🎓 レベル:基礎 | 重要度:A(必須)
📎 前提:パーセプトロンと多層パーセプトロン | 関連:誤差逆伝播法(勾配消失はここで効く)
要点(BLUF)
- 活性化関数は各ニューロンの出力に非線形をかける関数。これが無いと、層を何枚重ねても結局1枚の線形変換にしかならず、隠れ層の意味が消えます。
- 古典的な sigmoid/tanh は飽和領域で微分がほぼ0になり、深い網で勾配が消える(勾配消失)。
- ReLU は正領域で微分が1なので勾配消失を緩和し、計算も軽い。ただし負領域で死ぬ(dying ReLU)。これを補うのが Leaky ReLU・ELU・GELU などの派生です。
1. なぜ非線形が必要か
結論:線形変換を重ねても、それは1つの線形変換にすぎないからです。
隠れ層が2層あり、活性化が無い(恒等写像 )場合を考えます。重みを 、バイアスを省略すると、
要するに:2層が という1つの行列に潰れます。何層重ねても表現できるのは線形関数だけで、層を深くする意味がありません。
ここに非線形 を挟むと、
となり、 が線形でない限りこの合成は1つの行列にまとめられません。非線形こそが「深さ」を意味あるものにする、つまり多層パーセプトロンが複雑な関数を近似できる源泉です(パーセプトロンと多層パーセプトロン の普遍近似はこの非線形性に依存します)。
補足:「非線形ならなんでもよい」のではありません。微分しやすく(誤差逆伝播法 で勾配を流す)、勾配が消えにくく、計算が軽いものが好まれます。以下の関数選びはすべてこの3条件のトレードオフです。
2. sigmoid
- 出力は に収まり、「確率っぽい」値として解釈できます(ロジスティック回帰 と同じ関数)。
- 微分は 。 のとき最大で 、それ以外では必ずそれより小さくなります。
要するに:sigmoid の微分はどんな入力でも 0.25 以下。さらに が大きい/小さい(飽和領域)では が 0 か 1 に張り付き、 になります。これが後述の勾配消失の主犯です。
もう1つの弱点は出力がすべて正(ゼロ中心でない)こと。ある層の出力がすべて正だと、次の層の重みに流れる勾配の符号が揃ってしまい、更新がジグザグになって収束が遅くなります。
3. tanh
- 出力は でゼロ中心。sigmoid のジグザグ問題が緩和され、一般に sigmoid より学習しやすいです。
- 微分は で最大 (sigmoid の 0.25 より大きい)。
要するに:tanh は「ゼロ中心の sigmoid」。中心付近では sigmoid より勾配が大きく学習しやすいものの、飽和すれば微分は同じく 0 に近づくので、勾配消失そのものは解決しません。実際 という関係があり、両者は本質的に同じ S 字飽和型です。
4. ReLU(Rectified Linear Unit)
( では微分は定義されませんが、実装上は 0 か 1 を割り当てます。)
ReLU の利点は3つです。
- 勾配消失を緩和:正領域では微分がつねに 1。深い網でも勾配がそのまま流れます(後述)。
- 計算が軽い:指数関数が不要で
max一発。 - 疎な活性化:負の入力は 0 になるので、一部のニューロンだけが発火する疎な表現になります。
一方の弱点が dying ReLU 問題です。 では微分が 0。あるニューロンが学習中に常に負の入力を受ける状態に陥ると、誤差逆伝播法 の勾配が 0 のまま流れ、重みが二度と更新されず「死んだ」ままになります。大きすぎる学習率や偏った初期化で起きやすく、多数のニューロンが死ぬと網の表現力が落ちます。
なぜ起きるか:勾配は出力側から として伝わってきますが、ReLU の微分 0 がそれを完全に遮断します。一度ゼロ出力に落ちると入力側へ「お前を直せ」という信号が届かないので、自力で復活できないのです。
5. ReLU の派生
dying ReLU と「ゼロ中心でない」を補うために、負領域に小さな傾きを与える派生が多数あります。
| 関数 | 定義( 側) | 狙い |
|---|---|---|
| Leaky ReLU | ( は固定の小さな正数、例 0.01) | 負領域でも微小な勾配 を残し「死」を防ぐ |
| PReLU | ( を学習で最適化) | 傾きをデータに合わせて調整 |
| ELU | 負領域を滑らかにし、出力平均をゼロに寄せる | |
| GELU | 入力を「通すか/消すか」を確率的にゲートする滑らかなReLU | |
| Swish / SiLU | sigmoid をゲートに使った滑らかなReLU |
GELU(Gaussian Error Linear Unit) は Transformer 系で定番の活性化です(要最新確認)。標準正規分布の累積分布関数 を使い、
と定義されます( はガウス誤差関数)。実装では tanh による近似式
がよく使われます。要するに:ReLU が「正なら通す/負なら 0」と硬く切るのに対し、GELU は「入力の大きさに応じて確率的に通す割合を決める」滑らかなゲートです。 で なので ReLU に近づき、 で なので 0 に近づきます。原点付近が滑らかで微分が途切れない点が ReLU より優れます。
Swish / SiLU は 。SiLU(Sigmoid Linear Unit)は係数なし、Swish は と を持つ一般形です。GELU と同じく「線形 × ゲート」の形で、近年の大規模モデルでは Swish のゲート付き派生 SwiGLU が GELU を上回るという報告もあります(要最新確認。生成・LLM領域は変化が速いので採用前に最新を確認してください)。
6. 勾配消失問題のメカニズム
ここが活性化関数選びの核心です。誤差逆伝播法 では、第 層の誤差 が出力側から次の再帰で伝わります(記号は誤差逆伝播のノートに準拠)。
これを入力側まで展開すると、各層の活性化の微分 が積で掛かります。 層を遡ると、ざっくり
要するに:sigmoid のように だと、層を1枚遡るごとに勾配が最大でも に減ります。10 層あれば で、入力に近い層の勾配はほぼ消滅します。これが勾配消失で、深い網で前段がまったく学習しなくなる現象の正体です。
ReLU が効く理由はここで明確になります。正領域では なので、いくつ層を重ねても勾配が 1 のまま遮られずに伝わり、 が指数的に潰れません。「ReLU は勾配消失を緩和する」とは、まさにこの の積が小さくならないことを指します。
flowchart TB
subgraph S["sigmoid/tanh:勾配消失"]
A1["出力層の勾配 1.0"] --> A2["× φ' ≤ 0.25"]
A2 --> A3["前層 ≈ 0.25"]
A3 --> A4["× φ' ≤ 0.25"]
A4 --> A5["前々層 ≈ 0.06"]
A5 --> A6["入力側 ≈ 0(消失)"]
end
subgraph R["ReLU:勾配が保たれる"]
B1["出力層の勾配 1.0"] --> B2["× φ' = 1(正領域)"]
B2 --> B3["前層 ≈ 1.0"]
B3 --> B4["× φ' = 1"]
B4 --> B5["入力側 ≈ 1.0(保たれる)"]
end
注意:勾配消失は活性化だけの問題ではなく、重みの大きさにも依存します。重みが大きすぎれば逆に勾配が爆発します(勾配爆発)。活性化の選択に加え、適切な初期化や正規化で対処します → 重み初期化と正規化。
活性化関数の系統マップ
graph TD
Root["活性化関数"] --> Sat["飽和型(S字)"]
Root --> Piece["区分線形・非飽和型"]
Sat --> Sig["sigmoid:0〜1・微分 ≤ 0.25・非ゼロ中心"]
Sat --> Tanh["tanh:-1〜1・ゼロ中心・最大微分 1"]
Sig -.->|"飽和で勾配消失"| Problem["勾配消失問題"]
Tanh -.->|"飽和で勾配消失"| Problem
Piece --> ReLU["ReLU:max(0, z)・正領域 φ'=1"]
ReLU -->|"勾配消失を緩和"| Good["深い網で学習可能"]
ReLU -.->|"負領域 φ'=0"| Dead["dying ReLU"]
Dead --> Leaky["Leaky ReLU/PReLU:負側に傾き α"]
Dead --> ELU["ELU:負側を滑らかに"]
ReLU --> Smooth["GELU/Swish:滑らかなゲート型"]
Smooth -->|"Transformer で定番(要最新確認)"| Modern["近年の主流"]
7. 出力層の活性化は別もの
ここまでは隠れ層の話です。出力層の活性化は「何を予測したいか」で決まり、隠れ層とは選び方が異なります。
- 2値分類:sigmoid(出力を1つの確率 に)→ ロジスティック回帰 と同じ。
- 多クラス分類:softmax(各クラスの確率に正規化し、和を1にする)。
- 回帰:恒等写像(活性化なし。実数値をそのまま出す)。
要するに:隠れ層は「勾配を流す」ための非線形(ReLU 系が主流)、出力層は「予測の形に合わせる」ための変換(softmax・恒等など)。役割が違うので混同しないでください。なお softmax は出力を確率にするための変換で、隠れ層の非線形性とは目的が別です。
⚠️ よくある誤解・落とし穴
- 「ReLU を使えば常に最善」ではない:ReLU は隠れ層の万能薬ではありません。RNN 系では tanh が好まれる場面があり、Transformer では GELU/Swish が標準。出力層に ReLU を使うのも誤りです。タスクとアーキテクチャで選びます。
- 「飽和」と「ゼロ中心でない」は別の欠点:sigmoid は両方を抱えますが、原因は別です。飽和 → 勾配消失、非ゼロ中心 → 更新のジグザグ。tanh はゼロ中心化で後者だけを解決し、飽和(前者)は残ります。区別して理解してください。
- dying ReLU を勾配消失と同一視しない:勾配消失は「飽和で が小さい」、dying ReLU は「負領域で がちょうど 0 になりニューロンが死ぬ」。前者は値が小さいだけ、後者は完全にゼロで復活不能、という違いがあります。
- 隠れ層と出力層を同じ基準で選ばない:上記のとおり目的が違います。「分類の出力に ReLU」「回帰の出力に sigmoid」は典型的な誤り。
- GELU/Swish は領域が動きやすい:生成モデル・LLM 周りの活性化(SwiGLU など)は流行り廃りが速いです。採用時は最新の知見を確認してください(要最新確認)。
対応するシミュレーション
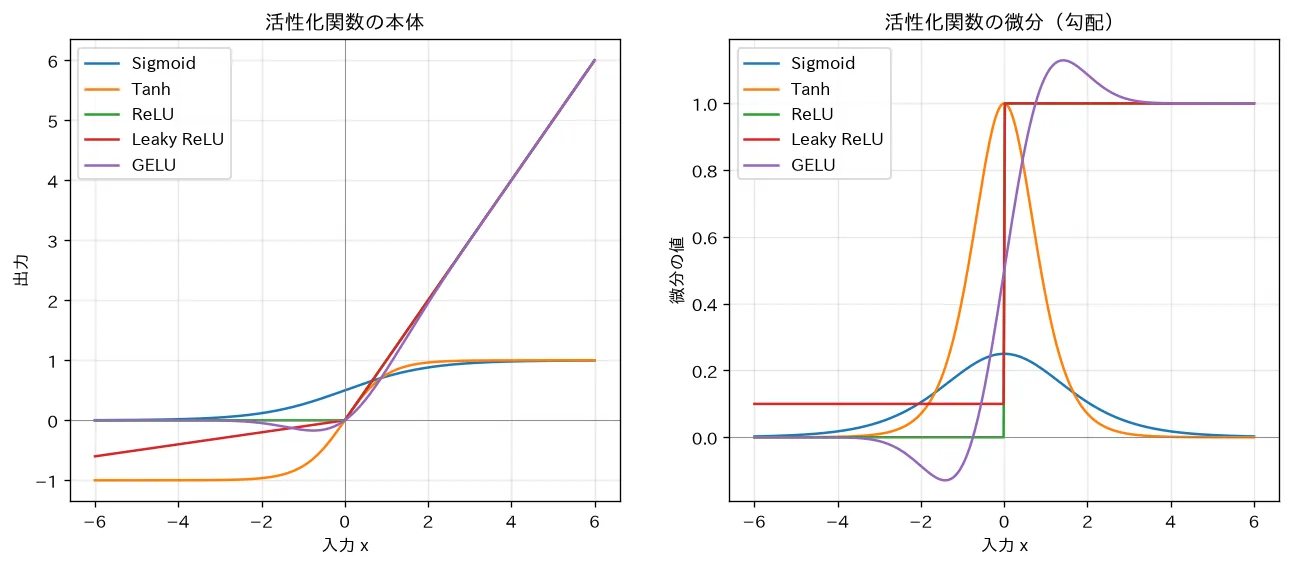
simulations/activation_functions.py:sigmoid・tanh・ReLU・Leaky ReLU・GELU を関数本体と微分の両方で並べてプロットします。sigmoid/tanh は入力の絶対値が大きい領域で微分が に潰れる(飽和=勾配消失の原因)のに対し、ReLU 系は正の領域で微分が を保つことを、グラフと数値( での微分値)で確認できます。
関連ノート
- ニューラルネットワーク 目次(このドメインの目次)
- パーセプトロンと多層パーセプトロン(非線形性が深さに意味を与える土台)
- 誤差逆伝播法(勾配消失は の再帰で効く)
- 重み初期化と正規化(勾配消失・爆発への対処)
- ロジスティック回帰(sigmoid と確率的解釈の出発点)
- 機械学習テキスト 全体目次