🎓 レベル:発展 | 重要度:A(必須)
要点(BLUF)
- Transformer は RNN も畳み込みも使わず、注意機構だけで系列を処理するアーキテクチャです(Vaswani et al., 2017「Attention Is All You Need」)。
- 各ブロックは マルチヘッド自己注意 + 位置ごとのFFN を、それぞれ 残差接続 + LayerNorm で包んだもの。順序情報は 位置符号化 で外から注入します。
- 全位置を並列に処理でき、任意の2位置を1ステップで直接結べるので、RNN の逐次処理・長期依存問題を解消し、大規模化に向きます。Phase 12 のLLMはすべてこの構造の上に立ちます。
1. 背景:なぜ注意「だけ」なのか
それまでの系列モデルの主役は RNN(再帰型ニューラルネットワーク)でした。RNN は隠れ状態を1ステップずつ受け渡すので、本質的に2つの弱点を持ちます。
- 逐次処理しかできない:時刻 の計算に の結果が必要なので、系列方向に並列化できない。GPU を活かしきれません。
- 長期依存が薄れる:離れた2トークンを結ぶには、その間のすべてのステップを情報が通過する必要があり、勾配が減衰します(LSTM/GRU で緩和はするが消えない)。
2017年の「Attention Is All You Need」は、この2点を注意機構だけで解決しました。注意は系列のどの位置からどの位置へも直接アクセスできるので、距離が遠くても1回の演算で結べます。しかも全位置の計算が独立なので完全に並列化できます。これがTransformerの2大利点 ── 並列性と長期依存への強さです。
要するに:「順番に伝える」RNN をやめ、「全部を一度に見比べる」注意に置き換えた、ということです。
2. 全体構造:エンコーダ・デコーダのスタック
オリジナルのTransformerは機械翻訳用で、エンコーダとデコーダを持ちます。エンコーダは入力系列を文脈付きベクトル列に変換し、デコーダはそれを参照しながら出力系列を1トークンずつ生成します。それぞれ同一のブロックを 個積みます(原論文は )。
各ブロックの中身は「サブ層を残差接続 + LayerNorm で包む」の繰り返しです。サブ層の出力を とすると、1サブ層は
です(これが原論文の Post-LN 配置。後述するように現代は配置が変わります)。残差接続 は深いネットの勾配を通しやすくし、LayerNorm はスケールを揃えて学習を安定させます(重み初期化と正規化)。
要するに:どのサブ層も「入力に変換結果を足して、正規化する」という同じ型にはまっています。
flowchart TB
subgraph DEC["デコーダブロック(×N)"]
D_in["前層の出力"] --> D1["マスク付きマルチヘッド自己注意"]
D1 --> DA1["Add and Norm"]
DA1 --> D2["エンコーダ-デコーダ注意(クロス注意)"]
D2 --> DA2["Add and Norm"]
DA2 --> D3["位置ごとのFFN"]
D3 --> DA3["Add and Norm"]
end
subgraph ENC["エンコーダブロック(×N)"]
E_in["前層の出力"] --> E1["マルチヘッド自己注意"]
E1 --> EA1["Add and Norm"]
EA1 --> E2["位置ごとのFFN"]
E2 --> EA2["Add and Norm"]
end
EA2 -. "K と V を供給" .-> D2
エンコーダブロック=「自己注意 → Add&Norm → FFN → Add&Norm」の2サブ層。デコーダブロックは間にクロス注意が挟まり3サブ層になります。クロス注意では、Query をデコーダ側から、Key・Value をエンコーダ出力から取ります(=「出力を作りながら入力を参照する」)。
3. 自己注意(self-attention)
Transformerの心臓は自己注意です。注意機構で見たスケール付きドット積注意
において、Q・K・V を同じ系列から作るのが自己注意です。入力埋め込み行列 ( トークン)から、学習する射影行列で
を作ります。すると は 全トークン対の類似度行列()になり、softmax 後の重みで を加重平均します。つまり各トークンが系列内の全トークンを参照して、自分の新しい表現を作り直すわけです。
なぜ で割るのか
これは省略できない重要ポイントです。 の各成分が独立に平均0・分散1とすると、内積 の分散は になります(独立和の分散は分散の和)。 が大きいと内積の絶対値が 程度に膨らみ、softmax がほぼ one-hot に飽和して勾配がほぼ0になります。 で割ると分散が1に戻り、softmax が極端化せず勾配が流れます。
要するに:割り算は「次元が増えても softmax を飽和させない」ための分散の正規化です。理論的裏付けは「独立和の分散=分散の和」という確率の基本事実です。
4. マルチヘッド注意(multi-head attention)
自己注意を1組だけ走らせると、1種類の「見方」しか得られません。Transformerは注意を 個並列に走らせます(原論文 )。各ヘッドは独立の射影 を持ち、 を 分割した低次元 ()で注意を計算します。
各ヘッドの出力()を横に結合して、出力射影 で元の次元に戻します。
flowchart LR X["入力 X"] --> H1["head_1:W_1 で射影し注意"] X --> H2["head_2:W_2 で射影し注意"] X --> Hd["head_h:W_h で射影し注意"] H1 --> C["Concat(横に結合)"] H2 --> C Hd --> C C --> O["出力射影 W_O"] O --> Y["MultiHead の出力"]
ポイントは、各ヘッドが異なる表現部分空間を同時に見ること。あるヘッドは係り受け、別のヘッドは共参照、というように役割分担が観察されます。しかも次元を 分割しているので、計算量はシングルヘッドとほぼ同じまま表現力だけ上がります。
要するに:1人のアナリストではなく、別の視点を持つ 人に同時に見させて意見を統合する、というイメージです。
5. 位置符号化(positional encoding)
自己注意には致命的な性質があります。 は集合的な類似度しか見ず、トークンの順序を一切区別しません。入力をシャッフルしても各位置の出力が同じように入れ替わるだけ(置換同変, permutation-equivariant)で、「猫が犬を追う」と「犬が猫を追う」を区別できません。だから順序情報を外から注入する必要があります。これが位置符号化です。
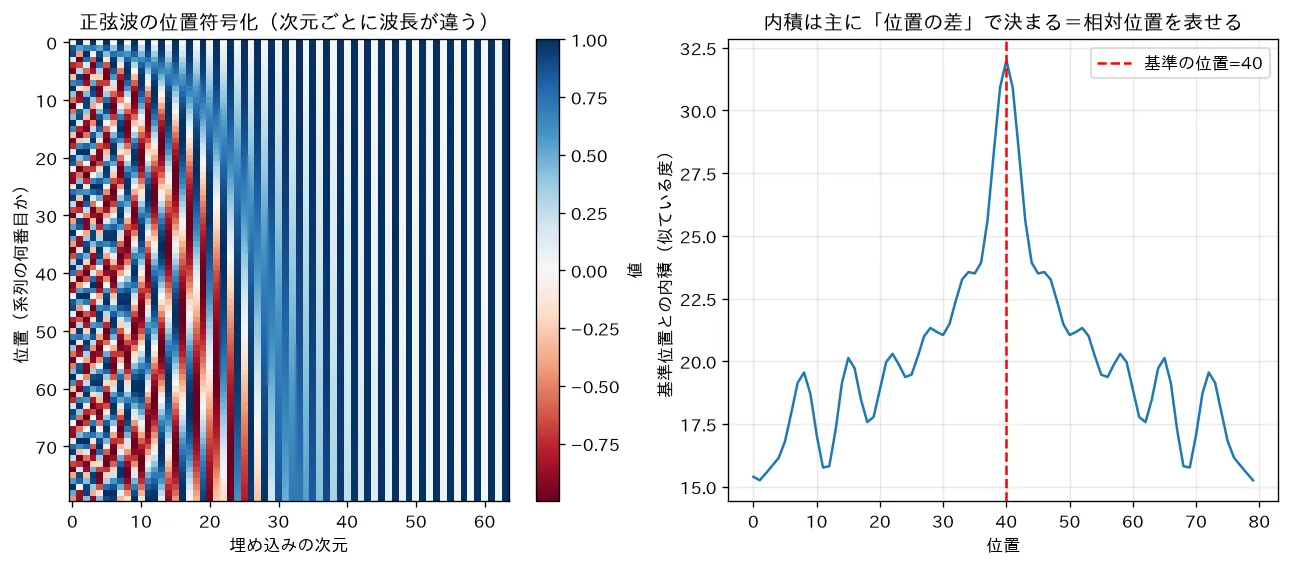
原論文は周期の異なる正弦・余弦を使います。位置 、次元インデックス に対して
これを入力埋め込みに足し込みます。波長は から まで幾何級数的に並び、低次元=細かい振動(局所)、高次元=緩やかな振動(大域)を担います。各位置が一意の「指紋」を持ち、かつ任意のオフセット に対して が の線形変換で書けるので、モデルが相対位置を学びやすいという性質があります。
正弦波の代わりに学習可能な位置埋め込み(位置ごとにベクトルを学ぶ)も広く使われます。どちらが良いかはタスク・系列長によります(外挿には正弦波系が有利とされる)。
要するに:注意は「順序を見ない」ので、各位置に固有の波形を足して「ここは何番目か」を教えています。
📌 要最新確認:現代のLLMは正弦波PEより RoPE(回転位置埋め込み) や ALiBi などの相対位置方式が主流です。長文への外挿・KVキャッシュとの相性が理由ですが、この領域は変化が速いので最新を確認してください。
6. マスク付き注意(masked attention)
デコーダは出力を自己回帰的に(左から1トークンずつ)生成します。学習時は正解系列を一括投入して並列に学習しますが、ここで問題が起きます ── 自己注意は全位置を見るので、位置 を予測するときに未来の正解 まで覗いてしまう(カンニング)。これを防ぐのがマスク付き自己注意です。
ソフトマックス前のスコア行列で、 より右(未来)の要素を に置き換えます。
は softmax 後に重み0になるので、各位置は自分以下の位置だけを参照します。これにより「未来を見ない」自己回帰性が保たれ、学習時も全位置を並列に計算できます(RNN なら逐次にしかできなかった処理が、マスク1枚で並列化できる点が美しい)。
要するに:上三角を で塞ぐマスク1枚で「未来を見ない」を実現し、それでも並列学習できます。
7. 位置ごとのFFN(position-wise feed-forward network)
注意サブ層の後には、各位置に独立同一に適用される2層MLPが入ります。
中間次元は より広く(原論文 に対し内側 )、活性化は ReLU(現代は GELU/SwiGLU が主流)。注意が「位置間で情報を混ぜる」のに対し、FFN は「各位置の特徴を非線形に変換する」役割で、両者は補完的です。
要するに:注意で混ぜて、FFN で各位置を作り込む、という分業です。
8. なぜ強いか:RNN との対比
Transformer の優位性は計算量の比較で明確になります。系列長 、表現次元 のとき:
| 観点 | 自己注意(Transformer) | リカレント(RNN/LSTM) |
|---|---|---|
| 層あたり計算量 | ||
| 逐次演算の数(並列化のしにくさ) | ||
| 任意2位置間の最大経路長 |
決定的なのは下2行です。逐次演算が =系列方向に完全並列化でき、GPU/TPU を使い切れる。経路長が =離れた2トークンも1ホップで結べるので長期依存に強い。RNN はどちらも で、これがボトルネックでした。
短い系列( が普通)では計算量 も RNN の と同等以下に収まり、並列性の利点だけが残ります。この「並列化しやすくスケールする」性質こそが、後の巨大化(GPT/BERT/LLM)を可能にした本質です。
graph LR
A["トークン1"] -. "1ホップで直結" .- D["トークン_n"]
subgraph RNN_path["RNN:間を全部通過する"]
R1["t1"] --> R2["t2"] --> R3["…"] --> Rn["t_n"]
end
要するに:「並列に計算できる」×「遠くと直接つながる」の両取りが、スケール時代の主役になった理由です。
9. 効率化・変種と LLM への橋渡し
自己注意の弱点は系列長 に対し (スコア行列が )で、長文だとメモリ・計算が爆発します。これを緩和する研究が多数あります(要最新確認:この領域は進展が速い)。
- IO効率化:FlashAttention 系。 の計算量自体は変えず、GPU メモリ階層を意識して実測を高速化(近似ではない)。
- 疎・低ランク近似:注意を一部の位置に限る(Sparse/Longformer 系)、線形近似(Linear/Performer 系)で計算量を 寄りに削減。
- 正規化・配置の改良:Pre-LN・RMSNorm など(次節)。
これらを踏まえ、現代の標準的なTransformerは原論文から進化し、Pre-LN(RMSNorm)・RoPE・SwiGLU・GQA/MQA・バイアスなし層といった構成に収束しつつあります(要最新確認)。事前学習・微調整・RAG・推論実務といった応用は 大規模言語モデル 目次 で扱います。
⚠️ よくある誤解・落とし穴
- 「位置符号化は飾り」ではない:これが無いと自己注意は語順を区別できません(置換同変)。位置情報の注入は必須で、無くすと文の意味を失います。
- エンコーダのみ/デコーダのみの区別:BERT 系はエンコーダのみ(双方向に全位置を見る、マスクなし。理解・分類向き)、GPT 系はデコーダのみ(マスク付き自己回帰、生成向き)。原論文のエンコーダ-デコーダ型は翻訳のような系列変換向き。「Transformer = エンコーダ-デコーダ」と思い込まないこと。
- 注意の重み = 解釈(説明)ではない:注意の重みを「モデルがどこを根拠にしたか」と読みたくなりますが、注意は説明可能性の保証ではありません。重みが高い=因果的に重要、とは限らない(この点は議論があり、鵜呑みにしないこと)。
- LayerNorm の配置は1通りではない:原論文は Post-LN(残差の後に正規化)。深いモデルでは勾配が不安定になりやすく、現代は Pre-LN(サブ層の前で正規化、残差経路をクリーンに保つ)が主流。ただし Pre-LN にも深層での表現崩壊の問題が指摘され、Peri-LN など新方式も研究中(要最新確認)。
- 「全部を見る」のコスト:自己注意は 。長文では効率化(前節)が必須で、無印の注意がそのままスケールするわけではありません。
対応するシミュレーション
simulations/positional_encoding.py:Transformer が語順を扱うための正弦波の位置符号化を可視化します。次元ごとに波長を変えた sin/cos で各位置に固有のパターンを与えること、ある位置と各位置の内積が基準位置でピークになり距離とともに滑らかに変化する=相対位置を内積で表せることを示します。注意機構そのものの挙動(スケール付きドット積・√d)は前提ノート 注意機構 のシミュレーションが対応します。