← 統計検定テキスト 一覧
📊 対象級:準1級 ・ 1級 | 重要度:A(頻出)
要点(BLUF)
時系列解析の核心は「どのモデルがデータを生成したか を、ACFとPACFのパターンから読み取ること」。非定常ならば差分で定常化し、定常化後にAR(p)かMA(q)かARMA(p,q)かをACF/PACFの打ち切れ(カットオフ)パターン で同定する。AR(1)なら ρ k = φ k \rho_k = \varphi^k ρ k = φ k ∣ φ ∣ < 1 \lvert\varphi\rvert < 1 ∣ φ ∣ < 1
1. 時系列データの構成要素
観測値 X t X_t X t
X t = T t + S t + C t + I t X_t = T_t + S_t + C_t + I_t X t = T t + S t + C t + I t 成分 記号 内容 トレンド成分 T t T_t T t 長期的な増減傾向(人口増・技術進歩など) 季節成分 S t S_t S t 一定周期で繰り返すパターン(月次・四半期など) 循環成分 C t C_t C t 景気循環のような数年単位の波。トレンドと混同されやすい 不規則成分 I t I_t I t 上記3つを除いた残差。ランダムな変動
要するに「時系列 = 決定論的なパターン3つ + ランダムな残り 」です。確率的モデル(AR・MA・ARIMA)は主に不規則成分をモデル化しますが、ARIMAの差分はトレンド(漸近的非定常)を除去する操作でもあります。
2. 定常性
2.1 弱定常(Wide-Sense Stationary / Covariance Stationary)
時系列 { X t } \{X_t\} { X t }
( 1 ) E [ X t ] = μ ( すべての t で一定 ) ( 2 ) V a r ( X t ) = σ 2 < ∞ ( すべての t で一定 ) ( 3 ) C o v ( X t , X t + k ) = γ k ( t に依存せず、ラグ k だけの関数 ) \boxed{
\begin{aligned}
&(1)\quad E[X_t] = \mu \quad (\text{すべての }t\text{ で一定})\\
&(2)\quad \mathrm{Var}(X_t) = \sigma^2 < \infty \quad (\text{すべての }t\text{ で一定})\\
&(3)\quad \mathrm{Cov}(X_t, X_{t+k}) = \gamma_k \quad (t\text{ に依存せず、ラグ }k\text{ だけの関数})
\end{aligned}
} ( 1 ) E [ X t ] = μ ( すべての t で一定 ) ( 2 ) Var ( X t ) = σ 2 < ∞ ( すべての t で一定 ) ( 3 ) Cov ( X t , X t + k ) = γ k ( t に依存せず、ラグ k だけの関数 ) 要するに「平均・分散が時点によらず一定で、自己共分散はラグ差だけで決まる 」。株価の水準や気温の年間トレンドを含む原系列はふつう非定常ですが、差分を取ると定常になることが多いです。
⚠️ 強定常(分布全体が時間シフト不変)と弱定常は別概念。正規過程では同値ですが、一般には強定常 → 弱定常のみが成立します。試験では「弱定常」「共分散定常」が主題。
2.2 ホワイトノイズ
{ ε t } \{\varepsilon_t\} { ε t } ホワイトノイズ であるとは
E [ ε t ] = 0 , V a r ( ε t ) = σ 2 , C o v ( ε t , ε s ) = 0 ( t ≠ s ) E[\varepsilon_t] = 0, \quad \mathrm{Var}(\varepsilon_t) = \sigma^2, \quad \mathrm{Cov}(\varepsilon_t, \varepsilon_s) = 0 \; (t \neq s) E [ ε t ] = 0 , Var ( ε t ) = σ 2 , Cov ( ε t , ε s ) = 0 ( t = s ) 要するに「無相関・等分散・平均ゼロの過程 」。正規ホワイトノイズ(ε t ∼ N ( 0 , σ 2 ) \varepsilon_t \sim N(0, \sigma^2) ε t ∼ N ( 0 , σ 2 )
2.3 自己共分散関数と自己相関関数(ACF)
ラグ k k k 自己共分散 は
γ k = C o v ( X t , X t + k ) = E [ ( X t − μ ) ( X t + k − μ ) ] \gamma_k = \mathrm{Cov}(X_t, X_{t+k}) = E[(X_t - \mu)(X_{t+k} - \mu)] γ k = Cov ( X t , X t + k ) = E [( X t − μ ) ( X t + k − μ )] 自己相関係数(ACF) ρ k \rho_k ρ k γ 0 \gamma_0 γ 0
ρ k = γ k γ 0 \rho_k = \frac{\gamma_k}{\gamma_0} ρ k = γ 0 γ k 要するに「X t X_t X t k k k X t + k X_{t+k} X t + k − 1 -1 − 1 1 1 1
2.4 偏自己相関関数(PACF)
ρ k \rho_k ρ k X t X_t X t X t + k X_{t+k} X t + k 間に挟まる X t + 1 , … , X t + k − 1 X_{t+1}, \ldots, X_{t+k-1} X t + 1 , … , X t + k − 1 。これを取り除いた純粋な直接相関が偏自己相関(PACF) α k \alpha_k α k
α k = C o r r ( X t − X ^ t , X t + k − X ^ t + k ) \alpha_k = \mathrm{Corr}(X_t - \hat{X}_t, \; X_{t+k} - \hat{X}_{t+k}) α k = Corr ( X t − X ^ t , X t + k − X ^ t + k ) ここで X ^ t \hat{X}_t X ^ t X t + 1 , … , X t + k − 1 X_{t+1}, \ldots, X_{t+k-1} X t + 1 , … , X t + k − 1 X t X_t X t X ^ t + k \hat{X}_{t+k} X ^ t + k ラグ k k k X t X_t X t X t + k X_{t+k} X t + k 」。
3. AR(p)モデル — 自己回帰モデル
3.1 定義
X t = c + φ 1 X t − 1 + φ 2 X t − 2 + ⋯ + φ p X t − p + ε t X_t = c + \varphi_1 X_{t-1} + \varphi_2 X_{t-2} + \cdots + \varphi_p X_{t-p} + \varepsilon_t X t = c + φ 1 X t − 1 + φ 2 X t − 2 + ⋯ + φ p X t − p + ε t 要するに「今期の値 = 定数 + 過去 p p p 」。名前の”自己回帰”は「X X X X X X
ラグ演算子 B B B B X t = X t − 1 B X_t = X_{t-1} B X t = X t − 1
φ ( B ) X t = c + ε t , φ ( B ) = 1 − φ 1 B − φ 2 B 2 − ⋯ − φ p B p \varphi(B) X_t = c + \varepsilon_t, \quad \varphi(B) = 1 - \varphi_1 B - \varphi_2 B^2 - \cdots - \varphi_p B^p φ ( B ) X t = c + ε t , φ ( B ) = 1 − φ 1 B − φ 2 B 2 − ⋯ − φ p B p 3.2 AR(1)の平均・分散・自己相関 — 完全導出
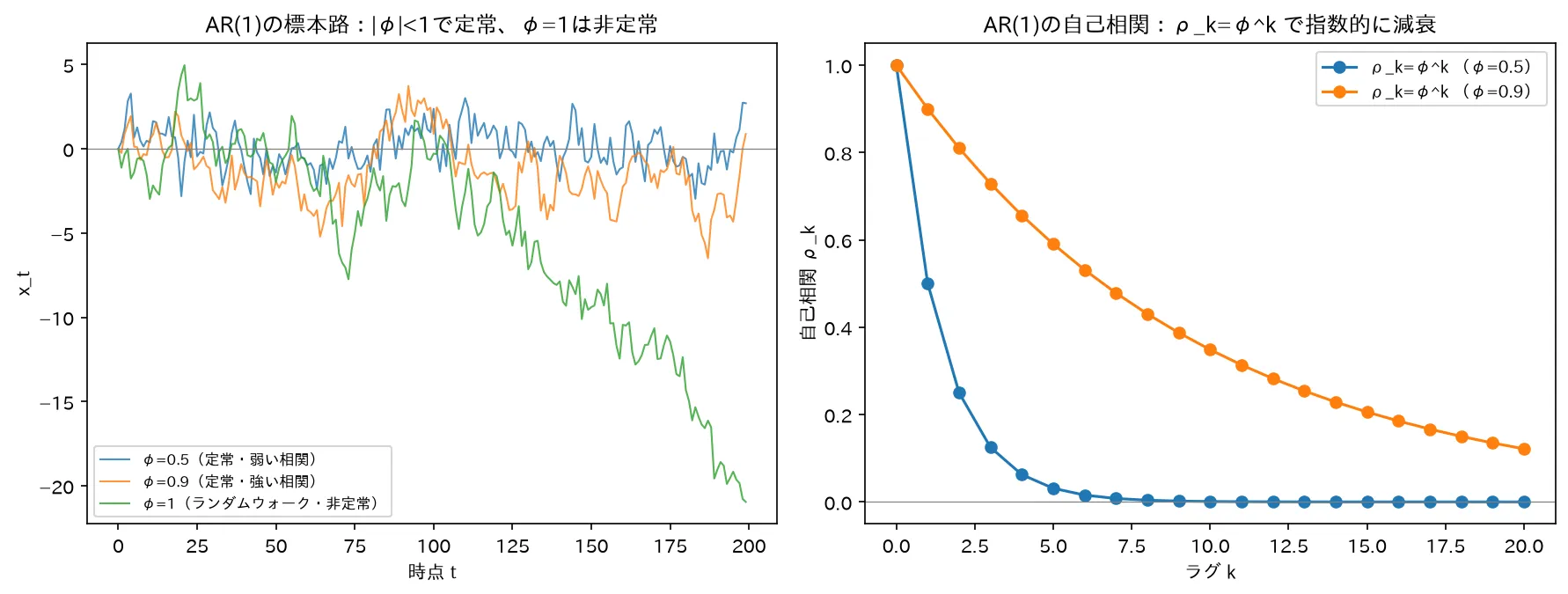
左:AR(1)の標本路(|φ|<1は定常、φ=1のランダムウォークは非定常)。右:自己相関 ρ_k=φ^k は指数的に減衰。図は simulations/ar1_acf_jikkeiretsu.py で生成。
AR(1) X t = c + φ X t − 1 + ε t X_t = c + \varphi X_{t-1} + \varepsilon_t X t = c + φ X t − 1 + ε t ε t ∼ W N ( 0 , σ 2 ) \varepsilon_t \sim WN(0, \sigma^2) ε t ∼ W N ( 0 , σ 2 )
平均の導出
定常性を仮定すると E [ X t ] = E [ X t − 1 ] = μ E[X_t] = E[X_{t-1}] = \mu E [ X t ] = E [ X t − 1 ] = μ
μ = c + φ μ ⟹ μ = c 1 − φ \mu = c + \varphi \mu \;\Longrightarrow\; \mu = \frac{c}{1-\varphi} μ = c + φ μ ⟹ μ = 1 − φ c 要するに「定常なら平均はどの時点でも同じ μ \mu μ c = 0 c=0 c = 0 μ = 0 \mu=0 μ = 0
分散の導出
X t = φ X t − 1 + ε t X_t = \varphi X_{t-1} + \varepsilon_t X t = φ X t − 1 + ε t V a r ( X t ) = V a r ( X t − 1 ) = γ 0 \mathrm{Var}(X_t) = \mathrm{Var}(X_{t-1}) = \gamma_0 Var ( X t ) = Var ( X t − 1 ) = γ 0
γ 0 = E [ X t 2 ] = E [ ( φ X t − 1 + ε t ) 2 ] = φ 2 E [ X t − 1 2 ] + 2 φ E [ X t − 1 ε t ] + E [ ε t 2 ] \gamma_0 = E[X_t^2] = E[(\varphi X_{t-1} + \varepsilon_t)^2]
= \varphi^2 E[X_{t-1}^2] + 2\varphi E[X_{t-1} \varepsilon_t] + E[\varepsilon_t^2] γ 0 = E [ X t 2 ] = E [( φ X t − 1 + ε t ) 2 ] = φ 2 E [ X t − 1 2 ] + 2 φE [ X t − 1 ε t ] + E [ ε t 2 ] X t − 1 X_{t-1} X t − 1 ε t \varepsilon_t ε t X X X E [ X t − 1 ε t ] = 0 E[X_{t-1}\varepsilon_t]=0 E [ X t − 1 ε t ] = 0
γ 0 = φ 2 γ 0 + σ 2 ⟹ γ 0 ( 1 − φ 2 ) = σ 2 ⟹ γ 0 = σ 2 1 − φ 2 \gamma_0 = \varphi^2 \gamma_0 + \sigma^2
\;\Longrightarrow\;
\gamma_0(1 - \varphi^2) = \sigma^2
\;\Longrightarrow\;
\boxed{\gamma_0 = \frac{\sigma^2}{1 - \varphi^2}} γ 0 = φ 2 γ 0 + σ 2 ⟹ γ 0 ( 1 − φ 2 ) = σ 2 ⟹ γ 0 = 1 − φ 2 σ 2 要するに「定常性の仮定自体が 1 − φ 2 > 0 1 - \varphi^2 > 0 1 − φ 2 > 0 ∣ φ ∣ < 1 \lvert\varphi\rvert < 1 ∣ φ ∣ < 1 ∣ φ ∣ ≥ 1 \lvert\varphi\rvert \ge 1 ∣ φ ∣ ≥ 1 γ 0 \gamma_0 γ 0
定常条件の特性方程式による言い換え
AR(p)の特性多項式 は φ ( z ) = 1 − φ 1 z − ⋯ − φ p z p \varphi(z) = 1 - \varphi_1 z - \cdots - \varphi_p z^p φ ( z ) = 1 − φ 1 z − ⋯ − φ p z p 特性方程式 φ ( z ) = 0 \varphi(z)=0 φ ( z ) = 0 単位円の外側 (∣ z ∣ > 1 \lvert z\rvert > 1 ∣ z ∣ > 1
AR(1)の場合、特性方程式は 1 − φ z = 0 1 - \varphi z = 0 1 − φ z = 0 z = 1 / φ z = 1/\varphi z = 1/ φ ∣ 1 / φ ∣ > 1 \lvert 1/\varphi \rvert > 1 ∣ 1/ φ ∣ > 1 ∣ φ ∣ < 1 \lvert\varphi\rvert < 1 ∣ φ ∣ < 1
⚠️ 「特性根が単位円外 」という条件は「特性根の絶対値が1より大きい 」という意味。「単位円内 」と書かれたら誤りです。
自己相関の導出(Yule-Walker 方程式の基礎)
γ k = E [ X t X t − k ] \gamma_k = E[X_t X_{t-k}] γ k = E [ X t X t − k ] μ = 0 \mu=0 μ = 0 X t − k X_{t-k} X t − k
E [ X t X t − k ] = φ E [ X t − 1 X t − k ] + E [ ε t X t − k ] E[X_t X_{t-k}] = \varphi E[X_{t-1} X_{t-k}] + E[\varepsilon_t X_{t-k}] E [ X t X t − k ] = φE [ X t − 1 X t − k ] + E [ ε t X t − k ] k ≥ 1 k \ge 1 k ≥ 1 ε t \varepsilon_t ε t t t t X t − k X_{t-k} X t − k E [ ε t X t − k ] = 0 E[\varepsilon_t X_{t-k}]=0 E [ ε t X t − k ] = 0
γ k = φ γ k − 1 \gamma_k = \varphi \gamma_{k-1} γ k = φ γ k − 1 この漸化式はYule-Walker方程式 の最も単純な形です。γ 0 \gamma_0 γ 0
γ k = φ k γ 0 \gamma_k = \varphi^k \gamma_0 γ k = φ k γ 0 自己相関は ρ k = γ k / γ 0 \rho_k = \gamma_k / \gamma_0 ρ k = γ k / γ 0
ρ k = φ k \boxed{\rho_k = \varphi^k} ρ k = φ k 要するに「AR(1)の自己相関はラグ k k k 。φ > 0 \varphi > 0 φ > 0 φ < 0 \varphi < 0 φ < 0
xychart-beta
title "AR(1)のACF比較(φ=0.7 vs φ=−0.7)"
x-axis "ラグ k" [0, 1, 2, 3, 4, 5, 6, 7, 8]
y-axis "自己相関 ρ_k" -1 --> 1
bar [1, 0.7, 0.49, 0.343, 0.24, 0.168, 0.118, 0.082, 0.057]
line [1, -0.7, 0.49, -0.343, 0.24, -0.168, 0.118, -0.082, 0.057]
(棒:φ = 0.7 \varphi=0.7 φ = 0.7 φ = − 0.7 \varphi=-0.7 φ = − 0.7
AR(1)のACFはラグが増えるにつれてゼロに向かって徐々に減衰 します(打ち切れない)。一方、PACFはラグ1のみ φ \varphi φ ラグ1で打ち切れる )。
4. MA(q)モデル — 移動平均モデル
4.1 定義
X t = μ + ε t + θ 1 ε t − 1 + θ 2 ε t − 2 + ⋯ + θ q ε t − q X_t = \mu + \varepsilon_t + \theta_1 \varepsilon_{t-1} + \theta_2 \varepsilon_{t-2} + \cdots + \theta_q \varepsilon_{t-q} X t = μ + ε t + θ 1 ε t − 1 + θ 2 ε t − 2 + ⋯ + θ q ε t − q 要するに「今期の値 = 定数 + 現在の誤差 + 過去 q q q 」。“移動平均”は過去の誤差の加重平均です。
4.2 MA(q)の性質(導出)
μ = 0 \mu=0 μ = 0 X t = ∑ j = 0 q θ j ε t − j X_t = \sum_{j=0}^{q} \theta_j \varepsilon_{t-j} X t = ∑ j = 0 q θ j ε t − j θ 0 = 1 \theta_0=1 θ 0 = 1
分散 (ラグ0の自己共分散):
γ 0 = V a r ( X t ) = ∑ j = 0 q θ j 2 σ 2 = σ 2 ∑ j = 0 q θ j 2 \gamma_0 = \mathrm{Var}(X_t) = \sum_{j=0}^{q} \theta_j^2 \sigma^2 = \sigma^2 \sum_{j=0}^{q} \theta_j^2 γ 0 = Var ( X t ) = j = 0 ∑ q θ j 2 σ 2 = σ 2 j = 0 ∑ q θ j 2 自己共分散 (1 ≤ k ≤ q 1 \le k \le q 1 ≤ k ≤ q
γ k = E [ X t X t − k ] = E [ ∑ i = 0 q θ i ε t − i ⋅ ∑ j = 0 q θ j ε t − k − j ] = σ 2 ∑ j = 0 q − k θ j θ j + k \gamma_k = E[X_t X_{t-k}]
= E\!\left[\sum_{i=0}^{q}\theta_i \varepsilon_{t-i} \cdot \sum_{j=0}^{q}\theta_j \varepsilon_{t-k-j}\right]
= \sigma^2 \sum_{j=0}^{q-k} \theta_j \theta_{j+k} γ k = E [ X t X t − k ] = E [ i = 0 ∑ q θ i ε t − i ⋅ j = 0 ∑ q θ j ε t − k − j ] = σ 2 j = 0 ∑ q − k θ j θ j + k (ε \varepsilon ε
k > q k > q k > q γ k = 0 \gamma_k = 0 γ k = 0
ρ k = 0 ( k > q ) \boxed{\rho_k = 0 \quad (k > q)} ρ k = 0 ( k > q ) 要するに「MA(q)のACFはラグq q q 」。これがMA(q)次数 q q q
4.3 MA(q)は常に定常
MA(q)は有限個のホワイトノイズの線形和なので、平均・分散・自己共分散はすべて有限かつ時間に依存しません。次数によらず MA は常に定常 です。
4.4 反転可能性(Invertibility)
MA過程が「AR(∞)の形に書き換えられる」条件を反転可能性 と言います。MA(q)の反転可能性は特性多項式 θ ( z ) = 1 + θ 1 z + ⋯ + θ q z q \theta(z) = 1 + \theta_1 z + \cdots + \theta_q z^q θ ( z ) = 1 + θ 1 z + ⋯ + θ q z q
5. ARMA(p,q)モデル
AR(p)とMA(q)を組み合わせたモデルです。
X t = c + φ 1 X t − 1 + ⋯ + φ p X t − p + ε t + θ 1 ε t − 1 + ⋯ + θ q ε t − q X_t = c + \varphi_1 X_{t-1} + \cdots + \varphi_p X_{t-p} + \varepsilon_t + \theta_1 \varepsilon_{t-1} + \cdots + \theta_q \varepsilon_{t-q} X t = c + φ 1 X t − 1 + ⋯ + φ p X t − p + ε t + θ 1 ε t − 1 + ⋯ + θ q ε t − q ラグ演算子で書くと φ ( B ) X t = c + θ ( B ) ε t \varphi(B) X_t = c + \theta(B)\varepsilon_t φ ( B ) X t = c + θ ( B ) ε t
定常条件 :φ ( z ) = 0 \varphi(z)=0 φ ( z ) = 0 反転可能条件 :θ ( z ) = 0 \theta(z)=0 θ ( z ) = 0
ARMA(p,q)のACFもPACFも、どちらも**ラグが増えるにつれて指数的に減衰(打ち切れない)**します。これがARMAを他のモデルと区別する特徴です。
6. ARIMA(p,d,q)— 和分・差分・非定常への対応
6.1 和分過程と差分
AR(1)で φ = 1 \varphi = 1 φ = 1 X t = X t − 1 + ε t X_t = X_{t-1} + \varepsilon_t X t = X t − 1 + ε t
1階差分 ∇ X t = X t − X t − 1 \nabla X_t = X_t - X_{t-1} ∇ X t = X t − X t − 1 ∇ X t = ε t \nabla X_t = \varepsilon_t ∇ X t = ε t
一般に、d d d d d d I ( d ) I(d) I ( d )
∇ d X t = ( 1 − B ) d X t ∼ 定常 ARMA ( p , q ) \nabla^d X_t = (1-B)^d X_t \sim \text{定常 ARMA}(p,q) ∇ d X t = ( 1 − B ) d X t ∼ 定常 ARMA ( p , q ) 6.2 ARIMA(p,d,q)の定義
φ ( B ) ( 1 − B ) d X t = c + θ ( B ) ε t \boxed{\varphi(B)(1-B)^d X_t = c + \theta(B)\varepsilon_t} φ ( B ) ( 1 − B ) d X t = c + θ ( B ) ε t
p p p d d d q q q
要するに「差分で定常化してからARMAを当てる 」というモデルです。d = 0 d=0 d = 0
6.3 季節差分と SARIMA
季節性(周期 s s s 季節差分 ∇ s X t = X t − X t − s \nabla_s X_t = X_t - X_{t-s} ∇ s X t = X t − X t − s SARIMA(p,d,q)(P,D,Q)_s では、通常の差分と季節差分の両方で定常化します。概念として理解していれば準1級には十分です(1級ではモデル式の展開も問われる)。
7. モデル同定:ACF・PACFによる次数の決定
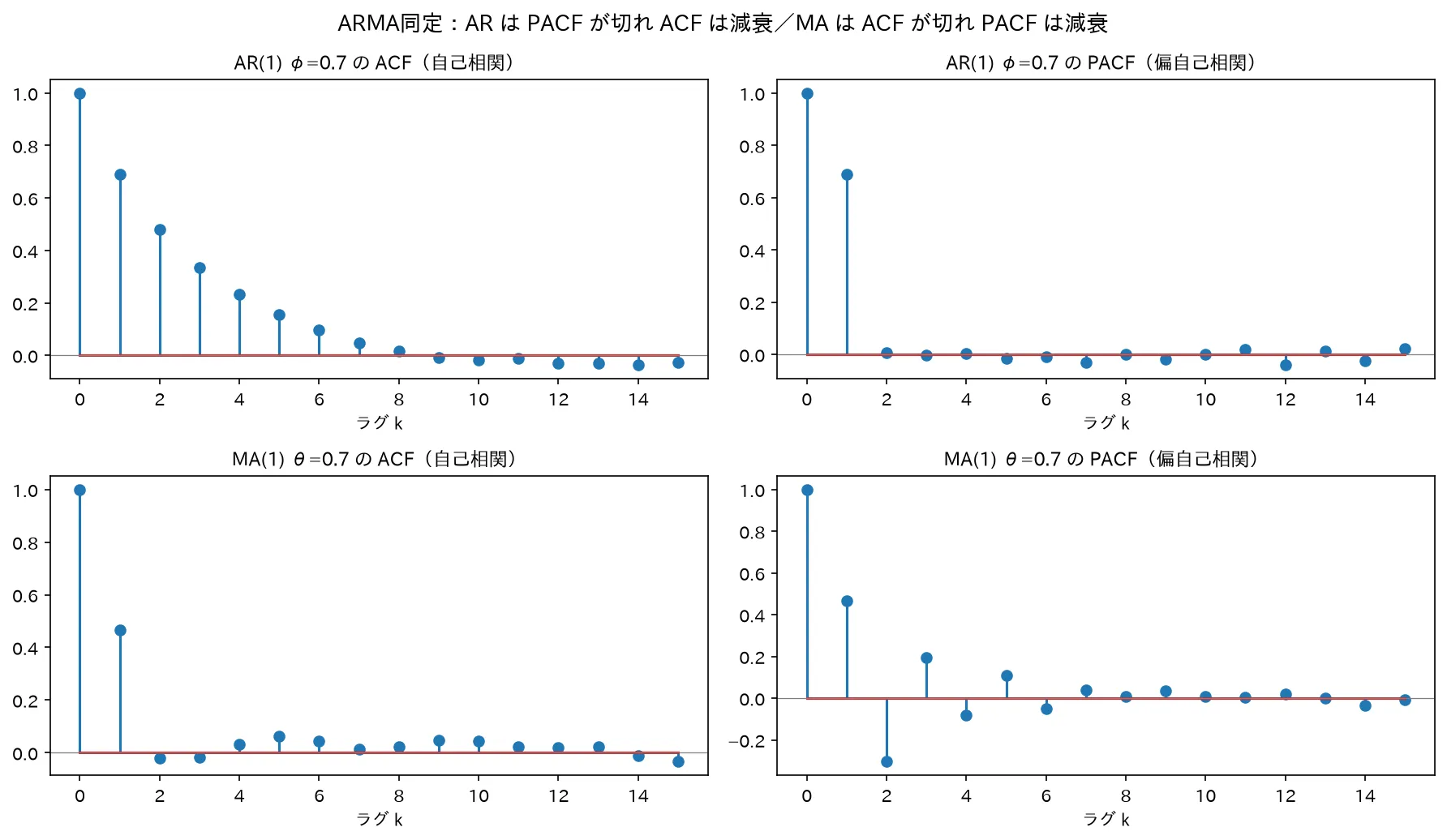
上=AR(1):ACFは減衰・PACFがラグ1で切れる/下=MA(1):ACFがラグ1で切れPACFは減衰。この非対称性が次数同定の決め手。図は simulations/acf_pacf_doutei.py で生成。
ARIMAのモデリングはBox-Jenkinsの手順に従います。
flowchart TD
A[原系列の観察] --> B{単位根・非定常?}
B -- "はい" --> C["差分を取る<br/>d 回繰り返す"]
C --> D{定常になったか?}
D -- "いいえ" --> C
D -- "はい" --> E[ACF と PACF を計算]
B -- "いいえ" --> E
E --> F{ACF の形状}
F -- "ラグ q で打ち切れ" --> G["MA(q)候補"]
F -- "指数的に減衰" --> I{PACF の形状}
I -- "ラグ p で打ち切れ" --> H["AR(p)候補"]
I -- "指数的に減衰" --> J["ARMA(p,q)候補<br/>AIC等で次数選択"]
G --> K[残差診断:白色化を確認]
H --> K
J --> K
K -- "OK" --> L["ARIMA(p,d,q)確定"]
K -- "NG" --> E
7.1 同定の核心表
モデル ACF(自己相関) PACF(偏自己相関) AR(p) ラグが増えるにつれ徐々に減衰(打ち切れない) ラグ p で打ち切れる MA(q) ラグ q で打ち切れる ラグが増えるにつれ徐々に減衰(打ち切れない) ARMA(p,q) 徐々に減衰(打ち切れない) 徐々に減衰(打ち切れない)
要するに「ARはPACFを見てpを決め、MAはACFを見てqを決める 」。ARMAはどちらも打ち切れないので、AICなどの情報量基準で次数を選びます。
⚠️ 最頻出の誤解:「ARモデルの次数はACFで決める」「MAモデルはPACFで決める」と逆に覚えること。正しくは「AR→PACF 、MA→ACF 」。理由は「AR(p)は p p p p p p q q q q q q
8. Yule-Walker方程式(1級の核心)
AR(p)のパラメータ φ 1 , … , φ p \varphi_1, \ldots, \varphi_p φ 1 , … , φ p ρ 1 , … , ρ p \rho_1, \ldots, \rho_p ρ 1 , … , ρ p Yule-Walker方程式 が成立します。
AR(p)式の両辺に X t − k X_{t-k} X t − k k = 1 , … , p k=1,\ldots,p k = 1 , … , p γ k = φ 1 γ k − 1 + ⋯ + φ p γ k − p \gamma_k = \varphi_1 \gamma_{k-1} + \cdots + \varphi_p \gamma_{k-p} γ k = φ 1 γ k − 1 + ⋯ + φ p γ k − p X X X γ 0 \gamma_0 γ 0
ρ k = φ 1 ρ k − 1 + φ 2 ρ k − 2 + ⋯ + φ p ρ k − p , k = 1 , 2 , … , p \rho_k = \varphi_1 \rho_{k-1} + \varphi_2 \rho_{k-2} + \cdots + \varphi_p \rho_{k-p}, \quad k = 1, 2, \ldots, p ρ k = φ 1 ρ k − 1 + φ 2 ρ k − 2 + ⋯ + φ p ρ k − p , k = 1 , 2 , … , p 行列形式にまとめると:
( ρ 1 ρ 2 ⋮ ρ p ) = ( 1 ρ 1 ⋯ ρ p − 1 ρ 1 1 ⋯ ρ p − 2 ⋮ ⋱ ⋮ ρ p − 1 ρ p − 2 ⋯ 1 ) ( φ 1 φ 2 ⋮ φ p ) \begin{pmatrix} \rho_1 \\ \rho_2 \\ \vdots \\ \rho_p \end{pmatrix}
=
\begin{pmatrix}
1 & \rho_1 & \cdots & \rho_{p-1}\\
\rho_1 & 1 & \cdots & \rho_{p-2}\\
\vdots & & \ddots & \vdots\\
\rho_{p-1} & \rho_{p-2} & \cdots & 1
\end{pmatrix}
\begin{pmatrix} \varphi_1 \\ \varphi_2 \\ \vdots \\ \varphi_p \end{pmatrix} ρ 1 ρ 2 ⋮ ρ p = 1 ρ 1 ⋮ ρ p − 1 ρ 1 1 ρ p − 2 ⋯ ⋯ ⋱ ⋯ ρ p − 1 ρ p − 2 ⋮ 1 φ 1 φ 2 ⋮ φ p 要するに「ACFのデータさえあれば、AR係数が線形方程式を解くだけで推定できる 」。この推定量をYule-Walker推定量 と呼びます。係数行列はToeplitz行列(各対角線上の要素が同じ)であり効率的に解けます。
AR(1)では ρ 1 = φ \rho_1 = \varphi ρ 1 = φ
φ 1 = ρ 1 ( 1 − ρ 2 ) 1 − ρ 1 2 , φ 2 = ρ 2 − ρ 1 2 1 − ρ 1 2 \varphi_1 = \frac{\rho_1(1-\rho_2)}{1-\rho_1^2}, \quad \varphi_2 = \frac{\rho_2 - \rho_1^2}{1-\rho_1^2} φ 1 = 1 − ρ 1 2 ρ 1 ( 1 − ρ 2 ) , φ 2 = 1 − ρ 1 2 ρ 2 − ρ 1 2 1級では上記の行列方程式を立てて φ \varphi φ
9. 単位根検定 — ADF検定の概念
X t X_t X t I ( 1 ) I(1) I ( 1 ) 単位根検定 です。
AR(1)モデルを変形します。X t = φ X t − 1 + ε t X_t = \varphi X_{t-1} + \varepsilon_t X t = φ X t − 1 + ε t ∇ X t = X t − X t − 1 = ( φ − 1 ) X t − 1 + ε t \nabla X_t = X_t - X_{t-1} = (\varphi - 1) X_{t-1} + \varepsilon_t ∇ X t = X t − X t − 1 = ( φ − 1 ) X t − 1 + ε t δ = φ − 1 \delta = \varphi - 1 δ = φ − 1
∇ X t = δ X t − 1 + ε t \nabla X_t = \delta X_{t-1} + \varepsilon_t ∇ X t = δ X t − 1 + ε t 帰無仮説:H 0 : δ = 0 H_0: \delta = 0 H 0 : δ = 0 = φ = 1 = \varphi = 1 = φ = 1 H 1 : δ < 0 H_1: \delta < 0 H 1 : δ < 0 = φ < 1 = \varphi < 1 = φ < 1
通常のt検定の分布ではなくDickey-Fuller分布 (非標準)が使われます。これを一般化してAR(p)に拡張したものがADF(Augmented Dickey-Fuller)検定 。
∇ X t = δ X t − 1 + ∑ j = 1 p − 1 γ j ∇ X t − j + ε t \nabla X_t = \delta X_{t-1} + \sum_{j=1}^{p-1} \gamma_j \nabla X_{t-j} + \varepsilon_t ∇ X t = δ X t − 1 + j = 1 ∑ p − 1 γ j ∇ X t − j + ε t 要するに「単位根検定は δ = 0 \delta=0 δ = 0 」。通常のt分布より左裾が厚いため、有意性の棄却域も通常の検定と違います。検定統計量が十分に負なら帰無仮説(単位根)を棄却し「定常」と判断します。
試験での問われ方(級ごとの差)
準1級での出題傾向
AR(1)の定常条件・平均・分散・自己相関の公式と、ACF/PACFによるモデル同定の表が中心。差分・ARIMAの枠組みと季節性の概念。
定常性の3条件の定義 (平均一定・分散一定・自己共分散がラグのみに依存)を答えさせる。AR(1)の定常条件 :∣ φ ∣ < 1 \lvert\varphi\rvert < 1 ∣ φ ∣ < 1 γ 0 = σ 2 / ( 1 − φ 2 ) \gamma_0 = \sigma^2/(1-\varphi^2) γ 0 = σ 2 / ( 1 − φ 2 ) AR(1)の自己相関 ρ k = φ k \rho_k = \varphi^k ρ k = φ k φ = 0.8 \varphi=0.8 φ = 0.8 ρ 2 = 0.64 \rho_2=0.64 ρ 2 = 0.64 同定の表 (上表)を使い、与えられたACF・PACFのコレログラムからモデルを特定する択一問題。ARIMA(p,d,q)の意味(p , d , q p,d,q p , d , q
MA(q)は常に定常であることの理由の説明。
1級での出題傾向
Yule-Walker方程式の行列形式・AR推定量の導出・予測の理論・スペクトル密度(範囲表改訂の可能性があるため要最新確認 )。
Yule-Walker方程式を導出 (両辺に X t − k X_{t-k} X t − k φ \varphi φ AR(2)の Yule-Walker 推定量の計算(上式を代入して数値を求める)。
最小2乗推定・尤度推定 との対比、各推定量の大標本性質(一致性・漸近正規性)。h h h X ^ t + h ∣ t = E [ X t + h ∣ X t , X t − 1 , … ] \hat{X}_{t+h\mid t} = E[X_{t+h}\mid X_t, X_{t-1},\ldots] X ^ t + h ∣ t = E [ X t + h ∣ X t , X t − 1 , … ] X ^ t + h = φ h X t \hat{X}_{t+h} = \varphi^h X_t X ^ t + h = φ h X t ADF検定の検定統計量と棄却域(通常t分布との違い)。
スペクトル密度とACFのフーリエ変換による対応(Wiener-Khinchinの定理)の概念。
10. 引っかけ・頻出論点
⚠️ ARとMAのACF/PACFを逆に覚える :「ARはPACFが切れ、MAはACFが切れる」。「ACFが p p p q q q P ACF = A R、A CF = M A → PA=AM(“パ”と”AM”で覚える)」。
⚠️ 定常条件の方向の混乱 :「特性根が単位円外」=∣ z ∣ > 1 \lvert z\rvert > 1 ∣ z ∣ > 1 ∣ φ ∣ < 1 \lvert\varphi\rvert < 1 ∣ φ ∣ < 1 ∣ φ ∣ > 1 \lvert\varphi\rvert > 1 ∣ φ ∣ > 1
⚠️ MA過程の分散にAR次数を代入 :MA(q)の分散は σ 2 ∑ j = 0 q θ j 2 \sigma^2 \sum_{j=0}^{q} \theta_j^2 σ 2 ∑ j = 0 q θ j 2 σ 2 / ( 1 − φ 2 ) \sigma^2/(1-\varphi^2) σ 2 / ( 1 − φ 2 )
⚠️ ρ k \rho_k ρ k φ k \varphi^k φ k γ k = φ k γ 0 \gamma_k = \varphi^k \gamma_0 γ k = φ k γ 0 γ 0 \gamma_0 γ 0
⚠️ ARIMAの d d d :d = 1 d=1 d = 1
⚠️ 単位根検定は通常t分布ではない :H 0 H_0 H 0
よくある疑問(Q&A)
Q1. 「弱定常」と「強定常」はどう違いますか?どちらを使えばよいですか?
強定常は「任意の時点の集合 ( t 1 , … , t k ) (t_1,\ldots,t_k) ( t 1 , … , t k ) ( X t 1 , … , X t k ) (X_{t_1},\ldots,X_{t_k}) ( X t 1 , … , X t k ) τ \tau τ モーメント(1次・2次)のみ に条件を課します。実用上は弱定常が主に使われます。正規過程(任意有限次元分布が正規)では2次モーメントが分布全体を決めるので、弱定常と強定常が同値になります。試験で「定常」と言われたら、文脈がなければ弱定常を指します。
Q2. AR(1)で φ = 1 \varphi = 1 φ = 1
φ = 1 \varphi=1 φ = 1 γ 0 = σ 2 / ( 1 − 1 2 ) \gamma_0 = \sigma^2/(1-1^2) γ 0 = σ 2 / ( 1 − 1 2 ) X t = X t − 1 + ε t X_t = X_{t-1} + \varepsilon_t X t = X t − 1 + ε t X t = X 0 + ∑ s = 1 t ε s X_t = X_0 + \sum_{s=1}^{t}\varepsilon_s X t = X 0 + ∑ s = 1 t ε s V a r ( X t ) = t σ 2 \mathrm{Var}(X_t) = t\sigma^2 Var ( X t ) = t σ 2 時間とともに無限に大きくなり 、定常性の条件(分散一定)が破れます。
Q3. ACFのラグq q q
コレログラム(棒グラフ形式のACFプロット)を見て、**ラグ q q q q + 1 q+1 q + 1 ρ k = 0 \rho_k = 0 ρ k = 0 ± 1.96 / n \pm 1.96/\sqrt{n} ± 1.96/ n
Q4. ARMA(p,q)はACFもPACFも打ち切れないとすると、どうやって次数を決めるのですか?
ARMAの場合は情報量基準 (AICやBIC)で決めます。A I C = − 2 log L + 2 ( p + q + 1 ) \mathrm{AIC} = -2\log L + 2(p+q+1) AIC = − 2 log L + 2 ( p + q + 1 ) L L L p , q p,q p , q log n ⋅ ( p + q + 1 ) \log n \cdot (p+q+1) log n ⋅ ( p + q + 1 )
Q5. ARIMA(0,1,0)とランダムウォークは同じですか?
はい、同じです。∇ X t = ε t \nabla X_t = \varepsilon_t ∇ X t = ε t X t = X t − 1 + ε t X_t = X_{t-1} + \varepsilon_t X t = X t − 1 + ε t X t = X t − 1 + c + ε t X_t = X_{t-1} + c + \varepsilon_t X t = X t − 1 + c + ε t
まとめ
定常性の3条件 :平均一定・分散一定・自己共分散はラグのみに依存。これが崩れるときは差分で定常化する(d d d AR(1)の基礎 :μ = c / ( 1 − φ ) \mu = c/(1-\varphi) μ = c / ( 1 − φ ) γ 0 = σ 2 / ( 1 − φ 2 ) \gamma_0 = \sigma^2/(1-\varphi^2) γ 0 = σ 2 / ( 1 − φ 2 ) ρ k = φ k \rho_k = \varphi^k ρ k = φ k ∣ φ ∣ < 1 \lvert\varphi\rvert < 1 ∣ φ ∣ < 1 モデル同定の鉄則 :AR → PACFが p p p q q q Yule-Walker方程式 (1級):ACFからARパラメータを求める線形方程式系。k = 1 , … , p k=1,\ldots,p k = 1 , … , p ρ k = ∑ i = 1 p φ i ρ k − i \rho_k = \sum_{i=1}^{p}\varphi_i \rho_{k-i} ρ k = ∑ i = 1 p φ i ρ k − i ADF単位根検定 :H 0 H_0 H 0
関連ノート