🎓 レベル:発展 | 重要度:A(必須)
📎 前提:ファインチューニング | 強化学習:Actor-Criticと深層強化学習(PPO)・方策勾配法
要点(BLUF)
- アラインメント=事前学習済みLLMを、人間の選好(有用・無害・正直)に合わせて振る舞わせる工程。「正しい続きを生む能力」と「望ましく振る舞う性質」は別物なので必要になります。
- RLHF は3段。SFT →(人間の選好ペアから)報酬モデル を Bradley-Terry で学習 → PPO で報酬最大化、ただし元モデルからの KLペナルティで離れすぎを防ぐ。
- DPO は報酬モデルとRLループを丸ごと省き、「最適方策が報酬の閉形式で書ける」性質を逆用して、選好データを 二値分類損失に帰着させる。RLHFより簡単・安定とされます(要最新確認)。
1. なぜアラインメントが必要か
事前学習(ファインチューニング の前段)が最適化しているのは、ただ一つ「次トークンの尤度」です。膨大なテキストの分布を再現するよう訓練されたモデルは、もっともらしい続きを生むのが得意になります。しかしこれは「ユーザーの指示に従い、有用で、害がなく、正直に答える」こととは一致しません。
具体的なズレの例:
- 指示追従の欠如:「3行で要約して」と頼んでも、学習データ上ありがちな「長い解説の続き」を生成してしまう。事前学習は指示を従うべき命令ではなく単なる文脈として扱う。
- 無害性の欠如:危険な手順を問われたとき、Web上にその種の文章が存在する以上、確率的には「もっともらしい続き」として出てしまいうる。
- 正直さの欠如:知らないことを、それらしく断定する(ハルシネーション)。尤度最大化は「自信のある嘘」を罰しない。
目標を一言で言えば helpful / harmless / honest(3H) にすることです。問題は、この3Hを損失関数として直接書けない点にあります。「良い応答とは何か」を数式で定義できないなら、人間の判断そのものを学習信号にするしかありません。これがアラインメントの中心的な発想です。
要するに:事前学習は「言語の分布を真似る」最適化であって、「望ましく振る舞う」最適化ではない。後者は人間の選好をデータ化して教え込む必要がある。
2. RLHF の3段パイプライン
RLHF(Reinforcement Learning from Human Feedback)は、人間のフィードバックを報酬に変換し、それを強化学習で最大化する枠組みです。強化学習の基礎は 方策勾配法・Actor-Criticと深層強化学習 で導入済みなので、ここでは言語モデルにどう写像されるかに集中します。
| 強化学習の語彙 | LLM での対応 |
|---|---|
| 方策 | 言語モデルそのもの(プロンプトを状態、トークン列を行動とみなす) |
| 状態 | プロンプト (+それまでに生成したトークン列) |
| 行動 | 次のトークン(系列全体では応答 ) |
| 報酬 | 応答 の「人間にとっての望ましさ」 |
flowchart LR
A["事前学習済みLLM"] --> B["(1) SFT<br/>(教師ありで指示追従を仕込む)"]
B --> C["(2) 報酬モデル r_φ<br/>(選好ペアをBradley-Terryで学習)"]
B --> D["(3) PPOで方策を更新<br/>(r_φ を最大化 + KLペナルティ)"]
C --> D
D --> E["アラインメント済みLLM"]
(1) SFT(教師ありファインチューニング)
少量の高品質な「指示 → 模範応答」ペアで教師あり学習し、まず指示追従の型を仕込みます。これは ファインチューニング の指示チューニングそのものです。RLHFの初期方策 となり、後段ではこれが**基準(reference)**にもなります。
(2) 報酬モデル:選好を Bradley-Terry でスカラー化
ここが「人間の判断を数式に変える」ステップです。手順はこうです。
- SFTモデルに同じプロンプト を与え、応答を複数サンプリングする。
- 人間が応答ペア を見比べ、どちらが良いかだけを答える(絶対点ではなく相対比較)。勝った方を 、負けた方を と書く。
- この選好データから、応答にスカラー報酬を返す関数 を学習する。
「比較しか得られないデータから、絶対的なスコア をどう作るか」を埋めるのが Bradley-Terry モデルです(元は対戦結果からプレイヤーの強さを推定する古典的選好モデル)。「 が に勝つ確率」を、報酬の差にロジスティック関数を噛ませた形で表します:
要するに:勝率は報酬の差だけで決まる(差が大きいほど勝率が1に近づく)。報酬の絶対値には意味がなく、定数を足しても勝率は変わらない(後でDPOがこの性質を突きます)。
学習は、観測された選好に対する**負の対数尤度(=二値分類の交差エントロピー)**を最小化するだけです:
実装上、 はSFTモデルの最終層に「スカラーを出すヘッド」を付けたものを使うのが普通です。
(3) PPO:報酬を最大化、ただしKLで縛る
報酬モデル を「環境からの報酬」とみなし、言語モデル=方策 を報酬が高い応答を出すよう更新します。ただし、報酬モデルを最大化するだけだと方策は の穴(誤って高得点を返す変な出力)に殺到します。これが reward hacking です。
これを防ぐため、基準方策 (=SFTモデル)から離れすぎないようKLダイバージェンスのペナルティを足します。RLHFが最大化する目的は次の形です:
- 第1項:報酬モデルが高く評価する応答を出したい。
- 第2項:元モデルからの逸脱に課す罰金。 がその強さ。
- のトレードオフ:小さすぎると reward hacking が起き、報酬モデルの穴を突いた壊れた出力に収束する。大きすぎると元モデルに張り付いて学習が進まない。
要するに:「報酬を上げろ、ただし元の自分から大きく変わるな」という綱引き。KL項は安全綱で、報酬モデルという不完全な物差しを盲信させないための歯止め。
この目的を実際に最適化するのが PPO(Actor-Criticと深層強化学習 で導入)です。実装では、KL項はクエリ時にトークンごとの報酬へ織り込む(各トークンで を加える)形が標準で、価値関数を学習するクリティックも必要になります。SFTモデル・報酬モデル・方策・クリティックと4つのモデルを同時に扱うため、RLHFは重く不安定になりがちです。この重さが、次のDPOを生む動機になります。
3. DPO:報酬モデルとRLを省く
DPO(Direct Preference Optimization)は、報酬モデルの学習もPPOのループもまるごと消し、選好データから直接方策を最適化します。発想の核心は「RLHFの最適方策が報酬の閉形式で書けるなら、報酬を介さず方策を直接動かせる」という点です。論文タイトルが秀逸で、Your Language Model is Secretly a Reward Model(言語モデルは密かに報酬モデルである)。
導出の流れ(3ステップ)
ステップ1:RLHF目的の最適方策には閉形式がある。 上のKLペナルティ付き目的は、 について解析的に解けます(これは強化学習の最大エントロピー的な構造から来る、廃れない結果です)。最適方策は基準方策を報酬で指数的に重み付けした形、すなわちボルツマン分布になります:
ここで は確率を1に正規化する分配関数。直観は「元の自分の出しやすさ を土台に、報酬が高い応答ほど確率を持ち上げる」。 が小さいほど報酬の差が効き、 が大きいほど に近づきます。
ステップ2:式を逆に解いて、報酬を方策で表す。 上の式を について解き直すと、報酬が方策の対数比で書けます:
要するに:報酬はもはや独立した存在ではなく、「最適方策が基準方策よりどれだけそのトークン列を好むか(対数比)」に を掛けたもの。方策の中に報酬が埋め込まれていることが見える。これが「言語モデルは密かに報酬モデル」の意味。
ステップ3:Bradley-Terry に代入すると が消える。 この をそのまま Bradley-Terry の選好確率に代入します。 と は同じプロンプト に対する応答なので、両者の報酬差を取ると厄介な が打ち消し合います(前述の通り、Bradley-Terryは報酬の差にしか依存しないため、扱いにくい分配関数が綺麗に消える)。残るのは方策の対数比だけ:
DPO 損失
あとは を学習対象 に置き換え、報酬モデルのときと同じく負の対数尤度を最小化するだけです:
これはただの二値分類損失です。報酬モデルもクリティックも環境からのサンプリングも要らず、選好データ と基準モデル さえあれば、勾配降下で直接 を更新できます。勾配の形は直観的で、「 の確率を上げ、 の確率を下げる」方向に働き、しかも現在のモデルが報酬を取り違えている( を より好んでいる)ペアほど強く効くよう自動で重み付けされます。
要するに:DPOは「報酬モデルを訓練 → RLで最大化」という2段を、「最適方策の閉形式」という数学の橋でつなぎ、選好データを直接食わせる1段の分類問題に畳み込んだ。RLHFと同じ目的を、RLなしで解いている。
RLHF vs DPO
flowchart TB
subgraph RLHF["RLHF (報酬モデル経由)"]
R1["選好データ"] --> R2["報酬モデル r_φ を学習<br/>(Bradley-Terry)"]
R2 --> R3["PPOで方策を更新<br/>(報酬最大化 + KLペナルティ)"]
R3 --> R4["アラインメント済み方策"]
end
subgraph DPO["DPO (報酬モデルを介さない)"]
D1["選好データ"] --> D2["分類損失で方策を直接更新<br/>(報酬モデルもRLも不要)"]
D2 --> D3["アラインメント済み方策"]
end
| 観点 | RLHF(報酬モデル+PPO) | DPO |
|---|---|---|
| 報酬モデル | 明示的に学習する | 不要(方策に暗黙的に埋め込む) |
| 最適化 | 強化学習(PPO・サンプリング・クリティック) | 教師あり分類(勾配降下のみ) |
| 同時に持つモデル | 4つ(SFT/RM/方策/クリティック) | 2つ(方策/基準) |
| 安定性・実装 | 重く不安定になりやすい | 軽く安定とされる(要最新確認) |
| 解いている目的 | KL制約付き報酬最大化 | 同じ目的(数学的に等価) |
DPOは実装が容易で安定なため広く使われますが、「常にRLHF(PPO)より優れるか」はタスクやデータ量・基準方策の選び方に依存し、決着はついていません。新しい派生(後述)も次々出ています。ここは要最新確認の領域です。
⚠️ よくある誤解・落とし穴(要最新確認を含む)
- 「報酬の絶対値に意味がある」と思い込む — 誤り。Bradley-Terryもボルツマン分布も報酬の差しか使わず、定数シフトに不変。報酬モデルの出力スコアを別タスクの絶対指標として使ってはいけない。
- KLペナルティは飾りではない — これを外すと方策は報酬モデルの穴に殺到する(reward hacking)。 はアラインメントの効き目と安全綱のバランスを握る最重要ハイパラ。
- DPOにも基準方策 が要る — 「RLを消した」だけで、KL制約の構造( からの逸脱を抑える)は損失の中に残っている。 の質はDPOの結果を大きく左右する。
- reward hacking は解けた問題ではない(要最新確認) — RLHF/DPO/Constitutional AI を経ても、過剰追従(sycophancy)・長さの水増し・形式の操作といった「物差しの抜け穴を突く」挙動は世代を超えて残ると報告されています。報酬モデルや評価者が完全でない限り原理的に残る課題です。
- 過剰拒否(over-refusal) — 無害性を強く効かせると、正当な質問まで断る「過剰に慎重なモデル」になりがち。helpful と harmless は綱引きで、片方を上げると片方が下がる。
- RLAIF / Constitutional AI(要最新確認) — 人間の選好ラベルの代わりにAI自身に選好を付けさせ規模を稼ぐ手法(RLAIF)や、明文化した原則(憲法)に沿って自己批判・自己修正させて無害性を高める Constitutional AI が広く使われています。2026年時点でも改良(憲法の動的更新など)が活発で、この節は最新の一次情報での確認が必須です。
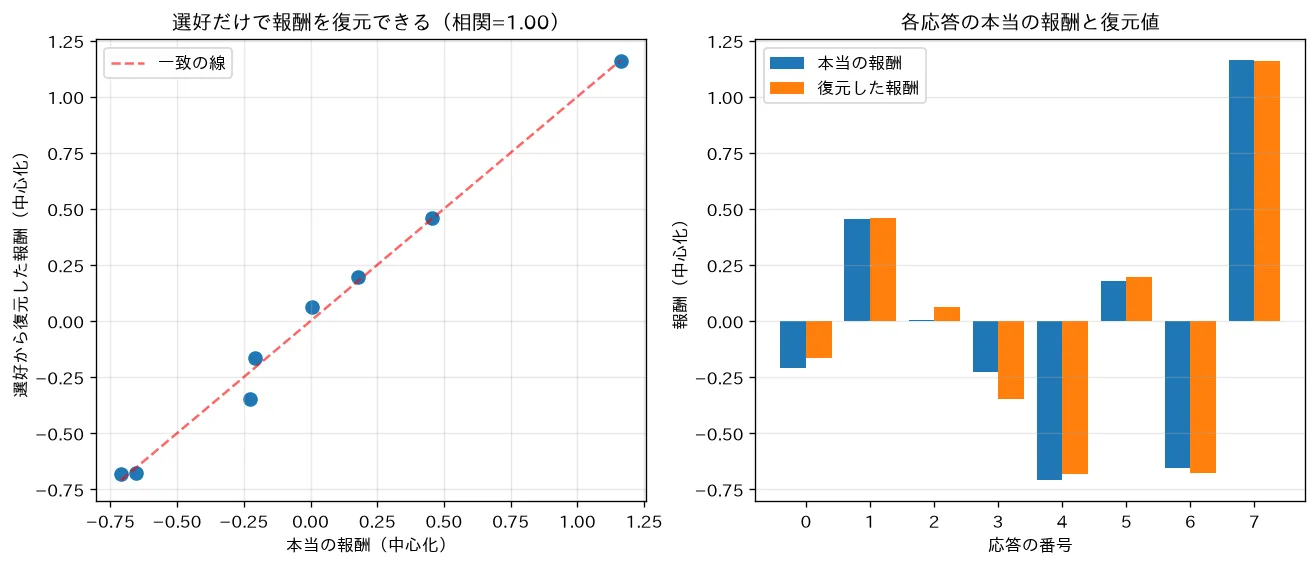
対応するシミュレーション
simulations/dpo_bradley_terry.py:RLHF/DPO の土台である Bradley-Terry モデル で、隠れた報酬を持つ応答たちの「どちらが好きか」の比較データを生成し、その比較だけから各応答の報酬を最尤推定(=「勝者−敗者」を特徴にしたロジスティック回帰)で復元します。本当の報酬とほぼ一直線にのり順位が当たること(相関0.99)を可視化します。DPO はこの報酬モデルを陽に作らず最適方策の閉形式から選好へ直接フィットします。