🎓 レベル:基礎 | 重要度:B(標準)
要点(BLUF)
- ナイーブベイズは「ベイズの定理で事後確率 を求め、最大の class を選ぶ」生成的分類器です。 という積の形が核心です。
- この積が成り立つのは「class が分かれば各特徴は互いに独立(条件付き独立)」という大胆=ナイーブな仮定のおかげ。現実にはほぼ破れていますが、それでも分類はよく当たります。
- 特徴の型に応じて の分布を選びます(連続→ガウシアン、回数→多項、有無→ベルヌーイ)。学習で一度も出なかった値の確率が 0 になるゼロ頻度問題はラプラススムージングで防ぎます。
1. 出発点:ベイズの定理から分類へ
入力 を観測したとき、それが class である確率(事後確率)を知りたい。ベイズの定理(→ 統計 ベイズの定理)はこれを次のように書き換えます:
- :事前確率。データを見る前の各 class の出やすさ(例:迷惑メールが全体の3割)。
- :尤度。「class が なら、この特徴の組 がどれくらい出るか」。
- :周辺尤度。 そのものの出やすさ。 に依存しない定数です。
分類では「どの で事後確率が最大か」だけが知りたいので、 によらない分母 は無視できます:
要するに:事後確率=(事前確率)×(尤度)を class ごとに比べ、一番大きい class を予測にする。分母は順位に効かないので捨ててよい、ということです。
2. ナイーブな仮定:条件付き独立
問題は尤度 です。特徴が 個あると、その同時分布をまともに推定するには ごとに全組み合わせの頻度が必要で、データがいくらあっても足りません(次元の呪い)。
そこでナイーブベイズは大胆な近道を取ります。class さえ分かれば、各特徴は互いに独立だと仮定するのです(これを条件付き独立と呼びます)。すると同時分布が各特徴の積にバラせます:
これを §1 に代入すると、ナイーブベイズの基本式が出ます:
要するに: 次元のお化けのような同時分布を推定する代わりに、「class ごと・特徴ごと」の1次元分布を 個だけ推定すればよくなった、ということです。推定するパラメータが激減し、少ないデータでも学習できます。
flowchart LR X["入力 x = (x1, ..., xp)"] --> P1["P(x1 | y) を class ごとに評価"] X --> P2["P(x2 | y)"] X --> P3["... P(xp | y)"] PRI["事前確率 P(y)"] --> MUL["積をとる: P(y) × ∏ P(xj | y)"] P1 --> MUL P2 --> MUL P3 --> MUL MUL --> ARG["argmax で最大の class を選ぶ"] ARG --> YH["予測 ŷ"]
仮定はどれくらいウソか
条件付き独立は現実にはまず成り立ちません。たとえば迷惑メール判定で「無料」と「キャンペーン」は強く共起しますが、ナイーブベイズは両者を別々に数えて二重カウントします。だから出てくる確率の値そのものは信用できない(往々にして 0 や 1 に張りつく)。にもかかわらず分類が当たる理由は §6 で説明します。
3. 尤度をどう測るか:3つの分布
をどんな分布でモデル化するかは、特徴の型で決まります。代表的な3種類です。
| 変種 | 特徴の型 | のモデル | 典型用途 |
|---|---|---|---|
| ガウシアンNB | 連続値 | 正規分布 | 身長・センサー値など数値データ |
| 多項NB | 回数・頻度(非負整数) | カテゴリ分布(多項分布) | 文書の単語出現回数(BoW) |
| ベルヌーイNB | 二値(0/1・有無) | ベルヌーイ分布 | 単語が「出たか出ないか」だけを見る |
ガウシアンNB
特徴 が連続なら、class ごとに平均 と分散 を訓練データから推定し、密度を当てはめます:
要するに:class ごとに「その特徴の平均と散らばり」を覚えておき、新しい値がその釣鐘曲線のどこに来るかで尤もらしさを測る、ということです。
多項NB(テキスト分類の定番)
文書を「単語の出現回数」のベクトルで表すとき、class における単語 の出現確率 を頻度で推定します:
ここで は「class の文書群に単語 が出た総回数」、分母は class の総単語数です。
要するに:「このカテゴリの文章で、この単語が全単語の何%を占めるか」を確率として使う、ということです。
ベルヌーイNB
回数ではなく「出たか・出ないか」の二値だけを見ます。class で特徴 が出る確率を とすると、出なかったこと()も明示的に確率に反映します:
要するに:多項NBが「何回出たか」を数えるのに対し、ベルヌーイNBは「出た/出ない」の有無を見て、しかも出なかった単語のペナルティも勘定に入れる点が違います。短文では後者が有利なことがあります。
4. ゼロ頻度問題とラプラススムージング
多項・ベルヌーイNBには落とし穴があります。訓練データで class に一度も現れなかった単語 があると 。すると §2 の積 が、たった一語のせいでまるごと 0 になり、その class は完全に除外されてしまいます。
しかし「訓練データに出なかった=そのカテゴリで絶対に出ない」わけではありません。これがゼロ頻度問題です。
対策は、すべての数え上げに最初から下駄を履かせること。多項NBなら各単語のカウントに を足します:
は特徴(語彙)の総数、 は平滑化の強さです。 をラプラススムージング(加算平滑化)、 をリッドストーン平滑化と呼びます。
要するに:「未観測の単語にも、念のため少しだけ確率を分けておく」操作です。分子に を足すぶん、分母も語彙数 だけ増やして全体を1に正規化し直しています。
flowchart LR Z["ある単語の頻度が 0"] --> PZ["P(xj | y) = 0"] PZ --> KILL["∏ P が 0 に → その class を誤って除外"] LAP["ラプラス平滑化: 分子に +α, 分母に +αV"] -.->|"0 を避ける"| FIX["どの確率も > 0 を保つ"]
ガウシアンNBはこの問題が起きません。正規分布の密度はどの値でも厳密に正なので、確率が 0 になりようがないからです(だから sklearn の
GaussianNBにalphaはありません)。
5. 実装の勘所:log で足す
積 は、特徴が数百あると極端に小さい数の掛け算になり、コンピュータが 0 と区別できなくなります(アンダーフロー)。そこで対数を取り、積を和に変えます:
は単調増加なので、対数を取っても class の順位は変わりません。argmax の答えは同じまま、数値だけが安定します。
要するに:「ものすごく小さい数の掛け算」を「ほどほどの大きさの足し算」に置き換えるだけのテクニックで、比べたいのは順位だけなので対数化は無害です。
6. なぜ仮定が雑でも当たるのか
ここが一番おもしろい論点です。条件付き独立は明らかに間違っているのに、ナイーブベイズはしばしば実用的な精度を出します。理由は 分類の評価軸が「確率の正確さ」ではなく「順位の正しさ」だからです。
- 私たちが本当に欲しいのは 、つまりどの class が一番大きいかだけ。
- 独立仮定が破れると確率の値は大きく歪みます(共起する特徴を二重カウントするため、勝った class の確率が過剰に 1 に近づく)。
- しかし歪んでも、正解 class が最大であり続ける限り、予測は当たる。誤分類(0-1損失)は確率値のズレを罰しないのです。
これを理論的に示したのが Domingos & Pazzani (1997) の「On the Optimality of the Simple Bayesian Classifier under Zero-One Loss」です。彼らは「独立仮定が大幅に破れていても、0-1損失のもとでは最適でありうる」こと、そして「確率推定が正確であるための条件(領域)は、分類が正しいための条件よりはるかに狭い」ことを示しました。
要するに:ナイーブベイズの出す確率は当てにならないが、順位は意外と保たれる。だから「確率値を信じる用途(リスク評価・期待値計算)」には向かないが、「ラベルを当てる用途」には強い、という使い分けになります。
7. 生成モデルとしての立ち位置
ナイーブベイズは 生成モデル です。 と を別々にモデル化するということは、結局同時分布 を組み立てていることになります。同時分布が手に入れば、原理的にはそこから新しいデータ を生成することもできます。
これは ロジスティック回帰 のような識別モデルとの根本的な違いです。識別モデルは (または決定境界)を直接学び、 がどう生まれるかには関心がありません。
graph TB GEN["生成モデル: P(x, y) を学ぶ<br/>(ナイーブベイズ・LDA)"] DIS["識別モデル: P(y | x) を直接学ぶ<br/>(ロジスティック回帰・SVM)"] GEN -->|"ベイズの定理で P(y | x) を導く・x を生成も可"| USE1["少データに強い・速い・確率が歪みがち"] DIS -->|"境界だけに集中"| USE2["大データで高精度・確率は素直"]
なお、ガウシアンNBと 判別分析(LDA・QDA) はどちらも「class ごとに正規分布を当てる生成モデル」という点で親戚です。違いは、ナイーブベイズが特徴間の独立を仮定して共分散を対角に制限するのに対し、LDA/QDA は特徴間の相関(非対角の共分散)まで使う点にあります。
⚠️ よくある誤解
- 「ナイーブベイズの出力確率は信頼できる」は誤り。独立仮定の破れで確率は 0/1 に張りつきやすく、値はほぼ当てになりません。信用してよいのは**順位(argmax の結果)**だけ(→ §6)。確率の良し悪しを測るなら 評価指標(分類)とROC・AUC のキャリブレーションの観点が要ります。
- 「独立仮定が成り立たないと使えない」は誤り。仮定はほぼ常に破れていますが、0-1損失のもとでは順位が保たれやすく、実用精度は出ます(Domingos & Pazzani)。
- 「多項NBとベルヌーイNBは同じ」ではない。前者は出現回数を、後者は出現の有無+未出現のペナルティを使います。テキストの長さや特徴の性質で向き不向きが変わります。
- ラプラススムージングを連続特徴に使おうとするのは筋違い。ゼロ頻度問題は離散カウント(多項・ベルヌーイ)の話で、ガウシアンNBには無関係です。
- 掛け算のまま実装するとアンダーフローで壊れる。必ず を取って和に変換してから比較します(順位は不変)。
対応するシミュレーション
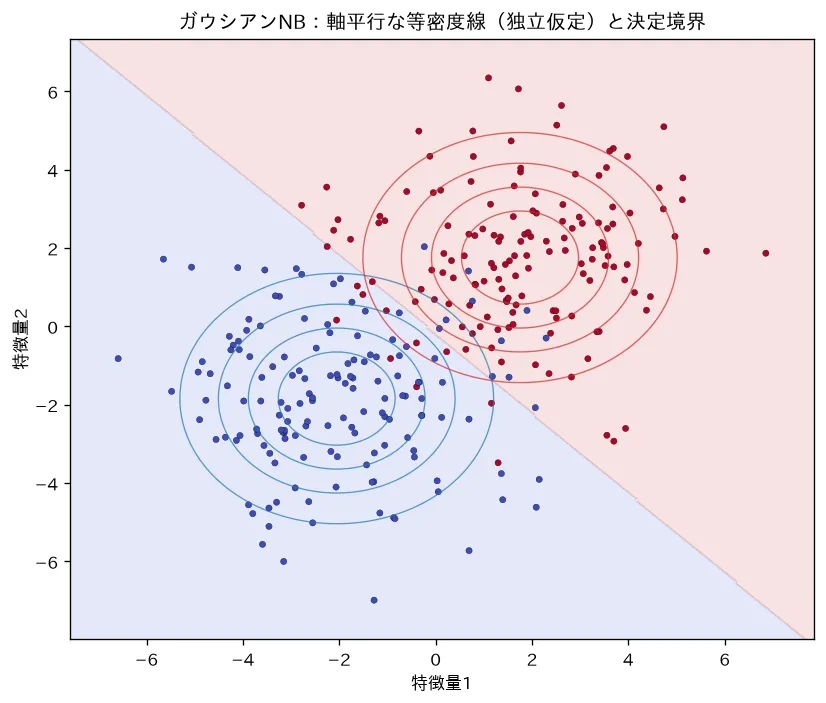
simulations/naive_bayes.py:2クラスデータにガウシアン・ナイーブベイズを当て、決定境界とあわせて各クラスの「軸に平行な等密度線」を描きます。「クラスを決めれば特徴は独立」という仮定のため各クラスの分布が1次元ガウスの積(傾かない楕円)になること、その素朴な仮定でも十分よく分類できることを可視化します。相関まで表すなら共分散をもつQDA(判別分析(LDA・QDA))です。
関連ノート
- 教師あり学習・分類 目次
- ロジスティック回帰(識別モデルの代表。生成 vs 識別の対比)
- 判別分析(LDA・QDA)(同じ生成モデル。特徴間の相関まで使う点が違い)
- 評価指標(分類)とROC・AUC(順位は当たるが確率は歪む=キャリブレーションの話)
- ベイズの定理(統計・事後確率の土台)
- 機械学習テキスト 全体目次