🎓 レベル:発展 | 重要度:B(標準)
📎 前提:汎化と過学習・バイアスバリアンス分解 | 関連:訓練・検証・テストと交差検証
要点(BLUF)
- 分布シフトとは、学習時のデータ分布と運用(テスト)時のデータ分布が食い違う現象です。汎化理論が前提とする i.i.d.(独立同分布)仮定が破綻し、テスト誤差の保証が効かなくなります。
- 同時分布を と分解すると、どこが変わるかで3類型になります。共変量シフト( が変化)・ラベルシフト( が変化)・概念ドリフト( そのものが変化)。
- 共変量シフト/ラベルシフトは 重要度重み付け で補正できますが、概念ドリフトは入力と正解の関係が変わるため重み付けでは直らず、再学習が必須です。検知自体が難しく、オフライン評価が良くても本番で崩れることが多い領域です。
1. i.i.d. 仮定の破綻 — なぜ汎化の保証が消えるか
機械学習の汎化(汎化と過学習・バイアスバリアンス分解・汎化理論)は、ある暗黙の前提の上に立っています。それは 訓練データもテストデータも、同じ1つの分布 から独立同分布(i.i.d.)で取られている というものです。
私たちが最小化しているのは訓練データ上の経験リスク ですが、本当に小さくしたいのは未知データ上の期待リスク
です。汎化バウンドが「訓練誤差が小さければテスト誤差も小さい」と言えるのは、 と が同じ の上で定義されているからです。
ところが本番運用では、データを生む分布が訓練時の から運用時の へずれます。すると最小化していた ( 上)と、本当に効く ( 上)が別物になります。
要するに、汎化の保証は「同じ世界でテストする」という約束込みのもので、本番で世界が変われば保証ごと無効になります。これが分布シフトで本番モデルが劣化する根本理由です。
2. 分布シフトの3類型 — 同時分布のどこが変わるか
同時分布を2通りに分解します。
「どの因子が変わり、どの因子が不変か」で類型が決まります。
graph TD ROOT["分布シフト P(x,y) が train と test で異なる"] --> COV["共変量シフト covariate shift"] ROOT --> LBL["ラベルシフト label shift"] ROOT --> CON["概念ドリフト concept drift"] COV --> COVD["P(x) が変化 ・ P(y|x) は不変"] LBL --> LBLD["P(y) が変化 ・ P(x|y) は不変"] CON --> COND["P(y|x) 自体が変化 (関係が変わる)"] COVD --> COVF["対策:重要度重み付け w(x) で補正可"] LBLD --> LBLF["対策:w(y) で補正可(未ラベルでも推定可)"] COND --> CONF["対策:重み付けでは不可 → 再学習が必須"]
2-1. 共変量シフト(covariate shift)
入力の分布 だけが変わり、入力から正解への関係 は不変 な場合です。
「入力ドリフト」「データドリフト」とも呼ばれます。たとえば、ある地域の患者で訓練した診断モデルを別の年齢構成の地域に出す場合、特徴量の分布は変わっても「この特徴ならこの病気」という関係自体は同じ、というイメージです。
2-2. ラベルシフト(label shift)
正解(クラス)の分布 が変わり、各クラスがどんな入力を生むか は不変 な場合です。
「事前確率シフト」とも呼ばれます。原因(病気 )が結果(症状 )を生むような因果構造で自然に起きます。たとえば流行で病気の有病率 が跳ね上がっても、「その病気が出す症状の出方 」は変わらない、という状況です。
2-3. 概念ドリフト(concept drift)
入力と正解の関係 そのものが変わる 場合です。これが一番厄介です。
「同じ入力に対する正解が、時間とともに変わってしまう」状態です。スパム判定で、スパマーが手口を変えれば「同じ文面」が以前は正常・今はスパム、と正解ラベルが反転します。需要予測で消費者の嗜好が変われば、同じ条件でも売れ行きが変わります。入力 の見た目は変わらないのに正解が変わるため、入力を観察するだけの監視では気づきにくいのが特徴です。
用語の注意:実務記事では「データドリフト= の変化(共変量シフト)」「概念ドリフト= の変化」と対比されることが多いです。一方で学術的には「concept drift」を同時分布 の任意の変化を指す広義語として使う流派もあります。文脈で広狭が変わる点に注意してください。本ノートでは上の狭義( の変化)で使います。
3. なぜ劣化するか — 重み付けの理論的裏付け
3-1. 期待リスクのずれと重要度重み付け
共変量シフトを例に、なぜ素朴な訓練がバイアスを持つのか、そしてどう直すのかを数式で見ます。本当に小さくしたいのはテスト分布上の期待リスクです。
ここで を掛けて割る、重要度サンプリングの恒等式を使います。
つまり、訓練分布から取った各サンプルに重み を掛けて平均すれば、テスト分布上のリスクを訓練データだけで不偏に推定できるということです(この比は測度論的には Radon–Nikodym 微分にあたります)。これが 重要度重み付け(importance weighting) の出発点で、Shimodaira (2000) が共変量シフト補正として導入しました。実際の重み付き経験リスク最小化はこうなります。
要するに、テスト側で多く出る領域のサンプルを重く、ほとんど出ない領域を軽く扱い直すことで、訓練データだけで「テスト世界での平均誤差」を最小化します。
3-2. 重要な但し書き:モデルが正しければ重み付けは要らない
ここが発展トピックの肝です。共変量シフトがあっても、モデル族が真の を表現できる(well-specified)なら、重み無しの素朴な最尤/ERM でも漸近的に正しい推定が得られます。 は不変なので、 をどこでサンプリングしようと、十分なデータがあれば正しい条件付き分布に収束するからです。
重要度重み付けが効くのは、モデルが誤特定(misspecified)されているときです。表現力が足りないと、モデルは「データが密に来る領域」を優先して当てにいきます。訓練とテストで密な領域がずれていると、訓練で重視した領域とテストで効く領域が食い違い、バイアスが生じます。重みは「テストで効く領域を重視し直す」ことでこのバイアスを補正します。
flowchart TD
Q["共変量シフトがある"] --> SPEC{"モデルは真の P(y|x) を表現できるか"}
SPEC -->|"できる(well-specified)"| OK["素朴な学習でも漸近的に正しい → 重み付け不要"]
SPEC -->|"できない(misspecified)"| WT["どの領域を優先するかでバイアス → 重要度重み付けが有効"]
要するに、「分布がずれたら必ず重み付けすべき」ではありません。重み付けは万能薬ではなく、有限データ・有限表現力という現実の不完全さを補正する道具です(しかも重みの分散が大きいと推定が不安定になる副作用もあります)。
3-3. ラベルシフトの補正と検知
ラベルシフトでは、重みは入力ではなく ラベル に付きます。
問題は、運用時にはラベルが手に入らないことです。ラベル無しのテスト入力だけから をどう推定するか が鍵になります。これを解くのが BBSE(Black Box Shift Estimation, Lipton et al. 2018) です。
考え方はシンプルです。既存分類器 の予測 について、訓練データで作った混同行列 は、ラベルシフト下では運用時にも不変です( が不変だから予測の出方も不変)。すると運用時の予測分布は
という線形関係になります。左辺(運用時の予測分布)は未ラベルでも数えられ、混同行列は訓練データから作れます。よって 混同行列が可逆なら、この連立方程式を解いて を逆算できる わけです。分類器が多少不正確・未校正でも、混同行列が可逆でありさえすれば一貫性が保証される、という点が実務的に強力です。
4. 検知 — シフトをどう見つけるか
シフト対策の前段は「気づくこと」です。手段は大きく2つです(MLOpsと実験管理 の監視の一部)。
| 監視対象 | 何を見るか | 長所 / 短所 |
|---|---|---|
| 性能監視 | 本番の予測精度・損失(正解ラベルが取れる場合) | 最も直接的。だが正解ラベルが遅延 or 入手不能だと使えない |
| 入力分布の監視 | 特徴量分布 の訓練 vs 本番の距離 | ラベル不要で常時可能。だが概念ドリフトは 不変なので検知できない |
入力分布の距離としてよく使うのは、
- コルモゴロフ–スミルノフ検定(KS検定):1次元連続特徴の分布が変わったかの検定
- カイ二乗検定:カテゴリ特徴の分布変化の検定
- PSI(Population Stability Index):ビン化した分布の安定性指標(実務で広く使われる)
- KLダイバージェンス / JSダイバージェンス:分布間のずれの情報量的な距離
flowchart LR
IN["本番データが届く"] --> M1{"正解ラベルは取れるか"}
M1 -->|"取れる"| PERF["性能監視(精度・損失の劣化を検知)"]
M1 -->|"取れない / 遅延"| DIST["入力分布の距離を監視(KS ・ PSI ・ KL)"]
PERF --> ALERT{"閾値を超えたか"}
DIST --> ALERT
ALERT -->|"超えた"| ACT["対策:重み付け / 再学習 / ドメイン適応"]
ALERT -->|"範囲内"| KEEP["現行モデルを継続"]
要するに、ラベルが取れるなら性能を直接見るのが一番確実で、取れないなら入力分布の距離で代理監視します。ただし入力分布の監視だけでは概念ドリフトを取りこぼすため、可能なら遅延ラベルでの性能再評価を組み合わせます。
5. 対策 — 補正・再学習・ドメイン適応
シフトの型に応じて手段が変わります。型を取り違えると対策が空振りします。
| 型 | 何が変わった | 主な対策 |
|---|---|---|
| 共変量シフト | 重要度重み付け で再重み付け / 再学習 | |
| ラベルシフト | による再重み付け(BBSEで を推定)・事後確率の補正 | |
| 概念ドリフト | 再学習が必須(新しい正解ラベル付きデータで学び直す) |
主要な打ち手は次の通りです。
- 重要度重み付け(reweighting):共変量/ラベルシフト向け。密度比 を推定し、訓練を重み付けし直す。再学習より安価で、多くの場合ギャップの大半を埋められるのが利点。一方、 の推定は難しく(特に高次元では密度比の分散が大きくなる)、重みが極端だと有効サンプルサイズが減り推定が不安定になります。
- 再学習(retraining):最も広く使われる産業的アプローチ。新しいデータで学び直す。概念ドリフトには再学習しか効きません(関係そのものが変わったので、過去の関係を重み付けし直しても無駄)。定期再学習・シフト検知トリガーでの再学習・オンライン学習(逐次更新)などの運用形態があります。
- ドメイン適応(domain adaptation):とくに教師なしドメイン適応は、ターゲット側のラベル無しで、ソースとターゲットで不変な表現を学習し、分布差そのものを表現空間で縮める方向です。
- 頑健な学習(robust learning):単一分布への過適合を避け、分布の集合(不確実性集合)に対する最悪ケースを最小化する**分布的にロバストな最適化(DRO)**など、設計段階でシフト耐性を組み込む方向です。
⚠️ よくある誤解・落とし穴
- 「分布がずれたら重み付けで直せる」ではない。重み付けが効くのは が不変な共変量/ラベルシフトのときだけです。概念ドリフト( の変化)は重み付けでは直らず、再学習が要ります。型の誤診が一番多い失敗です。
- シフト検知そのものが難しい。入力分布の監視はラベル不要で常時できますが、概念ドリフトは が変わらないので入力監視では検知できません。逆に性能監視は確実ですが、正解ラベルが遅延・入手不能だと回りません。万能な検知器は存在しません。
- オフライン評価が良くても本番で崩れる。交差検証(訓練・検証・テストと交差検証)は手元データ=同一分布の前提で性能を測ります。本番分布がずれていれば、その良いスコアはずれた世界では保証になりません。デプロイ後の継続監視が前提です。
- 重み付けはタダではない。重みの分散が大きいと有効サンプルサイズが目減りし、補正したつもりが推定をかえって不安定にします。密度比推定は高次元で特に難しく、「重み付け=無料の改善」ではありません。
- 共変量シフトでもモデルが正しければ重み付け不要。表現力が十分(well-specified)なら素朴な学習で漸近的に正しい解に届きます。重み付けは有限データ・誤特定という不完全さの補正であって、原理的な必須手順ではありません。
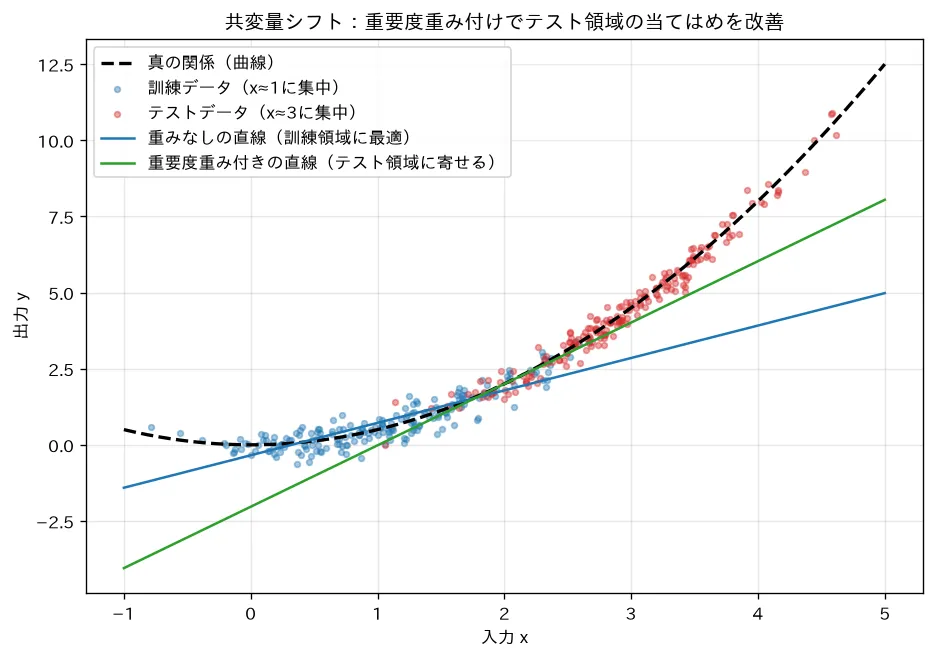
対応するシミュレーション
simulations/distribution_shift.py:入力分布が訓練()と運用()でずれた共変量シフトを作り、曲線の関係を直線で近似(モデル誤設定)した場合を見ます。重みなしの直線は訓練が密な領域の傾きに合わせてテスト領域で外れる一方、「テスト密度/訓練密度」を重要度重みにして当てはめ直すとテスト領域での誤差が大きく下がる(テストMSE 4.4→0.85)ことを可視化します。関係 自体が変わる概念ドリフトでは再学習が要る点にも触れます。