🎓 レベル:標準 | 重要度:A(必須)
📎 前提:再帰型ニューラルネットワーク(その限界を克服する)
要点(BLUF)
- 注意機構は、ある位置(クエリ)が系列の全位置を重み付きで参照し、関連する情報だけを取り出す仕組みです。
- 中核はスケール化ドット積注意 。クエリとキーの類似度を softmax で重みに変え、バリューを加重和します。
- RNN の固定長文脈ベクトルのボトルネックと**逐次処理(並列化不可)**を同時に解消し、Transformer の土台になります。
1. なぜ注意機構が必要か:RNN の3つの限界
再帰型ニューラルネットワークは系列を一歩ずつ処理しますが、機械翻訳のような seq2seq(系列を入力して別の系列を出力する)課題で、次の限界に突き当たります。
(1) 固定長文脈ベクトルのボトルネック
素朴な seq2seq は、エンコーダが入力系列全体を1本の固定長ベクトル (最後の隠れ状態)に押し込め、デコーダはそれだけを頼りに出力を生成します。
問題は、入力が長くなるほど に詰め込む情報が増えて溢れること。50 単語の文も 5 単語の文も同じ次元のベクトルに圧縮するため、長文では文頭の情報が失われやすい。これが「文脈ベクトルのボトルネック」です。
(2) 長期依存の困難
勾配消失により、遠く離れた位置どうしの依存(例:主語と遠い述語の一致)を学習しにくい。情報は時刻ステップを1つずつ伝播するため、距離 だけ離れた2語をつなぐには 回の伝播が必要です。
(3) 逐次処理で並列化できない
隠れ状態 は に依存するため、 を順番にしか計算できません。GPU は並列計算が得意なのに、RNN はその利点を活かせない。これが学習速度の致命的な制約になります。
要するに:RNN は「1本の細い管に情報を流す」ので、長文で詰まり(ボトルネック)、遠い関係が薄れ(長期依存)、順番待ちが発生する(並列化不可)。
2. 注意の発想:全部見て、重み付きで取り出す
ボトルネックの根本原因は「入力全体を1本のベクトルに潰すこと」です。ならば潰さなければよい。
注意機構の発想はこうです。出力側の各位置(クエリ)が、入力の全位置を直接参照し、「今どこが関係するか」を表す重みを計算して、関係する位置の情報を加重和で取り出す。
最初にこれを実現したのが Bahdanau ら(2014)の加法注意です。デコーダの各ステップ ごとに、エンコーダの全隠れ状態 との整合スコアを計算します。
これを softmax で重み に変え、ステップごとに変わる文脈ベクトル を作ります。
要するに:固定の を1本だけ持つのをやめ、「デコーダの今の状態に応じて、入力のどこを見るかを毎回作り直す」。これでボトルネックが消えます。
このあと **Luong ら(2015)**が、 と小さなネットワークを使う加法注意より、内積(ドット積)で類似度を測る方が単純かつ高速だと示しました。これがスケール化ドット積注意に直結します。
3. Query / Key / Value:検索の比喩
現代の注意は3つの役割に分けて定式化します。検索エンジンの比喩が分かりやすいです。
| 記号 | 名前 | 役割(検索の比喩) |
|---|---|---|
| クエリ (Query) | 「何を探しているか」。問い合わせ | |
| キー (Key) | 「各項目の見出し」。クエリと突き合わせる対象 | |
| バリュー (Value) | 「実際に取り出す中身」。重みに応じて混ぜる本体 |
検索では、問い合わせ(クエリ)を各文書の見出し(キー)と照合して関連度を測り、関連度の高い文書の中身(バリュー)を返します。注意機構はこれを「ハード(1件だけ返す)」ではなく「ソフト(全件を重み付きで混ぜる)」に行います。
具体的には、入力の各トークン埋め込み から、3つの学習可能な行列で射影して を作ります。
が学習対象です。何をクエリ・キー・バリューとして使うかをモデルが学習する点が重要です。
4. スケール化ドット積注意の導出
4.1 全体の式
ここで 、、、 はクエリ数、 はキー/バリュー数、 はクエリ・キーの次元です。
4.2 ステップごとの意味
- 類似度(スコア): の 成分は、 番目のクエリと 番目のキーの内積 。内積が大きいほど方向が揃っており「関連が強い」。
- スケーリング: で割る(理由は次節)。
- softmax:各クエリ行を確率分布に変換。。これが「クエリ がキー にどれだけ注目するか」の重み。
- 加重和:。重み でバリューを混ぜ、クエリ の出力ベクトルを得る。
要するに:「クエリとキーの内積で関連度を測り → softmax で配分率に変え → バリューをその率で混ぜる」。これを行列1発で全クエリ同時に計算します。
softmax の確率的な背景(指数で重みを作り、正規化して分布にする理由)は、各スコアを「大きいほど指数的に強調し、全体を に正規化して確率分布にする」変換だと理解すれば十分です。
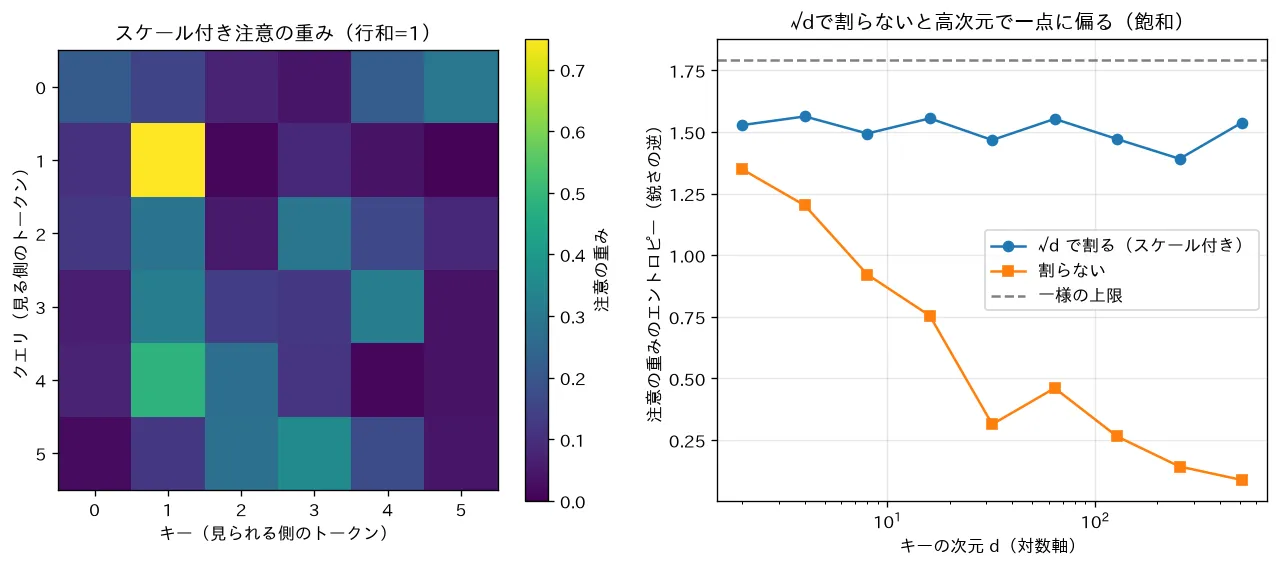
5. なぜ で割るのか(導出)
ここが本トピックの核心です。 は分散を一定に保つための正規化で、これがないと softmax が飽和して勾配が消えます。
5.1 分散が次元に比例して増える
クエリ とキー の各成分が、独立で平均 ・分散 と仮定します。内積は
各項 は独立な2変数の積なので、平均は 、分散は
独立な 個の和なので分散は加算され、
つまり内積の標準偏差は に比例して大きくなる。例えば なら 、 なら 。次元が増えるほど内積の値が大きくばらつきます。
5.2 大きな入力は softmax を飽和させ、勾配を消す
softmax は入力の差が大きいと、最大要素の出力がほぼ 、他がほぼ の極端に尖った分布になります。この飽和領域では softmax のヤコビアンが に近づきます。softmax の勾配は出力 を用いて
と書け、 や では 、すなわち勾配がほぼ消失します。学習初期にこうなると、注意の重みがほぼ更新されず学習が進みません。
5.3 で割ると標準偏差が 1 に戻る
スコアを で割ると、
次元 に依らず分散が約 に保たれます。これで softmax は飽和しにくい穏当な領域に収まり、勾配が健全に流れます。
要するに: は「次元が増えると内積のばらつきが 倍に膨らむ」のをちょうど打ち消す係数。割らないと softmax がカチカチに尖って勾配が死ぬので割る。深さ(次元)が変わってもスケールを揃える正規化です。
6. Q/K/V 計算フロー(図解)
flowchart LR
X["入力埋め込み X"] --> Q["クエリ Q = X·WQ"]
X --> K["キー K = X·WK"]
X --> V["バリュー V = X·WV"]
Q --> S["スコア = Q·Kᵀ(内積で類似度)"]
K --> S
S --> SC["スケーリング(÷ √dk)"]
SC --> SM["softmax(重み αに正規化)"]
SM --> W["加重和 Σ α·V"]
V --> W
W --> O["出力(文脈ベクトル)"]
自己注意では がすべて同じ入力 から作られる点に注目してください(次節)。
7. 自己注意と交差注意
注意は「クエリとキー/バリューがどこから来るか」で2種類に分かれます。
自己注意 (self-attention)
がすべて同じ系列から作られます(、いずれも同じ )。各トークンが同じ文の他のトークンを参照し、文脈に応じた表現を得ます。
- 例:「銀行(bank)の口座」と「川(river)の bank」で、同じ単語 bank が周囲の語を見て意味を変える。
- これが Transformer のエンコーダ・デコーダ内部の主役です。
交差注意 (cross-attention)
クエリと、キー/バリューが別の系列から来ます。典型は機械翻訳のデコーダで、
- クエリ = 出力側(翻訳先)の状態
- キー・バリュー = 入力側(翻訳元)のエンコーダ出力
これにより「出力の各語が、入力のどこに対応するか」を学習します。Bahdanau 注意(第2節)はまさに交差注意の原型でした。
| クエリ | キー・バリュー | 用途 | |
|---|---|---|---|
| 自己注意 | 同じ系列 | 同じ系列 | 系列内の文脈把握 |
| 交差注意 | 系列A | 系列B | 系列間の対応付け(翻訳など) |
8. 計算量 とその含意
系列長を 、表現次元を とします(簡単のため )。
- スコア計算 : と の積で 。
- 加重和 : と の積で 。
合わせて時間計算量は 、注意行列のメモリは です。
含意は2つあります。
- 並列化できる:RNN と違い、全位置のスコアを行列積で一度に計算できます。逐次依存がないので GPU で完全並列。これが学習速度の革命でした。
- 系列長の2乗で重い: が長いと が爆発します。長文書や高解像度画像( が大)では計算・メモリが厳しく、これが疎な注意・線形注意・FlashAttention などの効率化研究の動機になっています。
要するに:RNN は「速くないが軽い( だが逐次)」、注意は「並列で速いが で重い」。距離に依らず任意の2位置を1ステップで結べる(最大経路長 )のが、長期依存に効く本質です。
9. Transformer への橋渡し
スケール化ドット積注意そのものは学習可能なパラメータを持つ層ではなく、 を与えると重み付き和を返す演算です。これを部品として、Transformerは次を積み上げます。
- マルチヘッド注意:注意を複数並列に走らせ、異なる部分空間で別々の関係を捉える。
- 位置エンコーディング:自己注意は順序情報を持たない(後述の誤解参照)ため、位置情報を明示的に足す。
- 残差接続・層正規化・FFN:深く積めるようにする。
注意機構の理解は、そのまま Transformer と Phase 12 の大規模言語モデル(LLM)の土台になります。
⚠️ よくある誤解・落とし穴
- 「注意の重みが大きい=そこが理由(説明可能性)」とは限らない。注意重み は「どこを混ぜたか」を示しますが、モデルの予測根拠と1対1には対応しません。重みを別の妥当な分布に差し替えても出力がほぼ変わらない例が報告されており、注意重みを安易に「説明」として解釈するのは危険です。
- は「平均」ではなく「標準偏差」の正規化。(次元数)で割るのではなく で割ります。割るのは分散が に比例するからで、標準偏差を に戻すには平方根が必要です。 で割ると割りすぎてスコアが潰れます。
- 自己注意は順序を知らない。 は内積の集合で、トークンを並べ替えても(対応して並べ替えれば)同じ結果になります(置換同変)。だから語順を与えるには位置エンコーディングが別途必要です。注意だけでは「I love you」と「you love I」を区別できません。
- softmax は「ハードな選択」ではない。1箇所だけ選ぶのではなく全位置を重み付きで混ぜる「ソフト」な機構です。だからこそ微分可能で、勾配で学習できます。
対応するシミュレーション
simulations/attention_weights.py:スケール付きドット積注意 の重み行列をヒートマップで描き、各クエリが各キーをどれだけ見るか(行和=1)を可視化します。さらにキー次元 を変えて、 で割らないと内積が大きくなりすぎてソフトマックスが一点に偏り(エントロピーが0へ=飽和)勾配が消えること、 で割ると分布が保たれることを示します(Transformer)。
関連ノート
- 深層学習アーキテクチャ 目次
- 再帰型ニューラルネットワーク(克服対象の限界)
- Transformer(注意機構を部品に構築)
- 機械学習テキスト 全体目次