🎓 レベル:標準 | 重要度:A(必須)
📎 前提:バギングとランダムフォレスト(特徴量重要度)
要点(BLUF)
- 解釈性(説明可能AI / XAI)=「なぜモデルがその予測を出したか」を人間が理解できる形にすること。信頼・デバッグ・公平性・規制対応・科学的発見のために要る。
- 整理の軸は2つ:大域(global) vs 局所(local)(全体の傾向か、1件の予測か)と、モデル固有(intrinsic) vs モデル非依存(post-hoc)(モデル自体が透明か、後付けで説明するか)。
- 代表手法は 並べ替え重要度(大域・非依存)/LIME(局所・近傍を線形近似)/SHAP(局所+大域・シャープレイ値で寄与を公平配分、加法性を持つ)。ただしどれも近似であり、重要度の高さは「原因」を意味しない(相関≠因果)。
1. なぜ解釈性が要るのか
予測精度が高ければそれで十分、とはいきません。モデルがブラックボックス(入力と出力は見えるが、中の判断根拠が見えない)だと、次の場面で困ります。
- 信頼:医療診断や与信審査で「なぜ却下したか」を説明できないと、現場は結果を信用できません。
- デバッグ:精度は高いのに、実は「画像の背景の透かし」で犬猫を見分けていた、というショートカット学習を見抜けません。解釈して初めて気づけます。
- 公平性:特定の属性(性別・人種など)に依存していないかを検証するには、判断根拠を覗く必要があります → 公平性とバイアス。
- 規制・説明責任:金融・医療などでは「説明できること」が法令・ガイドライン上求められる場合があります。
- 科学的発見:モデルが見つけた「効いている特徴」が、新しい仮説のヒントになります。
ここで重要な区別を先に置きます。解釈性(interpretability)は「人間が因果関係や根拠をどれだけ理解できるか」、説明可能性(explainability)は「ブラックボックスの挙動を後付けで説明できるか」 を指すことが多いです。本ノートでは両者をまとめて「解釈性」と呼びますが、後述のように後付けの説明は近似であって真の根拠そのものではない点が常について回ります。
2. 整理の2つの軸
解釈手法は数が多いので、まず2軸で地図を描きます。
flowchart TB
Root["解釈手法の地図"]
Root --> A["軸1:適用範囲<br/>大域 vs 局所"]
Root --> B["軸2:透明性<br/>モデル固有 vs モデル非依存"]
A --> A1["大域 global<br/>モデル全体の傾向"]
A --> A2["局所 local<br/>特定の1件の予測"]
B --> B1["モデル固有 intrinsic<br/>モデル自体が透明"]
B --> B2["モデル非依存 post-hoc<br/>学習後に後付けで説明"]
A1 --> P1["並べ替え重要度<br/>(非依存・大域)"]
B1 --> P2["線形回帰の係数 / 決定木<br/>(固有・大域も局所も)"]
A2 --> P3["LIME<br/>(非依存・局所)"]
A2 --> P4["SHAP<br/>(非依存・局所+集約で大域)"]
軸1:大域(global) vs 局所(local)
- 大域:「このモデルは全体としてどの特徴を重視しているか」。データセット全体にわたる傾向。例:特徴量重要度ランキング。
- 局所:「この1件を、なぜモデルはこう予測したか」。個別予測の内訳。例:ある申込者の与信スコアの内訳。
要するに、鳥瞰図(大域)か虫眼鏡(局所)かの違いです。
軸2:モデル固有(intrinsic) vs モデル非依存(post-hoc)
- モデル固有(intrinsic):モデルの構造自体が透明で、追加処理なしに読める。線形回帰の係数、決定木の分岐など。
- モデル非依存(post-hoc / model-agnostic):学習済みモデルを外から入出力だけ観察して後付けで説明する。中身がニューラルネットでも勾配ブースティングでも同じ手順が使える。LIME・SHAP・並べ替え重要度がこれ。
要するに、最初から透明な箱(固有)か、不透明な箱を外から推し量る(非依存)かです。一般に「精度の高い複雑なモデルほど不透明」というトレードオフがあり、後者の手法が必要になります。
3. モデル固有の解釈(intrinsic)
複雑な後付け手法に行く前に、そもそも透明なモデルを押さえます。これらは説明が「近似」ではなく構造そのものなので、信頼度が高いのが利点です。
線形回帰の係数
線形回帰 では、係数 が「 を1単位増やすと予測が だけ動く」を直接表します(他を固定したとき)。符号と大きさがそのまま解釈になります。詳しくは 線形回帰(最小二乗法と確率的解釈)。
ただし特徴量のスケールが揃っていないと係数の大小を直接比べられない(単位の違いで が変わる)点に注意。比較するなら標準化してから見ます。
Lasso のスパース性
L1正則化(Lasso)は係数の一部をちょうど0に潰すので、「効いている特徴」だけが残った疎な(スパースな)モデルになります。これは変数選択を兼ねた解釈として強力です。Ridge は0にしないので、この性質はLasso特有です → 正則化(Ridge・Lasso・Elastic Net)。
決定木
決定木は「もし なら…さらに なら…」という** if-then ルールの連鎖**そのものなので、浅い木なら根から葉までたどるだけで判断根拠が読めます → 決定木。深くなると人間が追えなくなり、解釈性は失われます。
木の特徴量重要度(不純度減少)
ランダムフォレストや勾配ブースティングでは、各特徴がノード分割で不純度(ジニ不純度やエントロピー)をどれだけ減らしたかの合計を重要度とします。
ここで はノード での不純度減少、 はそのノードに来るデータの割合(重み)です。要するに、その特徴を使った分割が「データをどれだけきれいに分けたか」の総量。全木で平均してランキング化します → バギングとランダムフォレスト。
⚠️ ただしこの不純度ベースの重要度は カーディナリティの高い特徴(取りうる値が多い特徴)を過大評価しやすいという既知のバイアスがあります。連続値やIDのような特徴は分割の自由度が高く、見かけ上たくさん不純度を減らせてしまうためです。次節の並べ替え重要度はこの弱点を補えます。
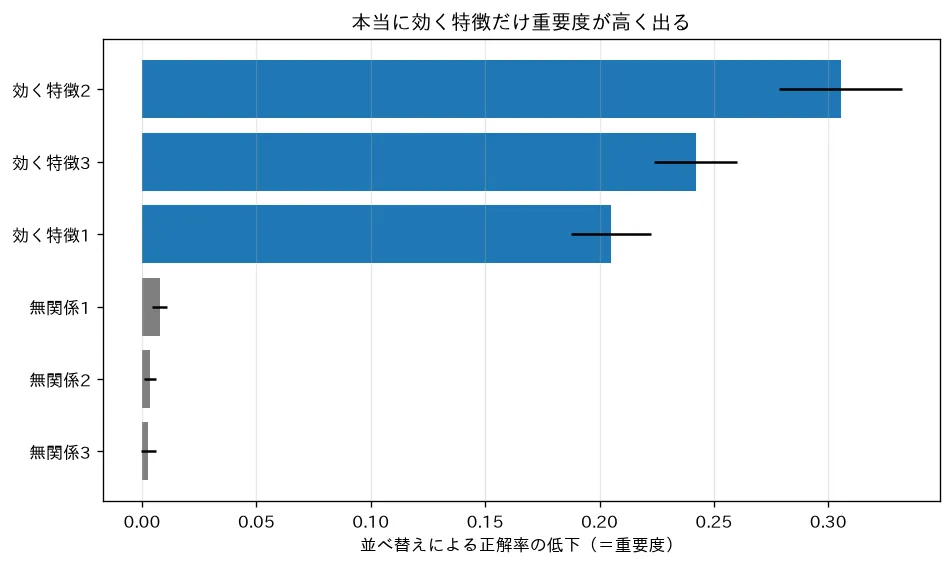
4. 並べ替え重要度(permutation importance)
モデル非依存・大域の代表手法。アイデアは極めて素直です。
ある特徴 の列だけをランダムにシャッフル(並べ替え)して、 と目的変数の関係を壊す。それでモデルの性能がどれだけ落ちたかを、その特徴の重要度とする。
性能が大きく落ちる → そのモデルはその特徴に強く依存していた、と読みます。要するに「その情報を奪ったら、どれだけ困るか」を測るわけです。
- 利点:どんなモデルにも使える。学習済みモデルと検証データだけで計算でき、再学習不要。木の不純度バイアスも回避できる。
- 仕組み上、1回のシャッフルだと偶然に左右されるので、複数回シャッフルして平均するのが普通です。
⚠️ 相関のある特徴で誤解を生む:2つの特徴が強く相関していると、片方をシャッフルしてももう片方が同じ情報を持っているため、性能があまり落ちません。結果、両方とも重要度が低く見える(重要度が分散・希釈される)。さらに、シャッフルは「現実には起こりえない特徴の組み合わせ」を作り出し、モデルが訓練時に見たことのない領域へ外挿(extrapolation)してしまうため、その意味でも値が歪みます。相関が強い場合は特徴をまとめる、条件付き並べ替えを使うなどの対処が要ります。
5. LIME:局所を線形で近似する
LIME(Local Interpretable Model-agnostic Explanations) は、注目する1点 の予測だけを説明する局所・非依存手法です。
核心のアイデア:複雑なモデル も、ある1点のごく近傍だけ見れば、単純な線形モデルで近似できるはず。だから「 の周りでだけ に似た、解釈可能な単純モデル 」を当てはめ、その の係数で説明します。
flowchart LR
A["説明したい1点 x"] --> B["x の近傍に<br/>サンプルを生成"]
B --> C["各サンプルを<br/>本物のモデル f で予測"]
C --> D["x に近いサンプルほど<br/>重く(近接カーネル)"]
D --> E["重み付きで<br/>単純な線形モデル g を学習"]
E --> F["g の係数 = x での<br/>局所的な特徴の効き方"]
数式では、次の目的関数を最小化する を選びます。
- :本物 と単純モデル の予測のズレ。ただし近接カーネル で「 に近いサンプルほど重く」重み付けする(局所忠実性=local fidelity)。
- : が複雑になりすぎない罰則(例:線形モデルで非ゼロ係数を少なく)。 は解釈可能なモデルの集合(線形・決定木など)。
要するに、「この1点の近くでだけ、本物のモデルにそっくりで、しかも人間が読める単純モデル」を作って代弁させる。 が「近く」の定義(距離が近いほど大きい重み)を与え、 が「読める」を担保します。
⚠️ LIMEは近傍サンプルの作り方や近接カーネルの幅(どこまでを近くと見るか)に敏感で、同じ点でも設定次第で説明が変わりうる、という再現性の弱さがあります。
6. SHAP:シャープレイ値で寄与を公平配分する
SHAP(SHapley Additive exPlanations) は、協力ゲーム理論のシャープレイ値を使って、各特徴が予測にどれだけ寄与したかを**「公平に」配分**します。局所説明が基本ですが、全データで集約すれば大域的な重要度にもなります。
アナロジー:利益の山分け
協力ゲームでは、複数のプレイヤーが協力して得た総利益を、各人の貢献度に応じて公平に分けたい。シャープレイ値はその唯一の公平な配分法です。SHAPはこれを「プレイヤー=特徴、総利益=その予測値」に置き換えます。
シャープレイ値の数式
特徴 のシャープレイ値 は、「 が加わることでモデル出力がどれだけ増えるか(限界貢献)」を、ありうるすべての特徴の組み合わせ について平均したものです。
- :全特徴の集合、: を含まない特徴の部分集合(先にいる「仲間」)。
- :特徴集合 だけを使ったときのモデル出力(協力ゲームの利得関数)。
- : に を加えたときの限界貢献。
- 前の係数 は、 がちょうどその位置で加わる順番が全 通り中どれだけあるかの重み。つまり全ての加入順序にわたる限界貢献の平均になっています。
要するに、「いろんな順番で特徴を1つずつ足していったとき、 を足した瞬間に予測がどれだけ動いたか」を、全順序で平均した値が です。
4つの公理(なぜ「公平」と言えるか)
シャープレイ値は、次の4性質を同時に満たす唯一の配分であることが証明されています(Shapley, 1953)。これがSHAPの理論的な強みの源です。
- 効率性(efficiency / 局所正確性):全特徴の寄与の和が、予測と基準値の差にちょうど等しい。
- 対称性(symmetry):2つの特徴がどんな組み合わせでも同じ貢献をするなら、寄与も等しい。
- ダミー(dummy / null player):どの組み合わせに足しても出力を変えない特徴の寄与は0。
- 加法性(additivity / linearity):2つのモデルを足したモデルの寄与は、各モデルの寄与の和。
加法性(局所正確性)が一番効く
実務でSHAPが好まれる最大の理由が、公理1から導かれる加法性です。1件の予測について、
- は基準値(base value)=全データの平均的な予測。
- 各特徴の寄与 をこれに足し合わせると、ちょうどその予測値 に一致します。
要するに、「平均的な予測 から出発し、各特徴がプラス/マイナスに押した分を足すと、最終予測に過不足なくたどり着く」。内訳が完全に閉じるので、説明として非常に納得感があります(LIMEの局所近似には、ここまでの厳密な閉じ方の保証はありません)。
計算コストと近似
ただし定義通りだと、部分集合 の数は特徴数に対して**指数的( 通り)**に増え、厳密計算は重い。そこで近似・高速化版が使われます。
- KernelSHAP:モデル非依存。重み付き線形回帰の形でシャープレイ値を近似する(どんなモデルにも使えるが重め)。
- TreeSHAP:決定木・ランダムフォレスト・勾配ブースティング専用。木の構造を利用して多項式時間で厳密なシャープレイ値を計算できる(高速)。
- DeepSHAP:ニューラルネット向けの近似。
flowchart TB
S["SHAP : シャープレイ値で寄与配分"] --> K["KernelSHAP<br/>(任意モデル・近似・重い)"]
S --> T["TreeSHAP<br/>(木モデル専用・厳密・高速)"]
S --> D["DeepSHAP<br/>(NN向け近似)"]
S --> P["加法性 : 寄与の和 = 予測 - 基準値"]
7. ⚠️ よくある誤解・落とし穴
- 解釈はあくまで近似である:LIME(局所線形近似)や KernelSHAP(サンプリング近似)は、真の判断根拠そのものではなくそれを推定したものです。設定や乱数で揺れます。後付け説明を「真実」と思い込まないこと。
- 重要度が高い = 原因ではない(相関≠因果):「特徴 の重要度が高い」は「モデルがその特徴に強く反応している」という意味であって、 が結果を引き起こす原因だとは限りません。例:アイスの売上が高い日は水難事故も多い(共通原因は気温)。介入してその特徴を変えたら結果が変わる、という因果の主張には別の枠組み(因果推論・反実仮想)が必要です。
- 相関した特徴で重要度が歪む:4節・5節で見た通り、強く相関する特徴は重要度が互いに希釈されたり、現実にない組み合わせへの外挿で値がブレたりします。特徴間の相関を確認せずにランキングを鵜呑みにしないこと。
- 木の不純度重要度のバイアス:取りうる値が多い特徴を過大評価します(3節)。並べ替え重要度やSHAPと突き合わせて確認するのが安全。
- 解釈を過信しない:もっともらしい説明が出ても、それは「モデルがそう振る舞っている」ことの説明にすぎず、モデルが正しい・公平である保証にはなりません。説明は意思決定を助ける材料であって、検証の代わりにはなりません。
対応するシミュレーション
simulations/permutation_importance.py:効く特徴3つと無関係な特徴3つが混ざったデータでランダムフォレストを学習し、並べ替え重要度を計算します。各特徴の値だけをシャッフルして関係を壊したときの正解率の低下量を重要度とすると、本当に効く特徴だけが大きく出て無関係な特徴はほぼ0になることを可視化します。モデル非依存に使える一方、特徴間の相関で重要度が分散する注意点(重回帰と多重共線性)にも触れます。