📊 対象級:1級 | 重要度:B(標準)
要点(BLUF)
診断検査の指標は「検査側の性質(感度・特異度)」と「患者側から見た当たり具合(PPV・NPV)」の2系統に分かれます。前者は有病率に依存しない検査固有の性能、後者は有病率に強く依存する——この区別がこの分野の心臓部です。
- 感度・特異度は検査固有:感度=病気の人を陽性と当てる率(真陽性率 TPR)、特異度=健康な人を陰性と当てる率(真陰性率 TNR)。偽陽性率=特異度、偽陰性率=感度。これらは有病率が変わっても不変。
- PPV・NPVは有病率依存:陽性的中率(PPV)=検査陽性者のうち本当に病気の割合。これはベイズの定理で事前確率(有病率)を事後確率に更新したもので、有病率が低いと感度が高くてもPPVは低くなる(偽陽性パラドックス)。
- 尤度比で更新を一行に:陽性尤度比 。事前オッズ × 尤度比 = 事後オッズというベイズ更新の乗法形が成り立ち、有病率の影響を切り離して検査の情報量を測れる。
- ROC曲線とAUC:カットオフを動かしたときの(横軸 特異度、縦軸 感度)の軌跡がROC曲線。その下面積AUCは識別能の要約で、0.5=偶然、1=完全。AUCは「ランダムに選んだ患者の検査値が、ランダムに選んだ健常者より高い確率」(Mann-Whitney U統計量と等価)。
1級(統計応用・医薬生物学)では2×2表からの感度/特異度/PPV計算・有病率がPPVに与える影響・尤度比による更新・ROC/AUCの解釈が問われます(出題範囲・配点は改訂されうるため要最新確認)。
graph TD ROOT["診断検査の性能評価"] --> TEST["検査固有の性質<br/>(有病率に不依存)"] ROOT --> PRED["患者側の当たり具合<br/>(有病率に依存)"] TEST --> SENS["感度 = 真陽性率 TPR<br/>病気の人を陽性と当てる"] TEST --> SPEC["特異度 = 真陰性率 TNR<br/>健康な人を陰性と当てる"] PRED --> PPV["PPV 陽性的中率<br/>陽性者のうち真の患者"] PRED --> NPV["NPV 陰性的中率<br/>陰性者のうち真の健常者"] SENS --> BAYES["ベイズの定理<br/>有病率→PPV/NPV"] SPEC --> BAYES BAYES --> LR["尤度比<br/>事前オッズ×LR=事後オッズ"] TEST --> ROC["ROC曲線・AUC<br/>カットオフを動かした識別能"]
1. 混同行列と4つの基本量
すべての出発点は 2×2 の混同行列(分割表) です。検査の判定(陽性/陰性)を行、真の病態(疾患あり/なし)を列に取ります。
| 疾患あり() | 疾患なし() | |
|---|---|---|
| 検査陽性() | 真陽性 TP | 偽陽性 FP |
| 検査陰性() | 偽陰性 FN | 真陰性 TN |
ここから「列方向(真の病態で割る)」と「行方向(検査結果で割る)」の2系統の指標が生まれます。この割る方向の違いが、感度/特異度とPPV/NPVを分ける本質です。
1.1 列方向 — 感度・特異度(検査固有)
真の病態を条件として、検査が当てる割合を測ります。
要するに「病気の人を、検査がちゃんと陽性と拾える率」。真陽性率(true positive rate, TPR)と同じものです。
要するに「健康な人を、検査がちゃんと陰性と返せる率」。真陰性率(TNR)と同じです。
ここから2つの誤り率が定義されます。
要するに「偽陰性率は見逃し率(病気を陰性と誤る)、偽陽性率は空振り率(健康を陽性と誤る)」。感度を上げれば見逃しが減り、特異度を上げれば空振りが減ります。
決定的な性質:感度・特異度は有病率に依存しない。 上の式はすべて「 の中だけ」「 の中だけ」で計算され、分母に「集団全体に占める病気の割合」が一切入りません。だから対象集団の有病率が高かろうが低かろうが、感度・特異度は検査そのものの固有の性能として変わりません。これがあとで効いてきます。
1.2 行方向 — PPV・NPV(有病率依存)
今度は検査結果を条件として、それが当たっている割合を測ります。患者・臨床医が本当に知りたいのはこちらです(「陽性と出た、で、私は本当に病気なの?」)。
要するに「検査が陽性と言った人のうち、本当に病気だった割合」。
要するに「検査が陰性と言った人のうち、本当に健康だった割合」。
感度 とPPV は条件と結果が入れ替わっているだけに見えますが、 なので一般にまったく別物です。この入れ替えを橋渡しするのがベイズの定理であり(第2節)、橋渡しに必要な追加情報が有病率です。だから感度・特異度が同じでも、有病率が違えばPPV・NPVは変わります。
flowchart LR CM["2×2 混同行列<br/>TP / FP / FN / TN"] --> COL["列方向:真の病態で割る"] CM --> ROW["行方向:検査結果で割る"] COL --> S1["感度 = TP/(TP+FN)"] COL --> S2["特異度 = TN/(TN+FP)"] ROW --> P1["PPV = TP/(TP+FP)"] ROW --> P2["NPV = TN/(TN+FN)"] S1 -.有病率に不依存.-> NOTE1["検査固有の性能"] P1 -.有病率に依存.-> NOTE2["集団によって変わる"]
2. PPVをベイズの定理で導く
2.1 導出
PPV は「検査陽性という証拠を得たあとの、病気である確率」です。これはまさにベイズの定理で事前確率を事後確率に更新する操作になります。事前確率は有病率 です。ベイズの定理より
分母 (検査が陽性になる全確率)を、病気の人からの陽性と健康な人からの陽性に分解します(全確率の公式)。
ここで 、、、 を代入すると、検査の指標だけで書けます。
要するに「PPV = 真陽性の量 ÷(真陽性の量+偽陽性の量)」。分子は「病気の人を正しく拾った量」、分母に足される第2項は「健康な人を誤って拾った量」です。同様に NPV も導けます。
ここで読み取るべき核心は、右辺に有病率 が露骨に入っていることです。感度・特異度(検査固有・ に無関係)が同じでも、 が変わればPPV・NPVは変わります。これがPPV/NPVが有病率依存である理由の数式上の証拠です。
flowchart LR PRIOR["事前確率<br/>有病率 p = P(D+)"] --> UPDATE["ベイズ更新<br/>感度・特異度で重み付け"] EVIDENCE["証拠:検査が陽性 T+"] --> UPDATE UPDATE --> POST["事後確率<br/>PPV = P(D+ | T+)"]
2.2 低有病率でPPVが激減する数値例
「感度が高い検査なら陽性なら安心」という直観がいかに危ういかを数値で見ます。感度 99%、特異度 95% という優秀な検査を考えます。
ケースA:有病率 (10%、よくある病気)
10万人を検査すると想定します(割合計算でもよいが人数の方が直観的です)。
- 病気の人 10,000 人 → 真陽性 、偽陰性 100
- 健康な人 90,000 人 → 偽陽性 、真陰性 85,500
陽性と出れば約 69% が本当に病気。まずまず信用できます。
ケースB:有病率 (0.1%、まれな病気・集団検診)
- 病気の人 100 人 → 真陽性 、偽陰性 1
- 健康な人 99,900 人 → 偽陽性 、真陰性 94,905
同じ感度99%・特異度95%の検査なのに、陽性と出ても本当に病気なのはわずか約2%。 98%は偽陽性です。
何が起きたか。健康な人が圧倒的多数(99,900人)なので、特異度95%でも生じる5%の偽陽性(4,995人)が、病気の人の真陽性(99人)を量で押し潰します。有病率が低いと「分母の健康な人の母数が巨大」になり、わずかな偽陽性率でも偽陽性の絶対数が真陽性を上回る——これが**偽陽性パラドックス(false positive paradox)/基準率の誤謬(base rate fallacy)**です。
| 有病率 | 真陽性 | 偽陽性 | PPV |
|---|---|---|---|
| 10%(ケースA) | 9,900 | 4,500 | 約 68.8% |
| 1% | 990 | 4,950 | 約 16.7% |
| 0.1%(ケースB) | 99 | 4,995 | 約 1.9% |
要するに「検査の性能(感度・特異度)が同じでも、まれな病気を低有病率の集団でスクリーニングすると、陽性的中率は劇的に下がる」。だからスクリーニング検査では「陽性 → ただちに確定」ではなく、より特異度の高い確定検査(confirmatory test)で再評価する2段構えが標準になります。
3. 尤度比とオッズ形のベイズ更新
3.1 尤度比の定義
PPVの式は有病率 を含むため、検査ごとに を変えて計算し直す手間があります。これを「検査の情報量( に依存しない)」と「集団の有病率」にきれいに分離できるのが**尤度比(likelihood ratio, LR)**です。
要するに「陽性という結果が、病気の人で出る確率は、健康な人で出る確率の何倍か」。 が大きいほど「陽性」が病気を強く示唆します。陰性についても同様に、
要するに「陰性という結果が、病気の人で出る確率は、健康な人で出る確率の何倍か」。 は小さい(0に近い)ほど「陰性」が病気を強く否定します。臨床の目安では または で強い証拠、 付近()はほとんど情報がない、とされます(あくまで目安)。
3.2 「事前オッズ × 尤度比 = 事後オッズ」の導出
ベイズの定理をオッズ(確率の比 )で書くと、尤度比が更新の乗数として顔を出します。事後確率の比を取ります。
分母の が上下で約分されて消えます(ベイズの定理をオッズで書く利点はここ——厄介な周辺確率 が消える)。残るのは
すなわち
要するに「検査前のオッズ(有病率のオッズ )に、尤度比を掛けるだけで検査後のオッズになる」。掛け算ひとつでベイズ更新が完了します。 は有病率に依存しない検査固有の量なので、これで「検査の情報量(尤度比)」と「集団の事前オッズ」が分離できました。
更新後の事後オッズを確率に戻せば です。この「確率→オッズ→(×尤度比)→オッズ→確率」の流れを図式化した臨床ツールが**ファーガンのノモグラム(Fagan nomogram)**で、3本の目盛り(事前確率・尤度比・事後確率)を直線で結ぶだけで事後確率が読めます。
flowchart LR A["事前確率<br/>有病率 p"] --> B["事前オッズ<br/>p/(1-p)"] B --> C["× 陽性尤度比 LR+"] C --> D["事後オッズ"] D --> E["事後確率<br/>= PPV"]
第2.2節のケースAを尤度比で再計算して整合を確認します。。事前オッズ 。事後オッズ 。事後確率 。第2.2節の 68.8% と一致します。
4. ROC曲線とAUC
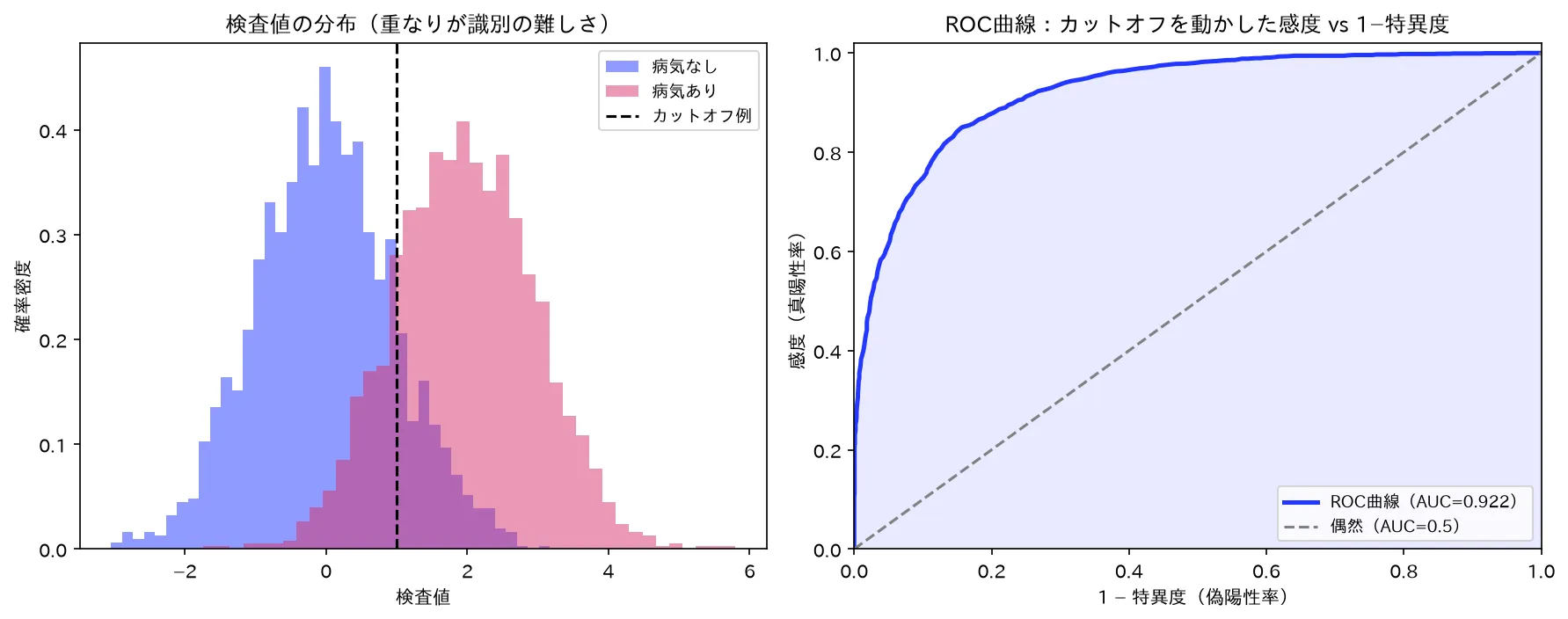
図は simulations/roc_auc_keijou.py で生成。
4.1 カットオフを動かす — ROC曲線
ここまでは「陽性/陰性」が固定された2値検査でした。しかし多くの検査は連続値(血液マーカーの濃度、スコア)を出し、「いくつ以上を陽性とするか」のカットオフ(閾値)を分析者が決めます。カットオフを動かすと感度と特異度がトレードオフで変わります。
- カットオフを下げる(陽性と判定しやすくする)→ 病気を拾いやすく感度↑、だが健康な人も拾い特異度↓。
- カットオフを上げる(陽性と判定しにくくする)→ 特異度↑、だが見逃しが増え感度↓。
この「カットオフを全範囲で動かしたときの(横軸 特異度、縦軸 感度)の点の軌跡」が **ROC曲線(receiver operating characteristic curve、受信者操作特性曲線)**です。縦軸が真陽性率(感度)、横軸が偽陽性率(特異度)であることを取り違えないでください。
xychart-beta title "ROC曲線(縦軸=感度、横軸=1-特異度)" x-axis "偽陽性率(1 - 特異度)" 0 --> 1 y-axis "真陽性率(感度)" 0 --> 1 line [0, 0.55, 0.75, 0.86, 0.92, 0.96, 1.0] line [0, 0.167, 0.333, 0.5, 0.667, 0.833, 1.0]
上の図で、上に膨らんだ曲線が良い検査のROC曲線、対角線(45度の直線)が「偶然と同じ=まったく識別できない検査」です。曲線が左上の角 に近づくほど良い(偽陽性率0で感度1=完璧)。曲線上のどの点を選ぶか(=どのカットオフを採用するか)の代表的な基準がユーデン指数(Youden index) を最大化する点で、これは曲線が左上角から最も離れる点に対応します。ただしユーデン指数が最適カットオフを与えるのは「感度と特異度を等価に扱い、コストを無視し、有病率を考えない」前提のときだけで、臨床的にはコストや有病率に応じて感度寄り/特異度寄りにずらすのが普通です。
4.2 AUC — 曲線の下面積と識別能
ROC曲線の下側の面積(area under the curve, AUC)が、カットオフに依存しない検査の総合的な識別能の要約です。
- :対角線。偶然と同じでまったく識別できない。
- :左上角を通る。完全な識別(病気と健康の検査値分布が重ならない)。
- 一般に大きいほど良い。 超で臨床的に有用、などの目安が使われます(あくまで目安)。
AUCの確率的解釈(重要). AUCには美しい確率的意味があります。
要するに「病気の人を1人、健康な人を1人ランダムに取ってきたとき、検査値が『病気の人 > 健康な人』と正しく順位づけされる確率」。 なら、ランダムなペアの80%で病気の人の方が高い値を示す、ということです。 はコイン投げ(順序がランダム)に対応し、 は常に病気の人が高い(完全分離)に対応します。
この解釈から、AUCはマン・ホイットニーのU統計量(ウィルコクソンの順位和統計量)と等価であることが導かれます。「2群の値の大小ペアの一致率」がまさにU統計量の定義だからです。つまりROC/AUCはノンパラメトリックな2群比較と地続きで、AUCの検定( か否か)はマン・ホイットニー検定に対応します。この接続は1級で順位統計量と絡めて問われうる論点です。
5. 第一種・第二種過誤との対応
診断検査の指標は、仮説検定の枠組みときれいに対応します。帰無仮説 「疾患なし(健康)」を立て、検査陽性を「 を棄却(病気と判定)」とみなします。
| 検定の枠組み | 診断検査での対応 | 意味 |
|---|---|---|
| 第一種過誤の確率 ( が真なのに棄却) | 偽陽性率 特異度 | 健康な人を誤って陽性とする |
| 特異度 | 健康な人を正しく陰性とする | |
| 第二種過誤の確率 ( が偽なのに採択) | 偽陰性率 感度 | 病気の人を誤って陰性とする(見逃し) |
| 検出力 | 感度 | 病気の人を正しく陽性とする |
要するに「特異度は『健康な人を健康と判断する確率』= に、感度は『病気を病気と検出する力』=検出力 に対応する」。カットオフを動かす操作は、検定の有意水準 を動かすことに相当し、 を厳しくすれば(特異度↑)検出力(感度)が下がる——検定で言う「 と のトレードオフ」が、診断検査の「特異度と感度のトレードオフ」そのものなのです。ROC曲線は、(横軸 特異度)を全範囲で動かしたときの検出力(縦軸 感度)の軌跡だ、と読み替えることもできます。
⚠️ 対応はあくまで「枠組みの類似」です。診断検査では を「健康」に取るのが慣例ですが、これは検査設計者の都合で、検定で をどちらに置くかと同様に約束ごとです。「感度=検出力」「特異度=」の対応は、=健康と置いたときの結果である点に注意してください。
6. 試験での問われ方(1級)
医薬生物学分野での1級の典型的な問われ方を、論点ごとに整理します(出題範囲・配点は要最新確認)。
- 2×2表からの計算:TP/FP/FN/TN が与えられ、感度・特異度・PPV・NPVを正しい分母で計算させる。「感度はTP/(TP+FN)(列で割る)、PPVはTP/(TP+FP)(行で割る)」の割る方向の区別が落とし穴。
- 有病率の影響:同じ感度・特異度でも有病率を変えたときPPVがどう変わるかを計算させ、低有病率でPPVが激減することを示させる。ベイズの定理 を立式させる場合がある。
- 尤度比とオッズ更新: を計算させ、「事前オッズ × 尤度比 = 事後オッズ」で事後確率(PPV)を求めさせる。尤度比が有病率に依存しないこと(検査固有の情報量)を理解させる。
- ROC/AUCの解釈:ROC曲線の軸(縦=感度、横=特異度)、AUCの値域(0.5〜1)と意味(識別能)、AUCの確率的解釈(ランダムペアの順位一致確率)、対角線が偶然であることを問う。Mann-Whitney U統計量との等価性まで触れられることがある。
- 過誤との対応:感度=検出力()、特異度= の対応、カットオフ移動が - トレードオフに対応することを問う。
- 検査の選び方:スクリーニングには感度重視(見逃しを避ける、 が小さい検査で除外)、確定診断には特異度重視(偽陽性を避ける、 が大きい検査で確定)という使い分けの理解。
7. 引っかけ・頻出論点
- ⚠️ 感度/特異度とPPV/NPVを混同する:感度 とPPV は条件と結果が逆で、 より別物です。「感度が99%だから陽性なら99%病気」は誤り(それはPPVであり有病率に依存)。割る方向(列=病態で割る/行=検査結果で割る)で区別する。
- ⚠️ PPVが有病率に依存しないと誤解する:PPV・NPVは有病率 に強く依存します(ベイズの式に が露骨に入る)。一方、感度・特異度は に依存しません。「検査の性能が同じなら的中率も同じ」は誤り——集団が変われば的中率は変わります。
- ⚠️ 低有病率での偽陽性パラドックスを見落とす:感度・特異度が高くても、まれな病気の集団検診では偽陽性が真陽性を量で上回り、PPVが激減します。「優秀な検査だから陽性ならほぼ確定」は低有病率では誤り。
- ⚠️ ROC曲線の軸を取り違える:縦軸は感度(真陽性率)、横軸は 特異度(偽陽性率)です。「横軸が特異度」は誤り。左上に近いほど良く、対角線は偶然。
- ⚠️ AUCを「正答率(accuracy)」と混同する:AUCは特定のカットオフでの正答率ではなく、全カットオフを通じた識別能の要約であり、「ランダムペアの順位一致確率」です。 は正答率50%ではなく「順序がコイン投げと同じ=識別不能」を意味する。
- ⚠️ 尤度比が有病率に依存すると誤解する: は感度・特異度だけからなり、有病率に依存しません(検査固有の情報量)。有病率が入るのは事前オッズの側です。「尤度比は集団によって変わる」は誤り。
- ⚠️ 感度・特異度はトレードオフだがPPVと一方向に動くと思い込む:カットオフ移動で感度↑なら特異度↓(トレードオフ)。PPV/NPVへの効きは有病率次第で単純化できない。「感度を上げればPPVも上がる」と短絡しない。
よくある疑問(Q&A)
Q1. 感度が99%なのに、陽性と出ても本当に病気なのが2%しかない、というのが信じられません。どこで直観が裏切られているのですか?
直観が見落としているのは「健康な人の母数の大きさ」です。感度99%は「病気の人を99%拾う」という、病気の人だけに関する性能で、健康な人がどれだけいるかは一切勘案していません。有病率0.1%の集団では、病気の人100人に対して健康な人が99,900人もいます。特異度95%でもこの99,900人の5%=4,995人が偽陽性になり、病気の人の真陽性99人を量で圧倒します。陽性者5,094人のうち真の患者は99人だけ、だからPPVは約2%。感度・特異度は「正解集合の中での当たり率」であって、「集団全体での当たり率」ではない——この分母の違いが直観を裏切る正体です。だからまれな病気のスクリーニングでは、陽性をそのまま信じず確定検査につなぐのです。
Q2. なぜPPVは有病率に依存して、感度・特異度は依存しないのですか? 同じ検査の指標なのに不思議です。
「何を分母にして割っているか」が違うからです。感度 は分母が「病気の人だけ」で、その中で陽性を拾う割合を測ります。この計算には「集団に病気の人が何%いるか(有病率)」は登場しません——病気の人の中での話なので。だから有病率が変わっても感度は不変。一方PPV は分母が「検査陽性の人全員(病気・健康混在)」で、その混在比率が有病率で決まります。有病率が下がれば陽性者に占める健康な人(偽陽性)の割合が増え、PPVが下がる。ベイズの定理の式 を見れば、感度・特異度は検査固有の定数として入り、(有病率)が別途掛かっている構造が一目で分かります。
Q3. 尤度比をわざわざ使う利点は何ですか? PPVを直接計算すればよくないですか?
利点は「検査の情報量を有病率から切り離せる」ことと「更新が掛け算ひとつで済む」ことです。PPVの式は有病率 を含むので、同じ検査でも対象集団(外来/救急/検診で有病率が違う)ごとに計算し直す必要があります。尤度比 は有病率を含まない検査固有の数なので、「この検査は陽性ならオッズを19.8倍にする」と一度言えば、あとは集団ごとの事前オッズに掛けるだけで事後オッズが出ます(事後オッズ=事前オッズ×尤度比)。臨床医が患者ごとに事前確率を見積もり、ノモグラムで事後確率を読む、という実践はこの分離があってこそ成り立ちます。検査の良し悪し(尤度比)と患者の事前確率を別々に扱えるのが尤度比の価値です。
Q4. AUCが「ランダムペアの順位一致確率」になるのはなぜですか? 面積の話だったのに確率が出てくるのが飛躍に感じます。
ROC曲線の下面積を積分の形で書くと、それがそのまま「病気の人の検査値が健康な人の検査値を上回る確率」に等しくなる、という数学的事実があります。直観的には、カットオフを動かして得た各点 は「あるカットオフで健康な人をどれだけ通し、病気の人をどれだけ拾うか」の組で、これを全カットオフで積み上げて面積にすると、「病気の検査値分布が健康の検査値分布より右にずれている度合い」を測ることになります。2群の値をすべてペアにして「病気>健康」と正しく並ぶ割合を数えたものが、まさにマン・ホイットニーのU統計量を標本数で割った量で、これがAUCと一致します。だからAUCは面積であり確率であり、同時にノンパラメトリックな2群比較の統計量でもある、という三位一体になっています。
Q5. スクリーニング検査と確定検査で、感度と特異度のどちらを優先すべきですか?
役割が逆です。スクリーニング(ふるい分け)は感度を優先します。目的は「病気を見逃さない」ことで、感度が高ければ偽陰性(見逃し)が少なく、陰性なら安心して除外できます( が小さい検査は陰性で病気を強く否定できる=rule out)。一方確定診断(confirmation)は特異度を優先します。目的は「健康な人を病気と誤らない」ことで、特異度が高ければ偽陽性が少なく、陽性なら確信を持って病気と判断できます( が大きい検査は陽性で病気を強く確定=rule in)。だから2段構え——感度重視のスクリーニングで広くふるい、陽性者だけを特異度重視の確定検査にかける——がまれな病気の実務標準です。これはQ1の偽陽性パラドックスへの対処そのものでもあります。
まとめ
- 2系統の指標:列方向(真の病態で割る)=感度 ・特異度 は検査固有で有病率に不依存。行方向(検査結果で割る)=PPV ・NPV は有病率に依存。偽陽性率=特異度、偽陰性率=感度。
- PPVはベイズの定理:。事前確率(有病率 )を検査陽性という証拠で事後確率に更新したもの。右辺に が入るのが有病率依存の証拠。
- 偽陽性パラドックス:感度99%・特異度95%でも有病率0.1%ではPPV約2%。低有病率では健康な人の母数が巨大で偽陽性が真陽性を量で上回る。スクリーニングは確定検査と2段構え。
- 尤度比:、。事後オッズ=事前オッズ×尤度比でベイズ更新が掛け算ひとつ。尤度比は有病率に依存しない検査固有の情報量。
- ROC曲線とAUC:縦軸=感度、横軸=特異度。カットオフを動かした軌跡。左上に近いほど良く対角線は偶然。AUCは識別能の要約(0.5=偶然、1=完全)で、「ランダムペアの順位一致確率」=Mann-Whitney U統計量と等価。
- 過誤との対応:特異度=、感度=検出力 (=健康と置いたとき)。カットオフ移動=- トレードオフ。
関連ノート
- ベイズの定理 PPVはベイズの定理で事前確率(有病率)を事後確率に更新したもの。本ノートの導出の土台
- 第一種の過誤・第二種の過誤・検出力(2種類の誤りとトレードオフ・サンプルサイズ設計) 特異度=、感度=検出力 の対応。カットオフ移動が - トレードオフに相当
- カイ二乗検定(適合度・独立性) 2×2分割表の独立性検定。診断検査の混同行列も同じ2×2表で、検査と病態の関連を検定できる
- 効果の指標 リスク比・オッズ比など2×2表から導く別系統の指標。尤度比のオッズ更新と数理的に地続き
- 医薬生物学分野ハブ(Phase 9) 医薬生物学分野の全体地図
- 1級「統計応用」(Phase 9 目次) 統計応用ドメインの全体地図