🎓 レベル:標準 | 重要度:B(標準)
📎 前提:モデル解釈性 | 関連:評価指標(分類)とROC・AUC
要点(BLUF)
- 機械学習の「公平性」とは、モデルが人種・性別などの保護属性によって不当に有利/不利な予測をしないこと。ここでの「バイアス」は統計的バイアスとは別概念で、社会的な不公平を指します。
- 公平性には複数の定義があり、何を群間で等しくするかが違います。代表は demographic parity・equalized odds・予測値パリティ(calibration)の3つ。
- これらは一般に同時に満たせない(不可能性定理)。どれを優先するかは技術ではなく価値判断であり、社会的文脈に依存します。
公平性が問題になる場面
公平性が深刻に効くのは、予測の結果が人生に直結する高ステークスな意思決定です。
| 領域 | モデルの用途 | 不公平が起きると |
|---|---|---|
| 採用 | 履歴書スクリーニング | 特定の性別・大学の応募者を機械的に落とす |
| 与信 | ローン審査・限度額 | 特定地域・属性の人に融資が下りにくい |
| 司法 | 再犯リスク評価 | 特定の人種に保釈・量刑で不利に働く |
| 医療 | 治療優先度・診断支援 | 特定の集団で診断精度が落ちる |
これらに共通するのは、過去のデータに社会的な偏りが含まれていることと、その偏りをモデルが学習して再生産・増幅しうることです。
「バイアス」という言葉の二義性に注意
機械学習で「バイアス」と言うとき、まったく別の2つの概念があります。混同しないでください。
- 統計的バイアス(汎化と過学習・バイアスバリアンス分解 のバイアス):モデルの予測の期待値が真の値からどれだけ系統的にずれているか。精度に関する数学的な量です。
- 社会的バイアス(このノートの主題):特定の社会集団に対する不公平・差別。精度が高くても社会的に不公平なモデルはありえます。
両者は独立です。「バイアスが小さい(=高精度)」モデルが「公平」とは限りません。
バイアスの源泉
不公平はモデルそのものより、入ってくるデータと問題設定から生まれます。主な源泉は3つです。
flowchart TD
A["過去の社会(差別・格差を含む)"] --> B["訓練データ"]
B --> C1["データの偏り(歴史的バイアス・標本選択バイアス)"]
B --> C2["ラベルの偏り(過去の判断がラベルになる)"]
B --> C3["特徴量が保護属性の代理(proxy)になる"]
C1 --> D["学習"]
C2 --> D
C3 --> D
D --> E["不公平な予測"]
E -. "予測が次の判断を生む" .-> A
(1) データの偏り(歴史的・標本選択) 過去のデータが社会の偏りをそのまま映している場合(歴史的バイアス)や、特定の集団のデータが少ない・偏った経路で集まる場合(標本選択バイアス)。例:ある集団のサンプルが極端に少ないと、その集団での予測が不安定になります。
(2) ラベルの偏り
教師あり学習の正解ラベル Y 自体が、過去の偏った人間の判断であることがあります。例:「採用された=優秀」というラベルで学習すると、過去の採用が偏っていた場合、その偏りを正解として学んでしまいます。
(3) 特徴量が保護属性の代理(proxy)になる 保護属性(人種・性別)を入力から削除しても公平にはならないのが厄介な点です。郵便番号・出身校・購買履歴などの一見中立な特徴が、保護属性と強く相関し、その代理(proxy)として働くからです。モデルは保護属性を直接使えなくても、proxy を経由して同じ差別を再現できてしまいます。これを間接差別と呼びます。
⚠️ 「保護属性をモデルに渡さなければ公平」という素朴な対策(fairness through unawareness)は、proxy があるためほぼ機能しません。
公平性の定義(何を等しくするか)
公平性は一つに定まりません。群間で何を等しくしたいかで定義が分かれます。保護属性を A、真のラベルを Y ∈ {0,1}、モデルの予測を Ŷ = h(X) とします。
graph TD
Q["公平性: 何を群Aの間で等しくする?"]
Q --> DP["demographic parity<br/>陽性率 P(Ŷ=1) を等しく"]
Q --> EO["equalized odds<br/>真陽性率・偽陽性率を等しく"]
Q --> CAL["予測値パリティ(calibration)<br/>陽性予測の的中率 PPV を等しく"]
DP --> DPN["「機会の量」を揃える"]
EO --> EON["「誤りの質」を揃える(機会均等)"]
CAL --> CALN["「スコアの意味」を揃える"]
(1) demographic parity(集団公平性 / 統計的パリティ)
属性によらず陽性と予測される割合を等しくする。
要するに、予測 Ŷ が保護属性 A から統計的に独立であることを求めます。「どの群でも同じ割合で採用される/融資される」という、結果の量の平等です。真のラベル Y を一切見ない点が特徴で、群ごとに本当に陽性率が違う場合でも一律に揃えるため、精度を犠牲にしやすいです。
(2) equalized odds(均等オッズ / 機会均等)
真のラベルで条件づけたうえで、真陽性率(TPR)と偽陽性率(FPR)を群間で等しくする。
要するに、予測 Ŷ が Y を与えた条件下で A から独立であること。「本当に陽性の人を正しく拾う率」と「本当は陰性なのに誤って陽性にする率」を群間で揃えるので、誤りの質の平等です。Y=1 の側だけを揃える緩い版を equal opportunity(機会均等) と呼びます(TPR のみ等しく)。TPR/FPR は 評価指標(分類)とROC・AUC の混同行列から出る量です。
(3) 予測値パリティ(predictive parity / calibration)
陽性と予測した人のうち実際に陽性だった割合(PPV)を群間で等しくする。
要するに、スコアの意味が群によらず同じであること。「リスクスコア0.8」がどの群でも同じ確率で陽性を意味するなら、スコアは公平に解釈できる、という立場です。較正(calibration)が群ごとに成り立つこと、と言い換えられます。
不可能性定理:3つは一般に両立しない
ここが本質です。上の3つの基準は、群ごとの基準率(base rate)が異なるとき、同時には満たせません。 これは Kleinberg ら・Chouldechova が独立に示した数学的事実であり、より良いアルゴリズムを作れば解決する、という類の問題ではありません。
なぜ両立しないか(Chouldechova の恒等式)
群ごとの基準率(実際の陽性割合)を p = P(Y=1) とすると、混同行列の各率の間に次の恒等式が常に成り立ちます。
ここで FNR は偽陰性率、FPR は偽陽性率です。この式は混同行列の定義から導かれる恒等式で、どんな分類器でも成り立ちます。
この式から両立不能が直ちに出ます。群1と群2で基準率が違う、つまり
のとき:
- もし 予測値パリティ(PPV を等しく:左辺が群間で同じ)を満たすなら、右辺も群間で等しくなければならず、基準率の比
p/(1-p)が違う分を(1-FNR)/FPRが打ち消す必要があります。つまり FNR・FPR は群間で違わざるをえない → equalized odds(誤り率の平等)が破れます。 - 逆に equalized odds(FNR・FPR を群間で等しく)を満たすなら、右辺の
p/(1-p)の違いがそのまま左辺に出るので PPV が群間で違う → 予測値パリティが破れます。
唯一の例外は分類器が完全に正確(FPR=0 かつ FNR=0)な場合だけで、現実のモデルではありえません。
要するに:群の基準率が違う限り、「スコアの意味を揃える(calibration)」ことと「誤りの率を揃える(equalized odds)」ことは数学的に同時達成できない。demographic parity も
Yと独立を強制するため、Yを見る他2つと一般に衝突します。
COMPAS 論争がまさにこれ
再犯リスク評価ツール COMPAS をめぐる有名な論争は、この定理の実例です。
- 提供側:「スコアは人種によらず較正されている(calibration を満たす)」→ 公平だと主張。
- ProPublica:「黒人被告の方が偽陽性率が高い(equalized odds が破れている)」→ 不公平だと主張。
どちらも正しい。 群の再犯基準率が異なるため、calibration と error rate balance は定理により両立しません。「どちらの公平性を優先すべきか」は、データやアルゴリズムでは決まらない価値判断・社会的選択の問題に変わります。
対策の3段:前処理・学習中・後処理
どの公平性指標を採るか決めたうえで、バイアスを緩和する介入は3つのタイミングに分かれます。
flowchart LR
D["訓練データ"] --> P1["前処理(データを直す)"]
P1 --> M["学習中(制約・正則化を入れる)"]
M --> P3["後処理(出力・閾値を調整)"]
P3 --> O["予測"]
P1 -. "再重み付け・再標本化・特徴変換" .-> P1
M -. "公平性を制約付き最適化" .-> M
P3 -. "群ごとに閾値を変える" .-> P3
(1) 前処理(pre-processing)— データを直す 学習前に、保護属性と他の特徴・ラベルの相関を弱めます。再重み付け、再標本化、特徴量の変換などで、データの段階で偏りを減らします。モデルに依存しない一方、モデルがデータをどう使うかを見ていないため、偏りが残ることもあります。
(2) 学習中(in-processing)— 学習に制約を入れる 損失関数に公平性の制約や正則化項を加え、精度と公平性を同時に最適化する制約付き最適化として解きます。例:公平性違反の大きさをペナルティとして足す。指標を直接ターゲットにできる一方、学習アルゴリズムの改変が必要です。
(3) 後処理(post-processing)— 出力・閾値を調整 学習済みモデルはそのままに、出力スコアや判定閾値を群ごとに調整して公平性を満たします。再学習が不要で手軽な一方、推論時に保護属性を知る必要がある点が制約です(前処理・学習中は訓練時のみ保護属性があればよい)。
精度と公平性のトレードオフ
これらの介入は多くの場合、全体精度を下げます。元のモデルは精度を最大化するよう学習されているので、そこに公平性制約を課せば、最適点から離れるぶん精度が落ちるのが普通です。
ε を小さく(公平性を厳しく)するほど、許される h の集合が狭まり、達成できる精度の下限が悪化します。「精度を取るか公平性を取るか、どこで折り合うか」自体が設計判断であり、唯一の正解はありません。
⚠️ よくある誤解・落とし穴(要最新確認)
- 保護属性を消せば公平、ではない。 proxy(代理変数)があるため、fairness through unawareness はほぼ効きません。
- 「公平性」は一つの数字ではない。 demographic parity・equalized odds・calibration はどれも「公平」を名乗りますが、揃える対象が違い、一般に両立しません。指標を選んだ時点で、ある立場を選んでいます。
- 不可能性定理は技術で回避できない。 群の基準率が違う限り数学的に両立不能で、より高度なモデルでも解消しません。残るのは「どれを優先するか」という規範的問題です。
- 公平性指標の選択そのものが価値判断・社会的判断であり、技術だけでは解けません。何を公平とみなすかは、適用領域・法制度・社会的合意に依存します。この領域は法規制(例:AI規制)・ガイドライン・ツールの実装が急速に動いているため、実務適用時は最新の規制・文献・ツールを必ず確認してください(要最新確認)。
- 技術が担えるのは「選んだ定義に対して測定し、トレードオフを可視化し、緩和する」ところまで。どの定義を選ぶかは技術の外側にあります。
まとめ
公平性とバイアスは、機械学習が社会と接続したときに必ず立ち現れる問題です。技術で解ける部分は「公平性を定義に落として測る・緩和する・トレードオフを示す」こと。技術で解けない部分は「どの公平性を優先するか」という価値判断で、これは社会的文脈に委ねられます。エンジニアの役割は、この境界を理解し、選択を明示的・説明可能にすること(モデル解釈性 とも直結します)。万能の公平モデルは存在せず、不可能性定理がそれを保証している、というのが出発点です。
対応するシミュレーション
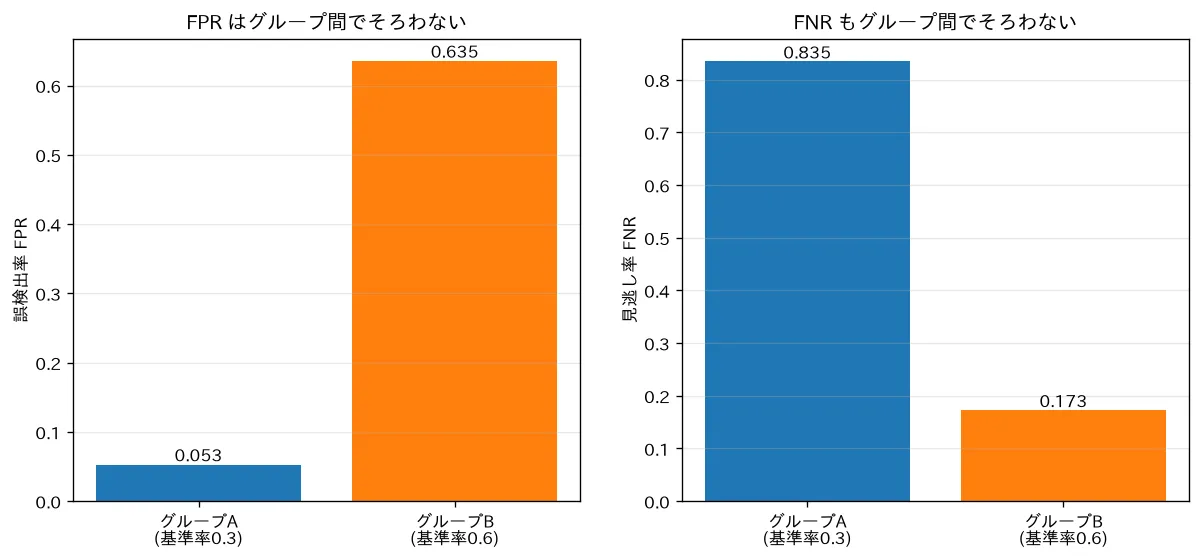
simulations/fairness_impossibility.py:陽性の基準率が違う2グループ(A=0.3 / B=0.6)の完全に較正されたスコアを作り、共通のしきい値での誤検出率FPRと見逃し率FNRを比べます。較正済みなのにFPR(A=0.05 / B=0.64)もFNR(A=0.84 / B=0.17)もグループ間でそろわないこと=Chouldechovaの不可能性定理(基準率が違うと「較正・等しいFPR・等しいFNR」を同時には満たせない)を数値で確かめます。どの公平性指標を優先するかは価値判断になります。