🎓 レベル:標準 | 重要度:B(標準)
📎 前提:LLMの全体像
要点(BLUF)
- 学習済みLLMを動かす実務は 「どう選ぶか(デコーディング)」「どう速くするか(KVキャッシュ・量子化・バッチ)」「どこまで読めるか(コンテキスト長)」 の3軸で整理できます。
- デコーディングは次トークン分布からの選び方で、greedy(決定的)↔ temperature/top-k/top-p(多様) のトレードオフ。原理は softmax の温度スケーリングひとつで説明できます。
- 速度の肝は 自己回帰生成での再計算を避ける KVキャッシュ と、重みを低ビットにする量子化。ただし量子化の具体手法とコンテキスト長対応は急速に動くので 要最新確認。
なぜ「推論の実務」が独立した話題になるのか
学習済みのLLMは、内部的には「これまでのトークン列を入力すると、次のトークンの確率分布を返す関数」です(自己回帰モデル=自己回帰モデル)。
学習が終われば仕事は終わり……ではありません。この分布をどう使うかで出力の質も速度もコストも大きく変わります。同じモデルでも、選び方ひとつで「毎回同じ無難な答え」にも「多様だが時々破綻する答え」にもなります。さらに、巨大なモデルを実際のメモリ・レイテンシ予算で動かすには工夫が要ります。これが推論(inference)の実務です。
1. デコーディング戦略:分布からどう選ぶか
モデルが返すのは確率分布であって、文字列そのものではありません。各ステップで語彙全体に対するロジット が出て、softmax で確率になります。ここから1個のトークンを選ぶ手続きがデコーディング戦略です。
greedy(貪欲法)
毎ステップ、最も確率の高いトークンを1個選びます。
要するに:いつも一番自信のある手を選ぶ。決定的(同じ入力なら毎回同じ出力)で実装も軽い。ただし「各ステップで最善」が「文全体として最善」とは限らないため、無難だが単調・反復的になりがちです。
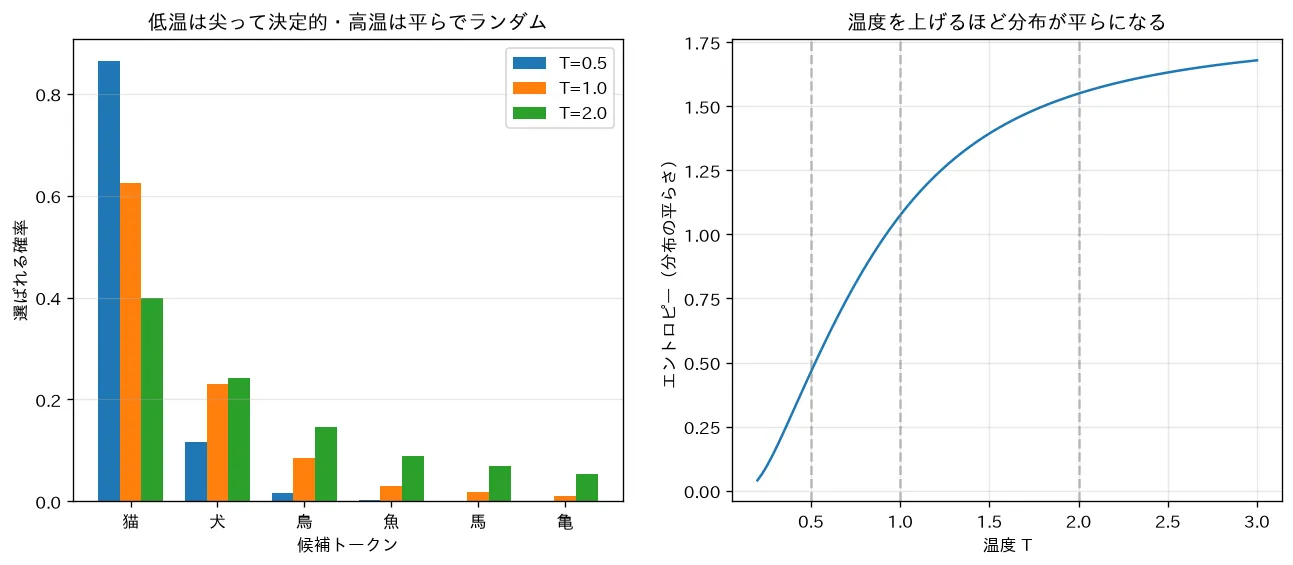
temperature(温度)
ロジットを温度 で割ってから softmax します。
- :最大ロジットに確率が集中 → greedy と等価
- :素の分布
- :分布が平坦化(低確率トークンが相対的に持ち上がる)
要するに: は確率分布の「鋭さ/なだらかさ」を変えるつまみです。新しい乱数を足すのではなく、既にある分布の形を作り直しているだけ、という点が本質です。
数理的な補足:この式は統計物理の Boltzmann分布と同じ構造です。ロジットが負のエネルギー、 が温度、分母が分配関数 に対応します。「温度を上げると状態がばらける」という直観がそのまま効きます。
top-k
確率上位 個のトークンだけを候補に残し、その中で(再正規化して)サンプリングします。要するに:「上位 件だけ見る」という固定枠の足切り。裾の極端に変なトークンを物理的に排除できますが、 が固定なので、自信のある場面でも自信のない場面でも同じ数だけ候補を残してしまいます。
top-p(nucleus sampling)
確率の高い順に足していき、累積確率が を超える最小の集合を候補にします(その中で再正規化してサンプリング)。
要するに:「上から積んで 割に達するまで」という動的な足切り。モデルが確信している場面では候補が数個に絞られ、迷っている場面では候補が自然に広がる——文脈に応じて候補数が変わるのが top-k との決定的な違いです。
トレードオフの全体像
| 戦略 | 決定性 | 多様性 | 典型用途 |
|---|---|---|---|
| greedy() | 高(毎回同じ) | 低 | コード生成・厳密な抽出 |
| temperature | 次第 | 次第 | 全体の鋭さ調整 |
| top-k | 中 | 中(固定枠) | 裾の足切り |
| top-p | 中 | 中(動的枠) | 会話・自由生成 |
実務では temperature + top-p を組み合わせるのが定番です。コードや構造化出力では低温+ほぼgreedy、対話では中温+top-p、という使い分けになります。
flowchart TD
A["次トークンのロジット z_i"] --> B["温度で割る(z_i ÷ T)"]
B --> C["softmax で確率分布 p_i"]
C --> D{"選び方"}
D -->|"greedy"| E["最大確率を1個(argmax)"]
D -->|"top-k"| F["上位k個に絞る(固定枠)"]
D -->|"top-p"| G["累積pまでの最小集合(動的枠)"]
F --> H["再正規化してサンプリング"]
G --> H
E --> I["次トークン確定"]
H --> I
I --> J["列に追加して次ステップへ"]
2. KVキャッシュ:自己回帰生成を速くする
LLMの生成は1トークンずつの自己回帰(自己回帰モデル)です。素朴に実装すると、新しいトークンを1個出すたびに、それまでの全トークンについて注意機構(注意機構)の計算をやり直すことになります。これは無駄です。過去のトークンの内部表現は前のステップから変わっていないからです。
注意機構では、各トークンから Query・Key・Value が作られ、Query と全 Key の内積で注目度を決めて Value を重み付き和します(Transformer)。ここで効くのが次の観察です。
新しいトークンを生成するとき、過去トークンの Key と Value は毎回まったく同じ。変わるのは「新しいトークン1個分」だけ。
そこで、過去トークンの Key/Value を層ごとに保存しておき、新トークン分だけ計算して継ぎ足すのが KVキャッシュです。
flowchart LR
subgraph S["ステップ t(KVキャッシュ利用)"]
A["新トークン x_t"] --> B["x_t の K, V を計算(1個分だけ)"]
C["キャッシュ:過去の K, V(1〜t-1)"] --> D["連結"]
B --> D
D --> E["注意計算(Q_t と全Kの内積)"]
E --> F["次トークン(t+1番目)を出力"]
B -.->|"追記して保存"| C
end
要するに:毎ステップの計算量を「列全体」から「新トークン1個分+キャッシュ参照」に減らす仕組みです。
メモリとのトレードオフ
KVキャッシュはタダではありません。保存するメモリは概ね
で、系列長に対して線形に増えます。長い文脈を扱うほどキャッシュがGPUメモリを圧迫し、ある長さを超えると計算ではなくメモリがボトルネックになります。「キャッシュをどう圧縮・破棄するか(cache eviction / compression)」は活発な研究領域で、具体手法は 要最新確認です。
3. 量子化(quantization)
巨大モデルは重みの数が膨大で、そのままだとメモリと帯域を食います。量子化は、重み(や活性)を低ビットの整数などで表現してこれを軽くする技術です。
- 通常の重みは 16bit(FP16/BF16)程度
- これを INT8(1バイト)→ VRAM 半分、INT4(0.5バイト)→ VRAM 1/4 のように落とす
ここで はスケール係数です。要するに:連続値の重みを「目盛りの粗い整数」に丸めて表現し、必要なときにスケールで戻す。目盛りが粗いぶん情報は落ちますが、メモリと速度を稼げます。
精度とのトレードオフ(要最新確認)
落とすビット数を下げるほど軽くなりますが、精度が劣化する可能性があります。重みだけを量子化するか、活性(KVキャッシュ含む)まで量子化するかでも難しさが変わり、外れ値(outlier)チャネルの扱いが精度の鍵になります。
⚠️ 要最新確認:どのビット幅・手法がどれだけ精度を保つかは、ハードウェアと手法の進歩で急速に変わります。「INT8はほぼ劣化が小さい」「特定の手法はメモリ制約下で有効」といった目安はありますが、採用時は最新のベンチマークで必ず確認してください。具体的な手法名・しきい値をこのノートに固定しません。
4. コンテキスト長:どこまで読めるか
LLMが一度に扱えるトークン数(コンテキスト長)は、性能だけでなくコストを直接決めます。理由は自己注意の計算量です。
各トークンが他の全トークンとの注目度を計算するため、ペア数が で効きます(注意機構)。要するに:文脈を2倍にすると注意のコストは約4倍。長文では、入力をまとめて処理する prefill 段階でこの が支配的になり、最初のトークンが出るまでの時間(TTFT)の大半を占めることもあります。
長文対応(コンテキスト窓の拡張)や KVキャッシュ圧縮、 を緩める疎な注意(sparse attention)などは研究が非常に速く動いている領域です。具体的な手法・上限は要最新確認としてください。
5. スループット:まとめて捌く(バッチ処理)
1リクエストずつ処理するとGPUが遊びます。実務のサーバは複数リクエストをバッチにまとめて throughput(秒あたりトークン数)を稼ぎます。
LLM推論は性質の異なる2フェーズに分かれます。
- prefill:入力プロンプト全体を一括処理。 の注意が効き 計算律速(compute bound)
- decode:1トークンずつ生成。KVキャッシュを参照しつつ1個分だけ計算するので メモリ律速(memory bound)
この2フェーズを束ね、終わったリクエストを抜いて新しいものを差し込みながら回す 継続バッチング(continuous batching / iteration-level scheduling) が、現代の推論サーバの基本です。要するに:GPUを遊ばせないよう、生成途中のリクエストを動的に出し入れしてバッチを満たし続ける、という考え方です。
⚠️ よくある誤解・落とし穴
- 「temperature は創造性のつまみ」ではない:温度がやるのは確率分布の鋭さ/平坦さの調整だけです。研究上も温度と「新規性」は弱い相関にとどまり、コヒーレンス(一貫性)とはほぼ無相関とされます。上げれば多様にはなりますが、それは創造性ではなくばらつきです。極端に上げれば破綻し、 にすると逆に反復ループが増えることもあります。
- 量子化は「ただ軽くなるだけ」ではない:ビットを落とせば精度が劣化しうるトレードオフです。どこまで許容できるかは用途次第で、具体手法の優劣は要最新確認。
- KVキャッシュは速くするがメモリを食う:速度と引き換えに系列長に比例したメモリを消費します。長文ではこれがボトルネックになります。
- コンテキスト長は「ただ長くすればいい」ではない: のため長文ほど高コスト。長文対応技術は急速に進歩中で 要最新確認。
- greedy = 常に最良ではない:各ステップで最善でも、文全体で最善とは限りません(局所最適)。
対応するシミュレーション
simulations/softmax_temperature.py:固定したロジットに温度つきソフトマックス をかけ、温度 を変えたときの次トークン確率分布とそのエントロピーを可視化します。(低温)は最大スコアのトークンに尖って決定的(greedy)、(高温)は分布が平らになって多様でランダムな生成になること、エントロピーが温度とともに単調に増えることを示します。top-k / top-p と併用されます。