← 統計検定テキスト 一覧
📊 対象級:準1級 ・ 1級 | 重要度:C(低頻度)
順序統計量の分布
要点(BLUF)
順序統計量 :標本 X 1 , … , X n X_1,\dots,X_n X 1 , … , X n 小さい順に並べ替えた ものを X ( 1 ) ≤ X ( 2 ) ≤ ⋯ ≤ X ( n ) X_{(1)}\le X_{(2)}\le\dots\le X_{(n)} X ( 1 ) ≤ X ( 2 ) ≤ ⋯ ≤ X ( n ) X ( 1 ) X_{(1)} X ( 1 ) X ( n ) X_{(n)} X ( n ) X ( k ) X_{(k)} X ( k ) k k k k k k 導出の核(これ1つ) :「X ( k ) ≤ x X_{(k)}\le x X ( k ) ≤ x n n n x x x k k k x x x B i n ( n , F ( x ) ) \mathrm{Bin}(n,F(x)) Bin ( n , F ( x )) k k k 全部 出る。
f X ( k ) ( x ) = n ! ( k − 1 ) ! ( n − k ) ! f ( x ) F ( x ) k − 1 { 1 − F ( x ) } n − k \boxed{\,f_{X_{(k)}}(x)=\dfrac{n!}{(k-1)!\,(n-k)!}\,f(x)\,F(x)^{k-1}\,\{1-F(x)\}^{n-k}\,} f X ( k ) ( x ) = ( k − 1 )! ( n − k )! n ! f ( x ) F ( x ) k − 1 { 1 − F ( x ) } n − k x x x k − 1 k-1 k − 1 x x x n − k n-k n − k 一様分布だと正体がベータ :X i ∼ U ( 0 , 1 ) X_i\sim U(0,1) X i ∼ U ( 0 , 1 ) F ( x ) = x F(x)=x F ( x ) = x X ( k ) ∼ B e ( k , n − k + 1 ) X_{(k)}\sim \mathrm{Be}(k,\,n-k+1) X ( k ) ∼ Be ( k , n − k + 1 ) E [ X ( k ) ] = k n + 1 E[X_{(k)}]=\dfrac{k}{n+1} E [ X ( k ) ] = n + 1 k n n n [ 0 , 1 ] [0,1] [ 0 , 1 ] 等間隔に分け合う イメージ。
本文
0. なにを並べ替えるのか
標本 X 1 , X 2 , … , X n X_1,X_2,\dots,X_n X 1 , X 2 , … , X n 値の小さい順に並べ替える と、
X ( 1 ) ≤ X ( 2 ) ≤ ⋯ ≤ X ( n ) X_{(1)}\le X_{(2)}\le \dots \le X_{(n)} X ( 1 ) ≤ X ( 2 ) ≤ ⋯ ≤ X ( n )
という新しい確率変数の列ができます。これらを**順序統計量(order statistics)**と呼びます。括弧つきの添字 ( k ) (k) ( k ) k k k X k X_k X k k k k
記号 意味 別名 X ( 1 ) X_{(1)} X ( 1 ) 最小値 min i X i \min_i X_i min i X i 第1順序統計量 X ( n ) X_{(n)} X ( n ) 最大値 max i X i \max_i X_i max i X i 第 n n n X ( k ) X_{(k)} X ( k ) k k k 第 k k k X ( n ) − X ( 1 ) X_{(n)}-X_{(1)} X ( n ) − X ( 1 ) 範囲(レンジ) range X ( ( n + 1 ) / 2 ) X_{((n+1)/2)} X (( n + 1 ) /2 ) 中央値 median(n n n
前提:以下では X 1 , … , X n X_1,\dots,X_n X 1 , … , X n 独立同分布(i.i.d.)で、共通の累積分布関数(CDF)F ( x ) = P ( X ≤ x ) F(x)=P(X\le x) F ( x ) = P ( X ≤ x ) f ( x ) = F ′ ( x ) f(x)=F'(x) f ( x ) = F ′ ( x ) 連続分布 とします。連続なら同点(タイ)が確率0で起きないので、不等号はすべて狭義 X ( 1 ) < ⋯ < X ( n ) X_{(1)}<\dots<X_{(n)} X ( 1 ) < ⋯ < X ( n )
graph LR
R["生データ X1,X2,...,Xn 取った順"] --> S["小さい順に並べ替え"]
S --> O1["X(1) 最小"]
S --> Ok["X(k) 第k"]
S --> On["X(n) 最大"]
O1 --> RANGE["範囲 = X(n) - X(1)"]
On --> RANGE
Ok --> MED["中央値 = 真ん中の順序統計量"]
なぜ重要か:極値 (洪水の最大水位、部品寿命の最小値=一番早く壊れるもの)、範囲 (管理図のレンジ R R R 中央値・分位点 (外れ値に強い要約)はどれも順序統計量です。ノンパラメトリック手法(ノンパラメトリック検定(符号・順位和・Wilcoxon) )や信頼区間の一部も順序統計量で構成されます。
1. 導出の核:「x x x
順序統計量の分布はすべて、次の橋渡しから出ます。
各 X i X_i X i X i ≤ x X_i\le x X i ≤ x x x x F ( x ) F(x) F ( x ) n n n x x x N x N_x N x B i n ( n , F ( x ) ) \mathrm{Bin}(n,\,F(x)) Bin ( n , F ( x ))
ここで決定的な同値関係:
{ X ( k ) ≤ x } ⟺ { x 以下の個数が k 個以上 } = { N x ≥ k } . \{X_{(k)}\le x\}\ \Longleftrightarrow\ \{x\text{ 以下の個数が }k\text{ 個以上}\}=\{N_x\ge k\}. { X ( k ) ≤ x } ⟺ { x 以下の個数が k 個以上 } = { N x ≥ k } .
要するに :「k k k x x x k k k x x x k k k k k k x x x 二項分布の問題に翻訳 します。
graph TD
Q["X(k) ≤ x ?"] --> E["⇔ x以下の個数 Nx ≥ k"]
E --> B["Nx ~ Bin(n, F(x))"]
B --> CDF["F_X(k)(x) = P(Nx ≥ k) = Σ_(j=k)^n C(n,j) F(x)^j (1-F(x))^(n-j)"]
2. 最大値・最小値(特別な場合から先に)
第 k k k k = n k=n k = n k = 1 k=1 k = 1
2-1. 最大値 X ( n ) X_{(n)} X ( n )
「最大値が x x x 全員が x x x
F X ( n ) ( x ) = P ( X ( n ) ≤ x ) = P ( X 1 ≤ x , … , X n ≤ x ) = ∏ i = 1 n P ( X i ≤ x ) = F ( x ) n . F_{X_{(n)}}(x)=P(X_{(n)}\le x)=P(X_1\le x,\dots,X_n\le x)=\prod_{i=1}^n P(X_i\le x)=F(x)^n. F X ( n ) ( x ) = P ( X ( n ) ≤ x ) = P ( X 1 ≤ x , … , X n ≤ x ) = ∏ i = 1 n P ( X i ≤ x ) = F ( x ) n .
密度はこれを微分(合成関数の微分、d d x F ( x ) n = n F ( x ) n − 1 f ( x ) \dfrac{d}{dx}F(x)^n=nF(x)^{n-1}f(x) d x d F ( x ) n = n F ( x ) n − 1 f ( x )
f X ( n ) ( x ) = n f ( x ) F ( x ) n − 1 . \boxed{\,f_{X_{(n)}}(x)=n\,f(x)\,F(x)^{n-1}\,}. f X ( n ) ( x ) = n f ( x ) F ( x ) n − 1 .
要するに :最大値が x x x x x x f ( x ) f(x) f ( x ) × n \times n × n n − 1 n-1 n − 1 x x x F ( x ) F(x) F ( x )
2-2. 最小値 X ( 1 ) X_{(1)} X ( 1 )
「最小値が x x x 大きい 」⇔「全員が x x x
P ( X ( 1 ) > x ) = P ( X 1 > x , … , X n > x ) = { 1 − F ( x ) } n . P(X_{(1)}>x)=P(X_1>x,\dots,X_n>x)=\{1-F(x)\}^n. P ( X ( 1 ) > x ) = P ( X 1 > x , … , X n > x ) = { 1 − F ( x ) } n .
よってCDFは
F X ( 1 ) ( x ) = 1 − P ( X ( 1 ) > x ) = 1 − { 1 − F ( x ) } n . F_{X_{(1)}}(x)=1-P(X_{(1)}>x)=1-\{1-F(x)\}^n. F X ( 1 ) ( x ) = 1 − P ( X ( 1 ) > x ) = 1 − { 1 − F ( x ) } n .
微分して(d d x { 1 − F ( x ) } n = − n { 1 − F ( x ) } n − 1 f ( x ) \dfrac{d}{dx}\{1-F(x)\}^n=-n\{1-F(x)\}^{n-1}f(x) d x d { 1 − F ( x ) } n = − n { 1 − F ( x ) } n − 1 f ( x )
f X ( 1 ) ( x ) = n f ( x ) { 1 − F ( x ) } n − 1 . \boxed{\,f_{X_{(1)}}(x)=n\,f(x)\,\{1-F(x)\}^{n-1}\,}. f X ( 1 ) ( x ) = n f ( x ) { 1 − F ( x ) } n − 1 .
要するに :最小値が x x x x x x × n \times n × n n − 1 n-1 n − 1 x x x 1 − F ( x ) 1-F(x) 1 − F ( x ) F ↔ 1 − F F\leftrightarrow 1-F F ↔ 1 − F
3. 第 k k k
一般の X ( k ) X_{(k)} X ( k ) (A) CDFを二項和で書いて微分 、(B) 微小区間で多項分布として直接 。どちらも同じ式に着地します。
(A) CDFを微分する(二項和ルート)
第1節の核から、CDFは「x x x k k k
F X ( k ) ( x ) = P ( N x ≥ k ) = ∑ j = k n ( n j ) F ( x ) j { 1 − F ( x ) } n − j . F_{X_{(k)}}(x)=P(N_x\ge k)=\sum_{j=k}^{n}\binom{n}{j}F(x)^j\,\{1-F(x)\}^{n-j}. F X ( k ) ( x ) = P ( N x ≥ k ) = ∑ j = k n ( j n ) F ( x ) j { 1 − F ( x ) } n − j .
これを x x x F ′ ( x ) = f ( x ) F'(x)=f(x) F ′ ( x ) = f ( x ) 隣り合う項どうしが望遠鏡的に打ち消し合い(telescoping) 、中央の1項だけが残ります。結果(途中計算は本節末の補足参照):
f X ( k ) ( x ) = n ! ( k − 1 ) ! ( n − k ) ! f ( x ) F ( x ) k − 1 { 1 − F ( x ) } n − k . \boxed{\,f_{X_{(k)}}(x)=\frac{n!}{(k-1)!\,(n-k)!}\,f(x)\,F(x)^{k-1}\,\{1-F(x)\}^{n-k}\,}. f X ( k ) ( x ) = ( k − 1 )! ( n − k )! n ! f ( x ) F ( x ) k − 1 { 1 − F ( x ) } n − k .
(B) 微小区間で直接数える(多項分布ルート・直感的)
密度の定義 f X ( k ) ( x ) d x ≈ P ( X ( k ) ∈ [ x , x + d x ] ) f_{X_{(k)}}(x)\,dx\approx P\big(X_{(k)}\in[x,x+dx]\big) f X ( k ) ( x ) d x ≈ P ( X ( k ) ∈ [ x , x + d x ] ) n n n X ( k ) X_{(k)} X ( k ) [ x , x + d x ] [x,x+dx] [ x , x + d x ]
箱 条件 個数 1個あたり確率 左 x x x k − 1 k-1 k − 1 F ( x ) F(x) F ( x ) 中 [ x , x + d x ] [x,x+dx] [ x , x + d x ] ちょうど1個 f ( x ) d x f(x)\,dx f ( x ) d x 右 x + d x x+dx x + d x n − k n-k n − k 1 − F ( x ) 1-F(x) 1 − F ( x )
「どの個体がどの箱か」の割り当て総数は多項係数 n ! ( k − 1 ) ! 1 ! ( n − k ) ! \dfrac{n!}{(k-1)!\,1!\,(n-k)!} ( k − 1 )! 1 ! ( n − k )! n !
f X ( k ) ( x ) d x = n ! ( k − 1 ) ! ( n − k ) ! ⏟ 割り当て数 F ( x ) k − 1 f ( x ) d x ⏟ 中の1個 { 1 − F ( x ) } n − k . f_{X_{(k)}}(x)\,dx=\underbrace{\frac{n!}{(k-1)!\,(n-k)!}}_{\text{割り当て数}}\,F(x)^{k-1}\,\underbrace{f(x)\,dx}_{\text{中の1個}}\,\{1-F(x)\}^{n-k}. f X ( k ) ( x ) d x = 割り当て数 ( k − 1 )! ( n − k )! n ! F ( x ) k − 1 中の 1 個 f ( x ) d x { 1 − F ( x ) } n − k .
両辺を d x dx d x 要するに :第 k k k x x x k − 1 k-1 k − 1 x x x n − k n-k n − k
graph LR
L["左の箱: k-1 個 各 F(x)"] --- C["中の箱: 1個 f(x)dx"]
C --- Rt["右の箱: n-k 個 各 1-F(x)"]
M["多項係数 n! / ((k-1)! 1! (n-k)!)"] -.掛ける.-> C
整合チェック
k = n k=n k = n n ! ( n − 1 ) ! 0 ! = n \dfrac{n!}{(n-1)!\,0!}=n ( n − 1 )! 0 ! n ! = n F n − 1 { 1 − F } 0 = F n − 1 F^{n-1}\{1-F\}^0=F^{n-1} F n − 1 { 1 − F } 0 = F n − 1 n f F n − 1 nf\,F^{n-1} n f F n − 1 k = 1 k=1 k = 1 n ! 0 ! ( n − 1 ) ! = n \dfrac{n!}{0!\,(n-1)!}=n 0 ! ( n − 1 )! n ! = n F 0 { 1 − F } n − 1 F^{0}\{1-F\}^{n-1} F 0 { 1 − F } n − 1 n f { 1 − F } n − 1 nf\{1-F\}^{n-1} n f { 1 − F } n − 1
💡 補足((A) のtelescoping):d d x ∑ j = k n ( n j ) F j ( 1 − F ) n − j \dfrac{d}{dx}\sum_{j=k}^n\binom{n}{j}F^j(1-F)^{n-j} d x d ∑ j = k n ( j n ) F j ( 1 − F ) n − j j j j + ( n j ) j F j − 1 ( 1 − F ) n − j f +\binom{n}{j}jF^{j-1}(1-F)^{n-j}f + ( j n ) j F j − 1 ( 1 − F ) n − j f − ( n j ) ( n − j ) F j ( 1 − F ) n − j − 1 f -\binom{n}{j}(n-j)F^{j}(1-F)^{n-j-1}f − ( j n ) ( n − j ) F j ( 1 − F ) n − j − 1 f ( n j ) j = ( n j − 1 ) ( n − j + 1 ) \binom{n}{j}j=\binom{n}{j-1}(n-j+1) ( j n ) j = ( j − 1 n ) ( n − j + 1 ) j = k j=k j = k ( n k ) k F k − 1 ( 1 − F ) n − k f \binom{n}{k}kF^{k-1}(1-F)^{n-k}f ( k n ) k F k − 1 ( 1 − F ) n − k f ( n k ) k = n ! ( k − 1 ) ! ( n − k ) ! \binom{n}{k}k=\dfrac{n!}{(k-1)!(n-k)!} ( k n ) k = ( k − 1 )! ( n − k )! n !
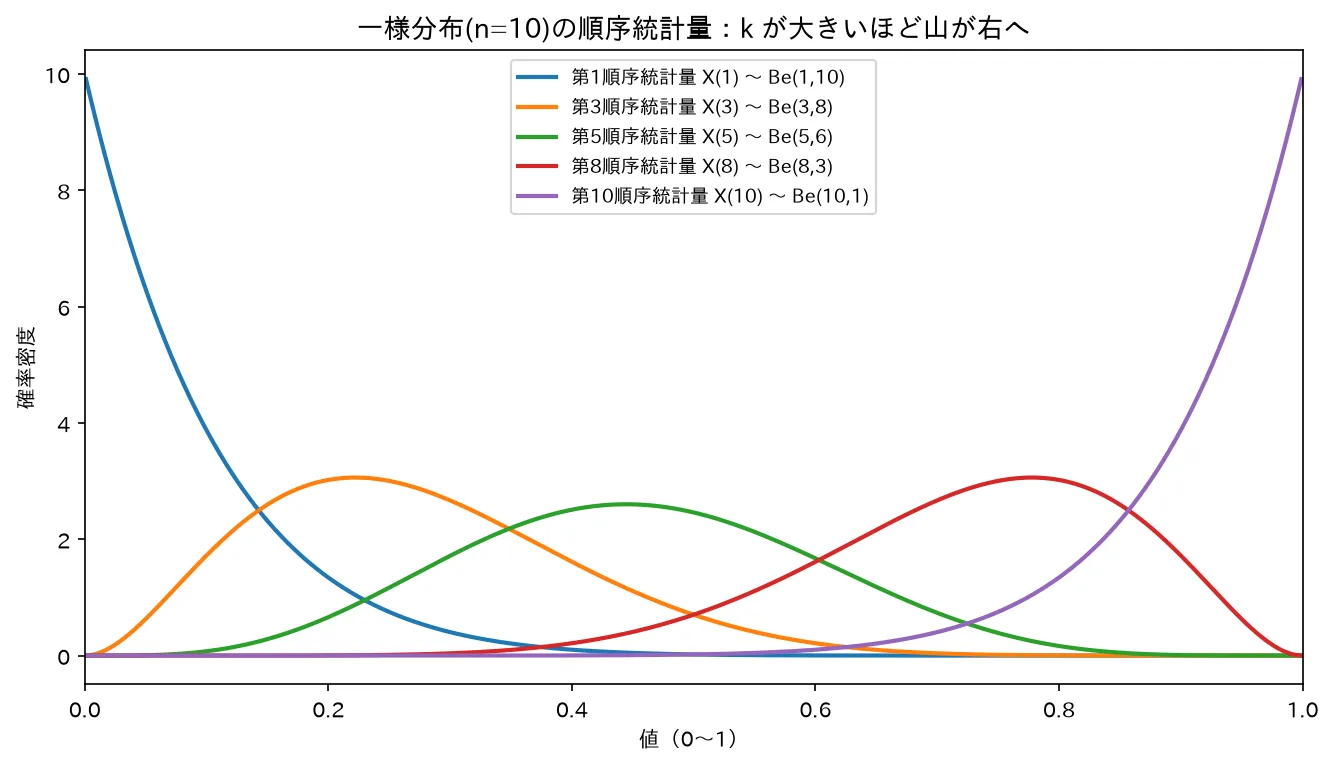
4. 一様分布の順序統計量=ベータ分布
ここが順序統計量の「正体」が見える名場面です。X i ∼ U ( 0 , 1 ) X_i\sim U(0,1) X i ∼ U ( 0 , 1 ) 一様分布(連続一様分布) )なら、0 ≤ x ≤ 1 0\le x\le 1 0 ≤ x ≤ 1 F ( x ) = x F(x)=x F ( x ) = x f ( x ) = 1 f(x)=1 f ( x ) = 1 k k k
f X ( k ) ( x ) = n ! ( k − 1 ) ! ( n − k ) ! x k − 1 ( 1 − x ) n − k ( 0 ≤ x ≤ 1 ) . f_{X_{(k)}}(x)=\frac{n!}{(k-1)!\,(n-k)!}\,x^{k-1}\,(1-x)^{n-k}\qquad(0\le x\le 1). f X ( k ) ( x ) = ( k − 1 )! ( n − k )! n ! x k − 1 ( 1 − x ) n − k ( 0 ≤ x ≤ 1 ) .
これはベータ分布 (指数分布・ガンマ分布・ベータ分布 )の密度 1 B ( α , β ) x α − 1 ( 1 − x ) β − 1 \dfrac{1}{B(\alpha,\beta)}x^{\alpha-1}(1-x)^{\beta-1} B ( α , β ) 1 x α − 1 ( 1 − x ) β − 1 α − 1 = k − 1 \alpha-1=k-1 α − 1 = k − 1 β − 1 = n − k \beta-1=n-k β − 1 = n − k α = k \alpha=k α = k β = n − k + 1 \beta=n-k+1 β = n − k + 1 n ! ( k − 1 ) ! ( n − k ) ! = 1 B ( k , n − k + 1 ) \dfrac{n!}{(k-1)!(n-k)!}=\dfrac{1}{B(k,\,n-k+1)} ( k − 1 )! ( n − k )! n ! = B ( k , n − k + 1 ) 1 B ( α , β ) = ( α − 1 ) ! ( β − 1 ) ! ( α + β − 1 ) ! B(\alpha,\beta)=\dfrac{(\alpha-1)!(\beta-1)!}{(\alpha+\beta-1)!} B ( α , β ) = ( α + β − 1 )! ( α − 1 )! ( β − 1 )!
X ( k ) ∼ B e ( k , n − k + 1 ) . \boxed{\,X_{(k)}\sim \mathrm{Be}(k,\ n-k+1)\,}. X ( k ) ∼ Be ( k , n − k + 1 ) .
ベータ分布の平均 α α + β \dfrac{\alpha}{\alpha+\beta} α + β α α β ( α + β ) 2 ( α + β + 1 ) \dfrac{\alpha\beta}{(\alpha+\beta)^2(\alpha+\beta+1)} ( α + β ) 2 ( α + β + 1 ) α β α = k , β = n − k + 1 \alpha=k,\ \beta=n-k+1 α = k , β = n − k + 1
E [ X ( k ) ] = k n + 1 , V [ X ( k ) ] = k ( n − k + 1 ) ( n + 1 ) 2 ( n + 2 ) . E[X_{(k)}]=\frac{k}{n+1},\qquad V[X_{(k)}]=\frac{k(n-k+1)}{(n+1)^2(n+2)}. E [ X ( k ) ] = n + 1 k , V [ X ( k ) ] = ( n + 1 ) 2 ( n + 2 ) k ( n − k + 1 ) .
要するに :n n n [ 0 , 1 ] [0,1] [ 0 , 1 ] n + 1 n+1 n + 1 等間隔で分け合う 。だから k k k k n + 1 \dfrac{k}{n+1} n + 1 k n = 1 n=1 n = 1 1 / 2 1/2 1/2 n = 3 n=3 n = 3 1 / 4 , 2 / 4 , 3 / 4 1/4,2/4,3/4 1/4 , 2/4 , 3/4 X X X U = F ( X ) ∼ U ( 0 , 1 ) U=F(X)\sim U(0,1) U = F ( X ) ∼ U ( 0 , 1 ) あらゆる連続分布の順序統計量の解析を一様分布に帰着できる ことの入口でもあります。
図は simulations/junjo_toukeiryo_beta_keijou.py で生成。
5. 同時分布と「独立でない」こと
5-1. 全順序統計量の同時密度
X ( 1 ) , … , X ( n ) X_{(1)},\dots,X_{(n)} X ( 1 ) , … , X ( n ) y 1 < y 2 < ⋯ < y n y_1<y_2<\dots<y_n y 1 < y 2 < ⋯ < y n
f X ( 1 ) , … , X ( n ) ( y 1 , … , y n ) = n ! ∏ i = 1 n f ( y i ) ( y 1 < ⋯ < y n ) . f_{X_{(1)},\dots,X_{(n)}}(y_1,\dots,y_n)=n!\,\prod_{i=1}^n f(y_i)\qquad(y_1<\dots<y_n). f X ( 1 ) , … , X ( n ) ( y 1 , … , y n ) = n ! ∏ i = 1 n f ( y i ) ( y 1 < ⋯ < y n ) .
要するに :もとの n n n n ! n! n ! n ! n! n ! 同時分布・周辺分布・条件付き分布 )。
5-2. なぜ独立でないのか
もとの X i X_i X i 並べ替えた瞬間に順序統計量どうしは独立でなくなります 。理由は順序制約 X ( 1 ) ≤ X ( 2 ) ≤ ⋯ ≤ X ( n ) X_{(1)}\le X_{(2)}\le\dots\le X_{(n)} X ( 1 ) ≤ X ( 2 ) ≤ ⋯ ≤ X ( n ) X ( 2 ) X_{(2)} X ( 2 ) X ( 1 ) X_{(1)} X ( 1 ) X ( 1 ) X_{(1)} X ( 1 ) ∏ i f X ( i ) ( y i ) \prod_i f_{X_{(i)}}(y_i) ∏ i f X ( i ) ( y i ) 因数分解できない (領域が y 1 < ⋯ < y n y_1<\dots<y_n y 1 < ⋯ < y n
⚠️ 「もとが独立だから順序統計量も独立」は誤り。並べ替えは独立性を壊す操作。一様分布の場合、隣接する順序統計量の差(スペーシング)X ( k ) − X ( k − 1 ) X_{(k)}-X_{(k-1)} X ( k ) − X ( k − 1 )
6. 数値例
例1:3個の一様乱数の最大値
X 1 , X 2 , X 3 ∼ U ( 0 , 1 ) X_1,X_2,X_3\sim U(0,1) X 1 , X 2 , X 3 ∼ U ( 0 , 1 ) X ( 3 ) X_{(3)} X ( 3 )
CDF:F X ( 3 ) ( x ) = x 3 F_{X_{(3)}}(x)=x^3 F X ( 3 ) ( x ) = x 3 0 ≤ x ≤ 1 0\le x\le1 0 ≤ x ≤ 1
PDF:f X ( 3 ) ( x ) = 3 x 2 f_{X_{(3)}}(x)=3x^2 f X ( 3 ) ( x ) = 3 x 2
期待値(ベータで k = 3 , n = 3 k=3,n=3 k = 3 , n = 3 E [ X ( 3 ) ] = 3 3 + 1 = 3 4 = 0.75 E[X_{(3)}]=\dfrac{3}{3+1}=\dfrac34=0.75 E [ X ( 3 ) ] = 3 + 1 3 = 4 3 = 0.75 ∫ 0 1 x ⋅ 3 x 2 d x = [ 3 4 x 4 ] 0 1 = 3 4 \displaystyle\int_0^1 x\cdot 3x^2\,dx=\Big[\tfrac34 x^4\Big]_0^1=\tfrac34 ∫ 0 1 x ⋅ 3 x 2 d x = [ 4 3 x 4 ] 0 1 = 4 3
「3個とも0.5以下」の確率=P ( X ( 3 ) ≤ 0.5 ) = 0.5 3 = 0.125 P(X_{(3)}\le0.5)=0.5^3=0.125 P ( X ( 3 ) ≤ 0.5 ) = 0. 5 3 = 0.125
例2:指数分布の最小値
X 1 , … , X n ∼ E x p ( λ ) X_1,\dots,X_n\sim \mathrm{Exp}(\lambda) X 1 , … , X n ∼ Exp ( λ ) F ( x ) = 1 − e − λ x F(x)=1-e^{-\lambda x} F ( x ) = 1 − e − λ x X ( 1 ) X_{(1)} X ( 1 )
F X ( 1 ) ( x ) = 1 − { 1 − F ( x ) } n = 1 − ( e − λ x ) n = 1 − e − n λ x . F_{X_{(1)}}(x)=1-\{1-F(x)\}^n=1-\big(e^{-\lambda x}\big)^n=1-e^{-n\lambda x}. F X ( 1 ) ( x ) = 1 − { 1 − F ( x ) } n = 1 − ( e − λ x ) n = 1 − e − nλ x .
これは指数分布 E x p ( n λ ) \mathrm{Exp}(n\lambda) Exp ( nλ ) そのもの。つまり「n n n n n n
min ( X 1 , … , X n ) ∼ E x p ( n λ ) , E [ X ( 1 ) ] = 1 n λ . \boxed{\,\min(X_1,\dots,X_n)\sim \mathrm{Exp}(n\lambda)\,},\qquad E[X_{(1)}]=\frac{1}{n\lambda}. min ( X 1 , … , X n ) ∼ Exp ( nλ ) , E [ X ( 1 ) ] = nλ 1 .
要するに :n n n λ \lambda λ n λ n\lambda nλ n n n
7. 試験での問われ方(級差)
準1級 :最小値・最大値のCDF/PDFを公式または短い導出で出せること、一様分布の順序統計量がベータになること・期待値 k / ( n + 1 ) k/(n+1) k / ( n + 1 ) 1級(数理) :第 k k k 自力で完全導出 、2つの順序統計量の同時分布・共分散 、指数や一様での具体計算、確率積分変換を絡めた応用まで。記述式で導出過程が採点対象。
級 典型的な問い 求められる深さ 準1級 min / max \min/\max min / max U ( 0 , 1 ) U(0,1) U ( 0 , 1 ) E [ X ( k ) ] E[X_{(k)}] E [ X ( k ) ] 公式適用+簡単な導出 1級 f X ( k ) f_{X_{(k)}} f X ( k ) C o v ( X ( i ) , X ( j ) ) \mathrm{Cov}(X_{(i)},X_{(j)}) Cov ( X ( i ) , X ( j ) ) 完全導出・多変数積分
年度・出題範囲表は改訂されうるため要最新確認 (特に準1級・1級の範囲表)。重要度は全体としては C(低頻度)だが、出たときは導出を問われると差がつくテーマ。
⚠️ 引っかけポイント
X ( k ) X_{(k)} X ( k ) X k X_k X k X ( k ) X_{(k)} X ( k ) k k k X k X_k X k k k k 順序統計量どうしは独立でない (もとが独立でも)。並べ替えが順序制約 X ( 1 ) ≤ ⋯ ≤ X ( n ) X_{(1)}\le\dots\le X_{(n)} X ( 1 ) ≤ ⋯ ≤ X ( n ) n ! ∏ f n!\prod f n ! ∏ f PDFの多項係数の分母を間違える 。f X ( k ) f_{X_{(k)}} f X ( k ) n ! ( k − 1 ) ! ( n − k ) ! \dfrac{n!}{(k-1)!(n-k)!} ( k − 1 )! ( n − k )! n ! ( n k ) \binom{n}{k} ( k n ) = n ! k ! ( n − k ) ! =\dfrac{n!}{k!(n-k)!} = k ! ( n − k )! n ! k − 1 k-1 k − 1 n − k n-k n − k k k k k − 1 k-1 k − 1 ベータのパラメータの取り違え 。X ( k ) ∼ B e ( k , n − k + 1 ) X_{(k)}\sim\mathrm{Be}(k,\,n-k+1) X ( k ) ∼ Be ( k , n − k + 1 ) n − k n-k n − k n − k + 1 n-k+1 n − k + 1 1 − x 1-x 1 − x n − k n-k n − k + 1 +1 + 1 k n + 1 \dfrac{k}{n+1} n + 1 k n + 1 n+1 n + 1 n n n 最小値の補集合の取り方 。最小値は「≤ x \le x ≤ x ≤ x \le x ≤ x > x >x > x > x >x > x 連続分布が前提 。同点が確率0で起きるのは連続のとき。離散分布だとタイ(同値)が正の確率で起き、X ( 1 ) < ⋯ < X ( n ) X_{(1)}<\dots<X_{(n)} X ( 1 ) < ⋯ < X ( n )
よくある疑問
Q1. 第 k k k ( n k ) \binom{n}{k} ( k n ) n ! ( k − 1 ) ! ( n − k ) ! \dfrac{n!}{(k-1)!(n-k)!} ( k − 1 )! ( n − k )! n !
A. 順序統計量は n n n 3つのグループ に分ける問題だからです。二項係数は「2グループに分ける(x x x k k k x x x k − 1 k-1 k − 1 x x x x x x n − k n-k n − k 3グループ に分けるので、多項係数 n ! ( k − 1 ) ! 1 ! ( n − k ) ! = n ! ( k − 1 ) ! ( n − k ) ! \dfrac{n!}{(k-1)!\,1!\,(n-k)!}=\dfrac{n!}{(k-1)!(n-k)!} ( k − 1 )! 1 ! ( n − k )! n ! = ( k − 1 )! ( n − k )! n ! x x x f ( x ) f(x) f ( x ) x x x k k k
Q2. 一様分布だとベータになるのはわかりました。一様でない一般の分布の順序統計量はどう扱うんですか?
A. 確率積分変換 を使います。任意の連続分布 X ∼ F X\sim F X ∼ F U = F ( X ) U=F(X) U = F ( X ) U ( 0 , 1 ) U(0,1) U ( 0 , 1 ) F ( X ( k ) ) = U ( k ) ∼ B e ( k , n − k + 1 ) F(X_{(k)})=U_{(k)}\sim\mathrm{Be}(k,n-k+1) F ( X ( k ) ) = U ( k ) ∼ Be ( k , n − k + 1 ) F − 1 F^{-1} F − 1 X ( k ) = F − 1 ( U ( k ) ) X_{(k)}=F^{-1}(U_{(k)}) X ( k ) = F − 1 ( U ( k ) )
Q3. なぜ順序統計量は独立でないんですか?もとのデータは独立なのに。
A. 「並べ替える」という操作自体が独立性を壊すからです。並べ替えた後は定義上 X ( 1 ) ≤ X ( 2 ) ≤ … X_{(1)}\le X_{(2)}\le\dots X ( 1 ) ≤ X ( 2 ) ≤ … 順序の鎖 が必ず成り立ちます。すると X ( 2 ) = v X_{(2)}=v X ( 2 ) = v X ( 1 ) ≤ v X_{(1)}\le v X ( 1 ) ≤ v X ( 1 ) X_{(1)} X ( 1 ) X ( 2 ) X_{(2)} X ( 2 ) X ( 1 ) X_{(1)} X ( 1 ) n ! ∏ i f ( y i ) n!\prod_i f(y_i) n ! ∏ i f ( y i ) y 1 < ⋯ < y n y_1<\dots<y_n y 1 < ⋯ < y n 三角形の領域 でしか正でなく、各変数の周辺密度の積(長方形領域なら独立)に分解できないことが証拠になります。
Q4. 範囲(レンジ)R = X ( n ) − X ( 1 ) R=X_{(n)}-X_{(1)} R = X ( n ) − X ( 1 )
A. 最大値と最小値の同時分布 から差の分布へ変数変換します。X ( 1 ) = u X_{(1)}=u X ( 1 ) = u X ( n ) = v X_{(n)}=v X ( n ) = v u ≤ v u\le v u ≤ v u u u v v v n − 2 n-2 n − 2 ( u , v ) (u,v) ( u , v ) f X ( 1 ) , X ( n ) ( u , v ) = n ( n − 1 ) f ( u ) f ( v ) { F ( v ) − F ( u ) } n − 2 f_{X_{(1)},X_{(n)}}(u,v)=n(n-1)f(u)f(v)\{F(v)-F(u)\}^{n-2} f X ( 1 ) , X ( n ) ( u , v ) = n ( n − 1 ) f ( u ) f ( v ) { F ( v ) − F ( u ) } n − 2 u < v u<v u < v R = v − u R=v-u R = v − u U ( 0 , 1 ) U(0,1) U ( 0 , 1 ) R ∼ B e ( n − 1 , 2 ) R\sim\mathrm{Be}(n-1,2) R ∼ Be ( n − 1 , 2 ) E [ R ] = n − 1 n + 1 E[R]=\dfrac{n-1}{n+1} E [ R ] = n + 1 n − 1
Q5. 中央値(メディアン)も順序統計量ですよね。標本中央値の分布は?
A. はい。n n n X ( ( n + 1 ) / 2 ) X_{((n+1)/2)} X (( n + 1 ) /2 ) k k k k = ( n + 1 ) / 2 k=(n+1)/2 k = ( n + 1 ) /2 B e ( n + 1 2 , n + 1 2 ) \mathrm{Be}\big(\tfrac{n+1}{2},\tfrac{n+1}{2}\big) Be ( 2 n + 1 , 2 n + 1 ) 1 / 2 1/2 1/2 n n n X ( n / 2 ) , X ( n / 2 + 1 ) X_{(n/2)},X_{(n/2+1)} X ( n /2 ) , X ( n /2 + 1 )
まとめ
順序統計量 X ( 1 ) ≤ ⋯ ≤ X ( n ) X_{(1)}\le\dots\le X_{(n)} X ( 1 ) ≤ ⋯ ≤ X ( n ) ( k ) (k) ( k ) X k X_k X k
すべての導出の核は「x x x ∼ B i n ( n , F ( x ) ) \sim\mathrm{Bin}(n,F(x)) ∼ Bin ( n , F ( x )) 。ここから最大 F n F^n F n 1 − ( 1 − F ) n 1-(1-F)^n 1 − ( 1 − F ) n k k k 第 k k k n ! ( k − 1 ) ! ( n − k ) ! f ( x ) F ( x ) k − 1 { 1 − F ( x ) } n − k \dfrac{n!}{(k-1)!(n-k)!}f(x)F(x)^{k-1}\{1-F(x)\}^{n-k} ( k − 1 )! ( n − k )! n ! f ( x ) F ( x ) k − 1 { 1 − F ( x ) } n − k 多項係数 (3グループ分け:左 k − 1 k-1 k − 1 n − k n-k n − k
一様 U ( 0 , 1 ) U(0,1) U ( 0 , 1 ) X ( k ) ∼ B e ( k , n − k + 1 ) X_{(k)}\sim\mathrm{Be}(k,n-k+1) X ( k ) ∼ Be ( k , n − k + 1 ) E [ X ( k ) ] = k n + 1 E[X_{(k)}]=\dfrac{k}{n+1} E [ X ( k ) ] = n + 1 k E x p ( n λ ) \mathrm{Exp}(n\lambda) Exp ( nλ )
全順序統計量の同時密度は三角領域上で n ! ∏ f n!\prod f n ! ∏ f 順序統計量どうしは独立でない (並べ替えが順序制約を生む)。
級差:準1級は min / max \min/\max min / max k k k
関連ノート