家 を学び TD誤差 =優位で更新)を多数のシードで学習し、学習曲線の平均±標準偏差の帯を比べます。Actor-Critic のほうが速く最短手数へ近づき、シード間のばらつき(帯の幅)も小さい=分散が小さいことを可視化します。A2C・PPO の土台です(方策勾配法)。