🎓 レベル:標準 | 重要度:B(標準)
📎 前提:汎化と過学習・バイアスバリアンス分解 | 理論:正則化の理論(重み減衰=L2=MAP)
要点(BLUF)
- ニューラルネット(NN)はパラメータが過剰なので、放っておくと訓練データを丸暗記して過学習する。だから正則化が必須です。
- 中核は Dropout:訓練時に各ユニットを確率 でランダムに0にし、指数個のサブネットワークを暗黙にアンサンブルして汎化を稼ぐ。推論時は全ユニットを使い、出力をスケール調整します。
- これに 重み減衰(L2)・データ拡張・早期終了・ラベルスムージングを組み合わせるのが実務の標準セットです。
1. なぜ NN には正則化が要るのか
NN は層を重ねるほどパラメータ数が爆発します。現代のモデルはデータ点数よりパラメータ数のほうが多い(過剰パラメータ化)ことが普通です。この状況では、モデルは訓練データを完全に通る関数をいくらでも作れてしまい、訓練誤差がほぼ0になっても汎化誤差(未知データでの誤差)が大きいという典型的な過学習が起きます。
これはバイアス-バリアンス分解(汎化と過学習・バイアスバリアンス分解)でいう「バリアンスが大きい」状態です。正則化とは、モデルの実効的な複雑さ(表現できる関数の幅)を制限して、バイアスを少し犠牲にバリアンスを大きく下げる操作だと捉えると見通しが良くなります。
graph TD
A["NNは過剰パラメータ → 過学習しやすい"] --> B["正則化でバリアンスを下げる"]
B --> C["重み減衰 (L2 / weight decay)"]
B --> D["Dropout (アンサンブル的)"]
B --> E["データ拡張 (不変性を教える)"]
B --> F["早期終了 (early stopping)"]
B --> G["ラベルスムージング (過信を抑える)"]
C --> H["汎化誤差の改善"]
D --> H
E --> H
F --> H
G --> H
図の要点:正則化は「複雑さの抑え方」が違うだけで、ゴールは全部「汎化誤差を下げる」で共通です。
2. 重み減衰(weight decay)= L2 正則化
最も古典的で、いまも全モデルに効くのが重み減衰です。損失にパラメータの2乗ノルムを足します。
要するに:「大きな重みにはペナルティを課す」。重みを0方向に引っ張ることで、特定の入力に過敏に反応する鋭い関数を避け、なめらかな関数を選ばせます。
理論的な意味づけ(L2 = ガウス事前分布での MAP 推定、なぜ過学習を抑えるか)は 正則化の理論 と 正則化(Ridge・Lasso・Elastic Net) にあるのでここでは繰り返しません。NN 固有の注意点だけ押さえます。
勾配で見ると「毎ステップ重みを縮める」
L2 項の勾配は なので、勾配降下の更新は
要するに:毎ステップ重みに を掛けて少しずつ縮める。これが「weight decay(重みの減衰)」という名前の由来です。
Adam では「weight decay ≠ L2」になる(要最新確認)
ここが NN 実務でハマりやすい落とし穴です。SGD では L2 正則化と weight decay は同じですが、Adam のような適応的最適化では一致しません。
- Adam は各パラメータの勾配履歴で学習率を調整します。L2 項を「損失に足す」方式(=勾配に を混ぜる)だと、その正則化項まで適応的学習率でスケールされてしまい、パラメータごとに実効的な減衰の強さがバラバラになります。
- 解決策が AdamW:weight decay を勾配計算から切り離し(decoupled)、更新の最後に を直接掛ける。これで全パラメータが均等に縮みます。
- 経験的に AdamW は Adam+L2 より汎化が良いことが多く、特にデータ量に対してモデルが大きいほど差が出ます。現代の深層学習・LLM学習では AdamW が事実上の標準です(最新の最適化手法は動きが速いので要最新確認)。
実務メモ:Transformer 系では BatchNorm/LayerNorm のスケール・バイアスや埋め込みには weight decay をかけない運用が一般的です。
3. Dropout(このノートの中心)
何をするか
訓練の各ステップで、層の各ユニットを独立に確率 で0にする(=ドロップする)。残ったユニットだけで順伝播・逆伝播します。どのユニットが落ちるかはミニバッチごとに毎回ランダムに引き直します。
数式で書くと、層の出力 に対しマスク (各要素が確率 で1、 で0のベルヌーイ)を要素積します。
要するに:毎回ネットワークの一部をランダムに「壊して」学習させる。これがなぜ効くのかが本題です。
graph LR
subgraph T["訓練時:毎回ランダムに一部を落とす"]
direction TB
I1["入力"] --> H1["h1"]
I1 --> H2["h2 (×ドロップ)"]
I1 --> H3["h3"]
I1 --> H4["h4 (×ドロップ)"]
H1 --> O1["出力"]
H3 --> O1
end
subgraph E["推論時:全ユニットを使う+スケール調整"]
direction TB
I2["入力"] --> G1["h1"]
I2 --> G2["h2"]
I2 --> G3["h3"]
I2 --> G4["h4"]
G1 --> O2["出力"]
G2 --> O2
G3 --> O2
G4 --> O2
end
T --> E
図の要点:訓練では毎回違うサブネットを使い、推論では全部つなぎ直す。だから「掛け算の整合」を取るスケーリングが必要になります(後述)。
解釈1:指数個のサブネットワークのアンサンブル
ユニットが 個あれば、ドロップのオン・オフの組み合わせは 通り。Dropout で訓練するとは、これら指数個のサブネットワーク(重みを共有した薄いネット)を少しずつ訓練し、推論時に近似的に平均することに相当します。
これは アンサンブルの原理 とまったく同じ発想です。アンサンブルは「多様な弱学習器の予測を平均すると、各モデルのバリアンスが打ち消し合って汎化が上がる」。Dropout は、1つのネットワークの中でこの多数決を擬似的にやっているわけです。バギングが「データを変えて多様性を作る」のに対し、Dropout は「ネットワーク構造を毎回変えて多様性を作る」と捉えると対応が見えます。
解釈2:共適応(co-adaptation)の抑制
もう一つの説明が共適応の抑制です。普通に学習すると、あるユニットが「隣のユニットBが必ず特徴Xを出してくれる」前提に依存して、自分はその穴埋めだけをする、という過度な役割分担が起きがちです。これは訓練データには効きますが、未知データでは脆い(Bが少し違う反応をすると連鎖的に崩れる)。
Dropout では「いつ誰が消えるか分からない」ので、各ユニットは特定の相棒に頼れず、単独でも意味のある特徴を学ばざるを得ない。結果として、より頑健で冗長性のある表現が育ちます。
2つの解釈は矛盾しません。「アンサンブル」はマクロな見方、「共適応抑制」はミクロな見方で、同じ現象の別の言葉です。
推論時のスケーリング(なぜ必要か・inverted dropout)
ここが Dropout で一番つまずく点です。訓練時は平均して 割のユニットしか活性化していないのに、推論時に全ユニットを使うと、次の層に入る信号の合計(期待値)が 倍に膨らんでしまいます。スケールが訓練時と推論時でズレると、出力が壊れます。
これを合わせる方法が2つあります。
- 推論時にスケールダウン(オリジナルの定式化):推論時に各ユニットの出力に を掛けて、訓練時の期待スケールに合わせる。
- 訓練時にスケールアップ(inverted dropout、現代の標準):訓練時に残ったユニットを 倍しておく。こうすると訓練時から期待スケールが揃うので、推論時は何もせず全ユニットをそのまま使える。
要するに:訓練側で先にスケールを補正しておけば、推論コードはドロップのことを考えなくてよい。実装が綺麗になるので、ライブラリ(PyTorch の nn.Dropout 等)はすべてこの inverted dropout を採用しています。
補足:推論時にもあえて Dropout を残し、複数回サンプリングして予測のばらつきを取る Monte Carlo Dropout という不確実性推定の使い方もありますが、これは「正則化」とは別目的の応用です(性能は Deep Ensembles に劣るという報告もあり、ここは要最新確認)。
4. データ拡張(data augmentation)
訓練データに、ラベルを保つ変換を施した「水増しサンプル」を加える手法です。画像なら回転・左右反転・平行移動・拡大縮小・切り出し(crop)・色調変化など。
flowchart LR
A["元画像 + ラベル: 猫"] --> B["左右反転"]
A --> C["少し回転"]
A --> D["ランダム切り出し"]
A --> E["明るさ変更"]
B --> F["どれもラベルは 猫 のまま"]
C --> F
D --> F
E --> F
F --> G["モデルは これらの変化に対し不変であれと学ぶ"]
なぜ汎化が上がるのか:不変性を教えている
ポイントは「データが増える」だけではありません。変換しても答えは同じという制約をモデルに教えています。猫は左右反転しても猫、少し傾いても猫です。この不変性(invariance)の事前知識をデータ経由で注入することで、モデルは本質的でない特徴(向き・位置・明るさ)に振り回されなくなります。
つまりデータ拡張は「新しい情報を足す」のではなく「こういう変化は無視してよい、という構造的事前分布を入れる」正則化です。だからドメインに合った変換を選ぶことが決定的に重要です(後述の落とし穴)。
代表的な発展形:
- Mixup:2枚の画像とラベルを線形補間して合成。決定境界をなめらかにします。
- Cutout:画像の一部を四角くマスク。1箇所のパッチへの依存を防ぎます。
- RandAugment:複数の変換をランダムに組み合わせる自動化手法。2つのハイパラだけで近 SOTA を出せる実務的な既定値(この領域は手法の入れ替わりが速く要最新確認)。
5. 早期終了(early stopping)
訓練を進めると訓練誤差は下がり続けますが、検証誤差はある時点で底を打ち、その後上昇に転じます(過学習の始まり)。検証誤差が最小になった時点で学習を止め、その重みを採用するのが早期終了です。
xychart-beta
title "訓練誤差は下がり続けるが、検証誤差は途中で反転する"
x-axis "エポック" [1, 5, 10, 15, 20, 25, 30]
y-axis "誤差" 0 --> 1
line "訓練誤差" [0.9, 0.5, 0.3, 0.18, 0.1, 0.06, 0.03]
line "検証誤差" [0.92, 0.55, 0.38, 0.3, 0.28, 0.33, 0.42]
図の要点:検証誤差が底を打った付近(この例では20エポック前後)で止めるのが早期終了。L2 と似た効果を持つこと(暗黙の正則化)は 正則化の理論 を参照。
実質的に「重みが大きく育つ前に止める」ので、学習時間の制限が複雑さの制限になるという意味で正則化として働きます。実装も軽く、ほぼ全タスクで併用されます。
6. ラベルスムージング(label smoothing)
分類で one-hot の正解ラベル(正解クラス1、他は0)を少しなまらせる手法です。クラス数 、強さ として、
正解クラスの目標を ではなく (例:0.9程度)に、他クラスを ではなく にします。
要するに:「絶対にこのクラスだ(確率100%)」とモデルに言わせない。
なぜ効くか
one-hot を目標にすると、softmax の性質上モデルは正解の logit を他より際限なく大きくしようとし、出力確率が1に張り付く**過信(overconfidence)**に陥ります。過信したモデルは訓練データのノイズまで覚え込みやすく、汎化と確率の信頼性(キャリブレーション)が悪化します。
ラベルスムージングは出力分布のエントロピーに下限を設け、logit が飽和するのを防ぎます。結果としてより頑健な特徴が育ち、汎化とキャリブレーションが改善します。画像分類や機械翻訳・LLM 学習で広く使われます(最新の使われ方は要最新確認。選択的分類のキャリブレーションを悪くする場合もあるとの報告あり)。
⚠️ よくある誤解・落とし穴
- Dropout を推論時にも(無自覚に)使ってしまう:Dropout は訓練時だけの操作です。推論時に有効のままだと出力が毎回ランダムに変動し、性能が落ちます。フレームワークでは
model.eval()(PyTorch)/training=False(Keras)で必ずオフにすること。inverted dropout のおかげで、オフにすればスケール補正は自動で整合します。 - Dropout と BatchNorm を順序を考えずに併用する:Dropout を BatchNorm の前に置くと、訓練時と推論時で「BNが見る入力の分散」がズレます(variance shift)。BN は学習中に蓄積した統計量を推論時に使うのに、Dropout は訓練→推論でユニットの分散を変えてしまうためです。これが両者を素朴に併用すると性能が落ちる主因。実務では Dropout は全 BN 層の後に置く、あるいは BN を使う層では Dropout を避ける、のが定石です(重み初期化と正規化 のBN挙動と合わせて理解すると良い)。
- データ拡張のやりすぎ・ドメイン不適合:拡張は「ラベルを保つ変換」でなければなりません。手書き数字で左右反転すると「2」と「5」が崩れる、医療画像で過度な色変換が病変を消す、などラベルが変わる/壊れる変換を入れると逆効果です。「この変換をしても答えは本当に同じか?」を常に問うこと。
- 正則化の入れすぎ(過小適合):Dropout 率を上げすぎる・λを大きくしすぎると、今度はモデルが訓練データすら学べずバイアスが過大になります。正則化は「過学習を確認してから」段階的に強めるのが基本です。
- Dropout を最終出力層に強くかける:出力直前に高い率の Dropout をかけると予測が不安定になりがち。一般に Dropout は中間の全結合層で効き、畳み込み層では効きにくい(空間相関のため)とされます。
まとめ
NN の正則化は「複雑さの抑え方」のバリエーションです。重み減衰(L2/AdamW)で重みを縮め、Dropoutで指数個のサブネットを暗黙にアンサンブルし共適応を断ち、データ拡張で不変性を教え、早期終了で育ちすぎる前に止め、ラベルスムージングで過信を防ぐ。これらは排他ではなく組み合わせて使うのが標準です。中核となる Dropout は「訓練でランダムに壊し、推論で全部つなぎ直す(inverted dropout でスケール整合)」という一点を押さえれば、仕組み・解釈・実装上の注意がすべて繋がります。
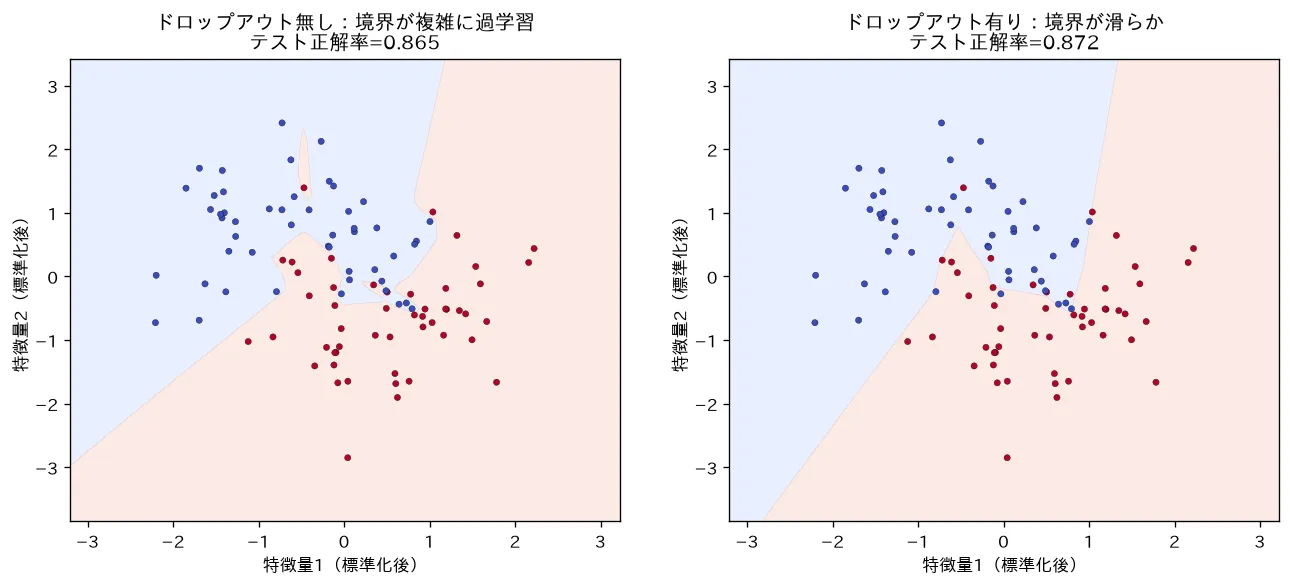
対応するシミュレーション
simulations/dropout_ensemble.py:ノイズの多い三日月データに大きめの MLP(隠れ200〜300ユニット)を当て、ドロップアウトの有無で比較します。無しは決定境界がノイズ点まで拾って過学習し訓練とテストの差が大きい一方、有りは毎回違う部分ネットを学ぶ暗黙のアンサンブルになって境界が滑らかになり、訓練とテストの差が縮みテスト正解率も改善することを可視化します(逆ドロップアウトの実装つき)。