← 統計検定テキスト 一覧
📊 対象級:1級 | 重要度:A(頻出)
要点(BLUF)
線形回帰モデル y = X β + ε y=X\beta+\varepsilon y = X β + ε 古典的仮定 (誤差の期待値0・等分散・無相関・説明変数は full rank)を置くと、最小二乗推定量(OLS)
β ^ = ( X ⊤ X ) − 1 X ⊤ y \hat\beta=(X^\top X)^{-1}X^\top y β ^ = ( X ⊤ X ) − 1 X ⊤ y が最良線形不偏推定量(BLUE:Best Linear Unbiased Estimator)になります。これが ガウス・マルコフの定理 です。
E ( ε ) = 0 , V a r ( ε ) = σ 2 I ⟹ β ^ = ( X ⊤ X ) − 1 X ⊤ y は BLUE \boxed{\;
\mathrm{E}(\varepsilon)=0,\ \ \mathrm{Var}(\varepsilon)=\sigma^2 I
\ \Longrightarrow\
\hat\beta=(X^\top X)^{-1}X^\top y\ \text{は BLUE}
\;} E ( ε ) = 0 , Var ( ε ) = σ 2 I ⟹ β ^ = ( X ⊤ X ) − 1 X ⊤ y は BLUE 要するに「線形かつ不偏な推定量の中で、OLS が一番ばらつき(分散)が小さい 」。重要なのは、ここに正規性は要らない こと。仮定は2次(分散・共分散)までで十分です。
ところが現実には等分散・無相関が崩れます(不均一分散・系列相関)。このとき V a r ( ε ) = σ 2 Ω \mathrm{Var}(\varepsilon)=\sigma^2\Omega Var ( ε ) = σ 2 Ω Ω ≠ I \Omega\neq I Ω = I 依然として不偏だが、もはや BLUE ではない(非効率) 。さらに OLS の標準誤差の式が壊れ、検定・信頼区間が誤ります。この場合に BLUE を回復するのが**一般化最小二乗法(GLS)**です。
V a r ( ε ) = σ 2 Ω ⟹ β ^ G L S = ( X ⊤ Ω − 1 X ) − 1 X ⊤ Ω − 1 y が BLUE \boxed{\;
\mathrm{Var}(\varepsilon)=\sigma^2\Omega
\ \Longrightarrow\
\hat\beta_{\mathrm{GLS}}=(X^\top \Omega^{-1}X)^{-1}X^\top \Omega^{-1}y\ \text{が BLUE}
\;} Var ( ε ) = σ 2 Ω ⟹ β ^ GLS = ( X ⊤ Ω − 1 X ) − 1 X ⊤ Ω − 1 y が BLUE GLS は「Ω − 1 / 2 \Omega^{-1/2} Ω − 1/2 要最新確認 )。
1. 線形回帰モデルと古典的仮定
ガウス・マルコフの定理の主張を正確に書くには、まずどんな仮定の下での話か を厳密に押さえる必要があります。これらの仮定こそが定理の前提条件であり、後で「どれが崩れると何が起きるか」を整理する基礎になります。
観測を n n n k k k
y = X β + ε , y ∈ R n , X ∈ R n × k , β ∈ R k , ε ∈ R n y=X\beta+\varepsilon,\qquad
y\in\mathbb{R}^{n},\ X\in\mathbb{R}^{n\times k},\ \beta\in\mathbb{R}^{k},\ \varepsilon\in\mathbb{R}^{n} y = X β + ε , y ∈ R n , X ∈ R n × k , β ∈ R k , ε ∈ R n と書きます。要するに「観測ベクトル y y y X X X β \beta β ε \varepsilon ε
# 仮定 数式 意味 (A1) 線形性 y = X β + ε y=X\beta+\varepsilon y = X β + ε モデルが係数 β \beta β (A2) 誤差の期待値0 E ( ε ) = 0 \mathrm{E}(\varepsilon)=0 E ( ε ) = 0 系統的なズレがない(外生性の最小限) (A3) 等分散・無相関 V a r ( ε ) = σ 2 I \mathrm{Var}(\varepsilon)=\sigma^2 I Var ( ε ) = σ 2 I 各誤差の分散が一定 σ 2 \sigma^2 σ 2 (A4) 非確率・full rank X X X r a n k ( X ) = k \mathrm{rank}(X)=k rank ( X ) = k X ⊤ X X^\top X X ⊤ X
(A3) を成分で書くと意味がはっきりします。
V a r ( ε ) = σ 2 I ⟺ V a r ( ε i ) = σ 2 ( すべての i ) , C o v ( ε i , ε j ) = 0 ( i ≠ j ) \mathrm{Var}(\varepsilon)=\sigma^2 I
\iff
\mathrm{Var}(\varepsilon_i)=\sigma^2\ (\text{すべての } i),\quad
\mathrm{Cov}(\varepsilon_i,\varepsilon_j)=0\ (i\neq j) Var ( ε ) = σ 2 I ⟺ Var ( ε i ) = σ 2 ( すべての i ) , Cov ( ε i , ε j ) = 0 ( i = j ) 要するに「全部の誤差が同じばらつきを持ち(等分散・homoscedastic)、互いに相関しない(無相関) 」。この2つがセットで、共分散行列が σ 2 \sigma^2 σ 2
(A4) の full rank は、X ⊤ X X^\top X X ⊤ X ( X ⊤ X ) − 1 (X^\top X)^{-1} ( X ⊤ X ) − 1 重回帰分析 を参照)。
正規性は仮定に入っていない ことに注意。ε ∼ N ( 0 , σ 2 I ) \varepsilon\sim N(0,\sigma^2 I) ε ∼ N ( 0 , σ 2 I ) ガウス・マルコフの定理には不要 です。正規性が要るのは「β ^ \hat\beta β ^ 全不偏推定量の中で 最良(UMVUE)」と言いたいときや、t t t F F F 線形 不偏の中で最良」であり、2次までの仮定(A1〜A4)だけで成立します。
2. OLS推定量とその基本性質
定理の証明に入る前に、OLS が満たす2つの性質——線形であること と不偏であること ——を確認します。BLUE の “L”(線形)と “U”(不偏)に対応します。
2.1 OLS推定量の導出
OLS は残差平方和 S ( β ) = ( y − X β ) ⊤ ( y − X β ) S(\beta)=(y-X\beta)^\top(y-X\beta) S ( β ) = ( y − X β ) ⊤ ( y − X β ) β \beta β β \beta β
∂ S ∂ β = − 2 X ⊤ ( y − X β ) = 0 ⟹ X ⊤ X β ^ = X ⊤ y ⟹ β ^ = ( X ⊤ X ) − 1 X ⊤ y \frac{\partial S}{\partial \beta}=-2X^\top(y-X\beta)=0
\ \Longrightarrow\
X^\top X\,\hat\beta=X^\top y
\ \Longrightarrow\
\hat\beta=(X^\top X)^{-1}X^\top y ∂ β ∂ S = − 2 X ⊤ ( y − X β ) = 0 ⟹ X ⊤ X β ^ = X ⊤ y ⟹ β ^ = ( X ⊤ X ) − 1 X ⊤ y 要するに「残差平方和が最小になる係数を解いた結果がこの式」。導出の詳細は単回帰・重回帰のノート(単回帰分析 、重回帰分析 )に譲り、ここでは結果を使います。
2.2 線形性
β ^ \hat\beta β ^ y y y C : = ( X ⊤ X ) − 1 X ⊤ C:=(X^\top X)^{-1}X^\top C := ( X ⊤ X ) − 1 X ⊤ k × n k\times n k × n X X X
β ^ = C y , C = ( X ⊤ X ) − 1 X ⊤ \hat\beta=Cy,\qquad C=(X^\top X)^{-1}X^\top β ^ = C y , C = ( X ⊤ X ) − 1 X ⊤ 要するに「β ^ \hat\beta β ^ y y y C C C y y y C C C
C X = ( X ⊤ X ) − 1 X ⊤ X = I k CX=(X^\top X)^{-1}X^\top X=I_k C X = ( X ⊤ X ) − 1 X ⊤ X = I k という重要な性質を満たします(後の証明で使う)。要するに「C C C X X X
2.3 不偏性
β ^ \hat\beta β ^ y = X β + ε y=X\beta+\varepsilon y = X β + ε E ( ε ) = 0 \mathrm{E}(\varepsilon)=0 E ( ε ) = 0
E ( β ^ ) = E [ C ( X β + ε ) ] = C X β + C E ( ε ) = I k β + 0 = β \mathrm{E}(\hat\beta)=\mathrm{E}\big[C(X\beta+\varepsilon)\big]
=CX\beta+C\,\mathrm{E}(\varepsilon)
=I_k\beta+0=\beta E ( β ^ ) = E [ C ( X β + ε ) ] = C X β + C E ( ε ) = I k β + 0 = β 要するに「OLS の期待値は真の係数 β \beta β 」。これが BLUE の “Unbiased”。点推定量の不偏性の一般論は 点推定(推定量の良さ:不偏性・一致性・有効性・十分性) を参照。
2.4 OLSの分散共分散行列
「最良(最小分散)」を論じる準備として、OLS の分散を計算します。β ^ − β = C ε \hat\beta-\beta=C\varepsilon β ^ − β = C ε V a r ( ε ) = σ 2 I \mathrm{Var}(\varepsilon)=\sigma^2 I Var ( ε ) = σ 2 I
V a r ( β ^ ) = V a r ( C ε ) = C V a r ( ε ) C ⊤ = C ( σ 2 I ) C ⊤ = σ 2 C C ⊤ \mathrm{Var}(\hat\beta)=\mathrm{Var}(C\varepsilon)=C\,\mathrm{Var}(\varepsilon)\,C^\top
=C(\sigma^2 I)C^\top=\sigma^2 CC^\top Var ( β ^ ) = Var ( C ε ) = C Var ( ε ) C ⊤ = C ( σ 2 I ) C ⊤ = σ 2 C C ⊤ C C ⊤ = ( X ⊤ X ) − 1 X ⊤ X ( X ⊤ X ) − 1 = ( X ⊤ X ) − 1 CC^\top=(X^\top X)^{-1}X^\top X (X^\top X)^{-1}=(X^\top X)^{-1} C C ⊤ = ( X ⊤ X ) − 1 X ⊤ X ( X ⊤ X ) − 1 = ( X ⊤ X ) − 1
V a r ( β ^ ) = σ 2 ( X ⊤ X ) − 1 \boxed{\;\mathrm{Var}(\hat\beta)=\sigma^2 (X^\top X)^{-1}\;} Var ( β ^ ) = σ 2 ( X ⊤ X ) − 1 要するに「OLS のばらつきは σ 2 ( X ⊤ X ) − 1 \sigma^2(X^\top X)^{-1} σ 2 ( X ⊤ X ) − 1 」。ガウス・マルコフの定理は、これが「あらゆる線形不偏推定量の分散の中で最小(行列の意味で)」と主張します。
3. ガウス・マルコフの定理:証明
ここが本ノートの核心です。**任意の線形不偏推定量の分散共分散行列が、OLS の分散共分散行列より「大きい」(差が半正定値)**ことを省略なく示します。
3.1 主張の正確な定式化
OLS 以外の任意の線形 推定量を β ~ = A y \tilde\beta=Ay β ~ = A y A A A k × n k\times n k × n β ~ \tilde\beta β ~ 不偏 であるとき、
V a r ( β ~ ) − V a r ( β ^ ) は半正定値(positive semidefinite) \mathrm{Var}(\tilde\beta)-\mathrm{Var}(\hat\beta)\ \text{は半正定値(positive semidefinite)} Var ( β ~ ) − Var ( β ^ ) は半正定値( positive semidefinite ) これが定理の主張です。「分散行列の差が半正定値」が何を意味するかを明確にしておきます。任意の定数ベクトル ℓ ∈ R k \ell\in\mathbb{R}^k ℓ ∈ R k ℓ ⊤ [ V a r ( β ~ ) − V a r ( β ^ ) ] ℓ ≥ 0 \ell^\top[\mathrm{Var}(\tilde\beta)-\mathrm{Var}(\hat\beta)]\ell\ge0 ℓ ⊤ [ Var ( β ~ ) − Var ( β ^ )] ℓ ≥ 0
V a r ( ℓ ⊤ β ~ ) ≥ V a r ( ℓ ⊤ β ^ ) ( 任意の ℓ ) \mathrm{Var}(\ell^\top\tilde\beta)\ \ge\ \mathrm{Var}(\ell^\top\hat\beta)\quad(\text{任意の } \ell) Var ( ℓ ⊤ β ~ ) ≥ Var ( ℓ ⊤ β ^ ) ( 任意の ℓ ) 要するに「係数のどんな線形結合 ℓ ⊤ β \ell^\top\beta ℓ ⊤ β 」。ℓ \ell ℓ β ^ j \hat\beta_j β ^ j
3.2 不偏性が課す制約(鍵となる条件 A X = I AX=I A X = I
β ~ = A y \tilde\beta=Ay β ~ = A y
E ( β ~ ) = E [ A ( X β + ε ) ] = A X β + A E ( ε ) = A X β \mathrm{E}(\tilde\beta)=\mathrm{E}\big[A(X\beta+\varepsilon)\big]=AX\beta+A\,\mathrm{E}(\varepsilon)=AX\beta E ( β ~ ) = E [ A ( X β + ε ) ] = A X β + A E ( ε ) = A X β これが任意の β \beta β β \beta β
A X β = β ( ∀ β ) ⟹ A X = I k AX\beta=\beta\ (\forall\beta)\ \Longrightarrow\ \boxed{\,AX=I_k\,} A X β = β ( ∀ β ) ⟹ A X = I k 要するに「線形推定量 A y Ay A y ⟺ A X = I k \iff AX=I_k ⟺ A X = I k 」。OLS の C C C C X = I k CX=I_k C X = I k
3.3 差分行列の導入と分散の分解
A A A C C C
D : = A − C = A − ( X ⊤ X ) − 1 X ⊤ , すなわち A = C + D D:=A-C=A-(X^\top X)^{-1}X^\top,\qquad \text{すなわち}\quad A=C+D D := A − C = A − ( X ⊤ X ) − 1 X ⊤ , すなわち A = C + D 要するに「任意の線形不偏推定量 A A A C C C D D D D D D A X = I k AX=I_k A X = I k C X = I k CX=I_k C X = I k
D X = ( A − C ) X = A X − C X = I k − I k = 0 ⟹ D X = 0 DX=(A-C)X=AX-CX=I_k-I_k=0
\quad\Longrightarrow\quad \boxed{\,DX=0\,} D X = ( A − C ) X = A X − C X = I k − I k = 0 ⟹ D X = 0 要するに「不偏という制約が、ズレ D D D D X = 0 DX=0 D X = 0 」。これが証明全体を回す鍵です。
次に β ~ = A y \tilde\beta=Ay β ~ = A y β ~ \tilde\beta β ~ β ~ − β = A ε \tilde\beta-\beta=A\varepsilon β ~ − β = A ε
V a r ( β ~ ) = A V a r ( ε ) A ⊤ = σ 2 A A ⊤ \mathrm{Var}(\tilde\beta)=A\,\mathrm{Var}(\varepsilon)\,A^\top=\sigma^2 AA^\top Var ( β ~ ) = A Var ( ε ) A ⊤ = σ 2 A A ⊤ ここに A = C + D A=C+D A = C + D
A A ⊤ = ( C + D ) ( C + D ) ⊤ = C C ⊤ + C D ⊤ + D C ⊤ + D D ⊤ AA^\top=(C+D)(C+D)^\top
=CC^\top+CD^\top+DC^\top+DD^\top A A ⊤ = ( C + D ) ( C + D ) ⊤ = C C ⊤ + C D ⊤ + D C ⊤ + D D ⊤ クロス項 C D ⊤ CD^\top C D ⊤ D C ⊤ DC^\top D C ⊤ D X = 0 DX=0 D X = 0 C = ( X ⊤ X ) − 1 X ⊤ C=(X^\top X)^{-1}X^\top C = ( X ⊤ X ) − 1 X ⊤
C D ⊤ = ( X ⊤ X ) − 1 X ⊤ D ⊤ = ( X ⊤ X ) − 1 ( D X ) ⊤ = ( X ⊤ X ) − 1 ⋅ 0 ⊤ = 0 CD^\top=(X^\top X)^{-1}X^\top D^\top=(X^\top X)^{-1}(DX)^\top=(X^\top X)^{-1}\cdot 0^\top=0 C D ⊤ = ( X ⊤ X ) − 1 X ⊤ D ⊤ = ( X ⊤ X ) − 1 ( D X ) ⊤ = ( X ⊤ X ) − 1 ⋅ 0 ⊤ = 0 同様に D C ⊤ = ( D C ⊤ ) DC^\top=(DC^\top) D C ⊤ = ( D C ⊤ ) D C ⊤ = D X ( X ⊤ X ) − 1 = 0 ⋅ ( X ⊤ X ) − 1 = 0 DC^\top=D X(X^\top X)^{-1}=0\cdot(X^\top X)^{-1}=0 D C ⊤ = D X ( X ⊤ X ) − 1 = 0 ⋅ ( X ⊤ X ) − 1 = 0 不偏制約 D X = 0 DX=0 D X = 0 C C C D D D 」。したがって
A A ⊤ = C C ⊤ + D D ⊤ = ( X ⊤ X ) − 1 + D D ⊤ AA^\top=CC^\top+DD^\top=(X^\top X)^{-1}+DD^\top A A ⊤ = C C ⊤ + D D ⊤ = ( X ⊤ X ) − 1 + D D ⊤ 両辺に σ 2 \sigma^2 σ 2
V a r ( β ~ ) = σ 2 A A ⊤ = σ 2 ( X ⊤ X ) − 1 ⏟ = V a r ( β ^ ) + σ 2 D D ⊤ \mathrm{Var}(\tilde\beta)=\sigma^2 AA^\top
=\underbrace{\sigma^2(X^\top X)^{-1}}_{=\,\mathrm{Var}(\hat\beta)}+\sigma^2 DD^\top Var ( β ~ ) = σ 2 A A ⊤ = = Var ( β ^ ) σ 2 ( X ⊤ X ) − 1 + σ 2 D D ⊤ 3.4 差は半正定値(結論)
移項すると
V a r ( β ~ ) − V a r ( β ^ ) = σ 2 D D ⊤ \boxed{\;\mathrm{Var}(\tilde\beta)-\mathrm{Var}(\hat\beta)=\sigma^2 DD^\top\;} Var ( β ~ ) − Var ( β ^ ) = σ 2 D D ⊤ ここで D D ⊤ DD^\top D D ⊤ D D D 半正定値 です(グラム行列)。実際、任意のベクトル ℓ \ell ℓ
ℓ ⊤ ( D D ⊤ ) ℓ = ( D ⊤ ℓ ) ⊤ ( D ⊤ ℓ ) = ∥ D ⊤ ℓ ∥ 2 ≥ 0 \ell^\top(DD^\top)\ell=(D^\top\ell)^\top(D^\top\ell)=\lVert D^\top\ell\rVert^2\ \ge\ 0 ℓ ⊤ ( D D ⊤ ) ℓ = ( D ⊤ ℓ ) ⊤ ( D ⊤ ℓ ) = ∥ D ⊤ ℓ ∥ 2 ≥ 0 要するに「D D ⊤ DD^\top D D ⊤ σ 2 > 0 \sigma^2>0 σ 2 > 0 σ 2 D D ⊤ \sigma^2 DD^\top σ 2 D D ⊤
V a r ( β ~ ) − V a r ( β ^ ) ⪰ 0 \mathrm{Var}(\tilde\beta)-\mathrm{Var}(\hat\beta)\ \succeq\ 0 Var ( β ~ ) − Var ( β ^ ) ⪰ 0 すなわち任意の線形不偏推定量 β ~ \tilde\beta β ~ 。これでガウス・マルコフの定理が証明できました。
等号が成り立つ(OLS と分散が完全に一致する)のは D ⊤ ℓ = 0 D^\top\ell=0 D ⊤ ℓ = 0 ℓ \ell ℓ D = 0 D=0 D = 0 A = C A=C A = C OLS と同じ分散を達成する線形不偏推定量は OLS だけ 」。この意味で OLS は線形不偏クラスにおいて一意 の最良推定量です。
4. 古典的仮定が崩れるとき
ガウス・マルコフの定理が効くのは (A1)〜(A4) が全部成り立つときだけ。現実には特に (A3) 等分散・無相関 がよく崩れます。崩れ方は2つです。
4.1 不均一分散(heteroskedasticity)と系列相関
(A3) が崩れると、共分散行列は単位行列の定数倍ではなくなり、一般に
V a r ( ε ) = σ 2 Ω , Ω は既知の正定値対称行列( Ω ≠ I ) \mathrm{Var}(\varepsilon)=\sigma^2\Omega,\qquad \Omega\ \text{は既知の正定値対称行列}(\Omega\neq I) Var ( ε ) = σ 2 Ω , Ω は既知の正定値対称行列 ( Ω = I ) と書けます。代表的な崩れ方:
不均一分散 :分散が観測ごとに違う(V a r ( ε i ) = σ i 2 \mathrm{Var}(\varepsilon_i)=\sigma_i^2 Var ( ε i ) = σ i 2 Ω \Omega Ω 対角行列 だが対角成分が一定でない。横断面データ(所得が大きいほど誤差も大きい等)で典型的。系列相関(自己相関) :誤差が互いに相関する(C o v ( ε i , ε j ) ≠ 0 \mathrm{Cov}(\varepsilon_i,\varepsilon_j)\neq0 Cov ( ε i , ε j ) = 0 Ω \Omega Ω 非対角成分を持つ 。時系列データで典型的(計量時系列の発展(単位根・共和分・ARCH/GARCH) で扱う AR 誤差など)。残差から崩れを診断する手順は 残差分析・回帰診断 を参照。
4.2 このとき OLS に何が起きるか(不偏だが非効率・標準誤差が誤る)
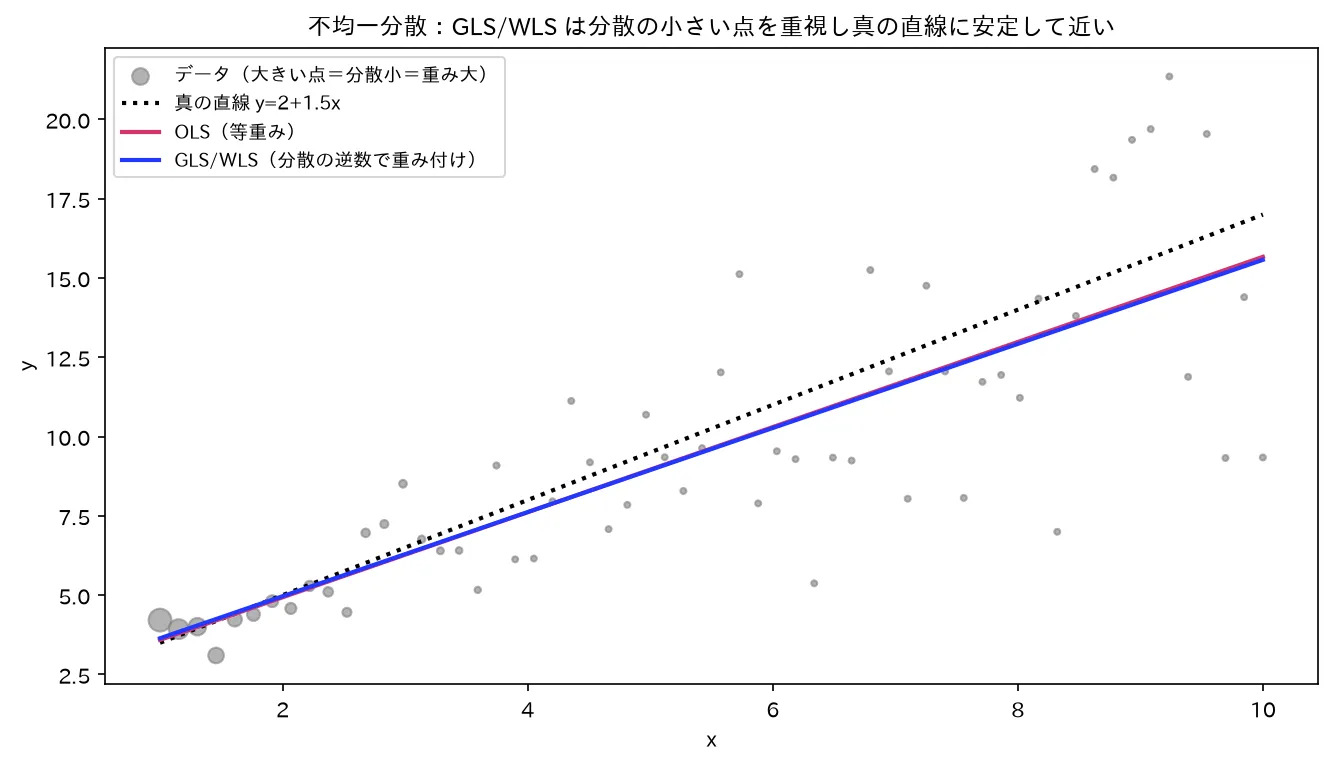
不均一分散では OLS(赤)は分散の大きい点に引っ張られ非効率。GLS/WLS(青)は分散の逆数で重み付けし精度の高い点を重視、真の直線(黒点線)に安定して近い。図は simulations/gls_vs_ols_keijou.py で生成。
ここは1級の頻出論点なので正確に整理します。V a r ( ε ) = σ 2 Ω \mathrm{Var}(\varepsilon)=\sigma^2\Omega Var ( ε ) = σ 2 Ω β ^ = C y \hat\beta=Cy β ^ = C y
(i) 不偏性は保たれる。 不偏性の証明(2.3節)で使ったのは E ( ε ) = 0 \mathrm{E}(\varepsilon)=0 E ( ε ) = 0
E ( β ^ ) = β ( 依然として不偏 ) \mathrm{E}(\hat\beta)=\beta\quad(\text{依然として不偏}) E ( β ^ ) = β ( 依然として不偏 ) 要するに「等分散・無相関が崩れても、OLS は相変わらず的を外さない(不偏) 」。
(ii) しかし非効率(もはや BLUE でない)。 OLS の真の分散は (A3) が崩れたので σ 2 ( X ⊤ X ) − 1 \sigma^2(X^\top X)^{-1} σ 2 ( X ⊤ X ) − 1
V a r ( β ^ ) = C V a r ( ε ) C ⊤ = σ 2 C Ω C ⊤ = σ 2 ( X ⊤ X ) − 1 X ⊤ Ω X ( X ⊤ X ) − 1 \mathrm{Var}(\hat\beta)=C\,\mathrm{Var}(\varepsilon)\,C^\top=\sigma^2 C\Omega C^\top
=\sigma^2(X^\top X)^{-1}X^\top \Omega X(X^\top X)^{-1} Var ( β ^ ) = C Var ( ε ) C ⊤ = σ 2 C Ω C ⊤ = σ 2 ( X ⊤ X ) − 1 X ⊤ Ω X ( X ⊤ X ) − 1 これは後述の GLS の分散より(半正定値の意味で)大きい 。要するに「OLS はまだ不偏だが、もっとばらつきの小さい推定量(GLS)が存在する=OLS は無駄にばらついている=非効率 」。
(iii) 標準誤差の式が壊れる(検定・信頼区間が誤る)。 最も実務的に危険なのはこれです。ソフトウェアが既定で出す OLS の分散推定 σ ^ 2 ( X ⊤ X ) − 1 \hat\sigma^2(X^\top X)^{-1} σ ^ 2 ( X ⊤ X ) − 1 真の分散 σ 2 C Ω C ⊤ \sigma^2 C\Omega C^\top σ 2 C Ω C ⊤
σ ^ 2 ( X ⊤ X ) − 1 ≠ σ 2 ( X ⊤ X ) − 1 X ⊤ Ω X ( X ⊤ X ) − 1 \hat\sigma^2(X^\top X)^{-1}\ \neq\ \sigma^2(X^\top X)^{-1}X^\top\Omega X(X^\top X)^{-1} σ ^ 2 ( X ⊤ X ) − 1 = σ 2 ( X ⊤ X ) − 1 X ⊤ Ω X ( X ⊤ X ) − 1 要するに「標準誤差を間違って計算する → t t t p p p 」。点推定は当たっているのに、その精度の見積もりが嘘になる のが不均一分散の本当の怖さです。対処は2系統:
崩れの構造を直す :Ω \Omega Ω GLS/WLS で BLUE を回復する(次節・本ノートの主題)。標準誤差だけ直す :OLS の点推定はそのまま使い、分散推定だけを σ 2 C Ω C ⊤ \sigma^2 C\Omega C^\top σ 2 C Ω C ⊤ Ω \Omega Ω n n n
5. 一般化最小二乗法(GLS)
V a r ( ε ) = σ 2 Ω \mathrm{Var}(\varepsilon)=\sigma^2\Omega Var ( ε ) = σ 2 Ω Ω \Omega Ω 一般化最小二乗法(GLS) 、別名 Aitken 推定量 です。核心は「Ω − 1 / 2 \Omega^{-1/2} Ω − 1/2
5.1 Ω − 1 / 2 \Omega^{-1/2} Ω − 1/2
Ω \Omega Ω Ω 1 / 2 \Omega^{1/2} Ω 1/2 Ω 1 / 2 Ω 1 / 2 = Ω \Omega^{1/2}\Omega^{1/2}=\Omega Ω 1/2 Ω 1/2 = Ω Ω 1 / 2 \Omega^{1/2} Ω 1/2 Ω − 1 / 2 \Omega^{-1/2} Ω − 1/2 Ω = Q Λ Q ⊤ \Omega=Q\Lambda Q^\top Ω = Q Λ Q ⊤ Ω 1 / 2 = Q Λ 1 / 2 Q ⊤ \Omega^{1/2}=Q\Lambda^{1/2}Q^\top Ω 1/2 = Q Λ 1/2 Q ⊤ 多変量正規分布 参照)。これを使ってモデル全体を左から掛けます(変換 )。
Ω − 1 / 2 y ⏟ = : y ∗ = Ω − 1 / 2 X ⏟ = : X ∗ β + Ω − 1 / 2 ε ⏟ = : ε ∗ ⟺ y ∗ = X ∗ β + ε ∗ \underbrace{\Omega^{-1/2}y}_{=:y^\ast}=\underbrace{\Omega^{-1/2}X}_{=:X^\ast}\beta+\underbrace{\Omega^{-1/2}\varepsilon}_{=:\varepsilon^\ast}
\quad\Longleftrightarrow\quad
y^\ast=X^\ast\beta+\varepsilon^\ast =: y ∗ Ω − 1/2 y = =: X ∗ Ω − 1/2 X β + =: ε ∗ Ω − 1/2 ε ⟺ y ∗ = X ∗ β + ε ∗ 要するに「元のモデルの両辺に Ω − 1 / 2 \Omega^{-1/2} Ω − 1/2 」。係数 β \beta β ε ∗ \varepsilon^\ast ε ∗ 等分散・無相関 になっていることです。実際
V a r ( ε ∗ ) = V a r ( Ω − 1 / 2 ε ) = Ω − 1 / 2 V a r ( ε ) ( Ω − 1 / 2 ) ⊤ = Ω − 1 / 2 ( σ 2 Ω ) Ω − 1 / 2 \mathrm{Var}(\varepsilon^\ast)=\mathrm{Var}(\Omega^{-1/2}\varepsilon)
=\Omega^{-1/2}\,\mathrm{Var}(\varepsilon)\,(\Omega^{-1/2})^\top
=\Omega^{-1/2}(\sigma^2\Omega)\Omega^{-1/2} Var ( ε ∗ ) = Var ( Ω − 1/2 ε ) = Ω − 1/2 Var ( ε ) ( Ω − 1/2 ) ⊤ = Ω − 1/2 ( σ 2 Ω ) Ω − 1/2 Ω − 1 / 2 \Omega^{-1/2} Ω − 1/2 Ω − 1 / 2 Ω Ω − 1 / 2 = Ω − 1 / 2 Ω 1 / 2 Ω 1 / 2 Ω − 1 / 2 = I \Omega^{-1/2}\Omega\,\Omega^{-1/2}=\Omega^{-1/2}\Omega^{1/2}\Omega^{1/2}\Omega^{-1/2}=I Ω − 1/2 Ω Ω − 1/2 = Ω − 1/2 Ω 1/2 Ω 1/2 Ω − 1/2 = I
V a r ( ε ∗ ) = σ 2 I \boxed{\;\mathrm{Var}(\varepsilon^\ast)=\sigma^2 I\;} Var ( ε ∗ ) = σ 2 I 要するに「変換後の誤差はちょうど古典的仮定 (A3) を満たす(等分散・無相関に戻った) 」。期待値も E ( ε ∗ ) = Ω − 1 / 2 E ( ε ) = 0 \mathrm{E}(\varepsilon^\ast)=\Omega^{-1/2}\mathrm{E}(\varepsilon)=0 E ( ε ∗ ) = Ω − 1/2 E ( ε ) = 0 y ∗ = X ∗ β + ε ∗ y^\ast=X^\ast\beta+\varepsilon^\ast y ∗ = X ∗ β + ε ∗ ガウス・マルコフの定理がそのまま使える 。
だから変換後モデルに古典的 OLS を当てれば、それが BLUE です。
β ^ G L S = ( X ∗ ⊤ X ∗ ) − 1 X ∗ ⊤ y ∗ \hat\beta_{\mathrm{GLS}}=(X^{\ast\top}X^\ast)^{-1}X^{\ast\top}y^\ast β ^ GLS = ( X ∗ ⊤ X ∗ ) − 1 X ∗ ⊤ y ∗ これを元の記号に戻します。X ∗ = Ω − 1 / 2 X X^\ast=\Omega^{-1/2}X X ∗ = Ω − 1/2 X y ∗ = Ω − 1 / 2 y y^\ast=\Omega^{-1/2}y y ∗ = Ω − 1/2 y
X ∗ ⊤ X ∗ = ( Ω − 1 / 2 X ) ⊤ ( Ω − 1 / 2 X ) = X ⊤ Ω − 1 / 2 Ω − 1 / 2 X = X ⊤ Ω − 1 X X^{\ast\top}X^\ast=(\Omega^{-1/2}X)^\top(\Omega^{-1/2}X)=X^\top\Omega^{-1/2}\Omega^{-1/2}X=X^\top\Omega^{-1}X X ∗ ⊤ X ∗ = ( Ω − 1/2 X ) ⊤ ( Ω − 1/2 X ) = X ⊤ Ω − 1/2 Ω − 1/2 X = X ⊤ Ω − 1 X X ∗ ⊤ y ∗ = ( Ω − 1 / 2 X ) ⊤ ( Ω − 1 / 2 y ) = X ⊤ Ω − 1 y X^{\ast\top}y^\ast=(\Omega^{-1/2}X)^\top(\Omega^{-1/2}y)=X^\top\Omega^{-1}y X ∗ ⊤ y ∗ = ( Ω − 1/2 X ) ⊤ ( Ω − 1/2 y ) = X ⊤ Ω − 1 y 代入して
β ^ G L S = ( X ⊤ Ω − 1 X ) − 1 X ⊤ Ω − 1 y \boxed{\;\hat\beta_{\mathrm{GLS}}=(X^\top\Omega^{-1}X)^{-1}X^\top\Omega^{-1}y\;} β ^ GLS = ( X ⊤ Ω − 1 X ) − 1 X ⊤ Ω − 1 y 要するに「OLS の式の真ん中に Ω − 1 \Omega^{-1} Ω − 1 。Ω = I \Omega=I Ω = I Ω − 1 \Omega^{-1} Ω − 1
5.2 GLS が BLUE である理由と分散
GLS が BLUE であることは、上の導出からただちに 従います。変換後モデルは古典的仮定を満たし、β ^ G L S \hat\beta_{\mathrm{GLS}} β ^ GLS 変換後モデルにおける BLUE 。そして「変換後モデルの線形不偏推定量」と「元モデルの線形不偏推定量」は Ω − 1 / 2 \Omega^{-1/2} Ω − 1/2 Ω − 1 / 2 \Omega^{-1/2} Ω − 1/2 β ^ G L S \hat\beta_{\mathrm{GLS}} β ^ GLS 元のモデルにおいても線形不偏推定量の中で BLUE 。これが Aitken の定理 です。
GLS の分散は、変換後モデルの OLS の分散 σ 2 ( X ∗ ⊤ X ∗ ) − 1 \sigma^2(X^{\ast\top}X^\ast)^{-1} σ 2 ( X ∗ ⊤ X ∗ ) − 1
V a r ( β ^ G L S ) = σ 2 ( X ⊤ Ω − 1 X ) − 1 \boxed{\;\mathrm{Var}(\hat\beta_{\mathrm{GLS}})=\sigma^2(X^\top\Omega^{-1}X)^{-1}\;} Var ( β ^ GLS ) = σ 2 ( X ⊤ Ω − 1 X ) − 1 要するに「GLS のばらつきは σ 2 ( X ⊤ Ω − 1 X ) − 1 \sigma^2(X^\top\Omega^{-1}X)^{-1} σ 2 ( X ⊤ Ω − 1 X ) − 1 」。ガウス・マルコフの定理を Ω ≠ I \Omega\neq I Ω = I Ω \Omega Ω σ 2 ( X ⊤ X ) − 1 X ⊤ Ω X ( X ⊤ X ) − 1 \sigma^2(X^\top X)^{-1}X^\top\Omega X(X^\top X)^{-1} σ 2 ( X ⊤ X ) − 1 X ⊤ Ω X ( X ⊤ X ) − 1 OLS は不偏だが非効率、GLS が効率的 」の数式的な中身です。
5.3 重み付き最小二乗法(WLS):Ω \Omega Ω
不均一分散だが無相関 のときは Ω \Omega Ω 対角行列 になります。
Ω = d i a g ( ω 1 , … , ω n ) , V a r ( ε i ) = σ 2 ω i \Omega=\mathrm{diag}(\omega_1,\dots,\omega_n),\qquad
\mathrm{Var}(\varepsilon_i)=\sigma^2\omega_i Ω = diag ( ω 1 , … , ω n ) , Var ( ε i ) = σ 2 ω i このとき GLS は特に**重み付き最小二乗法(WLS:Weighted Least Squares)**と呼ばれ、Ω − 1 = d i a g ( 1 / ω 1 , … , 1 / ω n ) \Omega^{-1}=\mathrm{diag}(1/\omega_1,\dots,1/\omega_n) Ω − 1 = diag ( 1/ ω 1 , … , 1/ ω n ) w i = 1 / ω i w_i=1/\omega_i w i = 1/ ω i
β ^ W L S = arg min β ∑ i = 1 n w i ( y i − x i ⊤ β ) 2 , w i = 1 ω i \hat\beta_{\mathrm{WLS}}=\arg\min_\beta\ \sum_{i=1}^n w_i\,(y_i-x_i^\top\beta)^2,\qquad w_i=\frac{1}{\omega_i} β ^ WLS = arg β min i = 1 ∑ n w i ( y i − x i ⊤ β ) 2 , w i = ω i 1 を最小化することに等しくなります。要するに「ばらつきが大きい観測(ω i \omega_i ω i 」。Ω − 1 / 2 = d i a g ( 1 / ω i ) \Omega^{-1/2}=\mathrm{diag}(1/\sqrt{\omega_i}) Ω − 1/2 = diag ( 1/ ω i ) ω i \sqrt{\omega_i} ω i Ω \Omega Ω
5.4 実行可能GLS(FGLS):Ω \Omega Ω
ここまでは Ω \Omega Ω 既知 という前提でした。しかし現実には Ω \Omega Ω わからない 。そこで2段階で進めます。これが**実行可能GLS(FGLS:Feasible GLS)**です。
第1段階:まず OLS で回帰し、残差から Ω の構造を推定して Ω̂ を作る 第2段階:Ω̂ を真の Ω の代わりに使って GLS を実行する 数式では、推定した Ω ^ \hat\Omega Ω ^ Ω \Omega Ω
β ^ F G L S = ( X ⊤ Ω ^ − 1 X ) − 1 X ⊤ Ω ^ − 1 y \hat\beta_{\mathrm{FGLS}}=(X^\top\hat\Omega^{-1}X)^{-1}X^\top\hat\Omega^{-1}y β ^ FGLS = ( X ⊤ Ω ^ − 1 X ) − 1 X ⊤ Ω ^ − 1 y 要するに「Ω \Omega Ω Ω \Omega Ω Ω ^ \hat\Omega Ω ^ Ω ^ \hat\Omega Ω ^ σ i 2 = h ( x i ) \sigma_i^2=h(x_i) σ i 2 = h ( x i )
FGLS の理論的注意(1級で問われうる) :Ω ^ \hat\Omega Ω ^ 厳密には BLUE ではない 。Ω ^ \hat\Omega Ω ^ Ω \Omega Ω n → ∞ n\to\infty n → ∞
6. 全体像:OLS → 仮定が崩れる → GLS/WLS の判断フロー
ここまでの流れを1枚にまとめます。
flowchart TD
S["線形回帰モデル<br/>y = Xβ + ε"] --> A2{"E(ε)=0 か?<br/>(A2 外生性)"}
A2 -- いいえ --> NG["OLS は不偏ですらない<br/>(内生性。GM定理の対象外)"]
A2 -- はい --> A3{"Var(ε)=σ²I か?<br/>(A3 等分散・無相関)"}
A3 -- "はい(成立)" --> OLS["OLS = (XᵀX)⁻¹Xᵀy<br/>ガウス・マルコフ定理 → BLUE"]
A3 -- "いいえ(崩れる)" --> Het["Var(ε)=σ²Ω, Ω≠I<br/>OLS は不偏だが非効率・標準誤差が誤る"]
Het --> Diag{"Ω は対角か?<br/>(不均一分散のみ)"}
Diag -- "はい(対角)" --> WLS["WLS = 重み wᵢ=1/ωᵢ で<br/>重みづけ最小二乗(GLS の特例)"]
Diag -- "いいえ(非対角)" --> GLS["GLS = (XᵀΩ⁻¹X)⁻¹XᵀΩ⁻¹y<br/>系列相関も含め BLUE を回復"]
Het --> Known{"Ω は既知か?"}
Known -- "いいえ(未知)" --> FGLS["FGLS:残差から Ω̂ を推定し<br/>GLS(厳密には漸近的に効率的)"]
Known -- "いいえ(構造を仮定したくない)" --> Robust["OLS の点推定はそのまま<br/>+ ロバスト標準誤差(検定だけ補正)"]
要するに「まず外生性 (A2) が要。これが崩れたら GM 定理の土俵外。(A2) があって (A3) も成り立てば OLS が BLUE。(A3) が崩れたら GLS(対角なら WLS)で BLUE を回復。Ω \Omega Ω 」。
7. 引っかけ・頻出論点
⚠️ BLUE は「線形・不偏」クラスの中での最良 :ガウス・マルコフは「線形 かつ不偏 な推定量の中で OLS が最小分散」と言っているだけです。この縛りを外せば——非線形 な推定量や、わざとバイアスを許す 推定量(リッジ回帰など、正則化(リッジ・Lasso) 参照)なら、OLS より MSE が小さくなることがあります。「OLS はあらゆる推定量の中で最良」は誤り 。
⚠️ 正規性は不要 :ガウス・マルコフの定理に ε ∼ N ( 0 , σ 2 I ) \varepsilon\sim N(0,\sigma^2 I) ε ∼ N ( 0 , σ 2 I ) 全 不偏推定量の中での最良(UMVUE/有効性)」や t t t F F F 誤り 。
⚠️ 不均一分散でも OLS は不偏 :(A3) が崩れても不偏性(E β ^ = β \mathrm{E}\hat\beta=\beta E β ^ = β 効率性 (最小分散)と標準誤差の正しさ 。「不均一分散だと OLS が偏る」は誤り ——偏るのではなく非効率になり、かつ標準誤差を誤算します。
⚠️ 標準誤差の式が壊れる方が実害が大きい :点推定が当たっていても、既定の σ ^ 2 ( X ⊤ X ) − 1 \hat\sigma^2(X^\top X)^{-1} σ ^ 2 ( X ⊤ X ) − 1 σ 2 ( X ⊤ X ) − 1 X ⊤ Ω X ( X ⊤ X ) − 1 \sigma^2(X^\top X)^{-1}X^\top\Omega X(X^\top X)^{-1} σ 2 ( X ⊤ X ) − 1 X ⊤ Ω X ( X ⊤ X ) − 1 t t t p p p
⚠️ WLS は GLS の特別ケース :Ω \Omega Ω Ω \Omega Ω 包含関係 。
⚠️ GLS(Ω \Omega Ω Ω \Omega Ω :FGLS は Ω ^ \hat\Omega Ω ^ 漸近的にしか 保証されません。「FGLS は BLUE」は不正確 。
⚠️ full rank が前提 :X ⊤ X X^\top X X ⊤ X ( X ⊤ X ) − 1 (X^\top X)^{-1} ( X ⊤ X ) − 1 ( X ⊤ Ω − 1 X ) − 1 (X^\top\Omega^{-1}X)^{-1} ( X ⊤ Ω − 1 X ) − 1
よくある疑問(Q&A)
Q1. ガウス・マルコフの定理に正規分布の仮定は本当に要らないのですか?
要りません。定理の証明(3章)で使ったのは E ( ε ) = 0 \mathrm{E}(\varepsilon)=0 E ( ε ) = 0 V a r ( ε ) = σ 2 I \mathrm{Var}(\varepsilon)=\sigma^2 I Var ( ε ) = σ 2 I 1次・2次のモーメントの仮定だけ で、分布の形(正規かどうか)は一切使っていません。だから誤差がどんな分布でも、期待値0・等分散・無相関でさえあれば OLS は BLUE です。正規性が登場するのは、(i)「線形に限らない 全不偏推定量の中で最良(UMVUE/有効性)」を言いたいとき、(ii) t t t F F F 厳密な標本分布 を導きたいとき。ガウス・マルコフはあくまで「線形不偏クラスの中での最良」なので正規性は不要、というのが正確な切り分けです。
Q2. 「最良(Best)」とは具体的に何が最小なのですか? スカラーの分散ではないのですか?
行列の意味での最小です。OLS の分散共分散行列 V a r ( β ^ ) \mathrm{Var}(\hat\beta) Var ( β ^ ) V a r ( β ~ ) \mathrm{Var}(\tilde\beta) Var ( β ~ ) 差 V a r ( β ~ ) − V a r ( β ^ ) \mathrm{Var}(\tilde\beta)-\mathrm{Var}(\hat\beta) Var ( β ~ ) − Var ( β ^ ) であることを「OLS が最良」と呼びます。これはスカラーに翻訳でき、任意の線形結合 ℓ ⊤ β \ell^\top\beta ℓ ⊤ β V a r ( ℓ ⊤ β ^ ) ≤ V a r ( ℓ ⊤ β ~ ) \mathrm{Var}(\ell^\top\hat\beta)\le\mathrm{Var}(\ell^\top\tilde\beta) Var ( ℓ ⊤ β ^ ) ≤ Var ( ℓ ⊤ β ~ ) ということ。ℓ \ell ℓ β ^ j \hat\beta_j β ^ j ℓ \ell ℓ 係数のあらゆる線形結合の分散が同時に最小 」という強い意味です。
Q3. 不均一分散があると、回帰の結果(係数の推定値)は信用できないのですか?
係数の点推定値そのもの は信用できます。OLS は不均一分散があっても不偏 だからです(的は外していない)。信用できなくなるのは標準誤差・t t t p p p の方です。既定の標準誤差は等分散を仮定した式で計算されるので、不均一分散の下では真の精度とズレ、検定が甘すぎたり厳しすぎたりします。だから「係数の値は使えるが、その有意性の判定は補正が要る」が正しい理解。補正は、構造がわかれば GLS/WLS で効率も回復、構造を仮定したくなければロバスト(ホワイト)標準誤差で検定だけ直す、の2択です。
Q4. GLS と WLS の違いは何ですか? どう使い分けますか?
WLS は GLS の特別ケース です。誤差の共分散行列 Ω \Omega Ω 対角 (=不均一分散はあるが誤差どうしは無相関)のときの GLS が WLS。このとき重み w i = 1 / ω i w_i=1/\omega_i w i = 1/ ω i 互いに相関している (系列相関・クラスタ相関など)と Ω \Omega Ω Ω − 1 \Omega^{-1} Ω − 1 一般の GLS が要ります。使い分けの目安は「誤差が無相関で分散だけ不均一 → WLS、誤差に相関がある → フルの GLS 」。横断面データの不均一分散は WLS、時系列の自己相関は GLS、というのが典型です。
Q5. 実際には Ω \Omega Ω
そのままでは使えません。だから現実には Ω \Omega Ω 実行可能GLS(FGLS)を使います。手順は「①まず OLS で回帰 → ②残差を見て Ω \Omega Ω Ω ^ \hat\Omega Ω ^ Ω ^ \hat\Omega Ω ^ Ω ^ \hat\Omega Ω ^ 厳密には BLUE ではなく 、効率性は標本が大きいときの漸近的な性質 としてしか保証されません。Ω \Omega Ω
まとめ
古典的仮定 (A1 線形性/A2 E ε = 0 \mathrm{E}\varepsilon=0 E ε = 0 V a r ε = σ 2 I \mathrm{Var}\varepsilon=\sigma^2 I Var ε = σ 2 I X X X ガウス・マルコフの定理 :OLS β ^ = ( X ⊤ X ) − 1 X ⊤ y \hat\beta=(X^\top X)^{-1}X^\top y β ^ = ( X ⊤ X ) − 1 X ⊤ y BLUE (線形不偏の中で最小分散)。正規性は不要 。証明の骨子 :任意の線形不偏 β ~ = A y \tilde\beta=Ay β ~ = A y A = C + D A=C+D A = C + D D X = 0 DX=0 D X = 0 V a r ( β ~ ) − V a r ( β ^ ) = σ 2 D D ⊤ ⪰ 0 \mathrm{Var}(\tilde\beta)-\mathrm{Var}(\hat\beta)=\sigma^2 DD^\top\succeq0 Var ( β ~ ) − Var ( β ^ ) = σ 2 D D ⊤ ⪰ 0 D = 0 D=0 D = 0 (A3) が崩れる と V a r ( ε ) = σ 2 Ω \mathrm{Var}(\varepsilon)=\sigma^2\Omega Var ( ε ) = σ 2 Ω Ω \Omega Ω Ω \Omega Ω 不偏だが非効率 、かつ標準誤差の式が壊れて検定・区間が誤る 。GLS :Ω − 1 / 2 \Omega^{-1/2} Ω − 1/2 V a r ( ε ∗ ) = σ 2 I \mathrm{Var}(\varepsilon^\ast)=\sigma^2 I Var ( ε ∗ ) = σ 2 I β ^ G L S = ( X ⊤ Ω − 1 X ) − 1 X ⊤ Ω − 1 y \hat\beta_{\mathrm{GLS}}=(X^\top\Omega^{-1}X)^{-1}X^\top\Omega^{-1}y β ^ GLS = ( X ⊤ Ω − 1 X ) − 1 X ⊤ Ω − 1 y σ 2 ( X ⊤ Ω − 1 X ) − 1 \sigma^2(X^\top\Omega^{-1}X)^{-1} σ 2 ( X ⊤ Ω − 1 X ) − 1 WLS は Ω \Omega Ω w i = 1 / ω i w_i=1/\omega_i w i = 1/ ω i FGLS は Ω \Omega Ω Ω ^ \hat\Omega Ω ^ 引っかけ:BLUE は線形不偏クラス内の最良(非線形・有偏ならもっと良いことも)/正規性不要/不均一分散で OLS は不偏だが標準誤差を誤る/WLS⊂GLS/FGLS は厳密には BLUE でない。
関連ノート