🎓 レベル:標準 | 重要度:B(標準)
📎 前提:訓練・検証・テストと交差検証 | 関連:ハイパーパラメータ最適化(実験)
要点(BLUF)
- MLOps は、機械学習モデルを「一度動かして終わり」ではなく、継続的に運用し続けるための仕組み・実践の総称です。研究の「動くモデル」と、本番の「運用できるシステム」はまったくの別物で、その差を埋めるのが MLOps です。
- DevOps との決定的な違いは、変わるものがコードだけではない点です。MLOps ではコードに加えてデータとモデルが変わるので、データとモデルもバージョン管理・テスト・監視の対象になります。
- 全体は データ → 学習 → 評価 → デプロイ → 監視 → 再学習 のループです。本番の性能や入力データの分布を監視し、劣化したら再学習をトリガーして閉じます。
1. なぜ MLOps か — 「動くモデル」から「運用できるシステム」へ
ノートブックで精度の出るモデルが作れた、というのは出発点にすぎません。本番で価値を出し続けるには、データの取り込み・前処理・学習・評価・配信・監視・再学習というシステム全体を回す必要があります。
ここで効いてくるのが 技術的負債(technical debt) です。Sculley らの有名な指摘に「機械学習のコードは、現実のMLシステム全体のごく一部にすぎない」というものがあります。実際にはコードの周りに、データ収集・データ検証・特徴抽出・設定管理・配信基盤・監視といった巨大な周辺コードがあり、そここそが運用コストの大半を生みます。
ML 特有の負債としてよく挙がるのが次の3つです。
- CACE 原則(Changing Anything Changes Everything):MLモデルは入力同士が絡み合う(entanglement)ため、ある特徴量を1つ足すだけで、無関係に見えた他の特徴量の重みまで動きます。「ここだけ変える」ができないのがMLの厄介さです。
- データ依存(data dependency):コードの依存はツールで追えますが、データの依存は追いにくい。特に入力シグナルが別のMLシステムの出力だったりすると、相手が勝手に更新されて自分が静かに壊れます。
- 隠れたフィードバックループ:モデルの出力が世界に作用し、それが次の入力データに混ざる。気づかないうちに自分の予測が自分の訓練データを汚染していきます。
要するに、MLは「コードを正しく書けば終わり」ではなく、データと世界が動き続ける前提で運用する必要がある。だから専用の規律=MLOpsが要るわけです。
DevOps と MLOps の違い
graph TB
subgraph DEV["DevOps(従来)"]
C1["コードを管理"]
C2["コードをテスト"]
C3["コードをデプロイ"]
end
subgraph ML["MLOps(拡張)"]
M1["コード + データ + モデル を管理"]
M2["コードに加え データ・スキーマ・モデル をテスト"]
M3["パイプラインをデプロイ"]
M4["継続的学習(CT)でモデルを再学習"]
end
DEV -.->|"対象が増える"| ML
DevOps が扱うのは基本的にコードです。一方 MLOps は、データ(とそのスキーマ)・モデルの妥当性まで検証し、さらに DevOps には無い CT(Continuous Training=継続的学習) を持ちます。CT が要るのは、MLモデルは通常のソフトより多くの理由で劣化するからです。コードを一行も変えていなくても、入力データの分布が変われば性能は勝手に落ちます(分布シフトと頑健性)。
2. 再現性 — 同じ結果をもう一度出せること
MLOps の土台は 再現性(reproducibility) です。「3か月前のあのモデルを、まったく同じ手順でもう一度作れるか?」に Yes と言えること。Yes と言えなければ、デバッグも監査も改善の比較もできません。
再現性のために固定すべきものは4つです。
- コード:学習スクリプト・前処理ロジック(Git でバージョン管理)
- データ:訓練・評価に使ったまさにそのデータ(後述のデータバージョン管理)
- 環境:ライブラリのバージョン・CUDA・OS。
requirements.txtをlatestではなく正確なバージョンで固定し、Docker イメージで丸ごと固める - 乱数シード:重みの初期化・データのシャッフル・データ分割などに使う乱数を固定する
⚠️ よくある落とし穴は 乱数シードだけ固定して安心することです。シードを固定しても、ライブラリのバージョンが違えば内部の計算が変わり結果はズレます。GPU では並列演算の順序が非決定的で、完全なビット一致は保証されないこともあります。再現性は「シード1つ」ではなく、コード・データ・環境・シードの4点セットで初めて成立すると考えてください。
3. 実験管理・追跡 — 試行を記録して比較する
モデル開発は本質的に多数の実験の比較です。学習率を変え、特徴量を足し、モデルを差し替え…と試すうちに、「どの設定が一番良かったんだっけ?」がすぐ分からなくなります。
これを防ぐのが 実験管理・追跡(experiment tracking) です。各実験ごとに次の3種類を自動で記録し、後から横並びで比較できるようにします。
- ハイパーパラメータ:学習率・正則化の強さ・木の深さなど(ハイパーパラメータ最適化 の探索は、まさに大量の実験を回す行為そのものです)
- 指標(メトリクス):訓練/検証の損失・精度・AUC など
- 成果物(アーティファクト):学習済みモデル本体・評価グラフ・前処理の統計量
ポイントは、設定 → 結果 の対応を機械的に残すことです。Excel に手で書くのではなく、実験のたびに自動でログされる仕組みにしておくと、再現性とも自然につながります(記録された設定をそのまま再実行できる)。
4. バージョン管理 — コードだけでは足りない
通常のソフトでは Git でコードを管理すれば十分です。ML では コード・データ・モデル・特徴量の4つをバージョン管理する必要があります。
| 対象 | なぜバージョン管理するか |
|---|---|
| コード | 学習・前処理の手順。Git の通常の役割 |
| データ | 同じコードでもデータが違えばモデルが変わる。「どのデータで学習したか」を固定しないと再現できない |
| モデル | 学習済みの重み。本番でどのバージョンが動いているか追え、問題時に前のバージョンへ戻せる(ロールバック) |
| 特徴量 | 同じ生データから作る特徴量の定義。学習時と推論時で計算がズレると訓練/サービング・スキューという静かな事故になる |
なぜデータまで管理するかというと、再現性の式が「モデル = コード × データ × 環境 × シード」だからです。どれか1つでも記録が欠ければ、同じモデルは二度と作れません。データは巨大なので、実体をそのまま Git に入れるのではなく、データのハッシュ(指紋)や参照だけをバージョン管理し、実体はストレージに置くのが定石です。
5. デプロイ — バッチ推論とオンライン推論
学習したモデルを本番で使えるようにするのがデプロイです。配信の形は大きく2つあり、いつ予測結果が必要かで選びます。
flowchart LR
subgraph BATCH["バッチ推論(オフライン)"]
B1["大量データを まとめて予測"] --> B2["結果をDBに保存"] --> B3["後で参照"]
end
subgraph ONLINE["オンライン推論(リアルタイム)"]
O1["1件のリクエスト"] --> O2["APIが即座に予測"] --> O3["数ミリ秒で返す"]
end
- バッチ推論(オフライン):大量のデータをまとめて定期的に予測し、結果を保存しておく方式。レコメンドの夜間バッチなど、即時性が要らないケース向け。シンプルで計算も安く済みます。欠点は、新しい入力(新規ユーザーなど)にはバッチが回るまで予測が無いこと。
- オンライン推論(リアルタイム):1件ずつのリクエストに対し、API がその場で予測を返す方式。Webリクエスト1回の中(数ミリ秒〜)で結果が要るケース向け。即時性が高い反面、レイテンシ SLA を守る運用が必要で、コストも上がります。
CI/CD — 自動でテストして届ける
DevOps から来た CI/CD も MLOps の柱です。
- CI(継続的インテグレーション):コードを変えたら自動でテスト・ビルドする。ML ではコードのテストに加え、データの検証やモデルの妥当性検証まで含めます。
- CD(継続的デリバリ):検証を通った成果物を自動で本番に届ける。ML で「届ける」対象はモデル単体のこともありますが、成熟したチームでは学習パイプラインそのものを届けます。
MLOps では DevOps の CI/CD に CT(継続的学習) が加わって 3点セットになる、と覚えておくと整理しやすいです。
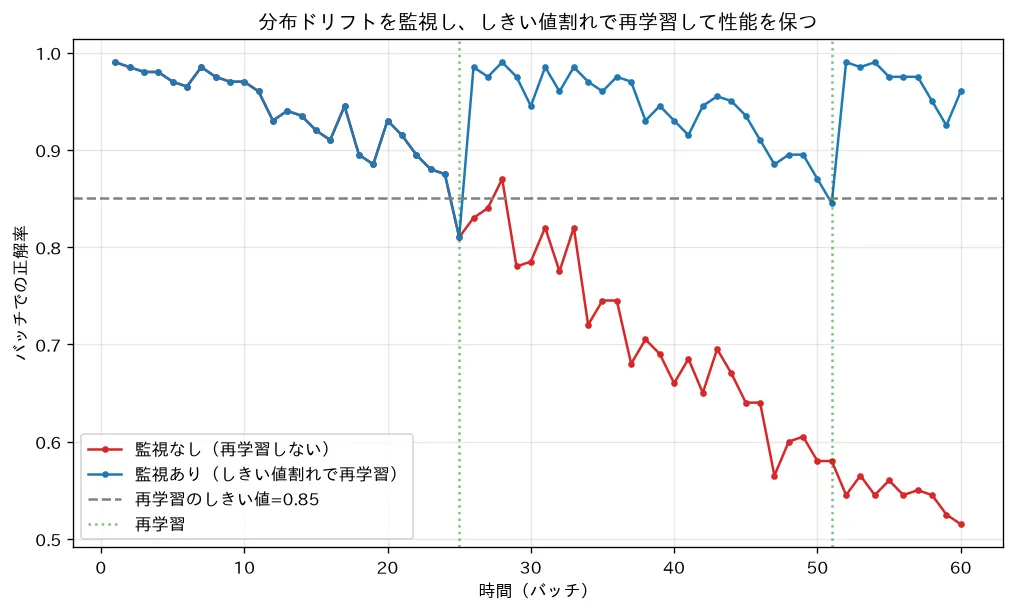
6. 監視と再学習 — ループを閉じる
デプロイは終わりではなく始まりです。本番に出した瞬間からモデルは劣化し始めるので、監視して、劣化したら再学習する必要があります。
監視する対象は主に3つです。
- 本番性能:実際の予測精度・ビジネス指標。ただし正解ラベルが遅れて届く(または届かない)ことが多く、直接の精度監視は難しい場合があります。
- 分布シフト:入力データの分布が訓練時からズレていないか(分布シフトと頑健性)。正解ラベルが無くても入力の分布変化なら検知できるため、実務では性能劣化の早期警報としてよく使われます。
- データ品質:欠損の急増・想定外の値・スキーマ違反など、入口のデータそのものの異常。
これらが閾値を超えたら 再学習(retraining) をトリガーします。トリガーの代表は、(1) 性能が閾値を下回った、(2) 分布シフトが許容を超えた、(3) 定期スケジュール(毎週など)、(4) 新しいデータが一定量たまった、の4つです。
⚠️ 大事なのは、再学習したモデルを無条件に本番へ出さないことです。新モデルは必ず旧モデルと評価で比較し、改善が確認できた場合だけ昇格させます(自動だとしても、検証ゲートを必ず通す)。盲目的な自動再学習は、汚れたデータでモデルを悪化させる事故につながります。
7. ML ライフサイクル — 全体は1つのループ
ここまでの要素は、独立した工程ではなく1本のループとしてつながっています。これが MLOps の全体像です。
flowchart LR DATA["データ収集・準備"] --> TRAIN["学習"] TRAIN --> EVAL["評価(旧モデルと比較)"] EVAL --> DEPLOY["デプロイ(バッチ / オンライン)"] DEPLOY --> MONITOR["監視(性能・分布シフト・品質)"] MONITOR -->|"劣化を検知 → 再学習をトリガー"| DATA
このループの自動化の度合いが、チームの成熟度を表します。よく使われる整理(Google Cloud の MLOps 成熟度)では次の3段階です。
- レベル0(手動):データ科学者がノートブックでモデルを作り、エンジニアに手渡しで本番化する。再学習はまれで、監視も無い。
- レベル1(パイプライン自動化+CT):学習をパイプライン化し、データ検証・モデル検証を組み込み、トリガーで自動再学習する。新しいパイプライン自体のデプロイはまだ手動。
- レベル2(CI/CD パイプライン自動化):パイプラインのコード変更まで自動でテスト・デプロイする。新しい特徴量やアルゴリズムを高速に試して本番へ流せる。
最初から全自動を目指す必要はありません。まず再現性と実験管理を固め、次に監視を入れ、それから再学習を自動化するという順で成熟度を上げていくのが現実的です。
8. ⚠️ 要最新確認 — ツールと LLMOps は動きが速い
このノートは 廃れにくい原理(再現性・実験管理・バージョン管理・デプロイ形態・監視と再学習のループ・成熟度)に絞って書いています。理由は、具体的なツールやサービスの寿命が短く、勢力図が数年で入れ替わるからです。実験管理・データバージョン管理・パイプライン基盤・モデル配信のツール名は、採用時点で必ず最新の比較を自分で確認してください(本ノートは原理の理解を目的とし、特定ツールは推奨しません)。
加えて、LLMOps(大規模言語モデルの運用、大規模言語モデル 目次)は急速に発展中の領域です。LLM では「学習」よりプロンプト・検索拡張・推論コスト・評価が運用の中心になり、本ノートの古典的MLOpsとは重心が変わります。LLMOps の具体については要最新確認としておきます。
対応するシミュレーション
simulations/mlops_monitoring.py:入力分布が時間とともにずれる(ドリフトする)データストリームで、再学習しないと精度がじわじわ下がり続ける(黙って劣化する)一方、精度を監視してしきい値を割ったら最近のデータで再学習するとそのつど性能が回復し一定水準を保てることを可視化します。「学習して終わり」ではなく「監視→異常検知→再学習→デプロイ」を回し続けるのが MLOps の中心で、実験管理(データ・コード・パラメータのバージョン管理)や CACE も論点です。