🎓 レベル:基礎 | 重要度:A(必須)
要点(BLUF)
- パーセプトロンは「重み付き和 を活性化関数に通す」たった1個のニューロンで、その正体はロジスティック回帰とほぼ同じです。
- 単層では線形分離可能な問題しか解けません。その象徴が XOR問題(Minsky & Papert, 1969)で、これが第一次ニューラルネット冬の時代の引き金になりました。
- 隠れ層を挟んで非線形変換を重ねた 多層パーセプトロン(MLP) は、万能近似定理により「1隠れ層でも十分なユニットがあれば任意の連続関数を任意精度で近似できる」ほど表現力が高い。ただし「近似できる」と「勾配降下で学習できる」は別問題です。
1. パーセプトロン:1個のニューロン
パーセプトロンは、入力 に重み を掛けて足し、バイアス を加え、活性化関数 に通すだけのモデルです。
ここで を重み付き和(あるいはプレ活性, pre-activation) と呼びます。 が出力の形を決めます。
- 要するに:「入力を線形に混ぜて、1つの非線形関数に通す」だけです。これ以上でも以下でもありません。
flowchart LR
X1["x1"] --> S(("Σ"))
X2["x2"] --> S
X3["x3"] --> S
B["バイアス b"] --> S
S --> Z["重み付き和 z = wᵀx + b"]
Z --> A["活性化 φ(z)"]
A --> Y["出力 ŷ"]
ロジスティック回帰との対応
活性化 にシグモイド を選ぶと、
これはロジスティック回帰そのものです。つまり1ニューロンのニューラルネットは、見慣れた線形分類器の言い換えにすぎません。
-
元祖のローゼンブラットのパーセプトロン(1958)は をステップ関数( で 、さもなくば )にしたもので、出力が にカチッと割れます。微分できないので、後の勾配学習にはシグモイドや活性化関数で扱う滑らかな関数を使います。
-
要するに:パーセプトロンは新しい魔法ではなく、「ニューロン」という言葉でロジスティック回帰を捉え直したものです。ここを起点に層を積むのが NN の物語です。
2. 単層の限界:XOR問題
単層パーセプトロン(入力 → 出力の1段だけ)が表せる決定境界は、 という1本の超平面です。したがって線形分離可能な問題しか解けません。
線形分離可能とは「2クラスを1本の直線(高次元なら超平面)でスパッと分けられる」状態のことです。AND・OR はこれを満たすので単層で解けます。ところが XOR(排他的論理和) は満たしません。
| XOR | ||
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
クラス1の点 とクラス0の点 は、1本の直線では決して分離できません(どう引いても片側に両クラスが混ざる)。これを XOR問題 と呼びます。
graph TD
subgraph XOR["XOR: 1本の直線では分離不可能(線形分離不可能)"]
P00["(0,0) → 0"]
P11["(1,1) → 0"]
P01["(0,1) → 1"]
P10["(1,0) → 1"]
end
note["どこに直線を引いても<br/>クラス0とクラス1が同じ側に混ざる"]
Minsky & Papert は著書『Perceptrons』(1969)でこの限界を数学的に証明しました。「単層パーセプトロンには本質的な壁がある」という結論が、ニューラルネット研究の停滞(第一次AI冬の時代)を招きます。
- 要するに:直線1本しか引けない以上、直線で分けられないものは原理的に無理。XOR はその最小の反例です。
3. 多層パーセプトロン(MLP):隠れ層で壁を越える
XOR を解く鍵は、入力と出力の間に 隠れ層(hidden layer) を挟むことです。隠れ層が入力を別の空間に非線形変換し、その空間で線形分離可能にしてしまう。これが MLP の核心です。
層の MLP は、層ごとに「線形変換 → 活性化」を繰り返します。第 層の出力(隠れ表現)を とすると、
ここで は第 層の重み行列、 はバイアスベクトル、 は要素ごとに作用する活性化関数です。最終層 が予測 になります。
- 要するに:「線形に混ぜて曲げる」を何段も重ねるだけ。1段がロジスティック回帰なら、MLP はロジスティック回帰を積み木のように積み上げたものです。
graph LR
subgraph Input["入力層"]
I1["x1"]
I2["x2"]
end
subgraph Hidden["隠れ層 h⁽¹⁾ = φ(W⁽¹⁾x + b⁽¹⁾)"]
H1["h1"]
H2["h2"]
end
subgraph Output["出力層 ŷ = φ(W⁽²⁾h + b⁽²⁾)"]
O1["ŷ"]
end
I1 --> H1
I1 --> H2
I2 --> H1
I2 --> H2
H1 --> O1
H2 --> O1
なぜ隠れ層で非線形が表せるのか
ポイントは活性化関数 が非線形であることです。隠れ層が新しい特徴 を作り、出力層はその新しい特徴空間で線形分離します。XOR なら、たとえば隠れユニットに「OR」と「NAND」を学習させ、出力層でそれらの「AND」を取れば XOR が組めます()。
- 古典的な線形手法(ロジスティック回帰やサポートベクターマシン(SVM))では、非線形にしたければ人手で特徴量(多項式項やカーネル)を設計する必要がありました。MLP は隠れ層がこの「効く特徴」をデータから自動で学習します。これが 特徴の自動学習(表現学習) と呼ばれる NN の最大の利点です。
- これらの重み をデータから決める仕組みが誤差逆伝播法であり、その更新を回すエンジンが勾配降下法です。
4. 万能近似定理(Universal Approximation Theorem)
MLP の表現力を保証するのが 万能近似定理 です。直感的には「隠れ層が1枚あって、ユニットを十分たくさん並べれば、どんな連続関数でも好きなだけ正確に真似できる」という主張です。
Cybenko(1989) の定理(おおよその形):
をコンパクト集合、 を任意の連続関数、 をシグモイド型(非多項式)の活性化関数とする。任意の に対し、適切な有限個のユニット数 と重み 、係数 を選べば、1隠れ層ネットワーク が を満たす。
- 要するに:「 の S 字をたくさん足し合わせれば、コンパクト領域上のどんな連続曲線も一様ノルムで(上限誤差を)いくらでも小さく近似できる」。シグモイドという部品で関数を“タイル張り”するイメージです。
歴史的には Cybenko(シグモイド、Hahn–Banach の定理を使った証明)、Hornik–Stinchcombe–White(1989)、Funahashi(1989) がほぼ同時に独立に示しました。さらに Hornik(1991) は「鍵は活性化関数の具体的な選び方ではなく、多層フィードフォワードという構造そのものにある」ことを示しています(非多項式なら何でもよい)。
「広さ」だけでなく「深さ」も効く(深さの効率)
1隠れ層で十分という定理は存在の保証であって、効率(必要ユニット数)の保証ではありません。実は同じ関数を表すのに、
- 浅く広く:ユニット数が指数的に必要になることがある
- 深く積む:多項式個のユニットで済むことがある
Telgarsky(2015〜16) は、深さ ・幅一定の ReLU ネットなら表せる「のこぎり波(sawtooth)」関数を、浅い(深さ2の)ネットで近似しようとすると幅が について指数的に必要になる、という深さ分離(depth separation) を構成的に示しました。
- 要するに:「1枚でも原理的には足りる」けれど、「深くするとはるかに少ないユニットで同じ表現が得られる」。これが深層学習が浅い MLP より好まれる理論的な理由の一つです。
graph TD
UAT["万能近似定理: 1隠れ層 + 十分なユニット → 任意の連続関数を近似可能"]
UAT --> E["存在の保証であって…"]
E --> N1["どれだけのユニット数が要るかは言わない"]
E --> N2["勾配降下で重みを見つけられるかは言わない"]
E --> N3["未知データへの汎化は言わない"]
UAT --> D["深さの効率: 深く積むと同じ関数を少ないユニットで表せる(Telgarsky)"]
5. ⚠️ よくある誤解・落とし穴
- 「万能近似=何でも学習できる」ではない。定理が言うのは「そういう重みが存在する」ことだけです。その重みを勾配降下法で実際に見つけられる保証はありません(最適化は非凸で、局所解や鞍点にはまり得る)。「表現できること(representability)」と「学習できること(learnability)」は別物です。
- 近似誤差を小さくする話と、汎化の話は別。訓練データ上でいくら正確に近似できても、未知データで当たるか(汎化理論)は別問題です。ユニットを増やして表現力を上げると、むしろ過学習しやすくなります(正則化の理論で抑える)。
- 活性化が線形だと多層の意味が消える。 が恒等写像(線形)だと、 のように何層重ねても1つの線形変換に潰れます。隠れ層が効くのは が非線形だからこそ。だから活性化関数の選択(ReLU など)が決定的に重要です。
- 「1隠れ層で十分」を実務の設計指針と取り違えない。定理は1層で足りると言いますが、第4節のとおり実際には深くした方が圧倒的に効率的・学習しやすいことが多い。理論の存在保証と、実務の設計は分けて考えます。
- パラメータ数 ≠ 性能。隠れユニットを闇雲に増やせば近似誤差は下がりますが、データ量とのバランス(ハイパーパラメータ最適化)を欠くと汎化が崩れます。
まとめ
パーセプトロンはロジスティック回帰を「ニューロン」として捉え直したもので、単層では線形分離可能な問題(XOR が反例)しか解けません。隠れ層を挟んだ MLP は非線形変換を重ねて表現力と特徴の自動学習を獲得し、万能近似定理がその表現力を理論的に裏付けます。ただし定理は「存在」の保証であって、「勾配降下で学習できる」「汎化する」は別問題。次は、その重みを実際に決める仕組み=誤差逆伝播法へ進みます。
対応するシミュレーション
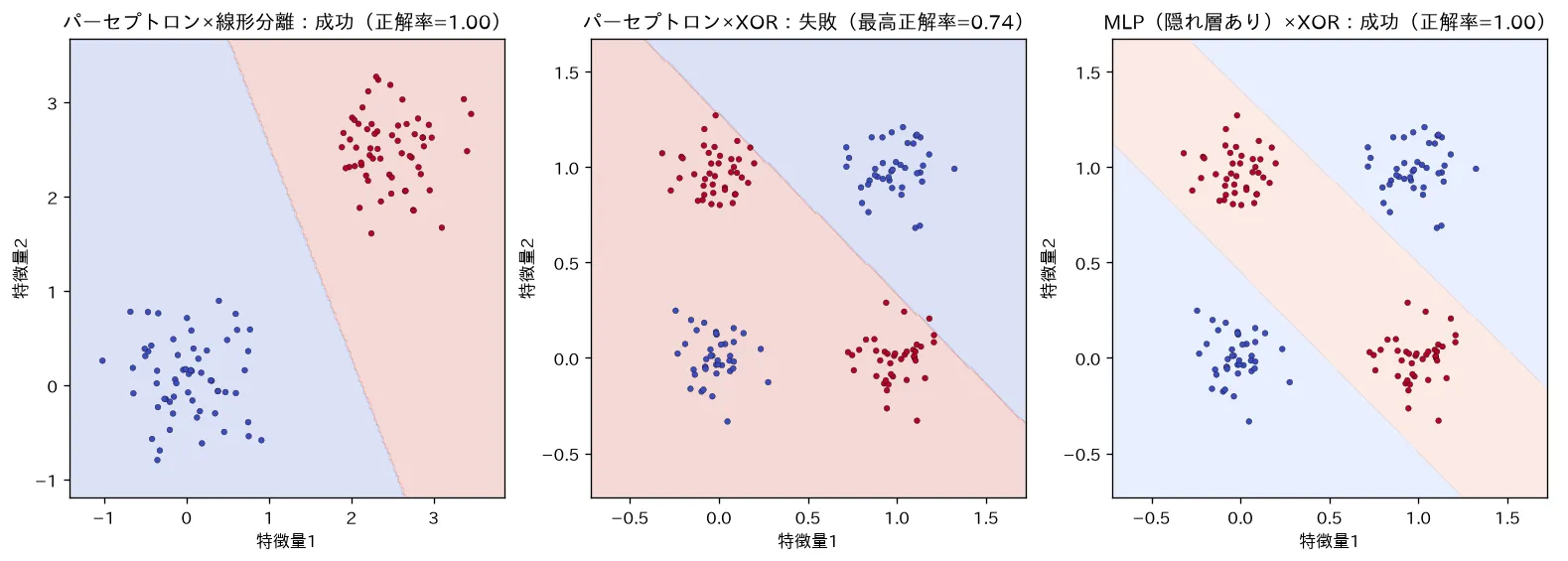
simulations/perceptron_xor.py:単層パーセプトロンの学習則を手実装し、(1) 線形分離できる2クラス(正解率1.0で成功)、(2) XOR(最良の直線でも上限 で失敗)、(3) 隠れ層ありのMLP(XORを正解率1.0で解決)を比較します。1本の直線では XOR を分けられないが、層を重ねると非線形の境界を引けて解ける、という「層を重ねる意味」の最小実例です(学習は 誤差逆伝播法)。
関連ノート
- ニューラルネットワーク 目次 — このドメインの目次
- 誤差逆伝播法 — MLP の重みを学習する仕組み(次トピック)
- 活性化関数 — 非線形性の源。ステップ/シグモイド/ReLU
- ロジスティック回帰 — 1ニューロンの原型
- 勾配降下法 — 重みを更新する学習エンジン
- 深層学習アーキテクチャ 目次 — 「深さ」を活かす次の層
- 機械学習テキスト 全体目次 — 全ドメインのハブ