📊 対象級:準1級 ・ 1級 | 重要度:B(標準)
要点(BLUF)
中央値・相関係数・複雑な統計量の標準誤差や信頼区間は、数式で求めようとすると標本分布がわからず手詰まりになります。ブートストラップとジャックナイフは、これを「手元の標本を母集団とみなして再標本を作り、統計量がどれだけばらつくかを計算機で実測する」ことで近似する手法です。
要するに「標本分布を数式で出せないなら、リサンプリングで実験的に作ってしまえ」ということです。土台は「標本が母集団の最良の推定」というプラグイン原理。準1級ではブートSE・ブート信頼区間・ジャックナイフのバイアス/分散の計算が、1級ではなぜそれで近似できるのか( の一致性)とBCa・理論的正当化が問われます。
1. 問題意識:標本分布が手に入らないとき
推定量 (標本から計算する量)の良し悪しを語るには、その標本分布——標本を取り直すたびに がどうばらつくか——が必要です。具体的には次の3つを知りたい。
- 標準誤差 :推定値のばらつきの大きさ(点推定(推定量の良さ:不偏性・一致性・有効性・十分性))
- バイアス :系統的なズレ
- 信頼区間: がありそうな範囲(区間推定(母平均・母比率・母分散の信頼区間))
標本平均 なら話は簡単で、 と解析的に出ますし、中心極限定理で分布も正規に近づきます(標本平均・標本比率の標本分布(標準誤差))。ところが——
- 中央値の標準誤差は? 公式は密度 を含み()、未知の密度値が要る。
- 相関係数 の分布は? 正規母集団でも複雑で、Fisher の 変換という小細工が要る。
- 2つの中央値の比や変動係数、最大固有値など、教科書に公式が載っていない統計量は無数にある。
要するに「 が複雑だと標本分布の数式が破綻する」。ここでリサンプリングの出番です。
graph LR
A["知りたい:θ̂ の<br/>SE・バイアス・信頼区間"] --> B{"標本分布は<br/>解析的に出る?"}
B -- "出る(平均など)" --> C["公式で計算<br/>se=σ/√n 等"]
B -- "出ない(中央値・相関係数)" --> D["リサンプリングで<br/>計算機近似"]
D --> E["ブートストラップ<br/>(復元抽出)"]
D --> F["ジャックナイフ<br/>(1個抜き)"]
2. プラグイン原理と経験分布関数(すべての土台)
リサンプリングが成り立つ理屈の核心はプラグイン原理です。1級の正当化はここに帰着します。
母集団は分布 で表されます。知りたい量はたいてい「分布 の関数」として書けます。例えば平均は 、中央値は 、分散は 。このように と書ける量を汎関数と呼びます。
しかし は未知です。手元にあるのは標本 だけ。そこで の代わりに、標本そのものを分布とみなした経験分布関数(empirical distribution function) を使います。
要するに「 は、 個の各データ点に等しい重み を置いた離散分布」です。 以下のデータが何割あるかを数えているだけ。
プラグイン推定量は、未知の をこの で置き換えたものです。
要するに「真の分布 がわからないなら、観測された分布 を代わりに差し込む(plug-in)」。平均なら と、ちゃんと標本平均が出てきます。
なぜ で代用してよいのか(一致性の根拠)
これが効く根拠は2つあります。
- 各点での大数の法則:固定した で は割合(指示関数の平均)なので、大数の法則(大数の法則(弱法則・強法則))より 。標本が増えれば経験分布は真の分布に各点で収束する。
- 一様収束(グリベンコ–カンテリの定理):実はもっと強く、。つまり は に一様に近づく。
要するに「 が大きければ は の極めて良い近似」。だから「 のもとでの の分布」を知りたいとき、「 のもとでの再標本の統計量の分布」で代用できる——これがブートストラップの理論的正当化です。 のもとで標本を取り直すことが、まさに復元抽出にあたります(各点が確率 で等しく選ばれるから)。
ここが1級の核心:ブートストラップとは「未知の のもとでの標本分布」を、「既知の のもとでの標本分布」で近似する操作。(グリベンコ–カンテリ)と、汎関数 の連続性(滑らかさ)があれば、ブートストラップ分布は真の標本分布に収束する。逆に が滑らかでない・ が裾を捉えられない場面で破綻します(第7節)。
3. ブートストラップ
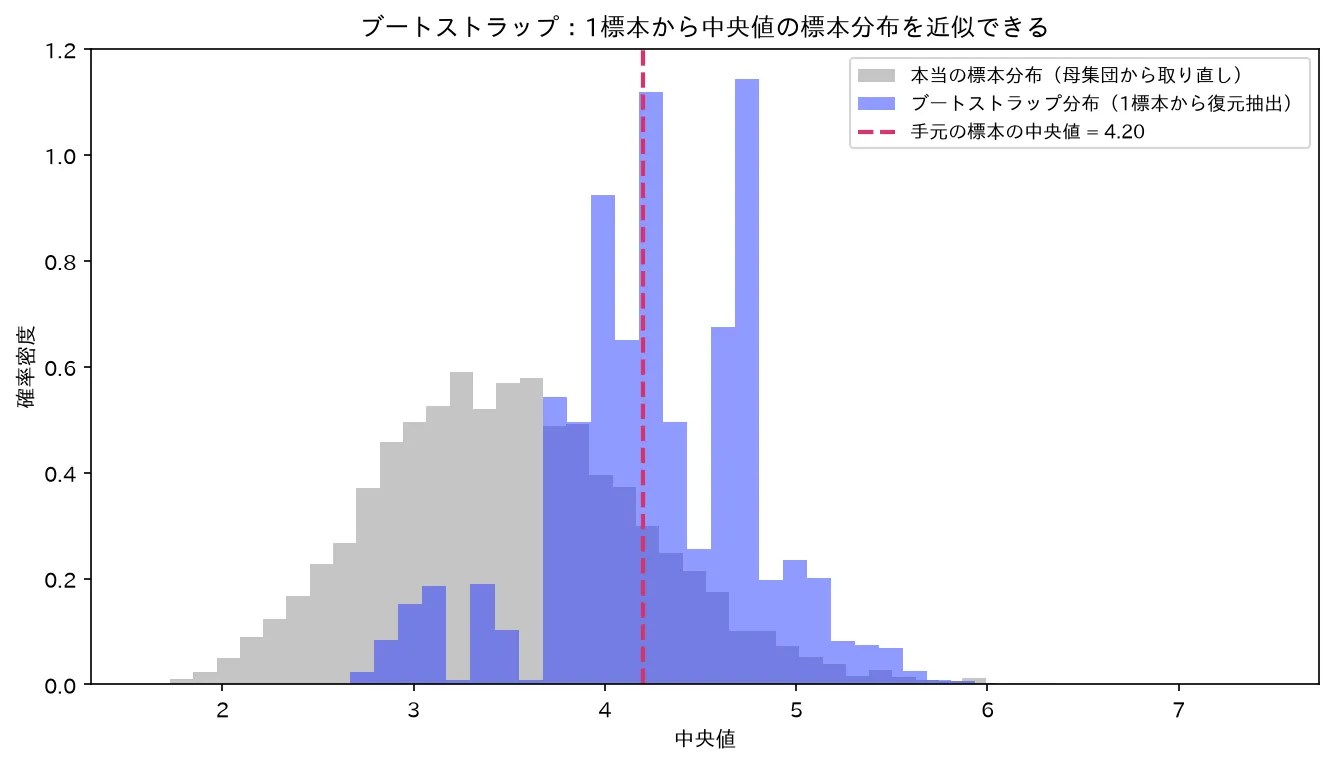
1標本から復元抽出した中央値の分布(青)が、母集団から取り直した本当の標本分布(灰)にほぼ一致。解析的に難しい統計量の標本分布を近似できる。図は simulations/bootstrap_bunpu_keijou.py で生成。
3.1 アルゴリズム
flowchart TD
A["元の標本<br/>X₁,…,Xₙ"] --> B["復元抽出でサイズ n の<br/>再標本(ブートストラップ標本)を作る"]
B --> C["各再標本で統計量 θ̂*ᵇ を計算"]
C --> D{"B 回<br/>繰り返した?"}
D -- "まだ" --> B
D -- "完了" --> E["θ̂*¹,…,θ̂*ᴮ の分布<br/>=標本分布の近似"]
E --> F["この分布の<br/>標準偏差 → ブートSE<br/>分位点 → 信頼区間<br/>平均−θ̂ → バイアス"]
手順を言葉で書くと:
- 元の標本 から、復元抽出(同じ点を何度選んでもよい)でサイズ (元と同じ大きさ)の再標本 を作る。これをブートストラップ標本と呼ぶ。
- その再標本で統計量を計算する:。これを**ブートストラップ複製(replicate)**と呼ぶ。
- 1–2 を 回(通常 )繰り返し、 を得る。
- この 個の散らばりが、 の標本分布の近似になっている。
⚠️ 再標本は必ず「復元抽出」で「元と同じサイズ 」。ここが頻出の引っかけ。非復元で同サイズに取ると元の標本そのものに戻ってしまう(順番が違うだけ)ので意味がない。復元だからこそ、ある点が2回入ったり0回だったりして、 からの新しい標本になる。
3.2 ブートストラップ標準誤差(導出)
の標準誤差は「標本分布の標準偏差」でした。標本分布をブートストラップ複製の集まりで近似したのだから、その標本標準偏差がブートストラップ標準誤差です。
まず複製の平均を
と置きます( 個の複製の平均値)。ブートストラップ標準誤差は
要するに「 個の複製がどれだけばらついているかの標準偏差が、そのまま の標準誤差の推定値」。分母が なのは標本分散と同じ不偏化の慣例です( が大きいので でも でも実質変わりません)。
この式が成り立つ理屈:理想的には「 から標本を取り直すたびの の標準偏差」が真の 。 を で置き換えると「 から取り直すたびの の標準偏差」になり、それを 個の複製でモンテカルロ近似したのが上式です。二段階の近似( と、無限回の再標本→有限 回)が入っている点が大事で、 を増やすと2段目の誤差は消えますが、1段目()の誤差は を増やさない限り消えません。
3.3 バイアスのブートストラップ推定
バイアスは 。プラグインで と置き換えると、 は に、 は再標本での期待値 になります。これを複製平均で近似して
要するに「ブートストラップ複製の平均が、元の推定値からどれだけずれているかがバイアスの推定**」。複製の中心 が元の より系統的に大きい/小さいなら、 にも同じ方向のバイアスがあると見なす。バイアス補正した推定量は になります。
3.4 ブートストラップ信頼区間
代表的な3つ。準1級ではパーセンタイル法を計算できれば十分、基本法との違いとBCaの考え方を知っていればなお良い。
(1) パーセンタイル法(percentile)——いちばん素直。ブートストラップ複製の分布から、下側 分位点と上側 分位点をそのまま端点にする。
要するに「複製を小さい順に並べ、下から2.5%・上から2.5%を切り落とした残りの範囲」(95%区間なら)。 なら 50 番目と 1950 番目の複製値が端点。
(2) 基本法(basic / pivotal)——「複製のばらつきの形」を元の推定値の周りに折り返す。ピボット の分布を で近似する発想で、
要するに「パーセンタイル法を を中心に左右反転させたもの」。分布が歪んでいるとパーセンタイル法と食い違い、どちらが妥当かは状況による。
(3) BCa(bias-corrected and accelerated, バイアス補正・加速)——パーセンタイル法を2つの量で補正する。1級で名前と趣旨が問われる。
- バイアス補正 :複製の中央が とずれていることを補正。(複製のうち 未満の割合を正規分位点に変換)。
- 加速 :標準誤差が の値によって変わる(分布の歪み)ことを補正。ジャックナイフの3次モーメントから計算する。
要するに「BCa はパーセンタイル法に『中心ズレ』と『歪み』の2補正を入れたもの」。素のパーセンタイル法より精度が高く(2次の精度 )、歪んだ分布で信頼できる。
4. ジャックナイフ
ジャックナイフはブートストラップより古く・単純で・決定的(乱数を使わない)な手法です。再標本のしかたは「1個ずつ抜く(leave-one-out)」だけ。
4.1 定義
番目のデータを除いた 個で計算した統計量を と書きます(ジャックナイフ複製)。これが で 個できます。その平均を
と置きます( 個のジャックナイフ複製の平均)。要するに「1個抜きを全データで試した 通りの推定値と、その平均」。乱数も繰り返し回数 も要らず、再標本は 通りに固定されます。
4.2 ジャックナイフのバイアス推定(完全導出)
公式は
なぜ係数が なのか。これは「バイアスが標本サイズに反比例して減る」という典型的な構造から出ます。順を追います。
ステップ1:バイアスの形を仮定する。 多くの推定量で、サイズ の標本に基づくバイアスは の冪で展開できます。
ここで は に依らない定数。要するに「バイアスは主に という、標本が増えれば消える項でできている」(1次のバイアス)。
ステップ2:2つのサイズを比べる。 元の推定量はサイズ なので
一方、ジャックナイフ複製 はサイズ の標本に基づくので、その期待値は
( は同サイズ の複製の平均なので、期待値は1個分と同じ。)要するに「1個抜くとサイズが になり、バイアスが少しだけ大きくなる」。
ステップ3:差を取る。 2式を引きます(1次項まで)。
要するに「サイズの違いから生じる差は 」。ここに が分離して出てくるのがポイント。
ステップ4: を掛けて1次バイアスを復元する。 元の推定量の1次バイアスは でした。上の差に を掛けると
要するに「 という係数は、サイズ差で薄まったバイアスを元の濃さに戻す増幅率」。最後に期待値を標本での実現値 で置き換えれば、推定量
が得られます。これを引いてバイアス補正したジャックナイフ推定量は
となり、 の項が消えてバイアスが に改善します。これがジャックナイフの本来の目的(バイアス削減)です。
4.3 擬似値とジャックナイフ分散推定
各データ点について**擬似値(pseudo-value)**を
と定義します。要するに「 番目の点を抜いたときの変化を 倍に増幅し、全体推定値 から測った『 番目の点の寄与』」。擬似値の平均はちょうどジャックナイフ推定量 になります。
平均が なら、その標準誤差は擬似値を 個の独立な観測のように扱って求めます。これがジャックナイフ分散推定です。
2つ目の等号は、擬似値の偏差 を代入し、 を整理すると出ます()。要するに「ジャックナイフ複製のばらつきに を掛けたものが分散の推定」。係数が (1より少し小さい)ではなく** 倍に近い大きな膨張**になっている点に注意——複製同士は 個もデータを共有していて差が小さいので、その小さな差を大きく増幅して真のばらつきに合わせています。
5. ブートストラップとジャックナイフの関係
決定的に重要な事実:**ジャックナイフはブートストラップの線形近似(一次近似)**です。
直観:統計量 を、各データ点の重みを少し動かしたときの変化で1次近似(テイラー展開)すると、その傾き(影響関数, influence function)が現れます。
- ジャックナイフは「1点を完全に抜く(重みを から へ)」という有限差分で、この影響関数を近似している。つまり を線形(1次)で近似して分散を組み立てる。
- ブートストラップは重みをランダムに大きく揺らすので、 の非線形な曲がりまで拾う。
要するに「ジャックナイフ=ブートストラップを1次(線形)で打ち切ったもの」。だから が線形に近い(平均など)なら両者はほぼ一致し、 が強く非線形・非平滑だとジャックナイフだけがずれる。
なぜ中央値でジャックナイフが破綻するか(頻出論点)
中央値は非平滑な統計量です。 が奇数なら中央値は真ん中の1個の値そのもの。ここで1点を抜くと——
- 抜いたのが中央値より大きい側か小さい側かで、新しい中央値は真ん中2個の値のどちらかへピョンと跳ぶ。
- 1個抜いた程度では中央値はほとんど変わらない(隣の値に移るだけ)。
つまりジャックナイフ複製 は数種類の値しか取らず、 が真のばらつきを大きく過小評価します。線形近似(影響関数)が中央値では存在しない(微分不可能)ことの現れです。
要するに「中央値・分位点のような非平滑統計量ではジャックナイフは一致性を失う」。一方ブートストラップは復元抽出で中央値を大きく揺らせるので、中央値の標準誤差はブートストラップで推定するのが定石。
graph TD B["ブートストラップ<br/>(重みを大きく揺らす)"] -->|"線形(1次)に<br/>打ち切ると"| J["ジャックナイフ<br/>(1点抜き=有限差分)"] B --- B2["非線形・非平滑でも<br/>有効(中央値OK)"] J --- J2["線形・平滑なら一致<br/>非平滑(中央値)で破綻"]
6. 比較表
| 観点 | ブートストラップ | ジャックナイフ |
|---|---|---|
| 再標本のしかた | 復元抽出でサイズ | 1個抜き(leave-one-out) |
| 再標本の個数 | 回(任意、乱数で生成。) | 通り(固定・決定的) |
| 乱数 | 使う(モンテカルロ近似) | 使わない(再現性100%) |
| 主な用途 | SE・バイアス・信頼区間(分布全体) | SE・バイアス(主にこの2つ) |
| 非線形・非平滑統計量 | 有効(中央値の SE もOK) | 線形近似なので非平滑で破綻(中央値NG) |
| 計算量 | 大( 回 統計量計算) | 小( 回。 が大きいと逆に重いことも) |
| 位置づけ | 一般的・主流 | ブートの線形近似(古典的・前身) |
要するに「ジャックナイフは軽くて決定的だが線形近似ゆえ非平滑統計量で破綻。ブートストラップは重いが汎用で信頼区間まで出せる」。歴史的にはジャックナイフが先(Quenouille・Tukey)で、Efron がそれを一般化したのがブートストラップ(論文題が “Another Look at the Jackknife”)。
7. ブートストラップが失敗する場面(万能ではない)
ブートストラップは強力ですが万能ではありません。1級では「いつ破綻するか」が問われます。プラグイン原理(第2節)が崩れる場面、すなわち が をうまく代理できない/汎関数 が滑らかでない場面で失敗します。
- 最大値・最小値などの極値統計量:標本最大 の分布。ブートストラップ標本の最大は元標本の最大 を超えられない(復元抽出は新しい大きな値を生めない)。再標本の最大は「元の最大が少なくとも1回選ばれるか」で決まる離散的な挙動になり、真の標本分布を再現できず一致性を失う。
- 重い裾(heavy tail)の分布:分散が存在しない(コーシー型など)/裾が極端に重い母集団では、標本平均ですらブートストラップが標本分布を一致推定できないことが知られる。 が稀な大きい値(裾)を取りこぼすため。
- 従属データ(時系列・空間データ):通常のブートストラップは「各観測が独立」を前提に1点ずつ復元抽出するので、時系列の自己相関を壊してしまう。SE を過小評価する。対策は連続するブロックごと抜き取るブロックブートストラップ。
- パラメータが境界にあるとき:真値が母数空間の端(例:分散が0、混合比が0や1)にある問題。
要するに「極値・重い裾・従属・境界では素のブートストラップは破綻する」。逆に言えば、滑らかな統計量+独立+裾が軽い、という標準的な状況でこそ威力を発揮します。
試験での問われ方(級ごとの差)
ブートストラップ・ジャックナイフは準1級・1級の範囲ですが、毎回出るわけではありません(出題範囲・配点は改訂されうるため要最新確認)。級で深さがはっきり違います。
準1級レベル
ここで問われるのは「計算と概念」。アルゴリズムを説明でき、ブートSE・ブート信頼区間(パーセンタイル法)・ジャックナイフのバイアス/分散を数値で計算できるか。
- ブートストラップの手順(復元抽出・サイズ ・ 回)を正しく述べる。**「復元抽出」「元と同じサイズ 」**が頻出の穴埋め・正誤。
- 与えられた複製値 からブート やパーセンタイル信頼区間を計算する。
- ジャックナイフのバイアス 、分散 を数値で求める。
- 「ジャックナイフは中央値で破綻」「ブートは万能でない」という定性的注意。
- ノンパラメトリックな手法という位置づけ(ノンパラメトリック検定(符号・順位和・Wilcoxon) と同じく分布を仮定しない発想)。
1級レベル
ここで問われるのは「理論的正当化と精緻化」。なぜ近似が成り立つか()を論じ、ジャックナイフ=ブートの線形近似であること、BCa の趣旨、破綻条件を説明・導出できるか。
- プラグイン原理と一致性:(グリベンコ–カンテリ)と の連続性からブートストラップ分布が真の標本分布に収束する論理。
- ジャックナイフのバイアス補正の導出(第4.2節の 係数の出どころ)。擬似値と影響関数の関係。
- ジャックナイフ=ブートストラップの線形近似であることと、中央値(非平滑統計量)で一致性が崩れる理由。
- BCa(バイアス補正 ・加速 )の役割と、パーセンタイル法より高精度(2次の精度)になる理由の概念。
- ブートストラップの破綻条件(極値・重い裾・従属データ)とその理由、対策(ブロックブートストラップ等)。
土台は、バイアス/分散の概念が 点推定(推定量の良さ:不偏性・一致性・有効性・十分性)、信頼区間が 区間推定(母平均・母比率・母分散の信頼区間)、近似する標本分布そのものが 標本平均・標本比率の標本分布(標準誤差)、一致性の根拠が 大数の法則(弱法則・強法則) です。
⚠️ 引っかけ・頻出論点
- ⚠️ 再標本は「復元抽出」かつ「元と同じサイズ 」。非復元で同サイズに取ると元標本に戻るだけで無意味。最頻出の正誤ポイント。
- ⚠️ を増やしても 不足は救えない。(再標本の回数)はモンテカルロ誤差を減らすだけ。 の誤差(標本サイズ 由来)は をいくら増やしても消えない。「 を大きくすれば精度が上がる」は半分だけ正しい。
- ⚠️ ジャックナイフは中央値・分位点(非平滑統計量)で破綻する。線形近似ゆえ。中央値の SE はブートストラップで。「ジャックナイフは何にでも使える」は誤り。
- ⚠️ ブートストラップも万能でない。最大値・最小値(極値)、重い裾、従属データ(時系列)で一致性を失う。「分布を仮定しないから常に正しい」は誤り。
- ⚠️ ジャックナイフのバイアス補正は1次()まで。 以降の高次バイアスは残る。完全にバイアスを消すわけではない。
- ⚠️ パーセンタイル法と基本(pivotal)法は別物。基本法は を中心に左右反転させた区間で、歪んだ分布だとパーセンタイル法と食い違う。混同しない。
よくある疑問(Q&A)
Q1. 復元抽出で同じ点が何度も選ばれたら、それは「水増し」で不正ではないのですか?
不正ではありません。むしろ復元抽出の本質です。ブートストラップは「経験分布 (各点に重み を置いた分布)から新しく標本を取る」操作で、 から1個引くとは「 個のどれかが等確率 で出る」こと。だから同じ点が2回出たり0回だったりするのが正しい振る舞いです。これにより各再標本が少しずつ違う構成になり、統計量がばらつく=標本分布を再現できる。もし非復元なら毎回同じ 個(順番違い)になってばらつきが出ず、何も推定できません。
Q2. (再標本の回数)はいくつにすればいいですか? 多いほど良いですか?
用途で変わります。標準誤差・バイアスの推定なら で十分、信頼区間(特に裾の分位点を使う)なら が目安。多いほどモンテカルロ誤差(有限回しか再標本していないことによる誤差)は減りますが、 を無限にしても精度には天井があります。なぜなら本質的な誤差は「 が真の と違う」こと(標本サイズ 由来)で、これは では一切改善しないから。 は「計算の精度」、 は「推定の精度」と切り分けて理解してください。
Q3. ジャックナイフが中央値で使えないのに、なぜ教科書に載っているのですか?
(1) 歴史的に先だから。ジャックナイフ(1950–60年代)はブートストラップ(1979年)より20年早く、バイアス削減の古典的手法として確立していました。(2) 平滑な統計量では今でも有効で、乱数を使わず決定的・軽量という利点があります(平均・分散・回帰係数など)。(3) ブートストラップの線形近似という理論的な位置づけが重要で、両者の関係を理解すると「リサンプリングが何をしているか」(影響関数の推定)が見通せます。試験では「中央値で破綻する」ことと「ブートの線形近似である」ことがセットで問われます。
Q4. ブートストラップ信頼区間が複数あって混乱します。結局どれを使えばいいですか?
精度と手間のトレードオフです。パーセンタイル法は最も単純(複製を並べて分位点を取るだけ)で準1級の中心。ただし分布が歪んでいると被覆確率がずれます。基本(pivotal)法はピボットの発想で、これも単純。最も精度が高いのはBCaで、バイアスと歪みの2補正を入れた2次精度の区間ですが計算が複雑(加速 をジャックナイフで出す)。実務では BCa が推奨されることが多いですが、試験(準1級)ではパーセンタイル法が計算できれば十分で、BCa は「より高精度な改良版」として趣旨を知っていれば良いです。
Q5. ブートストラップは「分布を仮定しない」と聞きましたが、本当に何の仮定もないのですか?
「特定の分布形(正規など)を仮定しない」という意味では正しいですが、仮定がゼロではありません。隠れた前提は (1) 観測が独立同分布(だから1点ずつ復元抽出してよい——時系列の従属データでは崩れる)、(2) が の良い近似(裾の薄い・サンプルの足りる状況——重い裾や極値では崩れる)、(3) 統計量 が滑らか(中央値のような非平滑だと注意が要る)です。つまり「分布形フリー」ではあるが「無条件」ではない。第7節の破綻条件は、これらの隠れた前提が破れる場面そのものです。
まとめ
- 中央値・相関係数など標本分布が解析的に出ない統計量の SE・バイアス・信頼区間を、リサンプリングで計算機近似する。土台はプラグイン原理:未知の を経験分布 で代用する( がグリベンコ–カンテリと大数の法則で保証)。
- ブートストラップ:標本から復元抽出でサイズ の再標本を 回作り、各々で統計量を計算。複製の標準偏差 がSE、複製平均− がバイアス、複製の分位点が信頼区間(パーセンタイル法)。BCa は2補正の高精度版。
- ジャックナイフ:1個抜きの 通りの複製。バイアス ( はサイズ差で薄まったバイアスを戻す増幅率)、分散 、擬似値 。
- 両者の関係:ジャックナイフ=ブートストラップの線形(一次)近似。だから中央値など非平滑統計量でジャックナイフは破綻(影響関数が存在しない)。
- ブートも万能でない:極値(最大・最小)・重い裾・従属データ(時系列)で一致性を失う。
- 級差:準1級=アルゴリズムとブートSE/CI・ジャックナイフのバイアス/分散の計算、1級=一致性の正当化()・線形近似・BCa・破綻条件。
関連ノート
- 点推定(推定量の良さ:不偏性・一致性・有効性・十分性) 推定量のバイアス・標準誤差(MSE)の定義。リサンプリングはこれらを計算機で近似する手法
- 区間推定(母平均・母比率・母分散の信頼区間) 頻度論の信頼区間。ブート信頼区間(パーセンタイル法・BCa)はこの代替・近似
- 標本平均・標本比率の標本分布(標準誤差) リサンプリングが近似しようとしている「標本分布」そのもの
- 大数の法則(弱法則・強法則) (一致性)の根拠。ブートストラップが成り立つ理屈の土台
- 欠測データ・EMアルゴリズム 同じ「計算機で統計を解く」計算統計の仲間
- ノンパラメトリック検定(符号・順位和・Wilcoxon) 分布を仮定しない発想という点でリサンプリングと同系統
- 確率過程・時系列・応用(Phase 8 目次) 確率過程・時系列・応用ドメインの全体地図