🎓 レベル:基礎 | 重要度:A(必須)
📎 前提:特になし(確率・統計の基礎があると理解が早い → 統計検定サイト)
要点(BLUF)
- 機械学習とは、ルールを人が書く代わりに、データから規則(モデル)を自動で獲得する枠組みです。
- 問題は大きく 教師あり学習 / 教師なし学習 / 強化学習 の3類型に分かれます。
- 「正解ラベルがあるか」「何を得たいか(予測か・構造の発見か・行動方針か)」で類型が決まります。
1. 機械学習とは何か
従来のプログラミングは「ルールを人が書き、データを入れて答えを出す」流れです。機械学習はこれを逆転させ、「データと答えを入れて、ルール(モデル)を出す」アプローチを取ります。
flowchart LR
subgraph 従来のプログラミング
R1["ルール(人が記述)"] --> P1["プログラム"]
D1["データ"] --> P1
P1 --> A1["答え"]
end
subgraph 機械学習
D2["データ"] --> M["学習アルゴリズム"]
A2["答え(正解ラベル)"] --> M
M --> R2["モデル(学習されたルール)"]
end
得られた「モデル」は、未知の入力に対して予測・判断を返す関数 です。良いモデルとは、学習に使っていない新しいデータでもうまく働くもの(=汎化する。詳しくは 汎化と過学習・バイアスバリアンス分解)。
2. 3つの類型
| 類型 | 目的 | データ | 代表的な問題 | 代表手法 |
|---|---|---|---|---|
| 教師あり学習 | 入力から出力を予測 | 入力 + 正解 | 回帰・分類 | 線形回帰・SVM・NN |
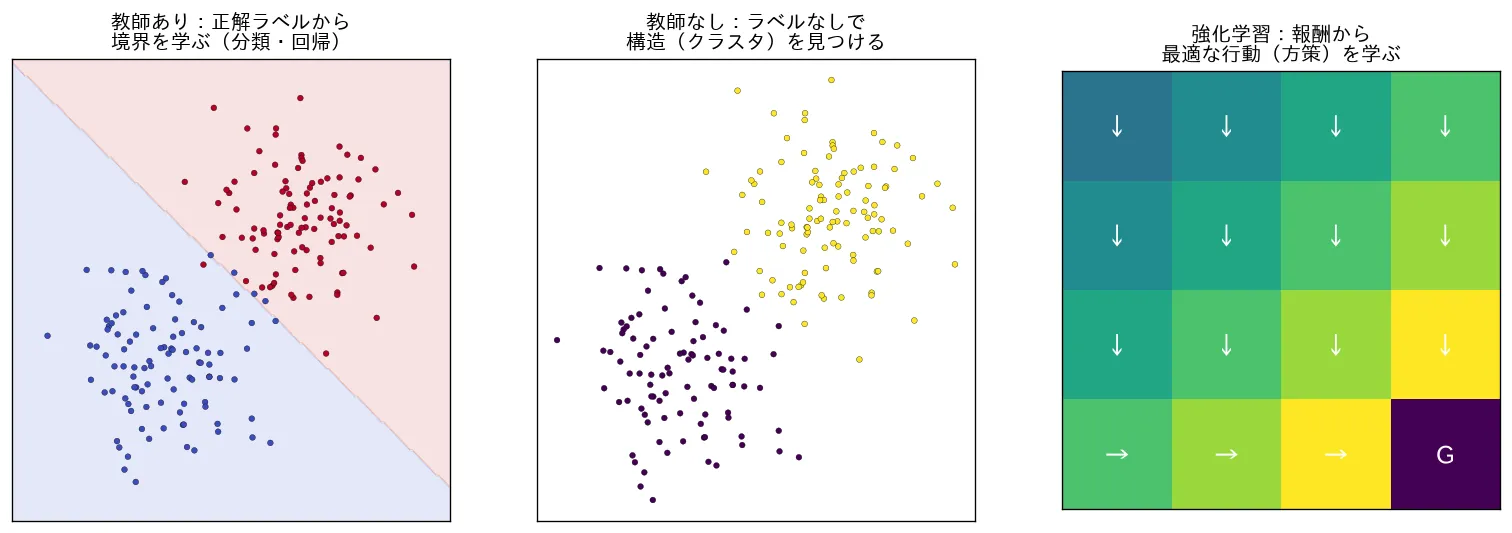
| 教師なし学習 | データの構造・パターン発見 | 入力 のみ | クラスタリング・次元削減 | k-means・PCA |
| 強化学習 | 報酬を最大化する行動方針の獲得 | 環境との試行錯誤(状態・行動・報酬) | 制御・ゲーム | Q学習・方策勾配 |
graph TD ML["機械学習"] --> SL["教師あり学習<br/>(正解ラベルあり)"] ML --> UL["教師なし学習<br/>(ラベルなし)"] ML --> RL["強化学習<br/>(報酬で学ぶ)"] SL --> REG["回帰:連続値を予測"] SL --> CLF["分類:カテゴリを予測"] UL --> CLU["クラスタリング:似たもの同士をまとめる"] UL --> DR["次元削減:本質的な軸を取り出す"] RL --> POL["方策:状態→行動の対応を学ぶ"]
- 教師あり:出力が連続値なら 回帰(例:気温から売上を予測)、カテゴリなら 分類(例:画像が犬か猫か)。Phase 2・3 で扱います。
- 教師なし:正解は与えられず、データ自体の構造を見つけます。クラスタリングや PCA(→ 統計の 主成分分析(PCA))。Phase 5。
- 強化学習:正解ラベルではなく 報酬 という弱い信号から、試行錯誤で良い行動方針を学びます。Phase 10。
3. どう使い分けるか
最初の分岐は「正解ラベル があるか」。あれば教師あり。なければ、構造を知りたいなら教師なし、行動を最適化したいなら強化学習、という順で考えると整理できます。
flowchart TD
Q1{"正解ラベル y がある?"}
Q1 -- "ある" --> SL["教師あり学習"]
Q1 -- "ない" --> Q2{"何を得たい?"}
Q2 -- "データの構造・要約" --> UL["教師なし学習"]
Q2 -- "行動の最適化(報酬あり)" --> RL["強化学習"]
⚠️ よくある誤解
- 「AI=深層学習」ではない。深層学習は機械学習の一手法(Phase 7 以降)。決定木や線形回帰も立派な機械学習です。
- 教師なし=簡単、ではない。正解がない分、評価が難しく解釈に注意が要ります。
- 分類と回帰の混同:出力が「数値」でも、順序のないカテゴリ(郵便番号など)は回帰では扱いません。出力の意味で判断します。
対応するシミュレーション
simulations/three_types_of_ml.py:機械学習の3類型を最小の例で横並びに可視化します。教師あり(正解ラベルから2クラスの境界を学ぶ)・教師なし(ラベルなしで k-means がクラスタを見つける)・強化学習(小さなグリッドワールドで報酬から最適方策の矢印を学ぶ)。「何が与えられ、何を最適化するか」が違うだけで、汎化・過学習・最適化の土台は共通であることを示します。
関連ノート
- 学習問題の定式化(仮説・損失・経験リスク) — どの類型も「損失を最小化する」という共通の数学で書ける
- 汎化と過学習・バイアスバリアンス分解
- 機械学習テキスト 全体目次