📊 対象級:1級 | 重要度:A(頻出)
計量時系列の発展(単位根・共和分・ARCH/GARCH)
要点(BLUF)
- 単位根過程 I(1) は のランダムウォークに代表される非定常過程で、1階差分すると定常 I(0) になる。これを安易に回帰すると見せかけの回帰(無関係なのに が高く 値が発散して有意に見える)が起きる。
- 共和分は「個々は I(1) なのに、ある線形結合だけが定常 I(0) になる」状態で、変数間の長期均衡関係を意味する。短期の調整と長期均衡を結ぶのが誤差修正モデル(ECM)。
- ARCH/GARCH は条件付き分散が過去のショックに依存するモデルで、金融データのボラティリティ・クラスタリング(大きい変動が大きい変動を呼ぶ)を捉える。
この4本(単位根・見せかけの回帰・共和分・ARCH/GARCH)は1級統計応用・社会科学分野で頻出する計量経済学固有の発展トピックです。定常 ARIMA の基礎は 時系列解析(定常性・ACF/PACF・AR・MA・ARMA・ARIMA) で扱ったので、本ノートは経済・金融時系列に固有の論点を差分として深掘りします。
1. 単位根過程:非定常の典型
1-1. 定義と AR(1) からの導入
最も簡単な自己回帰モデル AR(1) を出発点にします。
ここで係数 の大きさで過程の性質が決定的に変わります。
- :定常。ショック の影響は時間とともに で減衰し、平均へ回帰する。
- :単位根過程。これが本節の主役で、次のランダムウォークになる。
要するに何か: は「今日の値=昨日の値+新しいショック」。過去のショックが永遠に消えずに積み上がるため、過程は決まった水準に戻らず、ふらふらとさまよう。
1-2. なぜ「単位根」と呼ぶか
AR(1) をラグ演算子 ()で書くと
特性方程式 の根は です。 のとき根は 、すなわち**単位円上の根(unit root)**を持ちます。これが「単位根」の名の由来です。
要するに何か:定常の条件は「特性方程式の根がすべて単位円の外」。根がちょうど 1 になった境界ケースが単位根で、定常と非定常の分かれ目に立っている。
1-3. 和分 I(d) と差分による定常化
単位根過程は1階差分すると定常になります。
ここから和分次数(order of integration) を定義します。
- :そのまま定常。
- :1階差分して初めて定常になる(=単位根を1個持つ)。ランダムウォークはこれ。
- : 階差分して定常になる。
要するに何か: は「微分(差分)を1回かけると暴れがおさまる」レベルの非定常。経済データ(株価・GDP・為替・物価)は であることが非常に多い。
1-4. ランダムウォークはブラウン運動の離散版
ランダムウォーク は、時間刻みを細かくして連続極限をとるとブラウン運動(Wiener過程)に収束します。分散が
と時間 に比例して増大する点が、定常過程との決定的な違いです。
要するに何か:時間が経つほど散らばりが広がる。分散が一定でない時点で「定常」の定義から外れている。連続版がブラウン運動で、単位根分布の理論はブラウン運動の汎関数として導かれる(後述の DF 分布が正規分布にならない理由)。
1-5. ドリフトつき・トレンドつき
実データに合わせて定数項やトレンド項を加えた形も重要です。
ドリフト があると、確率的にさまよいながら平均的に傾き の直線に沿って動く(確率的トレンド+確定的トレンド)。単位根検定ではこの定数項・トレンド項を回帰式に含めるか否かが検定統計量の分布を変えるため、後述のように検定の型が複数あります。
2. 見せかけの回帰(spurious regression)
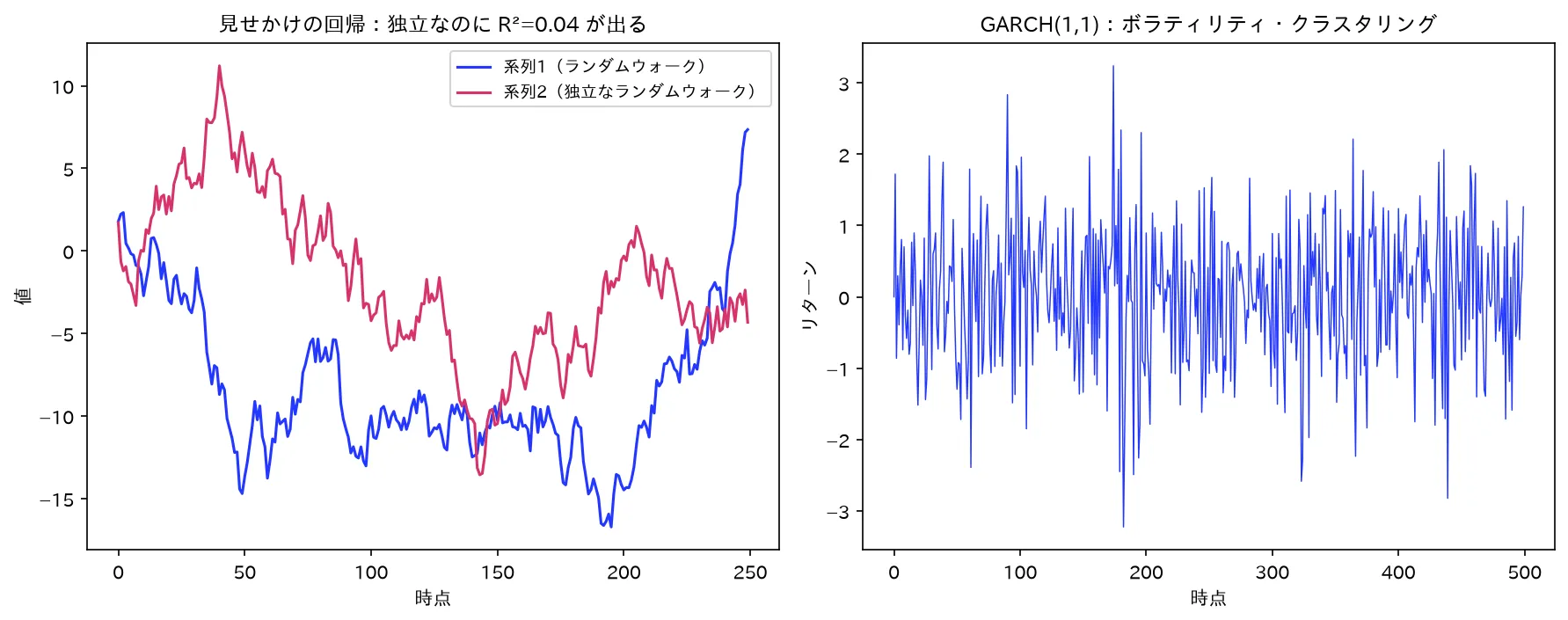
図は simulations/keiryo_misekake_garch.py で生成。
2-1. 現象
独立に生成された2つの単位根過程(互いに何の関係もない)を最小二乗法で回帰すると、
- 決定係数 が不当に高くなる
- 回帰係数の 統計量が発散して有意に見える
- しかし Durbin-Watson 統計量は極端に低い(誤差の強い系列相関)
という、本当は無関係なのに「強い関係がある」と誤判定する現象が起きます。Granger と Newbold(1974)がモンテカルロ実験で発見し、Phillips(1986)が理論的に証明しました。
2-2. 設定
互いに独立な2つのランダムウォーク
を用意し、これを
と回帰します。真の関係は (無関係)なので、 は 0 に収束し 値は有意にならない、はずです。ところが実際は逆になります。
2-3. なぜ起こるか(理論的裏付け)
核心は誤差項 が単位根を持ってしまう点にあります。 も も で、しかも独立なので一般には共和分しません(線形結合が定常にならない)。すると残差
は 、つまり非定常のままです。
通常の OLS の 検定は「誤差が定常で系列相関がない」ことを前提に標準誤差を計算します。ところが が だと、
- 残差の分散が時間とともに増大するため、OLS が報告する標準誤差が過小評価される。
- その結果 の分母が小さくなりすぎ、 値が膨らむ。
- しかも標本サイズ を増やすと 統計量は収束せず発散する( のオーダーで大きくなる)。
要するに何か: 値は普通「標本を増やすと真の値の周りに落ち着く」もの。ところが見せかけの回帰では標本を増やすほど“有意”になる。これは 統計量が定数に収束せず、ブラウン運動の汎関数(確率変数)に法則収束してしまうため。発散するのは「検定の前提(誤差の定常性)が壊れている」ことの帰結。
数学的には、 で がブラウン運動の積分で書ける非退化な確率変数に収束します。 自体は 倍されて無限大に飛ぶ、というのが Phillips の結果の骨子です。
2-4. 見分け方と対処
- 症状の目安: Durbin-Watson 統計量 なら見せかけの回帰を疑う(経験則)。DW が 2 から大きく外れて 0 に近い=残差に強い系列相関=残差が非定常のサイン。
- 正しい対処:
- まず各系列に単位根があるか単位根検定で確認する。
- ともに なら、安易にレベル(原系列)で回帰せず、差分をとってから回帰するか、共和分しているかを検定する。
- 共和分していれば、レベルの回帰には意味があり、後述の ECM で扱える。
引っかけ注意:「差分をとれば常に解決」ではない。差分回帰は短期の関係しか見られず、共和分している(長期均衡がある)場合は差分回帰で長期情報を捨ててしまう。共和分の有無で対処が分岐する。
3. 単位根検定:ADF検定とPP検定
3-1. 帰無仮説の向き(最重要の引っかけ)
単位根検定の帰無仮説は
です。「単位根あり=非定常」が帰無仮説である点を必ず押さえてください。したがって、
- 帰無仮説を棄却 → 定常と判断する。
- 棄却できない → 単位根がある(非定常)可能性を否定できない。
3-2. Dickey-Fuller(DF)検定
AR(1) を差分形に書き換えます。 の両辺から を引くと
単位根 は と等価です。よって検定は
という の係数検定(片側)になります。検定統計量は の 比
ですが、この は のもとで通常の 分布に従いません。 自体が単位根過程で非定常だからです。分布はブラウン運動の汎関数で表され、専用のDickey-Fuller 分布の臨界値表を使います(通常の 分布より棄却域が左に寄り、臨界値の絶対値が大きい)。
要するに何か:「単位根があるかを 検定で調べたいのに、その 値の分布が普通の にならない」というねじれが起きる。理由は説明変数 が非定常だから。だから DF 専用表を引く。
回帰式は定数項・トレンドの有無で3型あります。
| 型 | 回帰式 | 想定 |
|---|---|---|
| トレンドなし・定数なし | 平均0まわり | |
| 定数あり | ドリフトを許す | |
| 定数+トレンドあり | 確定トレンドを許す |
型によって臨界値が異なるため、データの見た目(トレンドの有無)に応じて選びます。
3-3. ADF検定(拡張Dickey-Fuller)
DF 検定は誤差 が i.i.d.(系列相関なし)を仮定します。現実には誤差に系列相関があることが多く、その場合 DF の分布が歪みます。そこでラグ差分項を説明変数に追加して系列相関を吸収したのが ADF 検定です。
追加した が誤差の自己相関を捉え、 を白色雑音に近づけます。検定の対象はあくまで で、臨界値表も DF と同じものを使います。
要するに何か:ADF は「DF の前提(誤差が無相関)が崩れる現実」に対応するための拡張。ラグ差分を足して誤差のクセを吸い取り、 の検定が正しく行えるようにしている。ラグ次数 は AIC/BIC で選ぶ。
3-4. PP検定(Phillips-Perron)
ADF が「ラグ項を足して系列相関を除く」のに対し、PP検定は回帰式はシンプルなまま、検定統計量を後から不均一分散・系列相関に頑健に補正する(ノンパラメトリックな長期分散推定で調整する)アプローチです。帰無仮説は ADF と同じ「単位根あり」です。誤差の構造の扱い方が違うだけで、目的は共通です。
使い分けの目安:系列相関の構造をラグで明示的にモデル化したいなら ADF、分散の不均一性も含めて頑健に補正したいなら PP。実務では両方かけて整合性を見ることが多い。
3-5. 検定のフロー
flowchart TD
A[時系列データ] --> B{グラフでトレンド・ドリフトの有無を確認}
B --> C[適切な型を選ぶ<br/>定数のみ/定数+トレンド/なし]
C --> D[ADF or PP検定を実施<br/>H0: 単位根あり]
D --> E{H0を棄却できるか?}
E -->|棄却できる| F[定常 I0<br/>そのまま回帰してよい]
E -->|棄却できない| G[非定常 I1の疑い<br/>1階差分をとる]
G --> H[差分系列に再度ADF]
H --> I{棄却できるか?}
I -->|棄却| J[元系列は I1 と判定]
I -->|棄却できない| K[I2 以上を疑う・再差分]
J --> L{複数の I1 系列がある?}
L -->|はい| M[共和分検定へ進む]
L -->|いいえ| N[差分系列で分析]
4. 共和分(cointegration)
4-1. 定義
複数の 過程 について、ある定数 (同時に0でない)が存在して
になるとき、 と は共和分しているといい、係数ベクトル を共和分ベクトルと呼びます。
要するに何か:個々はふらふらさまよう非定常なのに、ある決まった重み付き和だけは暴れずに一定水準の周りに収まる。 は普通 になるのに、この特定の組み合わせだけ非定常性が打ち消し合って になる、という特別な状態。
4-2. 経済学的意味:長期均衡
共和分ベクトルで作った は、変数間の長期均衡からの乖離を表します。 が定常=乖離が一定範囲に収まり続ける=両変数は長期的に連動しているということです。
具体例:
- 物価と賃金:それぞれは で右肩上がりにさまようが、実質賃金(賃金 − 物価、対数)は一定範囲に収まる。
- 金利の異なる満期:短期金利と長期金利は各々 だが、スプレッドは定常。
- 同一商品の2市場価格:裁定が効くため、価格差は定常に収まる。
引っかけ注意:見せかけの回帰と共和分は表裏一体。「 同士を回帰して残差が非定常 → 見せかけの回帰(無意味)」「 同士を回帰して残差が定常 → 共和分(長期均衡があり意味あり)」。回帰残差が か かで、同じ回帰が意味を持つか無意味かが決まる。
4-3. Engle-Granger 2段階法
共和分を検出して推定する最も基本的な手続きがEngle-Granger 2段階法です。
第1段階(共和分回帰):レベル(原系列)で OLS 回帰し、残差を得る。
ここで が共和分ベクトルの推定値(長期均衡の係数)に相当します。
第2段階(残差の単位根検定):残差 に ADF 検定をかける。
- 残差が定常 と判定 → 共和分している(長期均衡が存在)。
- 残差が非定常 → 共和分しておらず、第1段階の回帰は見せかけの回帰。
要するに何か:「レベルで回帰 → その残差が定常か検定」という2段構え。残差の定常性こそが共和分の証拠。なお残差は推定された値なので、ここで使う臨界値は通常の ADF 表ではなく共和分検定用(Engle-Granger用)の臨界値表を引く(推定で を使った分、棄却が起きにくくなる方向に補正されている)点が引っかけ。
3変数以上で共和分関係が複数あり得る場合は、Engle-Granger では扱いきれず、Johansen の手法(VAR ベースで共和分ランクを検定)を用います(1級では名称と「複数の共和分関係を同時に扱える」点を押さえれば十分なことが多い/要最新確認)。
4-4. 誤差修正モデル(ECM)
共和分があるとき、短期の変動と長期均衡への復元を同時に表現するのが**誤差修正モデル(Error Correction Model, ECM)**です。Granger 表現定理により「共和分しているなら ECM 表現が存在し、その逆も成り立つ」ことが保証されます。
- :短期の効果(差分どうしの関係。今期の の動きが今期の をどう動かすか)。
- :誤差修正項。前期末に長期均衡からどれだけズレていたか()を、今期どれだけ戻すか。 なら、均衡より上振れ()していたとき今期 を引き下げる方向に働く。
要するに何か:「短期はその場の勢いで動くが、長期均衡からズレすぎると引き戻される」という調整メカニズム。 は復元の速さ(調整速度)。 が大きいほど均衡へ早く戻る。差分どうし()は定常、誤差修正項 も共和分ゆえ定常なので、ECM 全体が定常変数だけで構成され、通常の OLS・ 検定が正当化される(見せかけの回帰を回避できている)。
4-5. 単位根・共和分・回帰の関係マップ
graph TD
A[2系列 x, y] --> B{各系列は I1?}
B -->|両方 I0| C[普通の回帰でOK<br/>定常なので問題なし]
B -->|両方 I1| D{線形結合が定常?<br/>= 共和分してる?}
D -->|共和分なし<br/>残差が I1| E[見せかけの回帰<br/>レベル回帰は無意味<br/>差分回帰へ]
D -->|共和分あり<br/>残差が I0| F[長期均衡が存在<br/>レベル回帰に意味あり]
F --> G[ECM で短期+長期を表現<br/>Granger表現定理]
E --> H[Δx, Δy の差分回帰<br/>短期関係のみ]
5. ボラティリティ変動:ARCH/GARCHモデル
5-1. 動機:ボラティリティ・クラスタリング
金融データ(株価リターン、為替リターン)には、平均(リターンの水準)を ARMA で予測しても残差がまだ**変動の大小に塊(クラスター)**を持つ性質があります。
- 大きく動いた翌日はまた大きく動きやすい。
- 静かな時期は静かなまま続く。
これをボラティリティ・クラスタリングと呼びます。ARMA は条件付き平均をモデル化しますが、条件付き分散は一定と仮定するため、この現象を表現できません。そこで条件付き分散を時間変化させるのが ARCH/GARCH です。
要するに何か:「いつ大きく動くか」ではなく「どれくらい大きく動くか(暴れ具合)」が時間とともに変わり、しかも暴れは群れる。平均のモデル(ARMA)では分散一定なので捉えられない。分散そのものを動的にモデル化する必要がある。
5-2. ARCHモデルの定式化
Engle(1982)のARCH() モデル(自己回帰条件付き不均一分散)は次の形です。誤差 を
と書き、その条件付き分散 を過去の二乗誤差で説明します。
は時刻 までの情報で条件づけた分散です。
要するに何か:「昨日大きなショック があったら、今日の分散 も大きくなる」という仕組み。過去のショックの二乗が今日の暴れ具合に効く。だから大きい変動の翌日は分散が上がり、クラスタリングが再現される。 は分散が正である(負にならない)ための制約。
無条件分散(定常時)は
となり、 が過程が爆発しない(弱定常)ための条件です。
5-3. GARCHモデルの定式化
ARCH は過去の二乗誤差だけで分散を説明するため、長い記憶を表すには多くのラグ が必要で、パラメータが増えすぎます。Bollerslev(1986)は過去の条件付き分散 そのものも説明変数に加え、簡潔にしました。これがGARCH() です。
最もよく使う GARCH(1,1) は
- :直近のショック(新規情報)への反応。
- :過去の分散水準の持続(記憶)。
要するに何か:「今日の暴れ具合=定数+昨日のショックの大きさ+昨日の暴れ具合」。ARMA の分散版だと思えばよい( が MA 的なショック項、 が AR 的な持続項)。 が大きいほどボラティリティが粘り強く続く(クラスタリングが長引く)。
定常条件は
で、 が1に近いほどショックの影響が長く残ります(高い持続性)。
5-4. 何を捉え、何を捉えないか
| 観点 | ARMA | ARCH/GARCH |
|---|---|---|
| モデル化対象 | 条件付き平均 | 条件付き分散 |
| 分散の扱い | 一定(homoskedastic) | 時間変化(heteroskedastic) |
| 捉える現象 | 系列相関・水準の予測 | ボラティリティ・クラスタリング |
| 典型データ | マクロ経済の水準系列 | 金融リターン |
実務ではARMA-GARCHとして、平均を ARMA、分散を GARCH で同時にモデル化します。
引っかけ注意:ARCH/GARCH が捉えるのは分散(2次モーメント)の時間変化であって、リターンの符号や水準(平均)の予測ではない。「GARCH で株価の上がり下がりを当てる」は誤り。当てるのは「どれくらい荒れるか」。また、リターン自体は無相関でも二乗リターンには相関がある、という形でボラティリティの予測可能性が現れる。
試験での問われ方(1級)
統計検定1級・統計応用(社会科学)では、計量経済学の時系列が**重要度A(頻出)**で出ます。問われ方の典型を整理します。
- 見せかけの回帰の仕組み:「独立な単位根過程を回帰するとなぜ が高く 値が有意になるのか」を、残差が で非定常になること・ 統計量が オーダーで発散することと結びつけて説明させる。Durbin-Watson が低いことを症状として挙げさせる問題も。
- 単位根検定の帰無仮説の向き:「=単位根あり(非定常)」を正しく書けるか。棄却=定常、という判定の方向。ADF が DF にラグ差分を足して系列相関を吸収する理由。検定統計量が通常の 分布に従わない理由(説明変数 が非定常だから)。
- 共和分の意味:「個々は だが線形結合が になる」状態=長期均衡。Engle-Granger 2段階法の手順(レベル回帰 → 残差の ADF)。残差が定常なら共和分・非定常なら見せかけの回帰、という分岐。
- ECM の構造:誤差修正項 の符号と意味(均衡からの乖離を引き戻す)、調整速度 。Granger 表現定理(共和分 ⟺ ECM 表現の存在)。
- ARCH/GARCH が捉える現象:条件付き分散が過去の二乗誤差・過去の分散に依存する式を書かせ、ボラティリティ・クラスタリングを説明させる。定常条件 。捉えるのは平均でなく分散である点。
- 計算寄りの出題:GARCH(1,1) の無条件分散 を求めさせる、ARCH の定常条件 を確認させる、など。
出題範囲表・各分野の比重は改訂されうるため要最新確認。社会科学分野では重回帰・時系列・標本調査の比重が高い、という傾向は近年共通。
⚠️ 引っかけ・頻出論点
- 単位根検定の帰無仮説は「単位根あり(非定常)」。「定常が帰無」ではない。棄却して初めて「定常」と言える。棄却できない=「非定常を否定できない」であって「非定常と証明された」ではない(検定力の問題)。
- DF/ADF統計量は通常の 分布に従わない。説明変数 が非定常だから。専用の Dickey-Fuller 臨界値表(型ごとに別)を使う。普通の 表で判定すると誤る。
- 見せかけの回帰では標本を増やすほど“有意”になる。 値が収束せず発散する。普通の回帰の直感( を増やせば真値に収束)が逆転する。
- 共和分と見せかけの回帰は残差の和分次数で分かれる。レベル回帰の残差が なら共和分(意味あり)、 なら見せかけ(無意味)。同じ回帰でも残差次第。
- Engle-Granger 第2段階の臨界値は通常のADF表ではない。残差が推定値( を使った)なので、共和分検定専用の臨界値を引く。
- 「差分をとれば万事解決」ではない。共和分している場合、差分回帰は長期均衡情報を捨てる。共和分があるなら ECM を使う。
- ARCH/GARCHは分散のモデルであり平均(リターンの方向)のモデルではない。捉えるのはボラティリティ・クラスタリング。リターン自体は無相関でも二乗リターンに相関が出る。
- GARCHの定常条件は (ARCH単体なら )。これを満たさないとボラティリティが発散する。1に近いほど高い持続性。
よくある疑問
Q1. 「単位根がある」と「非定常」は同じ意味ですか?
A. 厳密には違います。単位根( など)は非定常の一種です。非定常には他にも「確定トレンドを持つが単位根はない(トレンド定常)」場合があります。トレンド定常はトレンドを除けば定常になりますが、 は差分しないと定常になりません。両者は対処が異なる(トレンド除去 vs 差分)ため、単位根検定で型に確定トレンド項を入れて区別します。混同すると「差分すべきところをトレンド除去」して過剰差分・過小差分になります。
Q2. なぜ見せかけの回帰では が高くなるのに、それが問題なのですか?
A. が高い=「説明できている」ように見えるからこそ問題です。本当は無関係なのに高い と有意な 値が出るので、分析者が「強い関係を発見した」と誤って結論してしまう。 が高いのは、両系列がともにトレンド的にさまよう(共通の確率的トレンドではなく、各自の確率的トレンド)ために見かけ上一緒に動いて見えるだけで、因果も長期関係もありません。Durbin-Watson が極端に低い(残差が非定常で強い系列相関)ことが警告サインです。
Q3. 共和分しているかどうかを、回帰係数の有意性で判断してはいけないのですか?
A. いけません。それこそ見せかけの回帰の罠です。レベルで回帰して係数が有意でも、それだけでは「関係あり」と言えません(無関係でも有意に出るのが見せかけの回帰)。共和分の判定は回帰残差が定常か否かで行います(Engle-Granger 第2段階)。残差が定常なら、その回帰係数(共和分ベクトル)は長期均衡として意味を持ちます。「係数の有意性」ではなく「残差の和分次数」が判断基準です。
Q4. GARCH(1,1) で がほぼ1のとき何が起きますか?
A. ショックの影響がほとんど減衰せず長く残る状態で、ボラティリティの持続性が極めて高くなります。 ちょうどになると IGARCH(積分GARCH) と呼ばれ、分散における単位根のような状態で、無条件分散 が発散して定義できなくなります。金融データの実証では が 0.99 前後と非常に1に近い値になることが多く、これがボラティリティの長期記憶を反映しています。
Q5. ADF検定で棄却できなかったら「非定常で確定」と書いてよいですか?
A. よくありません。検定で帰無仮説(単位根あり)を棄却できないのは「単位根がないとは言えない」までで、「単位根があると証明された」ではありません。特に単位根検定は検定力が低い(真は定常でも、 が1に近いと棄却しにくい)ことが知られています。記述は「単位根の存在を否定できない」「非定常の可能性が残る」とするのが正確。複数の検定(ADF と PP)や型を変えて整合性を確認するのが実務的作法です。
まとめ
- 経済・金融時系列は (単位根)であることが多く、 のランダムウォークが基本形。1階差分で定常 になる。連続極限はブラウン運動。
- 同士を安易にレベルで回帰すると見せかけの回帰:残差が非定常になり、 が不当に高く 値が発散し、標本を増やすほど“有意”に見える。Durbin-Watson の低さが警告。
- **単位根検定(ADF・PP)**の帰無仮説は「単位根あり(非定常)」。棄却=定常。検定統計量は通常の 分布に従わず DF 専用表を使う。
- 共和分は「個々は なのに線形結合だけ 」=長期均衡。Engle-Granger 2段階法(レベル回帰 → 残差の ADF)で検定し、残差が定常なら共和分。短期と長期を結ぶのが ECM(誤差修正項が均衡へ引き戻す)。
- ARCH/GARCHは条件付き分散を過去のショック・過去の分散で説明し、ボラティリティ・クラスタリングを捉える。捉えるのは分散であって平均ではない。GARCH(1,1) の定常条件は 。
関連ノート
- 時系列解析(定常性・ACF/PACF・AR・MA・ARMA・ARIMA) 定常性・ARIMA・ランダムウォークの基礎(本ノートの前提)
- 確率過程(マルコフ連鎖・ポアソン過程) 確率過程の一般論
- ブラウン運動 ランダムウォークの連続極限・単位根分布の理論的背景
- ガウス・マルコフの定理とGLS OLSの前提と系列相関への対処
- 社会科学分野ハブ(Phase 9) 社会科学分野の全体像