🎓 レベル:標準 | 重要度:B(標準)
📎 前提:勾配降下法・モーメンタムとAdam系最適化(最適化器)
要点(BLUF)
- 最適化「器」(SGD・Adam)を選ぶことと、それを「うまく回す」ことは別問題。本ノートは後者、つまり学習率の動かし方・バッチサイズ・勾配クリッピング・学習曲線の読み方という実践知に集中します。
- 学習率(lr)が最重要ハイパラ。大きすぎれば発散、小さすぎれば遅い・悪い解に居座る。だから固定せずスケジュールで動かすのが定石です。
- 検証損失(学習曲線)を見ずに学習を回すのは計器を見ずに飛ぶのと同じ。曲線の形から「過学習・未学習・lr不適」を診断して手を打ちます。
なぜ学習率が最重要なのか
更新式はどの最適化器でも本質的に「勾配の方向へ歩幅 だけ進む」形です。
ここで が学習率(歩幅)、 が勾配(Adam なら適応的にスケールされた勾配)。**要するに は「1歩でどれだけ動くか」**で、ここを外すと他をどれだけ調整しても学習は成立しません。
- が大きすぎる:谷を飛び越えて損失が振動・発散する。損失が
nanになるのは大抵これです。 - が小さすぎる:1歩が小さく収束が遅い。さらに、浅いくぼみ(鞍点・悪い局所解の縁)から抜け出せずそこに居座ることがあります。
- ちょうど良い の帯は狭い。しかも学習の序盤(パラメータが乱雑)と終盤(最適点付近)で最適な歩幅は違います。
だから「1つの良い を固定で当てる」のではなく、学習の進行に応じて を変える=スケジュールを組みます。最適な初期値の探索自体は ハイパーパラメータ最適化 の手法(グリッド/ランダム/ベイズ最適化)で行います。
xychart-beta
title "学習率の大きさと損失のイメージ"
x-axis "更新ステップ" 0 --> 10
y-axis "損失" 0 --> 10
line [9, 9.5, 8.8, 9.7, 8.5, 9.9, 8.2, 9.8, 8.6, 9.5, 8.8]
line [9, 6, 4.2, 3, 2.2, 1.7, 1.4, 1.2, 1.1, 1.05, 1.0]
line [9, 8.7, 8.4, 8.1, 7.85, 7.6, 7.4, 7.2, 7.05, 6.9, 6.8]
上から順に「大きすぎ(振動・発散)」「ちょうど良い(速く下がる)」「小さすぎ(遅い)」のイメージです。
学習率スケジュール
学習を進めながら を変える代表パターンです。
① ステップ減衰(step decay)
一定エポックごとに を定数倍(例:30エポックごとに 0.1 倍)で落とします。
要するに「段階的に歩幅を縮める」。実装が単純で古典的なCNNで広く使われましたが、いつ・どれだけ落とすか()を手で決める必要があります。
② コサインアニーリング(cosine annealing)
全学習期間 にわたり、 をコサインカーブで滑らかに最小値へ落とします。
要するに「最初はゆっくり、中盤で一気に、最後はまたゆっくり」減らす。中盤で大きく動いて探索し、終盤は歩幅を絞って細かく収束させる――実務で経験的に良いとされてきた挙動を、閾値の手調整なしに自動で実現します。Transformer 系・大規模事前学習でほぼ標準になっています。なお最小値はゼロではなく最大値の 1/10 程度まで落とすレシピがよく使われます。
派生:ウォームリスタート(cosine annealing with warm restarts, SGDR) は、コサインで底まで下げたら を周期的に跳ね上げて再び下げる。複数の解を渡り歩いてアンサンブル的な効果を狙います。
③ ウォームアップ(warmup)
学習の最初だけ をゼロ付近から目標値まで線形に上げる短い助走区間です。その後に上記②などの減衰へ繋ぎます(「線形ウォームアップ+コサイン」が定番)。
なぜ必要か:学習序盤はパラメータがランダムで勾配が大きく暴れやすい。いきなり大きな を当てると初手で発散します。最初を小さく抑え、状態が落ち着いてから本来の大きな に乗せることで、より高いピーク学習率に耐えられ、結果として最終性能も上がりやすくなります。特に後述の大バッチ学習や Transformer の Adam では事実上必須です。ウォームアップ期間は全ステップの 0.1〜0.5% 程度が目安とされます(要最新確認:適切な長さはモデル・データ規模に依存)。
xychart-beta
title "学習率スケジュールの比較(ウォームアップ+減衰)"
x-axis "学習の進行" 0 --> 10
y-axis "学習率" 0 --> 10
line [9, 9, 9, 1, 1, 1, 0.1, 0.1, 0.1, 0.1, 0.1]
line [9, 8.7, 7.8, 6.4, 5, 3.6, 2.2, 1.2, 0.5, 0.15, 0.1]
line [1, 5, 9, 8.8, 8.3, 7, 5.2, 3.2, 1.5, 0.5, 0.1]
線①ステップ減衰(階段状)、②コサイン(滑らかなS字減衰)、③ウォームアップ+コサイン(最初に上昇してから減衰)。
ミニバッチサイズの影響
1回の更新で勾配を平均する標本数 がバッチサイズです。これは速度・安定性・汎化に効きます。
- が大きい:勾配の推定が安定(分散が小さい)。GPU を埋めやすく1エポックが速い。ただし更新が滑らかすぎて鋭い極小(sharp minima)に落ちやすく、汎化が落ちることが報告されています。
- が小さい:勾配にノイズが乗るが、そのノイズが正則化のように働き平坦な解に導いて汎化を助けることがある。一方で更新ごとのバラつきは大きい。
線形スケーリング則(linear scaling rule)
バッチサイズを 倍にしたら、学習率も 倍にするという実務則です。
直観:勾配は 個の標本平均なので、 を増やすと勾配推定の分散が下がる=1ステップの「実効的な情報量」が増えます。それに合わせて歩幅も大きく取らないと、せっかく大きなバッチで計算した割に進みが遅くなります。ResNet を ImageNet で大バッチ(〜8192)短時間学習する際にこの則が使われました。
ただし重要な但し書き(要最新確認):
- 線形スケーリングが成り立つのはある範囲まで(経験的にバッチ 〜8000 程度が目安)。それを超えると破綻し、より保守的な平方根スケーリング()の方が合うという報告があります。
- Adam が主流になって関係が変わった面があり、Adam では平方根スケーリングが良いとする実証もあります。最適なスケーリングは最適化器・モデル・データに依存するので、鵜呑みにせず小規模で確認してください。
- 大バッチで学習率を上げるときは、前述のウォームアップが事実上必須(序盤の大勾配×大lr=発散を防ぐため)。
勾配クリッピング
勾配のノルムに上限を設けて、超えたら縮める手法です。勾配爆発(exploding gradients)への対症療法で、特に RNN/LSTM や Transformer の学習で使います。
要するに「勾配ベクトルが長すぎたら、向きはそのまま長さだけ に切り詰める」(clip-by-norm)。向きを保つので学習の方向は壊さず、一発の暴れた更新だけを抑えられます。
- なぜ RNN で重要か:誤差逆伝播を時間方向に展開(BPTT)すると、同じ重み行列を時系列の長さぶん繰り返し掛けるため、固有値次第で勾配が指数的に膨張し得ます。これが勾配爆発で、1ステップでパラメータが吹き飛んで
nanになります。クリッピングはこの瞬間的な膨張を平らに均します。 - 閾値 の目安は 1.0〜5.0 がよく使われます(モデル依存。要最新確認)。
- 注意:クリッピングは「爆発」専用で「消失(vanishing)」は救えません。小さすぎる勾配を大きくはできない。消失側はアーキテクチャ(LSTM/GRU・残差接続・正規化)で対処します。
学習曲線の診断
横軸=エポック(または反復)、縦軸=損失で、訓練損失と検証損失を重ねて描いたものが学習曲線です。これは学習の「計器盤」で、形から原因を読みます。土台となる訓練/検証/テストの分け方は 訓練・検証・テストと交差検証 を参照。
| 曲線の形 | 診断 | 打ち手 |
|---|---|---|
| 訓練・検証ともに高止まり(早く頭打ち) | 未学習(高バイアス) | モデルを大きく/学習を長く/ を上げる/正則化を弱める |
| 訓練は下がり続けるが検証が途中から上昇(U字) | 過学習(高バリアンス) | 正則化・ニューラルネットの正則化 を強める/データ拡張/早期終了 |
| 訓練・検証ともに下がり続けて終わる | 未収束(打ち切り早すぎ) | エポックを増やす |
損失が振動・スパイク・nan | が大きすぎ/勾配爆発 | を下げる/ウォームアップ/勾配クリッピング |
| 検証が訓練より低い | データリーク or 検証セットが楽すぎ | 分割・前処理を疑う |
ポイントは訓練と検証の「差」:差が小さく両方高い=バイアス、差が大きい(訓練だけ低い)=バリアンス。この読み分けが 汎化と過学習・バイアスバリアンス分解 の実地版です。
flowchart TD
A["学習曲線を描く(訓練損失・検証損失)"] --> B{"損失が振動 / nan ?"}
B -- "はい" --> C["学習率を下げる<br/>ウォームアップ・勾配クリッピング"]
B -- "いいえ" --> D{"訓練損失は十分下がった?"}
D -- "いいえ(高止まり)" --> E["未学習:容量を増やす<br/>長く学習・正則化を弱める"]
D -- "はい" --> F{"検証損失も追従して下がる?"}
F -- "途中から上昇(U字)" --> G["過学習:正則化を強める<br/>データ拡張・早期終了"]
F -- "まだ下がり続ける" --> H["未収束:エポックを増やす"]
F -- "良好に収束" --> I["完了:チェックポイント保存"]
学習を回す周辺の実務
- エポック / 反復(iteration)/ ステップ:1エポック=訓練データ全体を1周。1反復=1ミニバッチで1更新。。スケジュールやログは「ステップ単位」で管理すると、バッチサイズを変えても整合します。
- 収束判定:固定エポックで止めるほか、検証損失が一定回数(patience)改善しなければ止める早期終了が実用的。最良時点のモデルを保持します。
- チェックポイント:エポックごと(または一定ステップごと)にモデル重み・最適化器状態・スケジューラ状態を保存。検証最良のものを別途残し、クラッシュからの再開にも使います。
- 再現性(シード):乱数シードを固定(重み初期化・データシャッフル・ドロップアウト)。ただし GPU 演算の非決定性や並列性で完全一致しないことがある点は割り切る。実験比較ではシードを揃えることが大事です。
実務のレシピ(順番が大事)
- まず動かす:小さなモデル・少データ・短いエポックで、損失が下がること・
nanが出ないことを確認。ここでパイプライン(前処理・損失・ログ・チェックポイント)を固める。 - 過学習できることを確認:ごく少量のデータで訓練損失をほぼ0まで落とせるか。落とせないなら実装バグを疑う(学習を始める前の最重要チェック)。
- 学習率を合わせる:これが最優先ハイパラ。スケジュール(ウォームアップ+コサイン等)を入れる。
- バッチサイズを決め、線形/平方根スケーリングで lr を整合(独立に弄らない)。
- 正則化を調整:ニューラルネットの正則化・重み減衰・データ拡張・早期終了で検証損失を最小化。
- その他のハイパラを ハイパーパラメータ最適化 で詰める。
鉄則:一度に1つだけ変える。複数同時に変えると、効いた要因が分からなくなります。
⚠️ よくある誤解・落とし穴
- 学習率を固定したまま回す:最初に良くても終盤で大きすぎ、最適点付近で振動して収束しきれない。スケジュールで落とすのが基本です。
- 検証損失を見ずに訓練損失だけで判断する:訓練損失はいくらでも下げられる(過学習)。汎化を測るのは検証損失。学習曲線を必ず両方描く。
- バッチサイズと学習率を独立に考える:バッチを倍にしたのに lr を据え置くと進みが鈍る/逆も発散。セットで動かす(線形 or 平方根スケーリング、要最新確認)。
- 勾配クリッピングで消失も直ると思う:クリッピングは爆発専用。消失はアーキテクチャ側の問題。
- 大バッチでウォームアップを省く:序盤の大勾配×大lrで初手発散しがち。大バッチほどウォームアップが効きます。
- 「コサインさえ使えば良い」と銘柄で考える:スケジュールは手段。ピーク lr が外れていれば何を使っても無駄。まず lr のオーダーを合わせる。
- 最小値までゼロに落とす:終盤に学習が止まる。最大値の 1/10 程度で止めるレシピが一般的。
対応するシミュレーション
simulations/early_stopping.py:過学習しやすい小さなMLPを長く学習させ、訓練誤差と検証誤差をエポックごとに記録します。訓練誤差は下がり続けるのに検証誤差は底を打って上昇に転じることを(対数軸で)可視化し、検証誤差が最小のエポックで止める早期終了が追加の正則化項なしに汎化を保つことを示します。L2正則化に近い効果をもちます(正則化の理論)。なお学習率と収束の挙動そのものは 勾配降下法・モーメンタムとAdam系最適化 のシミュレーションが対応します。
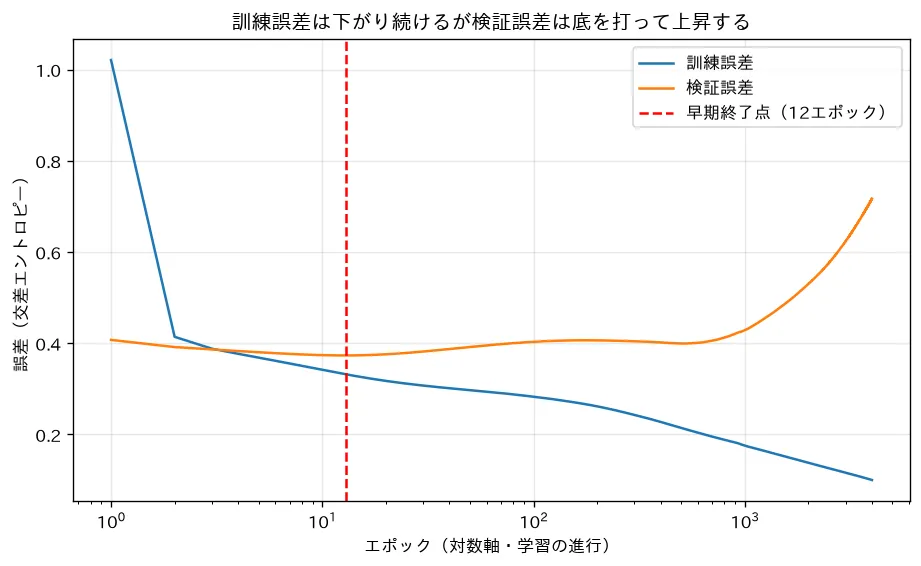
まとめ
- 最適化器を選ぶこととうまく回すことは別。回す側の主役は学習率スケジュール・バッチサイズ・勾配クリッピング・学習曲線診断。
- lr が最重要ハイパラ。固定せずウォームアップ+(コサイン等)減衰で動かす。
- バッチと lr はセットで調整(線形/平方根スケーリング、要最新確認)。RNN系では勾配クリッピングで爆発を抑える。
- 学習曲線(訓練 vs 検証)を計器として読む。差が小さく高い=未学習、訓練だけ低い=過学習、振動/
nan=lr過大。 - 進め方は「まず動かす→過学習できる確認→lr→バッチ整合→正則化→他ハイパラ」、一度に1つだけ変える。