🎓 レベル:標準 | 重要度:B(標準)
📎 前提:Transformer | 関連:主成分分析と次元削減(次元削減との対比)
要点(BLUF)
- 表現学習とは、生データ(単語・画像・カテゴリ)を、意味の近さが距離に反映された「良いベクトル」へ自動で変換する学習のこと。
- **埋め込み(embedding)**は離散シンボルを密な連続ベクトルに移す写像で、
one-hotの「疎で意味なし」を「密で意味あり」に変える。word2vec は文脈から学び、king − man + woman ≈ queenのような線形構造を獲得します。 - 大規模データで表現を学ぶ事前学習と、それを下流タスクに転用する転移学習・ファインチューニングが、現代の深層学習の標準レシピです。
1. 表現学習とは
機械学習の性能は「どんな入力特徴を与えるか」でほぼ決まります。古典的には、人間がドメイン知識を使って特徴量を手で設計していました(画像なら SIFT/HOG、テキストなら TF-IDF、信号なら FFT のピークなど)。これを 特徴量エンジニアリング と呼びます。
表現学習(representation learning) は、この特徴設計そのものをデータから学習する立場です。生データ を、下流タスクに使いやすいベクトル に写す関数 を、データから最適化します。
要するに:「どんな数字の並びで世界を見るか」を人間が決めるのではなく、データに決めさせる。
なぜ深層が表現学習に強いのか
深層ネットワークは層を重ねることで 階層的(hierarchical)な表現 を作れるからです。
- 浅い層:エッジ・色・短い文字列など低次の汎用的な特徴
- 中間層:テクスチャ・パーツ・句などの中間概念
- 深い層:「猫の顔」「文の意味」などのタスク寄りの高次概念
各層が前の層の出力を組み合わせて、より抽象的な特徴を構成していきます。低次の特徴ほど多くのタスクで共通に使えるため、後述の転移学習が効く理由にもなります。
flowchart LR
X["生データ x(画素・単語)"] --> L1["浅い層:エッジ・文字"]
L1 --> L2["中間層:パーツ・句"]
L2 --> L3["深い層:意味・概念"]
L3 --> H["表現 h(特徴ベクトル)"]
H --> T["下流タスク(分類など)"]
2. 埋め込み(embedding):離散を連続へ
埋め込み は、語彙やカテゴリのような離散シンボルを、低次元の密な実数ベクトルへ対応づける写像です。NLP の単語、推薦のアイテムID、カテゴリ変数などに広く使われます。
one-hot との対比(ここが本質)
語彙サイズ の単語を素朴に表すと one-hot ベクトル になります。 番目の単語は
これには二つの致命的な弱点があります。
- 疎で高次元: が数万〜数十万になり、ほぼ全成分が 0(次元の呪い)。
- 意味を持たない:任意の異なる単語 について すべての単語ペアが等距離。「猫」と「犬」も「猫」と「微分」も同じ距離で、近さの情報がゼロです。
埋め込みはこれを、学習された行列 ()で密ベクトルに移します。
要するに:one-hot との掛け算は「埋め込み行列の 列目を取り出す」操作。埋め込み層はルックアップテーブルそのものです。
次元(典型的に 100〜1000)の連続空間に置くことで、ベクトル間の距離・内積が意味の近さを表せるようになります。これが one-hot との決定的な差です。
| one-hot | 埋め込み | |
|---|---|---|
| 次元 | 語彙サイズ (巨大) | (小さい) |
| 密度 | 疎(1つだけ1) | 密(全成分が実数) |
| 意味 | 持たない(全ペア等距離) | 近い意味=近いベクトル |
| 学習 | 固定 | データから学習 |
3. word2vec:文脈から単語を学ぶ
word2vec(Mikolov ら, 2013)は、単語埋め込みを学ぶ代表的手法です。核にあるのは 分布仮説(distributional hypothesis):「ある単語の意味は、その周囲に現れる単語たち(文脈)で決まる」。よって文脈を予測するタスクを解かせれば、意味を反映した埋め込みが副産物として得られます。
word2vec には2つの構成があります。
flowchart TB
subgraph SG["Skip-gram:中心語 → 文脈語"]
C1["中心語"] --> P1["周辺語を予測"]
end
subgraph CB["CBOW:文脈語 → 中心語"]
P2["周辺語の平均"] --> C2["中心語を予測"]
end
Skip-gram の定式化
各単語に 中心語ベクトル と 文脈語ベクトル の2種類を持たせます。中心語 が与えられたとき、文脈語 が出る確率を softmax で定義します。
要するに:内積 が大きい(=方向が近い)単語ほど「文脈に来やすい」とみなす。共起しやすい単語どうしのベクトルが近づくよう押される。
長さ の文に対し、窓幅 の文脈ペアすべての負の対数尤度を最小化します。
中心語ベクトルに関する勾配は次の形で、「正解の文脈語 」から「モデルが予測する文脈語の期待値」を引いた予測誤差になります(勾配降下の更新と同じ構造)。
CBOW は逆向きで、周辺語ベクトルの平均 から中心語を当てます。
ざっくり、Skip-gram は低頻度語・複雑な語に強く、CBOW は高頻度語で速い、という使い分けです。
負例サンプリング(softmax が重い問題への対処)
分母の和 は語彙全体(数十万語)にわたるため、毎ステップ計算するのは非現実的です。そこで 負例サンプリング(negative sampling) を使い、「全語の分布を当てる多クラス問題」を「正しい共起ペアか、ランダムな雑音ペアかを見分ける二値分類」に置き換えます。Levy & Goldberg の整理では、最大化する目的は
ここで はシグモイド、 は雑音分布、 は負例数(数個〜十数個)。
要するに:「本物の文脈語との内積は大きく、ランダムに引いた無関係語との内積は小さく」を 個の負例だけで押す。全語を計算せず済むので一気に軽くなります(確率的勾配降下と同じ「全部見ずに近似」の発想)。
4. 埋め込み空間の性質:意味の幾何
word2vec の埋め込みの面白さは、意味の近さがベクトルの近さとして現れることです。類似度はふつうコサイン類似度で測ります。
線形構造(アナロジー)
有名なのが king − man + woman ≈ queen。意味の差分がベクトルの差分として揃う、という現象です。
つまり「男→女」という変化が、どの語対でもほぼ同じ方向ベクトルになっている。これは「性別」という意味軸が空間内の一定方向として埋め込まれていることを示します。なぜ生じるかは共起統計の構造から説明されており、明示的にそう学習させたわけではない創発的な性質である点が重要です([1901.09813] が理論的整理)。
graph LR
man["man"] -->|"性別の方向(→ 女性)"| woman["woman"]
king["king"] -->|"同じ方向 ≈"| queen["queen"]
次元削減との関係
埋め込みは 次元(数百次元)なので直接は見えません。可視化には 次元削減 を使い、2〜3次元へ落として「近い意味が固まる」様子を確認します。
- 主成分分析と次元削減:分散最大の方向で線形に低次元化(PCA)。大域構造の把握に。
- カーネルPCAと多様体学習:t-SNE / UMAP など、近傍構造を保つ非線形手法。クラスタの可視化に向く。
注意したいのは向きの違いです。PCA 等は「与えられたデータを低次元に映す」のに対し、埋め込み学習は「離散シンボルに意味ある座標を与える」。後者は次元削減の前段で、可視化はその座標を覗く手段です。
5. 事前学習と転移学習
考え方
- 事前学習(pretraining):大規模データ(Wikipedia、巨大画像集合など)で、まず良い表現 を学ぶ。
- 転移学習(transfer learning):その を初期値として、別の下流タスク(手元の小さなデータ)に流用する。
- ファインチューニング(fine-tuning):下流データで を追加学習し、タスクに合わせて微調整する。
flowchart LR
D1["大規模データ"] --> PT["事前学習(汎用表現を獲得)"]
PT --> W["学習済み重み θ"]
W --> FE["特徴抽出(θを凍結+分類層だけ学習)"]
W --> FT["ファインチューニング(θも追加学習)"]
D2["小さな下流データ"] --> FE
D2 --> FT
FE --> TaskA["下流タスクA"]
FT --> TaskB["下流タスクB"]
転用には二段階あります。
- 特徴抽出(feature extraction):事前学習の重みを凍結し、上に乗せた新しい分類層だけを学習。データが少ないときに過学習しにくい。
- ファインチューニング:上位層(時に全体)を解凍して下流データで更新。タスク固有の特徴まで適応でき、性能は高いがデータと計算を要する。
なぜ効くのか
事前学習で得た低次の汎用特徴を再利用(feature reuse)できるからです。エッジ・テクスチャ・基本的な構文といった特徴は多くのタスクで共通で、これらをゼロから学び直さずに済む。結果として、下流タスクは少ないデータ・短い学習で高精度に到達します。
要するに:良い初期値は「世界の見方の下地」。下地ができていれば、目的に合わせた微調整だけで済む。
6. 自己教師あり学習と文脈依存表現
word2vec が「人手ラベルなしで、文脈予測という擬似タスクから学ぶ」点に注目してください。これは 自己教師あり学習(self-supervised learning) の典型です。データ自身の一部を隠して当てさせる(next word / masked token / 一部画像の復元など)ことで、ラベルなしの大規模データから表現を引き出します。表現学習の現代的な主役です。
word2vec の限界は、各単語に固定の1ベクトルしか与えない点です。「bank(銀行)」と「bank(川岸)」が同じベクトルになってしまう。これを解決するのが 文脈依存表現(contextual embeddings) で、同じ単語でも周囲の文に応じて表現が変わります。
- BERT(masked language modeling による双方向事前学習)などの Transformer ベースのモデルが代表(Transformer が土台)。
- 対照学習(contrastive learning):似たペアを近づけ、異なるペアを遠ざける目的で表現を学ぶ自己教師ありの一族。文・画像の表現学習で広く使われます。
⚠️ 要最新確認:BERT 以降の事前学習・対照学習・文単位の埋め込みは進展が速い領域です。具体的なモデル名・SOTA・推奨手法は最新の文献で確認してください。詳細は 大規模言語モデル 目次 で扱います。
⚠️ よくある誤解・落とし穴
- 「埋め込みの各次元に意味がある」と思い込む:個々の軸が「性別」「時制」のように解釈できるとは限りません。意味は方向の組み合わせとして分散して表現されるのが普通。一部に解釈可能な方向が現れることはあっても、各次元=各概念ではありません。
- 「word2vec の類推は万能」と思う:
a − b + c形式のアナロジーは一定の関係(性別・国-首都など)でよく成り立ちますが、関係や語彙によっては破綻します。最近接語を探す際に入力3語を除外する慣習などにも依存し、過大評価されがちです。あくまで創発的な傾向であって保証ではありません。 - 事前学習データのバイアスをそのまま引き継ぐ:埋め込みは学習コーパスの統計を映すため、コーパスに含まれる社会的バイアス(職業と性別の結びつきなど)まで方向として埋め込みます。下流タスクにバイアスが転移する点は実務上の重大な注意点です。
- 「ファインチューニングすれば必ず良くなる」と考える:下流データが極端に少ない・事前学習ドメインと乖離が大きいと、ファインチューニングは過学習や破滅的忘却を招きます。まず特徴抽出(凍結)から試すのが安全です。
シミュレーション
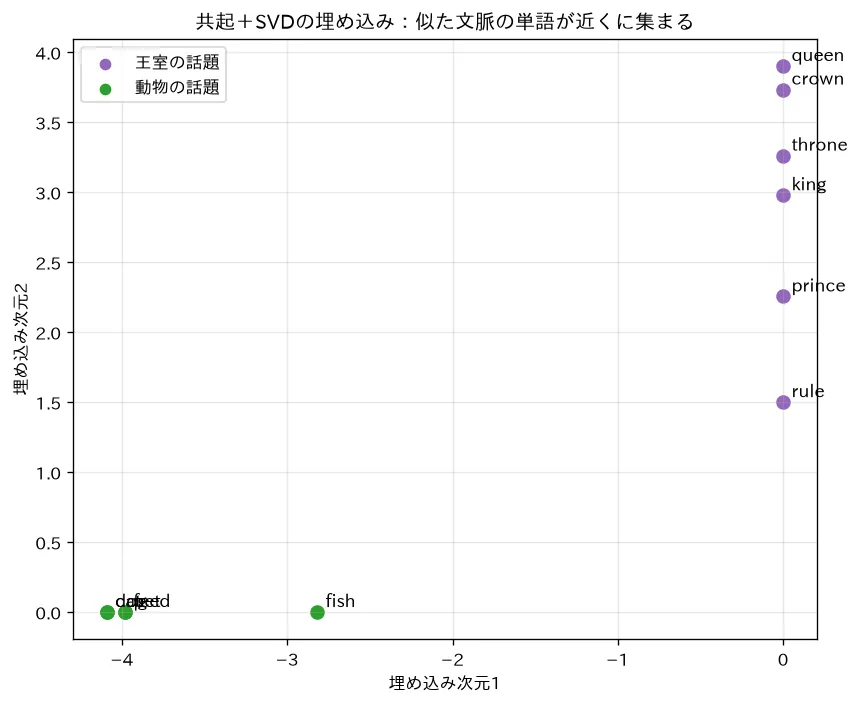
simulations/word_embeddings.py:分布仮説「似た文脈に現れる単語は似た意味」に基づき、小コーパスの単語共起行列を SVD で低次元に圧縮して埋め込みを作ります。王室の単語どうし・動物の単語どうしが近くに集まり、コサイン類似度も同じ話題で高く(king-queen 0.71)違う話題で低い(king-cat 0.00)ことを可視化します。word2vec はこれをニューラルネットの周辺語予測として解いた発展形で、埋め込みは下流タスク(検索拡張生成)の入力に使われます。可視化は t-SNE/UMAP(カーネルPCAと多様体学習)。
まとめ
- 表現学習は「特徴をデータから学ぶ」枠組みで、深層は階層的表現により強力。
- 埋め込みは離散シンボルを密ベクトル化し、one-hot の「疎・無意味・等距離」を「密・有意味・近さあり」に変える。
- word2vec は文脈予測(自己教師あり)で埋め込みを学び、コサイン近さ=意味の近さ、差分の整列としてアナロジーが創発する。
- 事前学習で汎用表現を獲得し、転移学習・ファインチューニングで下流に流用するのが現代の標準。文脈依存表現(BERT・対照学習)が次の発展で、ここは要最新確認。