🎓 レベル:標準 | 重要度:A(必須)
📎 前提:プロンプティングとIn-context learning | 関連:表現学習と埋め込み(埋め込み検索)
要点(BLUF)
- RAG(検索拡張生成)=「検索(retrieval)」で外部知識から関連文書を引いて、LLMの「生成(generation)」の根拠としてプロンプトに注入する仕組みです。
- LLM の知識は事前学習した時点で重みに固まる(パラメトリック知識)ため、最新情報・社内文書・出典が要る場面では幻覚しやすい。RAG は知識を重みの外に置くことでこれを補います。
- 効く理由は3つ。知識更新が容易(インデックスを差し替えるだけ)・出典提示ができる・幻覚(評価・ハルシネーション・安全性)が減る。ただし検索の品質が答えの品質を律速します。
動機:パラメトリック知識の限界
LLM は事前学習で大量のテキストを読み、その知識をモデルの重みの中に圧縮して持っています。これを パラメトリック知識(parametric knowledge) と呼びます。便利ですが、限界があります。
- 知識が固定される:学習を打ち切った時点(カットオフ)以降の出来事は知りません。昨日のニュースも、あなたの会社の社内規定も重みには入っていません。
- 出典がない:重みは「どの文書から学んだか」を覚えていません。だから根拠を示せず、検証もできません。
- 幻覚(ハルシネーション)が出る:知らないことを聞かれても、それらしい流暢な文章を生成してしまう。これはパラメトリック知識への過度な依存が原因の一つです(詳細は 評価・ハルシネーション・安全性)。
重みを焼き直す(ファインチューニング)という手もありますが、知識が変わるたびに再学習するのは高コストで、出典の問題も残ります。「知識をモデルの外に置き、必要なときだけ引いてくる」 ——これが RAG の発想です。
RAG の流れ:検索 + 生成
RAG は名前のとおり Retrieval(検索)と Generation(生成)の2段構えです。ユーザーの質問が来たら、まず外部の知識ベースから関連しそうな文書を引いてきて、それを In-context(プロンプトに入れて与える) の形で LLM に渡し、その文書を根拠に答えさせます。
flowchart LR
Q["ユーザーの質問<br/>(クエリ)"] --> E["埋め込みモデルで<br/>クエリをベクトル化"]
E --> S["ベクトルDBで<br/>近似最近傍検索 (ANN)"]
KB[("知識ベース<br/>(文書をチャンク化し<br/>埋め込み済み)")] --> S
S --> R["関連文書 (上位k件) を取得"]
R --> RR["リランキングで<br/>精度よく並べ替え"]
RR --> P["プロンプトに注入<br/>(質問 + 根拠文書)"]
P --> G["LLM が文書を根拠に生成"]
G --> A["出典つきの回答"]
ポイントは、LLM 自体は学習し直していないことです。同じ重みのまま、入力(プロンプト)に「正解の手がかり」を差し込むことで、ふるまいだけを変えています。これは プロンプティングとIn-context learning の in-context learning をそのまま応用した形です。
知識ベース側(図の KB)は事前に作っておきます。社内文書・マニュアル・論文などをチャンクに分割し、各チャンクを埋め込みベクトルに変換してベクトルDBに格納しておく、という準備工程(インデックス構築)です。
埋め込み検索(semantic search)
RAG の心臓部は「質問に意味的に近い文書をどう見つけるか」です。ここで使うのが 埋め込み(embedding)による検索です。
コサイン類似度で「意味の近さ」を測る
文書もクエリも、埋め込みモデルで高次元のベクトルに変換します(埋め込みの一般論は 表現学習と埋め込み)。意味が近いテキストどうしはベクトル空間で近くに配置されるよう学習されているので、ベクトルの近さ=意味の近さとみなせます。
近さの指標には コサイン類似度(cosine similarity) がよく使われます。ベクトル (クエリ)と (文書)について:
要するに:2つのベクトルの「向きがどれだけ揃っているか」だけを見る指標です。値は 〜 で、 に近いほど意味が似ています。分母でノルムを割っているので、文書の長さ(ベクトルの大きさ)に左右されず、向き=意味の方向だけで比べられるのが利点です。
これがキーワード一致(同じ単語が含まれるか)と決定的に違う点です。「自動車の燃費」と「クルマの燃料効率」は共通単語がほぼ無くても、意味ベクトルとしては近い。だから言い換えや同義語をまたいで正しい文書を引けます。
ベクトルDBと近似最近傍(ANN)
文書が数百万チャンクあると、クエリとの類似度を全件計算するのは現実的ではありません。そこで ベクトルDB は 近似最近傍探索(Approximate Nearest Neighbor, ANN) を使います。
ANN は「わずかな取りこぼし(再現率の数%低下)を許す代わりに、計算量を桁違いに減らす」アルゴリズム群です。完全な最近傍を諦めることで、数十億ベクトルでもミリ秒で「だいたい一番近いもの」を返せます。代表格の HNSW(Hierarchical Navigable Small World) は、ベクトルを多層のグラフでつなぎ、上の層を粗くたどってから下の層で細かく探す構造で、対数オーダーの探索量を実現します。
高次元ベクトルの最近傍探索は、次元が高いほど「全部が同じくらい遠い」状態に近づいて難しくなります(次元の呪い)。実務では、埋め込みの次元削減(主成分分析と次元削減)で次元を落として検索を軽くすることもあります。「意味を保ったまま圧縮された表現の上で近さを測る」という点で、RAG の検索は次元削減と地続きの発想です。
前処理:チャンク分割とリランキング
検索の質は前処理で大きく変わります。「RAG は検索の品質が律速」 という言葉のとおり、ここが本丸です。
チャンク分割(chunking)
長い文書を丸ごと1ベクトルにすると、話題が混ざって「何にでもそこそこ近いが、どれにもピッタリ来ない」ベクトルになってしまいます。そこで文書を意味のまとまりごとの断片(チャンク)に分割してから埋め込みます。
- 細かすぎると、文脈(前後のつながり)が切れて意味が痩せる。
- 粗すぎると、1チャンクに複数話題が混ざってノイズになる。
- 段落・見出し単位で切る、隣接チャンクを少し重ねる(オーバーラップ)など、意味のまとまりを保つ工夫が要ります。
リランキング(reranking)
ANN による検索は「速いが粗い」ので、2段構えにするのが定石です。
- 粗く広く(recall重視):ANN で候補を多め(例:数十〜100件)に取る。取りこぼしを防ぐのが目的。
- 精度よく並べ替え(precision重視):取った候補を、より重い高精度モデル(クエリと文書を一緒に読むタイプ)で関連度を測り直して並べ替える。これが リランキング です。
「速い検索で当たりをつけ、丁寧な評価で順位を確定する」という分業です。最終的にプロンプトへ入れるのは上位の少数だけなので、ここの精度が回答の根拠の質を決めます。
なぜ効くのか:知識を外部化する利点
RAG の本質は 「知識をモデルの重みではなく、外部のインデックスに置く」 ことです。これがそのまま3つの利点になります。
| 利点 | 理由 |
|---|---|
| 知識更新が容易 | 重みを再学習せず、ベクトルDBの中身を差し替えるだけで最新化できる |
| 出典提示ができる | どのチャンクを根拠にしたかが分かるので、引用・リンクを示せる(検証可能) |
| 幻覚(ハルシネーション)が減る | 生成を「引いてきた文書の内容」に縛る(grounding)ので、でっち上げが起きにくい |
ファインチューニングとの使い分け
ファインチューニング は知識やふるまいを重みに焼き込みます。RAG は知識を外に置きます。両者は対立ではなく役割分担です。
- RAG が向く:頻繁に更新される事実、社内文書、出典が要る場面、大量の文書から該当箇所を絞りたいとき。
- ファインチューニングが向く:口調・出力形式(JSONなど)・特定ドメインの推論スタイルといった**「事実」ではなく「ふるまい」を固定**したいとき、検索の往復を挟めないほど低レイテンシが要るとき。
- 併用:「事実は RAG、ふるまいはファインチューニング」が定番。知識は検索層に置きつつ、指示追従・形式遵守をファインチューニングで整えます。
実際、知識集約的なタスクでは「教師なしの追加学習で知識を詰め込む」より「RAG で引いてくる」ほうが正確になりやすい、という比較報告が複数あります(新規知識でも既存知識でも)。新しい事実を覚えさせたいなら、重みに焼くより外から渡すほうが筋が良い、と覚えておくとよいです。
⚠️ よくある誤解・落とし穴
- 「RAG を入れれば必ず正確になる」は誤り。 検索が外せば、LLM はその外れた文書を根拠にもっともらしく間違えます。ゴミを引けばゴミが出ます(garbage in, garbage out)。 RAG の品質改善の大半は、生成側ではなく検索側(チャンク・埋め込み・リランキング)の改善です。
- コンテキストへの過依存(context dominance)。 引いてきた文書がノイジー/反事実だと、LLM が自分の正しいパラメトリック知識を押しのけて誤情報に引きずられることがあります。検索=常に正しい前提を置かないこと。
- RAG はハルシネーションを「減らす」のであって「消す」のではない。 根拠があっても、要約の過程で歪む・古いチャンクを引く、といった失敗は残ります(評価・ハルシネーション・安全性)。
- キーワード検索と意味検索は排他ではない。 固有名詞や型番はキーワード一致(BM25等)が強く、言い換えは意味検索が強い。両者を組み合わせた検索(ハイブリッド)+リランキングが実務では強力です。
- 構成・ツールは急速に進化中(要最新確認)。 具体的なベクトルDB製品、埋め込みモデル、チャンク戦略、リランカー、エージェント的な多段検索などは変化が速い領域です。本ノートで押さえた原理(検索で根拠を引いて生成を縛る・埋め込みで意味検索・ANNで高速化・リランキングで精度) は廃れにくいので、具体構成は都度最新を確認してください。
対応するシミュレーション
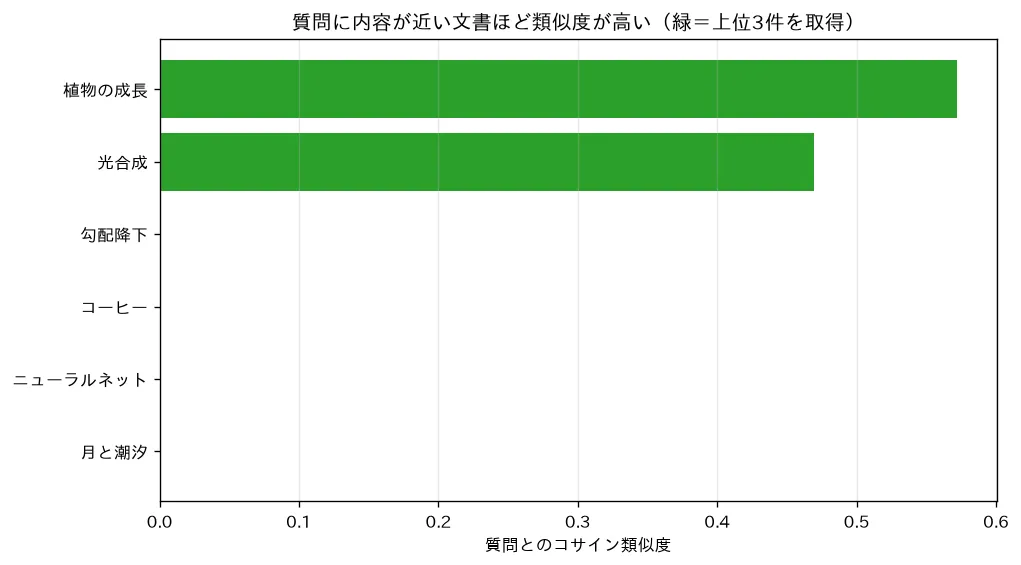
simulations/rag_retrieval.py:いろんな話題の文書集合と質問を同じベクトル空間(ここでは簡易に TF-IDF)に埋め込み、コサイン類似度で関連文書を取り出します。植物・光合成の質問に対し関連文書が上位に来て無関係な文書が下位になることを可視化します。検索した文書を文脈に渡せば、重みを再学習せず知識を更新でき出典も示せて幻覚を減らせること(実際は密な埋め込み+近似最近傍探索)を示します(評価・ハルシネーション・安全性)。