← 機械学習テキスト 一覧
🎓 レベル:発展 | 重要度:A(必須)
📎 前提:価値関数とベルマン方程式 | 関連:誤差逆伝播法 (勾配)
要点(BLUF)
方策そのもの π θ ( a ∣ s ) \pi_\theta(a\mid s) π θ ( a ∣ s ) J ( θ ) J(\theta) J ( θ ) 勾配上昇 で直接最大化する手法です。価値を経由しません。核心は方策勾配定理 ∇ θ J = E [ ∇ θ log π θ ( a ∣ s ) Q π ( s , a ) ] \nabla_\theta J = \mathbb{E}\!\left[\nabla_\theta\log\pi_\theta(a\mid s)\,Q^\pi(s,a)\right] ∇ θ J = E [ ∇ θ log π θ ( a ∣ s ) Q π ( s , a ) ]
Q Q Q REINFORCE 。高分散なのでベースライン を引き、最終的に優位関数 A = Q − V A=Q-V A = Q − V
1. なぜ価値ベースでは足りないのか
Q学習とSARSA のような価値ベースの手法は「各 ( s , a ) (s,a) ( s , a ) Q ( s , a ) Q(s,a) Q ( s , a ) arg max a Q \arg\max_a Q arg max a Q
連続行動空間が苦手 :arg max a Q ( s , a ) \arg\max_a Q(s,a) arg max a Q ( s , a ) a a a 確率的方策を表現できない :価値ベースは決定的方策(ε \varepsilon ε わざと確率的に振る舞うのが最適 な状況や、部分観測(POMDP)で最適方策が確率的になる状況を素直に表せません。方策の微小変化に弱い :Q Q Q arg max \arg\max arg max
そこで発想を変えます。価値を経由せず、方策そのものをパラメータ θ \theta θ として置き、θ \theta θ
π θ ( a ∣ s ) = (パラメータ θ を持つ、状態 s で行動 a を取る確率) \pi_\theta(a\mid s) \;=\; \text{(パラメータ }\theta\text{ を持つ、状態 }s\text{ で行動 }a\text{ を取る確率)} π θ ( a ∣ s ) = (パラメータ θ を持つ、状態 s で行動 a を取る確率) 実装上は、離散行動なら NN の出力をソフトマックスに通し、連続行動ならガウス分布の平均・分散を NN で出す、という形が定番です。
graph LR
subgraph V["価値ベース"]
V1["状態 s"] --> V2["Q(s,a) を学習"]
V2 --> V3["argmax_a Q を取る(間接)"]
end
subgraph P["方策ベース(方策勾配)"]
P1["状態 s"] --> P2["π_θ(a|s) を直接出力"]
P2 --> P3["勾配上昇で θ を更新(直接)"]
end
2. 目的関数と勾配上昇
最大化したいのは、方策 π θ \pi_\theta π θ τ = ( s 0 , a 0 , s 1 , a 1 , … ) \tau = (s_0, a_0, s_1, a_1, \dots) τ = ( s 0 , a 0 , s 1 , a 1 , … ) 期待リターン です。
J ( θ ) = E τ ∼ π θ [ G ( τ ) ] , G ( τ ) = ∑ t = 0 T γ t r t J(\theta) \;=\; \mathbb{E}_{\tau\sim\pi_\theta}\!\big[G(\tau)\big],
\qquad G(\tau)=\sum_{t=0}^{T}\gamma^{t}\,r_t J ( θ ) = E τ ∼ π θ [ G ( τ ) ] , G ( τ ) = t = 0 ∑ T γ t r t そして J J J J J J 勾配上昇 を使います。
θ ← θ + α ∇ θ J ( θ ) \theta \;\leftarrow\; \theta + \alpha\,\nabla_\theta J(\theta) θ ← θ + α ∇ θ J ( θ )
要するに:「うまくいく軌道が出やすくなる方向」に θ \theta θ ∇ θ J \nabla_\theta J ∇ θ J J J J θ \theta θ
3. 方策勾配定理の導出(省略なし)
3.1 軌道の確率を書き下す
方策 π θ \pi_\theta π θ τ \tau τ
p θ ( τ ) = ρ ( s 0 ) ⏟ 初期分布 ∏ t = 0 T π θ ( a t ∣ s t ) ⏟ 方策( θ 依存) p ( s t + 1 ∣ s t , a t ) ⏟ 遷移( θ 非依存) p_\theta(\tau) \;=\; \underbrace{\rho(s_0)}_{\text{初期分布}}\;\prod_{t=0}^{T}\;\underbrace{\pi_\theta(a_t\mid s_t)}_{\text{方策(}\theta\text{依存)}}\;\underbrace{p(s_{t+1}\mid s_t,a_t)}_{\text{遷移(}\theta\text{非依存)}} p θ ( τ ) = 初期分布 ρ ( s 0 ) t = 0 ∏ T 方策( θ 依存) π θ ( a t ∣ s t ) 遷移( θ 非依存) p ( s t + 1 ∣ s t , a t ) ここが導出の要です。θ \theta θ 方策の項だけ で、初期分布 ρ \rho ρ p p p θ \theta θ
3.2 log-derivative trick(スコア関数のトリック)
目的関数の勾配を素直に書くと、期待値の中身ではなく分布そのもの p θ p_\theta p θ θ \theta θ
∇ θ J ( θ ) = ∇ θ ∫ p θ ( τ ) G ( τ ) d τ = ∫ ∇ θ p θ ( τ ) G ( τ ) d τ \nabla_\theta J(\theta)
= \nabla_\theta \int p_\theta(\tau)\,G(\tau)\,d\tau
= \int \nabla_\theta p_\theta(\tau)\,G(\tau)\,d\tau ∇ θ J ( θ ) = ∇ θ ∫ p θ ( τ ) G ( τ ) d τ = ∫ ∇ θ p θ ( τ ) G ( τ ) d τ ここで恒等式 ∇ θ p θ = p θ ∇ θ log p θ \nabla_\theta p_\theta = p_\theta\,\nabla_\theta\log p_\theta ∇ θ p θ = p θ ∇ θ log p θ log-derivative trick 。∇ log f = ∇ f / f \nabla\log f = \nabla f / f ∇ log f = ∇ f / f p θ p_\theta p θ 期待値の形 に戻せます。
∇ θ J ( θ ) = ∫ p θ ( τ ) ∇ θ log p θ ( τ ) G ( τ ) d τ = E τ ∼ π θ [ ∇ θ log p θ ( τ ) G ( τ ) ] \nabla_\theta J(\theta)
= \int p_\theta(\tau)\,\nabla_\theta\log p_\theta(\tau)\,G(\tau)\,d\tau
= \mathbb{E}_{\tau\sim\pi_\theta}\!\big[\nabla_\theta\log p_\theta(\tau)\,G(\tau)\big] ∇ θ J ( θ ) = ∫ p θ ( τ ) ∇ θ log p θ ( τ ) G ( τ ) d τ = E τ ∼ π θ [ ∇ θ log p θ ( τ ) G ( τ ) ]
要するに:このトリックのおかげで「分布を微分する」問題が「サンプルした軌道の ∇ log p \nabla\log p ∇ log p
3.3 遷移確率と初期分布が消える
次に ∇ θ log p θ ( τ ) \nabla_\theta\log p_\theta(\tau) ∇ θ log p θ ( τ ) log \log log
∇ θ log p θ ( τ ) = ∇ θ log ρ ( s 0 ) ⏟ = 0 + ∑ t = 0 T [ ∇ θ log π θ ( a t ∣ s t ) + ∇ θ log p ( s t + 1 ∣ s t , a t ) ⏟ = 0 ] \nabla_\theta\log p_\theta(\tau)
= \underbrace{\nabla_\theta\log\rho(s_0)}_{=\,0}
+ \sum_{t=0}^{T}\Big[\nabla_\theta\log\pi_\theta(a_t\mid s_t)
+ \underbrace{\nabla_\theta\log p(s_{t+1}\mid s_t,a_t)}_{=\,0}\Big] ∇ θ log p θ ( τ ) = = 0 ∇ θ log ρ ( s 0 ) + t = 0 ∑ T [ ∇ θ log π θ ( a t ∣ s t ) + = 0 ∇ θ log p ( s t + 1 ∣ s t , a t ) ] ρ \rho ρ p p p θ \theta θ 遷移ダイナミクスが綺麗に消えます 。残るのは方策の項だけです。
∇ θ log p θ ( τ ) = ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) \boxed{\;\nabla_\theta\log p_\theta(\tau) = \sum_{t=0}^{T}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\;} ∇ θ log p θ ( τ ) = t = 0 ∑ T ∇ θ log π θ ( a t ∣ s t )
要するに:これがモデルフリーで方策勾配が計算できる理由 です。環境の遷移確率 p p p
3.4 因果性を使って Q π Q^\pi Q π
3.2・3.3 を合わせると ∇ θ J = E [ ( ∑ t ∇ θ log π θ ( a t ∣ s t ) ) G ( τ ) ] \nabla_\theta J = \mathbb{E}\big[\big(\sum_t\nabla_\theta\log\pi_\theta(a_t\mid s_t)\big)G(\tau)\big] ∇ θ J = E [ ( ∑ t ∇ θ log π θ ( a t ∣ s t ) ) G ( τ ) ] 因果性 (時刻 t t t t t t t t t Q π ( s t , a t ) Q^\pi(s_t,a_t) Q π ( s t , a t )
∇ θ J ( θ ) = E π θ [ ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) Q π ( s t , a t ) ] \boxed{\;\nabla_\theta J(\theta)
= \mathbb{E}_{\pi_\theta}\!\left[\sum_{t=0}^{T}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\,Q^\pi(s_t,a_t)\right]\;} ∇ θ J ( θ ) = E π θ [ t = 0 ∑ T ∇ θ log π θ ( a t ∣ s t ) Q π ( s t , a t ) ] これが方策勾配定理 です。「行動 a t a_t a t Q π Q^\pi Q π
4. REINFORCE:Q Q Q
方策勾配定理の Q π ( s t , a t ) Q^\pi(s_t,a_t) Q π ( s t , a t ) 1エピソードを最後まで走らせて得た実際のリターン G t = ∑ k = t T γ k − t r k G_t=\sum_{k=t}^{T}\gamma^{k-t}r_k G t = ∑ k = t T γ k − t r k Q π Q^\pi Q π G t G_t G t Q π ( s t , a t ) Q^\pi(s_t,a_t) Q π ( s t , a t )
∇ θ J ( θ ) ≈ ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) G t \nabla_\theta J(\theta)\;\approx\;\sum_{t=0}^{T}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\,G_t ∇ θ J ( θ ) ≈ t = 0 ∑ T ∇ θ log π θ ( a t ∣ s t ) G t これが REINFORCE (Williams, 1992)です。アルゴリズムは驚くほど単純です。
flowchart TD
A["現在の方策 π_θ で1エピソードを最後まで実行"] --> B["各ステップの軌道(s_t, a_t, r_t)を記録"]
B --> C["各 t のリターン G_t を後ろから計算"]
C --> D["勾配 Σ_t ∇log π_θ(a_t|s_t)・G_t を作る"]
D --> E["θ ← θ + α・勾配(勾配上昇)"]
E --> A
直観 :∇ θ log π θ ( a t ∣ s t ) \nabla_\theta\log\pi_\theta(a_t\mid s_t) ∇ θ log π θ ( a t ∣ s t ) a t a_t a t G t G_t G t
G t G_t G t 大きい(良い結果) :その方向に大きく進む → その行動の確率を上げる G t G_t G t 小さい/負(悪い結果) :逆向きに進む → その行動の確率を下げる
つまり「結果が良かった行動は、次から出やすくする」という、試行錯誤そのものを勾配で表現しています。
5. 高分散問題とベースライン
REINFORCE は理屈は綺麗ですが、実用上は勾配の分散が非常に大きい という重大な弱点があります。G t G_t G t
5.1 ベースラインを引いても期待値は不変
そこで、行動に依存しないベースライン b ( s t ) b(s_t) b ( s t )
∇ θ J ( θ ) = E π θ [ ∑ t ∇ θ log π θ ( a t ∣ s t ) ( G t − b ( s t ) ) ] \nabla_\theta J(\theta)\;=\;\mathbb{E}_{\pi_\theta}\!\left[\sum_{t}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\,\big(G_t - b(s_t)\big)\right] ∇ θ J ( θ ) = E π θ [ t ∑ ∇ θ log π θ ( a t ∣ s t ) ( G t − b ( s t ) ) ] 驚くべきことに、何を引いても勾配の期待値は変わりません (不偏のまま)。鍵は、引き算で増えた項 E [ ∇ θ log π θ ⋅ b ( s ) ] \mathbb{E}[\nabla_\theta\log\pi_\theta\cdot b(s)] E [ ∇ θ log π θ ⋅ b ( s )] ゼロ になることです。状態 s s s
E a ∼ π θ [ ∇ θ log π θ ( a ∣ s ) b ( s ) ] = b ( s ) ∑ a π θ ( a ∣ s ) ∇ θ log π θ ( a ∣ s ) \mathbb{E}_{a\sim\pi_\theta}\!\big[\nabla_\theta\log\pi_\theta(a\mid s)\,b(s)\big]
= b(s)\sum_{a}\pi_\theta(a\mid s)\,\nabla_\theta\log\pi_\theta(a\mid s) E a ∼ π θ [ ∇ θ log π θ ( a ∣ s ) b ( s ) ] = b ( s ) a ∑ π θ ( a ∣ s ) ∇ θ log π θ ( a ∣ s ) ここで log-derivative trick を逆向き に使うと π θ ∇ θ log π θ = ∇ θ π θ \pi_\theta\nabla_\theta\log\pi_\theta = \nabla_\theta\pi_\theta π θ ∇ θ log π θ = ∇ θ π θ
= b ( s ) ∑ a ∇ θ π θ ( a ∣ s ) = b ( s ) ∇ θ ∑ a π θ ( a ∣ s ) ⏟ = 1 = b ( s ) ∇ θ 1 = 0 = b(s)\sum_{a}\nabla_\theta\pi_\theta(a\mid s)
= b(s)\,\nabla_\theta\underbrace{\sum_{a}\pi_\theta(a\mid s)}_{=\,1}
= b(s)\,\nabla_\theta 1
= 0 = b ( s ) a ∑ ∇ θ π θ ( a ∣ s ) = b ( s ) ∇ θ = 1 a ∑ π θ ( a ∣ s ) = b ( s ) ∇ θ 1 = 0
要するに:b ( s ) b(s) b ( s ) a a a ∑ a ∇ π θ \sum_a\nabla\pi_\theta ∑ a ∇ π θ ベースラインはバイアスを入れません 。
5.2 分散だけが下がる
期待値は不変なのに、分散は引き方しだいで下げられます 。G t G_t G t 平均と比べて 良かったのか悪かったのか」です。b ( s ) = V π ( s ) b(s)=V^\pi(s) b ( s ) = V π ( s ) G t − V π ( s t ) G_t-V^\pi(s_t) G t − V π ( s t )
たとえば全リターンが + 100 +100 + 100 V ≈ 100 V\approx100 V ≈ 100 100 100 100
5.3 優位関数へ
b ( s ) = V π ( s ) b(s)=V^\pi(s) b ( s ) = V π ( s ) G t − V π ( s t ) G_t-V^\pi(s_t) G t − V π ( s t ) Q π ( s t , a t ) − V π ( s t ) Q^\pi(s_t,a_t)-V^\pi(s_t) Q π ( s t , a t ) − V π ( s t )
A π ( s , a ) = Q π ( s , a ) − V π ( s ) \boxed{\;A^\pi(s,a) \;=\; Q^\pi(s,a) - V^\pi(s)\;} A π ( s , a ) = Q π ( s , a ) − V π ( s ) これは「状態 s s s 平均的に 期待される価値 V π ( s ) V^\pi(s) V π ( s ) 特に行動 a a a ことがどれだけ得か」を測ります。優位関数を使った方策勾配が、現代的な定式化の標準形です。
∇ θ J ( θ ) = E π θ [ ∑ t ∇ θ log π θ ( a t ∣ s t ) A π ( s t , a t ) ] \nabla_\theta J(\theta)\;=\;\mathbb{E}_{\pi_\theta}\!\left[\sum_{t}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\,A^\pi(s_t,a_t)\right] ∇ θ J ( θ ) = E π θ [ t ∑ ∇ θ log π θ ( a t ∣ s t ) A π ( s t , a t ) ]
要するに:「平均より良い行動の確率を上げ、平均より悪い行動の確率を下げる」。V V V
6. 確率的方策の利点と次への橋渡し
方策勾配が価値ベースに勝る場面を整理します。
確率的方策を直接学べる :最適方策が確率的になる問題(ゲーム理論的状況・POMDP)で本領を発揮します。連続行動が自然 :ガウス方策の平均・分散を出すだけで、arg max \arg\max arg max 方策が滑らかに変化 :θ \theta θ arg max \arg\max arg max
一方で REINFORCE は V V V V V V V V V Q Q Q 同時に学習 し、優位関数をその場で推定する枠組みへ発展します。それが Actor-Criticと深層強化学習 です。Critic がブートストラップで A A A
⚠️ よくある誤解・落とし穴
「方策勾配は大域最適に収束する」→ 誤り。 勾配上昇である以上、一般に局所最適 にしか収束しません。J ( θ ) J(\theta) J ( θ ) θ \theta θ Q Q Q 「ベースラインを引くとバイアスが入る」→ 誤り。 5.1 で証明した通り、b b b 状態のみの関数 なら期待値は不変で、減るのは分散だけ です。ただし b b b 行動 a a a ∑ a ∇ π θ \sum_a\nabla\pi_\theta ∑ a ∇ π θ 「REINFORCE はサンプル効率が良い」→ 誤り。 1回の更新にエピソードを最後まで 走らせる必要があり(G t G_t G t オンポリシー 。高分散と相まってサンプル効率は悪く、これが Actor-Critic や PPO など後続手法の主たる動機になりました。対数の引数の取り違え: 勾配を掛けるのは ∇ θ log π θ ( a t ∣ s t ) \nabla_\theta\log\pi_\theta(a_t\mid s_t) ∇ θ log π θ ( a t ∣ s t ) G t G_t G t log \log log log \log log 方策の確率 だけです。勾配上昇 vs 勾配降下: J J J 最大化 対象なので符号は + α ∇ J +\alpha\nabla J + α ∇ J − ( log π θ ⋅ A ) -\,(\log\pi_\theta\cdot A) − ( log π θ ⋅ A ) 誤差逆伝播法 の自動微分にこの「サロゲート損失」を流すのが定番)。
対応するシミュレーション
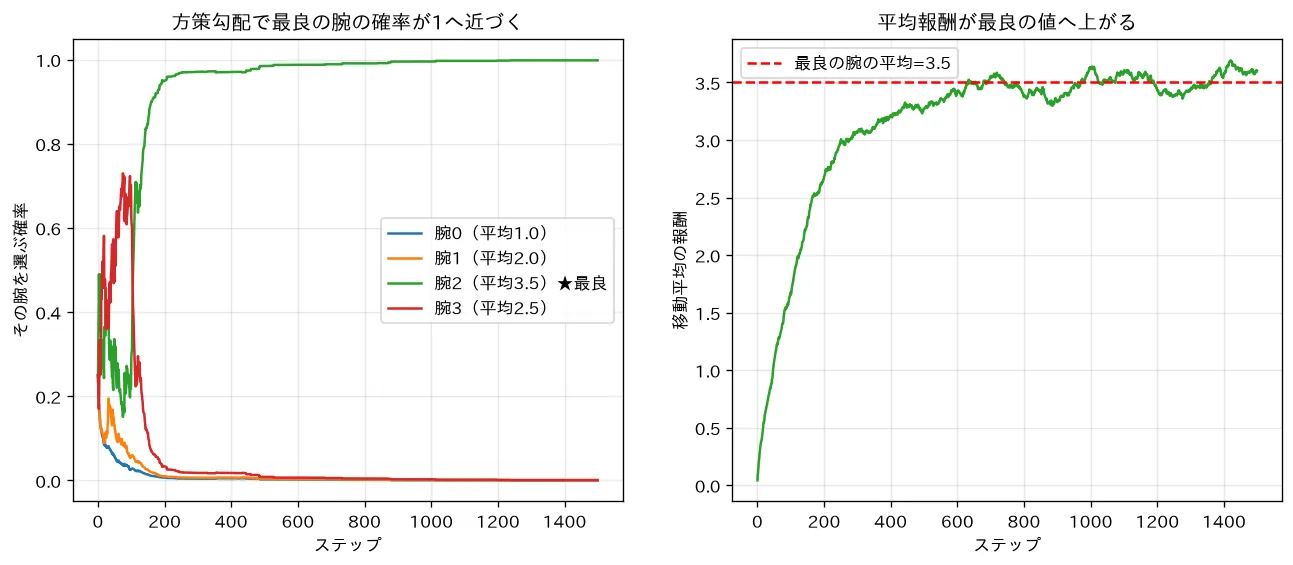
simulations/policy_gradient_bandit.py:4本腕バンディットで、方策をソフトマックスで表し REINFORCE で学習します。得た報酬に応じて ∇ log π ( a ) \nabla\log\pi(a) ∇ log π ( a ) Actor-Criticと深層強化学習 の優位関数へ)を可視化します。
関連ノート