🎓 レベル:標準 | 重要度:A(必須)
要点(BLUF)
- 再帰型ニューラルネット(RNN) は、隠れ状態 を時間方向に持ち回ることで可変長の系列を処理するモデルです。鍵は 時間方向の重み共有(毎ステップ同じ を使う)です。
- 学習は系列を時間方向に展開して誤差逆伝播する BPTT で行いますが、同じ重みを系列長ぶん掛けるため 勾配消失/爆発 が起き、長期依存が学べません。
- これを構造で緩和したのが LSTM(セル状態+3ゲート)と GRU(更新・リセットの2ゲート)。セル状態の 加法的更新 が「勾配の高速道路」を作ります。
1. 系列データはなぜ特別か
系列データとは、順序に意味があり、長さが一定でない データのことです。例:
- 時系列:株価・気温・センサー値(過去が未来に効く)
- 言語:単語の並び(「犬が猫を追う」と「猫が犬を追う」は語が同じでも意味が逆)
これらが 誤差逆伝播法 で扱った普通の MLP や、画像の CNN で扱いにくいのは次の3点です。
| 性質 | MLP / CNN の困りごと |
|---|---|
| 可変長 | 入力次元を固定する MLP は、長さ5の文と長さ50の文を同じ層で扱えない |
| 順序 | 全結合は入力をベクトルとして一括投入するので、並び順の情報が混ざって消える |
| 長距離の文脈 | 文頭の主語が文末の動詞の活用に効く、といった離れた依存を全結合で表すのは非効率 |
要するに:「同じ処理を、過去の要約を引き継ぎながら、1ステップずつ繰り返す」 仕組みが欲しい。それが RNN です。
2. RNN の構造:隠れ状態と重み共有
RNN は1ステップごとに 隠れ状態 を更新します。
- :時刻 の入力(例: 番目の単語ベクトル)
- :時刻 の隠れ状態。それまでの系列の要約(記憶)
- :入力→隠れ、:隠れ→隠れ(再帰)、:隠れ→出力
- :活性化関数(古典的には )
要するに: は「今の入力 と 直前までの要約 」を混ぜて作る現在の記憶。 はそこからの出力。
時間方向の重み共有
最重要の性質は、どの時刻でも同じ を使う ことです。これにより、
- 系列が何ステップ長くても パラメータ数は一定(可変長に対応できる)
- 「1ステップ進める」という同じ規則を学べばよく、CNN の空間方向の重み共有に対応する 時間方向の重み共有 になっている
時間展開(unfold)
再帰をほどいて並べると、深さ=系列長のフィードフォワード網に見えます。これが学習(BPTT)の出発点です。
flowchart LR
x1["x_t-1"] --> h1(("h_t-1"))
x2["x_t"] --> h2(("h_t"))
x3["x_t+1"] --> h3(("h_t+1"))
h0(("h_t-2")) -->|"W_hh"| h1
h1 -->|"W_hh (同じ重み)"| h2
h2 -->|"W_hh (同じ重み)"| h3
h1 --> y1["y_t-1"]
h2 --> y2["y_t"]
h3 --> y3["y_t+1"]
同じ (同じ重み)が時刻をまたいで何度も登場する点に注目してください。これが次の勾配問題の原因になります。
3. BPTT(通時的誤差逆伝播)
学習は、展開した網に 誤差逆伝播法 をそのまま適用するだけです。これを BPTT(Backpropagation Through Time) と呼びます。
各時刻の損失の合計 について、再帰重み の勾配は次の二重和になります。
ポイントは、時刻 から時刻 へ勾配を運ぶ部分 が、1ステップぶんのヤコビアンの 積 で書けることです。
要するに:「 ステップ離れた過去まで勾配を届ける」には、 を 回掛ける 必要がある。同じ行列の累乗が現れるのがRNN特有です。
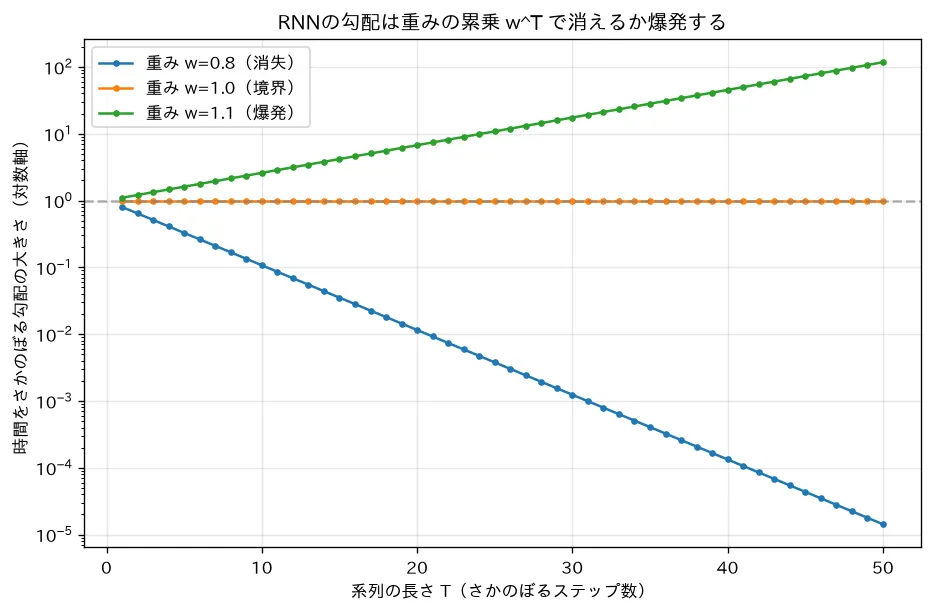
4. 勾配消失/爆発:長期依存が学べない
上のヤコビアン積のノルムを評価すると、なぜ長期依存が学べないかが見えます。1ステップぶんのノルムは
で抑えられます。ここで は の最大特異値(スペクトルノルム)、 は活性化の微分の上界( なら 、 なら )。したがって ステップでは
- → 指数的に縮む=勾配消失。遠い過去ほど学習信号が届かない
- → 指数的に膨らむ=勾配爆発。更新が発散する
xychart-beta
title "ステップ数に対する勾配の大きさ(係数の累乗)"
x-axis "さかのぼるステップ数" [10, 20, 30, 40, 50]
y-axis "勾配の相対的な大きさ" 0 --> 2.5
line [0.35, 0.12, 0.04, 0.015, 0.005]
line [1.2, 1.5, 1.8, 2.1, 2.4]
下の線(係数 )は爆発、上から落ちていく線(係数 )は消失を表します。、 のように、わずかな係数差が深刻な差になります。
補足: や は入力が大きいと微分がほぼ0(飽和)になり、 が小さくなりがちです。これは 活性化関数 で扱った飽和の問題と同根です。
二つの問題への対処は別物
- 爆発:勾配のノルムが閾値を超えたら縮める 勾配クリッピング が有効。これは 最適化の実務 で扱った汎用テクニックで、RNNでは特に重要です。
- 消失:クリッピングでは直らない(小さい勾配をさらに小さくしても意味がない)。ネットワーク構造そのものを変える のが解で、それが次のLSTM/GRUです。
5. LSTM:セル状態という「勾配の高速道路」
LSTM(Long Short-Term Memory) は、隠れ状態とは別に セル状態 という記憶専用の経路を持ち、情報の出入りを3つの ゲート で制御します。ゲートはすべて で を出力する「弁」です( は要素ごとの積)。
要するに:セル状態 が長期記憶の本体で、忘却ゲート で「前を残す量」、入力ゲート で「今を足す量」を決め、出力ゲート で「外に出す量」を決める。
flowchart LR
cprev(("c_t-1")) -->|"× f_t (忘却)"| add(("+"))
cand["c~_t (候補)"] -->|"× i_t (入力)"| add
add --> cnow(("c_t"))
cnow -->|"tanh して × o_t (出力)"| hnow(("h_t"))
xh["x_t と h_t-1"] -.->|"ゲート f_t, i_t, o_t を計算"| add
なぜ勾配が流れるのか(加法的更新がカギ)
通常のRNNでは の伝播が という 乗法的 なものでした。LSTMのセル状態を見ると、更新が 足し算 なので、セル状態どうしのヤコビアンは
になります(他の項は を直接含まないため、この経路が主役)。したがって から への勾配は
で、重み行列 も活性化の微分も掛からず、忘却ゲート だけが掛かります。(=記憶を保つ)に学習されれば、積はほぼ1のまま遠くまで伝わります。これが「定数誤差カルーセル(constant error carousel)」=自己ループの重みが実質1の経路で、いわば 勾配の高速道路 です。
直観:忘却ゲートを開けっ放し()・入力ゲートを閉じる()なら、セル状態は何ステップでもほぼ不変で運ばれる。だから長期依存が学べる。
6. GRU:ゲートを2つに簡略化
GRU(Gated Recurrent Unit) は、LSTMから セル状態と出力ゲートを廃し、ゲートを2つ に減らした軽量版です。隠れ状態 一本で長期記憶も担います。
要するに:更新ゲート が「前の記憶 」と「新候補 」の 配分 を1つの弁で決める( なら前をそのまま保つ=長期記憶)。リセットゲート は候補を作るとき過去をどれだけ見るか。
LSTMとの違い
| LSTM | GRU | |
|---|---|---|
| 記憶の経路 | 隠れ状態 + セル状態 (別経路) | 隠れ状態 のみ |
| ゲート数 | 3(忘却・入力・出力) | 2(更新・リセット) |
| パラメータ | 多い | 少ない(約3/4)。学習が速い傾向 |
| 性能 | データ・タスク次第 | 多くのタスクで同等。明確な優劣はタスク依存 |
GRUは「 と 」で残す/書き込むを連動させており、LSTMの忘却・入力ゲートを1つにまとめたものと見なせます。勾配が流れる原理(残す配分を1に近づけられる加法的経路)はLSTMと同じです。
7. 発展:双方向・多層・そしてTransformerへ
- 双方向RNN(Bi-RNN):系列を前向き・後ろ向きの2方向に走らせ、各時刻で両方の隠れ状態を結合します。文脈が前後両方にある言語タスク(品詞付与など)で有効。ただし系列全体が必要なので、逐次生成(リアルタイム)には使えません。
- 多層(スタック)RNN:RNN層を縦に積み、下層の出力 を上層の入力にします。抽象度の高い系列特徴を学べます。
- Transformerへの置き換え:RNNの本質的な弱点は、 が に依存するため 時間方向に並列化できない(長系列で遅い)ことと、ゲートで緩和してもなお超長距離依存が苦手なことです。これを、再帰を捨てて全時刻を一度に相互参照する 注意機構 で解いたのが 注意機構(Transformer)で、現在の系列モデルの主流になりました。RNN→LSTM/GRU→Transformer という流れで理解しておくと位置づけが明確です。
⚠️ よくある誤解・落とし穴
- 「LSTM/GRUなら勾配消失は完全に消える」:消えません。緩和 するだけです。忘却ゲートが小さく学習されれば は依然として縮みますし、超長系列では実務上の限界があります。
- 「勾配クリッピングで消失も直る」:直りません。クリッピングは 爆発 専用(大きすぎる勾配を縮める)。消失は構造(ゲート)で対処します。
- 「RNNは並列化できる」:時間方向には できません。 が を待つため逐次計算です。バッチ方向の並列だけが可能で、これがTransformer台頭の一因です。
- 「ゲートはオン/オフのスイッチ」:違います。 出力の 連続値 (弁の開度)で、要素ごとに別の開度を取ります。
- BPTTは全系列を保持する:展開した全時刻の活性を逆伝播まで保持するためメモリを食います。実務では一定長で打ち切る 打ち切りBPTT(truncated BPTT) を使います。
対応するシミュレーション
simulations/rnn_gradient.py:単純な線形RNNで、時間をさかのぼる勾配が再帰重みの累乗 になることを示します。 なら勾配が指数的に消え(勾配消失)、 なら爆発することを系列長に対する対数軸で可視化します。tanh の微分が1以下なので実際は消失が起きやすいこと、LSTM/GRU がセル状態の加法的経路で勾配の“高速道路”を作りこれを緩和することにも触れます。
関連ノート
- 深層学習アーキテクチャ 目次
- 注意機構(RNNを置き換えたTransformer)
- 誤差逆伝播法(BPTTの土台)
- 活性化関数(飽和と勾配消失)
- 最適化の実務(勾配クリッピング)
- 機械学習テキスト 全体目次