🎓 レベル:標準 | 重要度:B(標準)
要点(BLUF)
- 重みの初期スケールは「層をまたいで信号(活性・勾配)の分散が一定に保たれる」ように決める。これが Xavier/He 初期化の正体です。
- sigmoid/tanh には Xavier()、ReLU には He()。ReLU が信号の半分を 0 にする分、係数を 2 倍にして補います。
- バッチ正規化(BatchNorm) は各層の入力をミニバッチで標準化し、学習可能な で戻す仕組み。学習が速くなり初期化に頑健になりますが、学習時と推論時で使う統計量が違う点が落とし穴です。
1. なぜ初期化が重要なのか
深いネットの学習がうまくいくかどうかは、最初の重みのスケールに驚くほど敏感です。理由は 誤差逆伝播法 と 活性化関数 で見た勾配消失/爆発にあります。
順伝播でも逆伝播でも、信号は層を通るたびに「重み行列を掛ける」操作を繰り返します。掛け算の連鎖なので、1 層あたり信号がわずかに縮む(または膨らむ)だけでも、 層重なれば指数的に消失(または発散)します。
- 重みが小さすぎる → 活性も勾配も層ごとに縮み、深い層の勾配が 0 になって学習が進まない(勾配消失)。
- 重みが大きすぎる → 活性も勾配も膨らみ、数値が発散する(勾配爆発)。
- 全部 0(や全部同じ値) → すべてのニューロンが同じ出力・同じ勾配になり、対称性が破れない。何ニューロンあっても 1 個と同じになり、学習が始まりません。
要するに:初期化とは「対称性を破る乱数」かつ「信号が指数的に消えも爆発もしないスケール」を選ぶ作業です。
ここから「ちょうど良いスケール」を分散保存という条件から数式で導きます。
2. Xavier/Glorot 初期化:分散を層をまたいで保つ
順伝播の分散をたどる
1 つのニューロンの入力前活性 を、 本の入力 と重み の和で書きます(バイアスは省略)。
仮定を置きます:重みと入力は独立、どちらも平均 0、各 は同分布、各 も同分布。すると分散は次のように展開できます。
ここで使った事実は2つです。(1) 独立な確率変数の和の分散は分散の和になる。(2) 平均 0 で独立な2変数の積では になる(平均 0 が効いて交差項が消えます)。
層をまたいで分散を一定に保つ、つまり にしたいので、
要するに:入力が 本あって足し合わせる分、1 本あたりの重みの分散を に抑えれば、出力の散らばりが入力と同じになり、層を重ねても信号が一定スケールに保たれます。
逆伝播も考えて折衷する
誤差逆伝播法 で見たように、勾配は逆向きに同じ重み行列を掛けて伝わります。逆伝播で分散を保つには、対称的な議論から
が要求されます。順伝播()と逆伝播()の両方を同時に満たすのは一般に不可能( なら矛盾)なので、Glorot と Bengio は両者の**調和(折衷)**を取りました。
具体的には、一様分布なら区間 から引きます(一様分布の分散が なので、 で辻褄が合います)。
要するに:Xavier は「順と逆の両方向で信号の分散を保つ」よう、入力数と出力数の平均で重みのスケールを決める初期化です。tanh や sigmoid のように原点まわりで線形に近い(微分が 1 付近の)活性化に向きます。
3. He 初期化:ReLU のための補正
Xavier の導出では「活性化が原点まわりで線形(傾き ≈ 1)」を暗に仮定していました。ところが ReLU は なので、入力の半分(負の側)を問答無用で 0 にします。
平均 0 で対称な分布の入力に ReLU を通すと、分散はおよそ半分になります。直観的には「半分のニューロンが死ぬ」ので、出力の散らばりが半減するイメージです。式で書くと、ReLU 通過後の分散は通過前の約 です。
すると分散保存の条件式に の係数が入ります。
これが He(Kaiming)初期化です。Xavier の に対し、ちょうど 2 倍になっています。この 2 倍が、ReLU が削り取る半分をぴったり埋め合わせます。
要するに:ReLU は信号の分散を半分にするので、重みの分散を 2 倍()にして相殺する。ReLU 系(ReLU・Leaky ReLU など)を使うなら He 初期化が標準です。
| 活性化 | 推奨初期化 | 重みの分散 |
|---|---|---|
| tanh / sigmoid | Xavier / Glorot | |
| ReLU / Leaky ReLU | He / Kaiming |
4. バッチ正規化(BatchNorm):層の入力を毎回そろえる
初期化は「学習開始時点」の分散をそろえる対策でした。しかし学習が進むと前の層の重みが動き、各層への入力分布はまた崩れていきます。BatchNorm は学習中、各層の入力を毎ステップ標準化し直すことでこれに対処します。
ミニバッチ (特徴の各次元ごと)に対し、次の4ステップを行います。
- :ミニバッチで平均 0・分散 1 に標準化した値。 は 0 割り防止の微小値。
- (scale)・(shift):学習可能なパラメータ。標準化で失った表現力を取り戻すために置きます。極端には にすれば恒等変換に戻せるので、「標準化が不要なら戻す」自由をネットに与えています。
flowchart LR
X["層への入力 x(ミニバッチ)"] --> M["平均 μ_B を計算"]
X --> V["分散 σ_B^2 を計算"]
M --> N["標準化 x_hat =(x − μ_B)/ √(σ_B^2 + ε)"]
V --> N
N --> S["スケール・シフト y = γ・x_hat + β"]
S --> OUT["次の層へ(活性化へ)"]
G["学習可能 γ(scale)"] --> S
B["学習可能 β(shift)"] --> S
学習時と推論時で統計量が違う(最重要)
ここが BatchNorm 最大の注意点です。
- 学習時:いま流れているミニバッチの統計量 を使う。バッチ内のサンプル同士が結合する(あるサンプルの出力が同じバッチの他サンプルに依存する)。
- 推論時:1 件だけ来ることもありミニバッチ統計が定義できない/ばらつくため、学習中に蓄えた移動平均(母集団統計) を固定値として使う。
flowchart TB
subgraph TRAIN["学習時"]
A1["ミニバッチ統計 μ_B, σ_B^2 を使う"] --> A2["同時に移動平均を更新して蓄積"]
end
subgraph INFER["推論時"]
B1["蓄えた移動平均(母集団統計)を固定で使う"]
end
A2 -. "学習で貯めた統計を引き継ぐ" .-> B1
要するに:学習時は「今のバッチ」で標準化、推論時は「学習中ずっと観測した平均」で標準化。フレームワークの
model.train()/model.eval()切り替えはこの統計量の出し分けを担っており、切り替え忘れは推論結果を壊すバグの定番です。
なぜ効くのか(内部共変量シフト説には議論がある・要最新確認)
原論文(Ioffe & Szegedy, 2015)は「内部共変量シフト(学習中に各層の入力分布が動いてしまう現象)を抑えるから効く」と説明しました。直観的でわかりやすい説明です。
しかし後続研究(Santurkar et al., 2018)はこれに反論しています。わざとノイズを加えて共変量シフトを増やしても BatchNorm の効果は落ちなかったという実験から、「共変量シフトの抑制が効く理由ではない」と主張しました。代わりに提示されたのが損失地形の平滑化(smoothing the loss landscape)という説明です。BatchNorm は損失と勾配のリプシッツ性を改善(-平滑性を高める) し、勾配がより予測可能で滑らかになる——式の上では勾配の大きさを のスケールで抑える——ため、学習率を大きく取れて収束が速くなる、というものです。
実務上の効果として観測されるのは次の3点です。
- 学習率を上げられる(収束が速い)
- 初期化への頑健性が増す(多少ラフな初期化でも学習が進む)
- 軽い正則化効果(ミニバッチごとに統計が揺れるノイズが効く。そのため Dropout を弱める/外すこともある)
⚠️ 要最新確認:「なぜ効くか」は今も決着していない研究テーマです。内部共変量シフト説は直観的入口として有用ですが、それが本質だと断定はできません。
5. LayerNorm:Transformer の定番(要最新確認)
BatchNorm は「バッチ方向(同じ特徴次元を、バッチ内のサンプル間で)」標準化します。一方 LayerNorm は「特徴方向(1 サンプル内の全特徴を)」標準化します。正規化の向きが 90 度違う、と覚えると整理しやすいです。
LayerNorm が系列モデル・Transformer で好まれる理由:
- バッチサイズに依存しない(バッチ 1 でも定義でき、学習時と推論時で計算が同一)。分散学習での同期も不要。
- 系列データに向く(系列長が可変、バッチが小さい、サンプル間を結合させたくない、という NLP の事情に合う)。
⚠️ 要最新確認:近年の LLM では LayerNorm を簡略化した RMSNorm が主流になりつつあり、正規化を層の前に置く Pre-LN 構成が安定とされます。この辺りは動きが速い領域です。詳細は 深層学習アーキテクチャ 目次 側(Transformer)で扱います。
⚠️ よくある誤解・落とし穴
- 「BatchNorm を入れたから学習/推論の区別はいらない」:逆です。BatchNorm を入れた瞬間に区別が必須になります。推論時に
eval()を忘れてミニバッチ統計を使うと、入力 1 件のときに統計が無意味になり結果が崩れます。 - 「バッチが小さくても BatchNorm でOK」:小バッチでは の推定がノイジーになり、学習が不安定化・性能劣化します。検出やセグメンテーションのように画像が大きくバッチを大きく取れない場面で顕在化します。こういう場面は LayerNorm / GroupNorm 等を検討します。
- 「良い初期化さえすれば正規化はいらない/正規化を入れれば初期化は適当でいい」:両方とも信号スケールを保つ対策ですが、役割が違います。初期化は開始時点のスケールを、正規化は学習が進んだ後のスケールを整えます。深いネットでは両方が効きます。
- 活性化と初期化のミスマッチ:ReLU に Xavier を使うと(係数 2 が足りず)信号が層ごとに縮みがちです。活性化に合わせて初期化を選ぶのが鉄則です(活性化関数 参照)。
まとめ
- 初期化の本質は分散保存:順・逆伝播で信号の分散を一定に保つようスケールを選ぶ。tanh/sigmoid は Xavier()、ReLU は He(、半分死ぬ分を 2 倍で補正)。
- BatchNorm は学習中に各層入力を標準化し で戻す。学習を加速し初期化に頑健にするが、学習時=ミニバッチ統計/推論時=移動平均の出し分けが必須。
- 「なぜ効くか」は内部共変量シフト説より損失地形の平滑化説が有力視されるが未決着(要最新確認)。系列・Transformer では LayerNorm が定番(同じく要最新確認)。
対応するシミュレーション
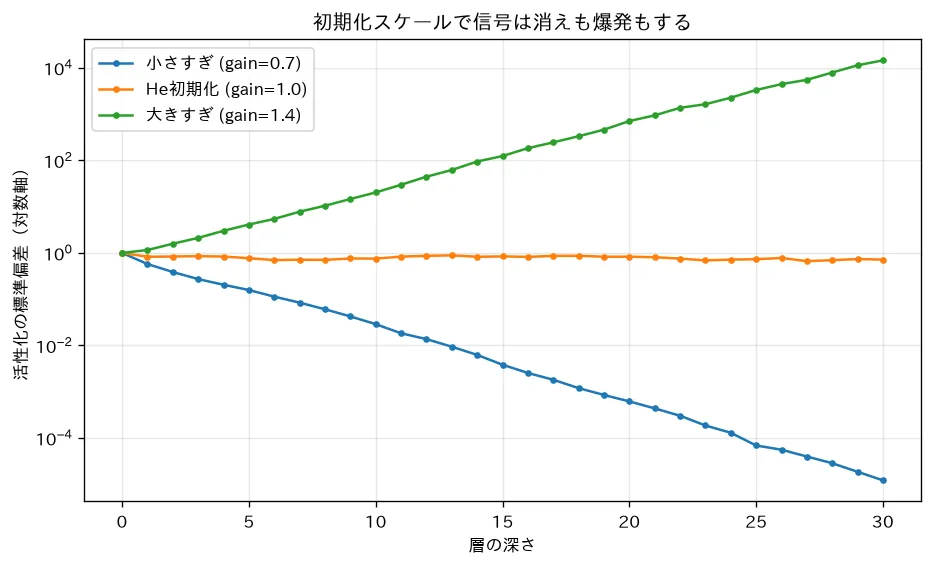
simulations/init_and_vanishing.py:30層の深いネットワーク(ReLU)に入力を順伝播させ、層ごとの活性化の標準偏差を測ります。初期化スケールが小さすぎると信号が層を経るごとに へ消え、大きすぎると爆発するのに対し、He初期化(分散 )なら活性化の大きさが深さを通じてほぼ保たれることを対数軸で確認できます。BatchNorm が初期化への過敏さを別角度から緩和する話とも対応します。
関連ノート
- ニューラルネットワーク 目次
- 誤差逆伝播法(勾配が層をまたいで掛け算で伝わる仕組み)
- 活性化関数(ReLU が分散を半減させる・勾配消失)
- モーメンタムとAdam系最適化(平滑な地形で学習率を上げられることと最適化の関係)
- 機械学習テキスト 全体目次